
- 1YOLOv8改进 | 进阶实战篇 | 利用YOLOv8进行过线统计(可用于人 、车过线统计)_yolov8 过线
- 2Lateral View语法
- 3Zookeeper集群搭建
- 4Web前端三大主流框架深度解析:React, Angular, Vue.js_3.2主流的web前端框架分析 2015开始前端发生了翻天覆地的变化,vue、react、angul
- 5Android Studio APK签名教程_android studio 签名
- 6C4.5决策树Python代码实现_python 实现c4.5
- 7zookeeper之分布式环境搭建
- 8“一言”槽点满满 “千帆”下海收费_文心一言 api 价格
- 9Base64编码原理_base64toint
- 10深度学习与行业知识库融合:提升AIGC技术在文档创作中的应用_aigc知识库
简述API HOOK技术及原理
赞
踩
目录
最朴实无华的全局HOOK – SysCall_Table HOOK
前言
在windows系统下编程,应该会接触到API函数的使用,常用的api函数大概已经有上千了。随着控件,stl等高效编程技术的出现,API的使用概率在普通的应用程序上就变得越来越小了,但当诸如控件这些现成的手段不能实现的功能时,我们还需要借助API。最初有些人对某些API函数的功能不太满意,就产生了如何修改这些API,使之更好的服务于程序的想法,这样API HOOK就自然而然的出现了。
典型的应用就是Windows兼容模式,不同版本的API实现可能不一样,但是对于应用程序来讲,低版本编译的程序跑在高版本上就需要重写一些API的实现,让其兼容高版本的内核。后来越来越多的安全的工具和病毒都会采用这种技术,修改底层的API函数实现。而现在很多可观测技术的底层都是用了HOOK技术。
本文旨在讨论该技术的本身实现技术和原理。

阅读前须知
C语言基础: 写过1000行以上的C代码就行。
操作系统基础: syscall、中断、虚拟内存概念、进程概念等。
X86-64的框架皮毛:寄存器用途及其传参方式。
汇编皮毛:能通过百度看懂指令就好。
所有示例代码均在centos 7/内核3.10/X64架构下运行,gcc编译。
原始的HOOK技巧(inline HOOK)
这是比较原始的一种hook技巧,主要针对用户态的程序,下面代码示例hook一个C语言的库函数fopen,让其失去原本的功能,打印第一个参数,返回一个字符串地址。
fopen函数原型:
| FILE *fopen(const char *path, const char *mode); |
| /* file: t30.c */ #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <dlfcn.h> #include <sys/mman.h> unsigned long libc_base = 0L; unsigned long get_libc_base() { unsigned long libcaddr; char *p, buf[256] = { 0 }; FILE* fd; fd = fopen("/proc/self/maps", "r"); if( !fd ) { printf("open maps error!"); return 0; } do { fgets(buf, sizeof(buf) - 1, fd); } while(!strstr(buf, "libc-")); p = strchr(buf, '-'); libcaddr = strtol(buf, &p, 16); fclose(fd); printf("libcbase is: 0x%lx\n", libcaddr); return libcaddr; } unsigned long get_target_addr(const char* func_name) { unsigned long funcaddr; void * p_libc = dlopen("libc.so.6",RTLD_LAZY); funcaddr = (unsigned long)dlsym(p_libc, func_name); /* 注释 A funcaddr -= get_libc_base(); funcaddr += libc_base; */ dlclose(p_libc); // 注释 B //funcaddr = (unsigned long)fopen; printf("function %s address is: 0x%lx\n", func_name, funcaddr); return funcaddr; } unsigned char old_code[12] = { 0 }; unsigned char new_code[12] = { 0 }; void * hook_fun(char *file, char *mode) { printf("path: [%s]\n", file); return "hello"; } void inline_hook(char *func_name, unsigned long pfun) { unsigned long fun_addr; int i; //libc_base = get_libc_base(); fun_addr = get_target_addr(func_name); unsigned long page_start = fun_addr & 0xfffffffff000; mprotect((void*)page_start, 0x1000, PROT_READ|PROT_WRITE|PROT_EXEC); memcpy(old_code, (void *)fun_addr, 12); new_code[0] = 0x48; new_code[1] = 0xb8; new_code[10] = 0xff; new_code[11] = 0xe0; for (i = 1; i <= 8; i++) new_code[i + 1] = (unsigned char)((pfun & ((unsigned long)0xff << (i - 1) * 8)) >> (i - 1) * 8); memcpy((void *)fun_addr, new_code, 12); } int main() { inline_hook("fopen", (unsigned long)hook_fun); FILE *fp = fopen("./1.txt", "a+"); printf("ret: [%s] [%lx] \n", fp, (unsigned long)fopen); return 0; } |
编译:gcc t30.c -o t30 -ldl
运行结果:
path: [./1.txt]
ret: [hello] [400720]
代码分析&知识点:
1. 默认情况下在linux下的应用程序都需要借助C语言的库才能正常工作,我们可以用ldd命令看到(下图),函数get_libc_base()用于获取 glibc库加载到内存中的首地址,由于内存加载库的位置是随机,所以每次运行时加载到内存空间的地址是不固定的。

