
- 1Dijkstra算法-最短路径问题+例题_dijkstra算法求解最短路径例题
- 2自然场景OCR检测(YOLOv3+CRNN)_yolo cnocr文字识别
- 3AI 绘画Stable Diffusion 研究(五)sd文生图功能详解(下)_sd文生图提示词
- 4CubeMX 看门狗喂狗后复位问题_看门狗初始化后,即使喂狗也复位
- 5【SDPTWVRP】基于matlab头脑风暴算法求解带时间窗和同时取送货车辆路径问题【含Matlab源码 1990期】_取送货并带时间窗的车辆路径问题数据集
- 6VMware Workstation Pro各版本下载链接汇总(特全!!!)_vmware workstation pro下载
- 7mysql 常规命令操作_MYSQL快速入门之常用命令介绍
- 8【学习日记week7】VQVAE(dVAE),DALL-E,BEiT:基于生成/跨模态生成的工作概述
- 9基于springboot的农产品销售管理系统/电商项目/水果超市管理系统/微信小程序毕设/农村电商资源对接平台【附源码】_农产品直供交易案例csdn
- 10RCNN系列目标检测算法详解
14-10 AIGC 项目生命周期——第一阶段
赞
踩
生成式 AI 项目生命周期的整个过程类似于从范围、选择、调整和对齐/协调模型以及应用程序集成开始的顺序依赖过程。流程表明每个步骤都建立在前一步的基础上。有必要了解每个阶段对于项目的成功都至关重要。
下面的流程图重点介绍了生成式 AI 项目生命周期的第一阶段 1 — “范围、选择和预训练”需要启动 GenAI 项目。
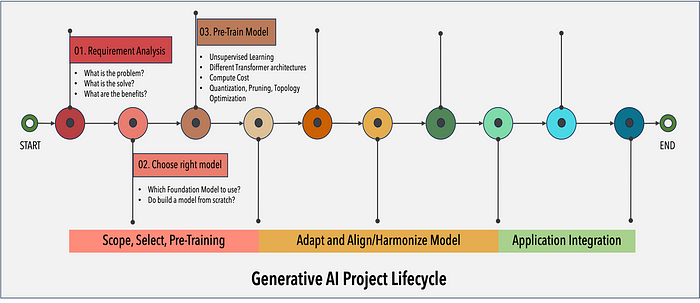
1. 范围:定义问题
与任何应用一样,生成式人工智能项目始于一个需要解决的问题。理解问题、通过生成式人工智能找到解决方案以及可衡量的指标构成了成功项目的支柱。法学硕士能够执行许多任务,但它们的能力在很大程度上取决于模型的大小和架构。确定项目旨在通过生成式人工智能实现什么目标。
您是否需要模型能够执行许多不同的任务?包括生成大量文本,或具有高度的能力,或者任务更具体,如命名实体识别,这样您的模型只需要根据要求擅长一项任务。明确对模型的期望可以节省更多时间,也许更重要的是,计算成本。
2. 选择:选择型号
范围要求决定了模型的选择。决定是使用自己的模型并从头开始训练它们,还是使用现有的基础模型(称为基础模型 (FM))。AI 社区提供了适合各种任务的各种预训练模型。评估这些模型至关重要,要考虑其性能、可扩展性和与项目的兼容性等因素。GPT、BERT、FLAN T5 是可供使用的强大模型的示例。
选择正确的 LLM 架构
特定任务的最佳 LLM 架构取决于该任务的具体要求。例如,
- 如果任务需要生成长文本序列,那么基于转换器的 LLM(如 GPT-3 或 BERT)可能是一个不错的选择。
- 如果任务需要回答问题或理解句子中单词的上下文,那么像 BERT 或 XLNet 这样的模型可能更合适。
- 如果任务需要总结个人/实体之间的对话,那么像 HuggingFace FLAN T5 这样的模型可能是一个选择。
3. 预训练大型语言模型
