
- 1ChatTTS,马斯克听了都说牛逼的语音合成模型!
- 2红队视角下的公有云基础组件安全(二)
- 3Python机器学习实战(一)
- 4【漏洞复现】SpringBlade error/list SQL 注入漏洞_springblade漏洞
- 5卷积神经网络原理及其C++/Opencv实现(3)_c++ 卷积神经网络图像
- 6扫雷超详解(可展开一片空白)_csdn扫雷
- 72024年Flutter开发全网最全学习路线指南_flutter 学习路线
- 8Spark SQL案例:统计每日新增用户_sparksql查询人数
- 9XXL-Job实战(一)
- 10Stable Diffusion:Linux、Mac环境安装教程_cannot locate tcmalloc (improves cpu memory usage)
【目标检测】VOC数据集介绍
赞
踩
数据集介绍
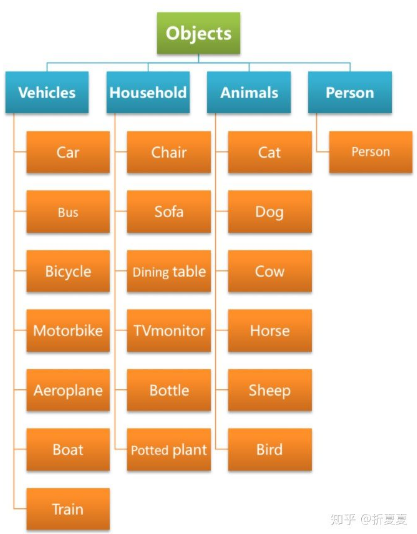
VOC数据集是目标检测领域最常用的标准数据集之一,在类别上可以分为4大类,20小类
- Annotations 进行 detection 任务时的标签文件,xml 形式,文件名与图片名一一对应
- ImageSets 包含三个子文件夹 Layout、Main、Segmentation,其中 Main 存放的是分类和检测的数据集分割文件
-
- Main
-
-
- train.txt 写着用于训练的图片名称
- val.txt 写着用于验证的图片名称
- trainval.txt train与val的合集
- test.txt 写着用于测试的图片名称
-
- JPEGImages 存放 .jpg 格式的图片文件
- SegmentationClass 存放按照 class 分割的图片
- SegmentationObject 存放按照 object 分割的图片
制作自己的VOC格式数据集
参考博客:【机器学习】 - 目标检测 - VOC格式数据集介绍与自己制作_51CTO博客_制作voc数据集
【目标检测】三个文件夹:
- Annotation:保存xml格式的label信息
- ImageSet:Main目录存放不同图片列表文件
-
- train.txt:训练图片文件名列表
- val.txt:验证图片文件名列表
- trianval.txt:训练和验证的图片文件名列表
- test.txt:测试图片文件名列表
- JPEGImages:目录下存放所有的图片集
1、第一步:我们参照原始VOC2007数据集的文件层次创建上述四个文件夹,也就是创建一个VOCdevkit文件夹,下面再创建Annotations、JPEGImages、ImageSets三个文件夹,最后在ImageSets文件夹下再创建一个Main文件夹。
创建好所有文件夹后,我们将自己的数据集图片都放到JPEGImages文件夹下。按照习惯,我们将图片的名字修改为000001.jpg这种格式的(参照原始数据集图片命名规则)。
另外强调两点:
- 第一点是图片的格式,图片需是JPEG或者JPG格式,其他格式需要转换一下。
- 第二点是图片的长宽比,图片长宽比不能太大或太小,这个参考原始VOC2007数据集图片即可。
2、第二步:我们来制作Annotations文件夹下所需要存放的xml文件。
- 这里我们需要借助工具:
-
- LabelImg工具GitHub - heartexlabs/labelImg: LabelImg is now part of the Label Studio community. The popular image annotation tool created by Tzutalin is no longer actively being developed, but you can check out Label Studio, the open source data labeling tool for images, text, hypertext, audio, video and time-series data.
- LabelImg标注工具Releases · heartexlabs/labelImg · GitHub
-
-
- 根据自己的情况选择下载window版本还是linux版本,然后解压使用就行了!
- 关于如何使用,这里以window版本的为例说明:
-
-
-
-
- 下载解压后会得到一个exe可执行文件,另一个是data文件夹,这里面有个txt文件,内容是预定义的分类标签名,里面的标签可以根据自己的需要进行修改。
-
-
说明:每标注完一张图片后进行保存,保存的xml文件名要与对应图片名一致,大家可以参考原始VOC2007数据集中JPEGImages文件夹下图片的命名和Annotations文件夹中的xml文件命名规则。
备注:这里还有个制作工具 VOC2007数据格式制作工具 也很好用,大家也可以试一试VOC2007样本制作工具.zip_免费高速下载|百度网盘-分享无限制
3、第三步:我们来制作ImageSets文件夹下Main文件夹中的4个文件(test.txt、train.txt、trainval.txt、val.txt)。
- test.txt:测试集
- train.txt:训练集
- val.txt:验证集
- trainval.txt:训练和验证集
在原始VOC2007数据集中,trainval大约占整个数据集的50%,test大约为整个数据集的50%;train大约是trainval的50%,val大约为trainval的50%。所以我们可参考以下代码来生成这4个txt文件:
- import os
- import random
-
- trainval_percent = 0.5
- train_percent = 0.5
- xmlfilepath = 'Annotations'
- txtsavepath = 'ImageSets/Main'
- total_xml = os.listdir(xmlfilepath)
-
- num=len(total_xml)
- list=range(num)
- tv=int(num*trainval_percent)
- tr=int(tv*train_percent)
- trainval= random.sample(list,tv)
- train=random.sample(trainval,tr)
-
- ftrainval = open(txtsavepath+'/trainval.txt', 'w')
- ftest = open(txtsavepath+'/test.txt', 'w')
- ftrain = open(txtsavepath+'/train.txt', 'w')
- fval = open(txtsavepath+'/val.txt', 'w')
-
- for i in list:
- name=total_xml[i][:-4]+'\n'
- if i in trainval:
- ftrainval.write(name)
- if i in train:
- ftrain.write(name)
- else:
- fval.write(name)
- else:
- ftest.write(name)
-
- ftrainval.close()
- ftrain.close()
- fval.close()
- ftest .close()
-
- #注意:上述代码中涉及到的路径要写全
- #另外各个数据集所占比例根据实际数据集的大小调整比例。