所幸,在每个进程启动后,内核会记录进程加载的所有动态库的首地址,放在/proc/{pid}/maps 中,如果要访问当前进程的只需要访问/proc/self/maps,过滤出libc库的首地址:

如上图,进程中的libc库的首地址为:0x7fd81e9bd000
函数get_libc_base()在本进程中hook本进程的库函数是没有用处的,但如果是编译成动态链接库(*.so文件),注入到其他进程中,就需要放开注释A处的代码来修正函数的偏移地址。
2. get_target_addr中使用了系统API函数dlsym()找到该库中存在的函数的首地址,代码中拿到了fopen当前进程中的首地址。这里如果直接把注释B处代码放开,也可以工作。但是打印一下我们就可以看出通过dlsym拿到的函数IP是0x7fdxxxxxxx起始的一个高位的地址,而直接通过” (unsigned long)fopen”赋值的是一段0x0400XXX开始的相对低位地址。其实默认情况下应用程序都是从0x0400000开始加载的,而这个低位的地址其实就在文件中,我们通过objdump反汇编可以看到,这个函数处其实是一段跳转指令。

这涉及到ELF文件结构中的一个知识点:GOT和PLT的重定位。(请参考PLT、GOT ELF重定位流程新手入门(详细到爆炸)_没事干写博客玩的博客-CSDN博客)
3. 在函数inline_hook中拿到了fopen的首地址,然后通过mprotect修改fopen首地址所在的内存段的读写权限,如果直接修改会导致内存不可读的程序崩溃;代码中的“fun_addr & 0xfffffffff000”就是取当前函数地址所在的内存页的首地址,0x1000 = 4096,刚好一个4K的页大小。但是这里有一个问题,如果函数首地址刚好在这个页的最后几位,而要修改的内存大小超过了当前页,还是会导致崩溃。
4. 用memcpy保存fopen起始的12字节的数据,然后构造新的长度相等的数据覆盖到fopen中;这样当其他函数要调用fopen的时候,就会首先执行我们构造好的12字节的数据。(因为现代计算机架构是分不清数据和代码的区别的,所以构造的数据只要放在代码段就可以被执行!)这12个字节的代码/数据只实现一个事情,跳转到hook_fun函数处,而hook_fun就是我们编写的代替原本fopen函数用的。参考下图示例。
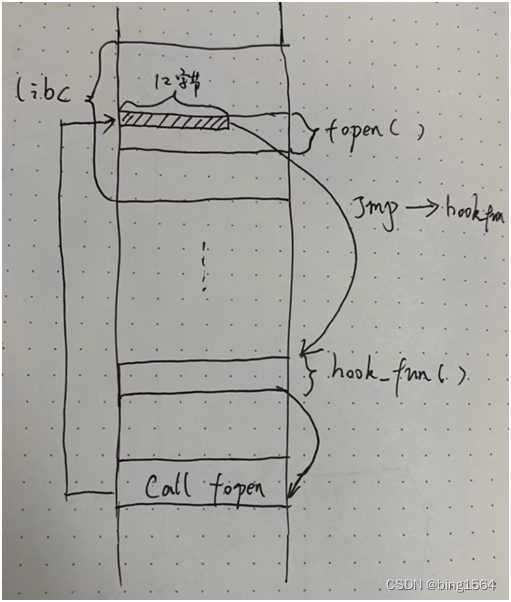
下面我们详细分析下,hook函数的字符串的构造方法:
一般要构造一个跳转方法大致有三种:
a. jmp offset;
b. jmp reg;
c. push&ret;
这里简单介绍下上面的汇编跳转,jmp offset表示从当前地址跳转到目标地址(相对跳转),目标地址和当前地址的偏移为offset,这种跳转好处是不修改当前执行环境且代码比较简单,坏处是长跳的时候不支持64系统,只能在32位程序下使用;jmp reg则不需要考虑32位还是64位,属于绝对跳转到寄存器中的地址,计算简单,但是会修改当前某个寄存器的变量;而push+ret则是模拟函数返回方式,把跳转的地址压入栈中,然后ret(0xc3)返回,编码相对复杂。
这里我们代码中选用的是第二种,先把目标函数hook_fun()的首地址放入寄存器rax中,然后”jmp rax;”实现跳转。
shell命令(需要安装gcc编译器):
| echo "asm(\"mov \$0x12345678abcd, %rax\\n jmp *%rax\\n\");" > test.c; cat test.c; gcc -c test.c; objdump -d test.o; rm -f test.c test.o |

