
热门标签
热门文章
- 1Halcon和Opencv区别和在视觉检测中的应用分析_opencv halcon 扫码对比
- 2java数组总结_Java数组知识点总结
- 3【数据分析实战经验】航空公司客户价值分析 LRMFC 模型(K-means聚类,工具python)_lrfmc模型
- 42024年数学建模深圳杯(东三省)A题(无人机编队)助攻论文&支撑材料.doc
- 5一款专业的音乐制作软件Studio One 6.6中文版怎么破解激活_studio one6.6
- 6又一个对标Sora的AI视频工具,Dream Machine,开始免费试用
- 7按钮级别权限管理数据库设计及后台接口实现
- 8使用Unity开发MetaQuest相关笔记教程_meta quest unity
- 9游族马寅龙:常见信息安全风险及应对方案_互联网收口
- 10Python抓取高考网图片
当前位置: article > 正文
Elo顾客忠诚度 —— kaggle数据_保险客户数据集
作者:人工智能uu | 2024-06-27 21:53:28
赞
踩
保险客户数据集
前言
这个数据集来自Kaggle这是链接,是Elo(巴西最大的本土支付品牌之一)和Kaggle合作的项目,通过Elo的匿名数据集预测每个客户的忠诚度(具体到card_id),以及查找影响客户忠诚度的因素。这个是数据集是虚构的(官方是这么说的),而且部分变量都经过匿名处理,并不清楚具体何意(保密工作相当到位)。
整个数据集包含以下的数据,
- historical_transactions: 每个card_id的消费历史,共有2千9百多万条
- new_merchant_transactions:测评期的消费数据,每个card_id在新商店的消费,近2百万条
- merchants:商户的信息数据
- train:训练集
- test: 验证集
- sample_submission:提交数据样本



分析建模
下面将通过python对消费数据进行处理,展现原始数据,已经数据清洗、特征工程和建模的过程。
数据载入
ht = pd.read_csv('all/historical_transactions.csv', dtype={
'city_id': np.int16, 'installments': np.int8, 'merchant_category_id': np.int16, 'month_lag': np.int8, 'purchase_amount': np.float32, 'category_2': np.float16, 'state_id': np.int8, 'subsector_id':np.int8})
nt = pd.read_csv('all/new_merchant_transactions.csv', dtype={
'city_id': np.int16, 'installments': np.int8, 'merchant_category_id': np.int16, 'month_lag': np.int8, 'purchase_amount': np.float32, 'category_2': np.float16, 'state_id': np.int8, 'subsector_id':np.int8})
train = pd.read_csv('all/train.csv')
test = pd.read_csv('all/test.csv')
- 1
- 2
- 3
- 4
- 5
- 6
我们先来看看数据长什么样,可以看到历史交易一共29112361条,测评期的交易有1963031条。



两份交易数据都有3个变量含有缺失值,下面进行数据清洗。
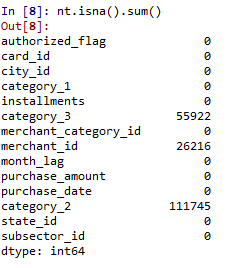
数据清洗
定义一个函数,然后对数据进行清洗。
def tidy_data(df):
df['category_2'].fillna(0, inplace=True)
df['category_3'].fillna('D', inplace=True)
df['installments'].clip(-1, 12, inplace=True)# 有outliers,统一规定范围
mode_mer = df['merchant_id'].mode().iloc[0]# 通过每张卡对应店铺的众数对merchant_id插补
df.sort_values('card_id', inplace=True)
group = df.groupby('card_id')['merchant_id'].apply(lambda x:x.fillna(x.mode().iloc[0] if len(x.mode())>0 else mode_mer))
df.drop('merchant_id', axis=1, inplace=True)
df['merchant_id'] = group.values
return df
ht = tidy_data(ht)
nt = tidy_data(nt)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
特征工程
现在,通过已有的数据增加一些变量,然后我们根据每个card_id消费记录(与各个变量的关系)对数据进行重组,构造一个新的数据集,方便后续操作。
def new_data(df):
df['purchase_date'] = pd.to_datetime(df['purchase_date'], format='%Y-%m-%d %H:%M:%S')
df['month'] = df['purchase_date'].dt.month
df['month'] = df['month'].astype(np- 1
- 2
- 3
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/人工智能uu/article/detail/763917