大型语言模型 (LLM) 中的预训练是指训练的初始阶段,在此阶段,模型将接触大量未标记的文本数据语料库,以学习语言中固有的模式和结构。预训练通过自监督学习使用大量非结构化文本数据来训练 LLM。
此阶段对于模型形成对语言内的语法、语义和上下文关系的总体理解至关重要。
ParagogerAI训练营 2img.ai
图片来自 DeepLearning.AI
LLM 的架构会影响训练效率和推理效率,即在接受训练后,模型能够多快多高效地得出答案。更复杂的模型可能会表现更好,但它们在生产环境中运行速度可能会更慢,成本也会更高。有几类大型语言模型适用于不同类型的用例:
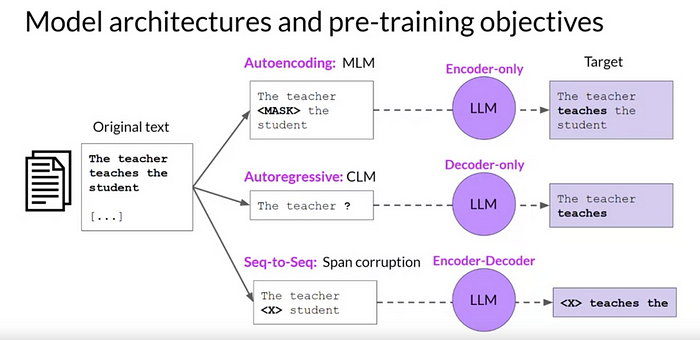
- 自动编码模型- 仅编码器 LLM。这些模型通常适用于能够理解语言的任务,例如命名实体识别 (NER)、分类和情感分析。仅编码器模型的示例包括 BERT(来自 Transformer 的双向编码器表示)、RoBERTa(稳健优化的 BERT 预训练方法)。这些模型使用 MLM (掩码语言建模)进行训练,其中输入被随机掩码。训练目标是预测掩码标记以重建原始句子。
- 自回归模型——仅解码器 LLM。这类模型非常擅长生成语言和内容。一些用例包括故事写作和博客生成。仅解码器架构的示例包括 GPT-3(生成式预训练 Transformer 3)、BLOOM。这些模型使用 CLM(因果语言模型)进行训练,其 训练目标是根据前一个标记序列预测下一个标记。这称为完整语言建模。
- 序列到序列模型——编码器-解码器 LLM 。这些模型结合了转换器架构的编码器和解码器组件,以理解和生成内容。这种架构的一些出色用例包括翻译和摘要。编码器-解码器架构的示例包括 T5(文本到文本转换器)、BART。这些模型使用Span 损坏模型进行训练。如果输入标记,这将屏蔽随机序列。训练目标是用添加到词汇表中的唯一标记替换被屏蔽的标记。
选择合适的预训练目标是持续研究的一个活跃领域,研究人员不断探索新的目标和组合,以充分发挥 LLM 的潜力。
LLM 预培训的挑战
开发和维护大型语言模型所需的大量资本投入、庞大的数据集、技术专长以及大规模计算基础设施一直是大多数企业进入的障碍。
为了训练大型语言模型(LLM),模型的设计非常重要,因为它决定了需要多少计算能力。ParagogerAI训练营 2img.ai
优化方法:
研究人员使用各种优化方法来处理复杂模型的计算需求。模型优化常用的三种技术是剪枝、量化和拓扑优化。
量化:这涉及降低模型权重和激活的精度,通常从浮点数降低到整数。精度降低为 16 位浮点数(FP16、BFLOAT16 -2 字节)或 8 位整数(INT8 -1 字节),而不是 32 位。
修剪:这涉及减少不需要和不太重要的参数的数量。
拓扑优化:这涉及将大模型中的信息压缩为更小、更高效的模型,以便更快地执行。这被称为模型提炼或知识提炼。
结论
在本文中,我们探讨了生成式 AI 项目生命周期,从
- 定义问题(范围)
- 根据需求和成本选择合适的大型语言模型。
- 基本预训练技术
- 模型架构和预训练目标。
- 训练前的挑战
- 提高 LLM 效率和加快执行速度的优化技术。
- ParagogerAI训练营 2img.ai