上面这句shell就是把两句汇编指令放入test.c中,然后编译成二进制test.o文件,然后通过objdump反汇编成指令和十六进制字节码。
汇编指令:
mov $0x12345678abcd, %rax ; 把0x12345678abcd 赋值到寄存器 rax中
jmp *%rax ; 把rax里的值当成地址,跳转到该地址处继续执行
指令对应的字节码(12个字节):
48 b8 cd ab 78 56 34 12 00 00 ff e0
在64位操作系统里虚拟地址长度是2的64次方,换算成16进制就是 16位长度即8个字节。所以不难看出字节码中是”cdab785634120000” 就是要跳转的8个字节长度的地址(为何是倒序存储,可以自行百度” 大小端模式存储”,这里不展开);而48b8 这两个字节就是mov [date] -> rax寄存器的操作码(op);而ffe0就是”jmp rax”的操作码,合计2+8+2一共12个字节。如果我们要执行原本的函数,只需要把保存下来的代码恢复回去,再调用就可以了。
5. 上述的方式就是一种比较古老且简单的HOOK方式,只要能拿到函数地址,就能勾住它,但是缺点显而易见:a) 在我们修改这段内存的时候,不是原子操作一步修改成功,这样在修改一半的时候发生线程切换,而环境代码又在多线程中,那么很容易崩溃; b) 只能hook某一个进程,不能hook整个系统,要想做成全局的HOOK参考下面的方式。
| inline HOOK:“我还是那句话,只要能拿到一个函数地址,我就能勾住;那年我双手插兜,不知道什么是对手。” |
最朴实无华的全局HOOK – SysCall_Table HOOK
这是专门针对系统API函数的全局HOOK,一旦对某个API安装完HOOK,所有用户态进程调用该系统函数都会被影响。在系统调用时,用户态切换到内核态环境会使用一个汇编指令syscall/sysenter(有的32位的系统会用一个中断 int 0x80;但是效果相同),在执行该指令前会把要调用的系统服务号写入到eax寄存器中;这里笔者找个网图凑合看看:
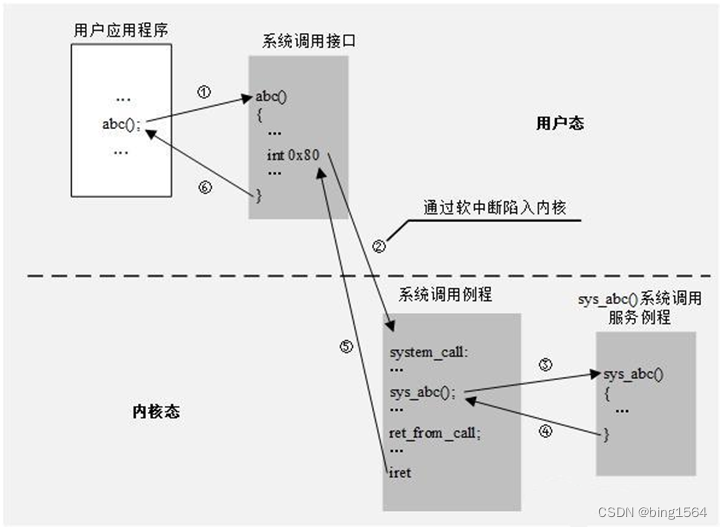
| /* file: sct_hook.c */ #include <linux/kernel.h> #include <linux/module.h> #include <linux/moduleparam.h> #include <linux/fs.h> #include <linux/sysctl.h> #include <linux/proc_fs.h> #include <linux/kallsyms.h> #include <asm-generic/uaccess.h> unsigned long *sys_table_addr; unsigned long p_sys_open; unsigned int is_ro_addr(unsigned long addr) { unsigned int level; unsigned int ro_enable = 0; pte_t *pte = lookup_address(addr, &level); if ((pte_val(*pte) & _PAGE_RW) == 0) ro_enable = 1; return ro_enable; } void set_addr_rw(unsigned long addr) { unsigned int level; pte_t *pte = lookup_address(addr, &level); if (pte->pte & ~_PAGE_RW) pte->pte |= _PAGE_RW; } void set_addr_ro(unsigned long addr) { unsigned int level; pte_t *pte = lookup_address(addr, &level);
pte->pte = pte->pte & ~_PAGE_RW; } #define REPLACE_FUNC(SCT, NEW_FN) \ do { \ if (is_ro_addr((unsigned long)(SCT))) { \ set_addr_rw((unsigned long)(SCT)); \ rw_enable = 1; \ } \ *(SCT) = NEW_FN; \ if (rw_enable == 1) { \ set_addr_ro((unsigned long)(SCT)); \ rw_enable = 0; \ } \ } while (0) static int hook_fun(const char __user *filename, int flags, umode_t mode) { char _filename[1024] = { 0 }; strncpy_from_user(_filename, filename, 1023); printk("process_name:[%s], pid = %d openfile =[%s]\n", current->comm, current->pid, filename); return ((int(*)(const char*, int, umode_t))p_sys_open)(filename, flags, mode); } static int __init kook_init(void) { int rw_enable = 0; sys_table_addr = (unsigned long *)kallsyms_lookup_name("sys_call_table"); p_sys_open = sys_table_addr[2]; REPLACE_FUNC(sys_table_addr + 2, (unsigned long)hook_fun); return 0; } static void __exit kook_exit(void) { int rw_enable = 0; REPLACE_FUNC(sys_table_addr + 2, (unsigned long)p_sys_open); } module_init(kook_init); module_exit(kook_exit); MODULE_LICENSE("GPL"); |
Makefile:
| #obj-$(CONFIG_TOA) += sct_hook.o obj-m += sct_hook.o all: make -C /lib/modules/`uname -r`/build M=$(PWD) clean: make -C /lib/modules/`uname -r`/build M=$(PWD) clean |
编译前需要安装内核开发环境:
yum install kernel-devel-`uname -r`
编译&加载运行:
make
insmod ./sct_hook.ko
1. REPLACE_FUNC是一个宏,用于更改地址,其中用到is_ro_addr、set_addr_ro、set_addr_rw,三个函数分别用于判断地址的可修改属性、设置地址只读、设置地址可读写,这是内核中修改只读内存地址的方法,类似于用户态中的mprotect()函数。
2. kook_init()是这个驱动程序的入口函数,类似于main()函数的概念,在加装该驱动的时候被执行;kook_exit()是退出函数,在驱动被协助的时候被执行。
3. kallsyms_lookup_name()函数是一个内核函数,用于获取内核中的一些函数和结构体的地址,这些函数地址我们可以在/proc/kallsyms里找到,代码中用于获取一个名叫"sys_call_table"的数组。我们通过查找/proc/kallsyms也能看到地址,如下图:

4. sys_call_table这个数组的定义位于内核文件 ./linux-3.10.0/arch/x86/kernel/syscall_64.c中,但是这个文件中看不到具体映射的函数,因为这是在编译的过程中由. /linux-3.10.0/arch/x86/syscalls/目录下的shell脚本生成的。如下图:

如果没有安装内核源码,我们可以在系统头文件/usr/include/asm/unistd_64.h中看到定义。
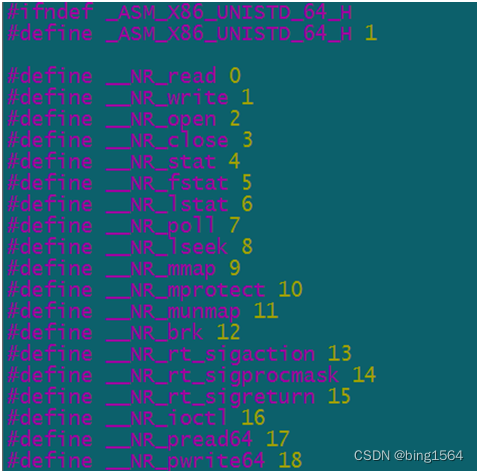
我们可以看到,__NR_open 这个宏和sys_open编号都等于2,其他的函数也是对应的关系;这种顺序排列构成了一个数组,数组中的值就是用户态函数所对应的内核函数的地址,当用户态要调用哪个内核函数的时候,只需要把数组中的序号放到eax/rax寄存器中,然后执行中断就可以调用到内核函数了。如下图:

那我们HOOK的思路就修改掉sys_call_table这个数组中内核函数sys_open的地址,就对整个系统中open函数进行了HOOK。
p_sys_open = sys_table_addr[2]; //保存sys_open函数的地址,放到变量p_sys_open中。
REPLACE_FUNC(sys_table_addr + 2, (unsigned long)hook_fun);//用hoo_fun的地址替换掉原本sys_open的函数地址。
5. 由于实现准备好hook_fun()函数的内容,最后替换地址的操作只需要1步(汇编中最后修改的指令),所以不存在线程切换过程中被迫中止而导致系统崩溃的问题。所以这个HOOK和UNHOOK都是安全的。执行“tail -f /var/log/messages”如下图:

打印了系统中所有调用open函数打开文件的文件路径和使用open函数的进程PID以及进程名。如果我们想对open函数的调用做一些个性化的判断,在我们hook_fun()函数中就可以完成。例如禁止打开某些文件,打开某些文件的时候篡改成打开其他文件,记录打开文件的行为等等。
内核跟踪的利器 - kprobe
我们在内核调试的过程中,往往需要知道一些函数的执行流程,何时被调用,入参和返回值是什么等等,还有一些动态追踪工具如ftrace、trace-cmd需要跟踪函数执行的过程,都可以视作为一种HOOK。对要跟踪的函数下钩子,然后等执行到该函数时调用钩子对执行的过程进行打点,类似于GDB的断点。
这里使用kprobe技术对内核函数sys_open()下一个钩子,代码如下:
| /* file: kprobe_open.c */ #include <linux/kernel.h> #include <linux/module.h> #include <linux/kprobes.h> #include <asm-generic/uaccess.h> static struct kprobe kp = { .symbol_name = "sys_open", }; static int handler_pre(struct kprobe *p, struct pt_regs *regs) { #ifdef CONFIG_X86 char filename[1024] = { 0 }; printk(KERN_INFO "pre_handler: p->addr = %p, ip = %lx," " flags = 0x%lx, di = %lx\n", p->addr, regs->ip, regs->flags, regs->di);
strncpy_from_user(filename, (void *)regs->di, 1023); printk("process_name:[%s], pid = %d openfile =[%s]\n", current->comm, current->pid, filename); #endif dump_stack(); return 0; } static void handler_post(struct kprobe *p, struct pt_regs *regs, unsigned long flags) { } static int handler_fault(struct kprobe *p, struct pt_regs *regs, int trapnr) { printk(KERN_INFO "fault_handler: p->addr = 0x%p, trap #%dn", p->addr, trapnr); return 0; } static int __init kprobe_init(void) { int ret; kp.pre_handler = handler_pre; kp.post_handler = handler_post; kp.fault_handler = handler_fault; ret = register_kprobe(&kp); if (ret < 0) { printk(KERN_INFO "register_kprobe failed, returned %d\n", ret); return ret; } printk(KERN_INFO "Planted kprobe at %p\n", kp.addr); return 0; } static void __exit kprobe_exit(void) { unregister_kprobe(&kp); printk(KERN_INFO "kprobe at %p unregistered\n", kp.addr); } module_init(kprobe_init) module_exit(kprobe_exit) MODULE_LICENSE("GPL"); |
Makefile:
| obj-m += kprobe_open.o all: make -C /lib/modules/`uname -r`/build M=$(PWD) clean: make -C /lib/modules/`uname -r`/build M=$(PWD) clean |
加载执行后的效果(dmesg):

1. 我们先来看下结构体struct kprobe,定义在内核 ./linux-3.10.0/include/linux/kprobes.h,如下图所示:
const char *symbol_name; 指向要跟踪或者说要HOOK的函数名称,这里的函数名称需要是在/proc/kallsyms 中能找到。
kprobe_opcode_t *addr; 表示被跟踪的函数的地址,如果symbol_name 正确,这个变量可以不用填写。
pre_handler、post_handler、fault_handler、break_handler,这4个变量都是回调函数指针,分别在被跟踪的函数执行前、执行后、执行前两者函数过程中出现异常、执行全过程中触发断点后被调用。上述代码中打印出在sys_open执行前,调用pre_handler指针指向的函数,然后再函数中打印了sys_open的第一个参数的信息,以及用dump_stack()打印了函数调用路径。
kprobe_opcode_t opcode; 用来保存原函数被替换掉的指令,这点非常重要。

2. register_kprobe()函数通过传参结构体kprobe,初始化要跟踪的函数。这其中做了类似inline HOOK的事情,把函数的首地址对应的第一个指令替换成”int 3”,也就是字节码0xCC;当调用sys_open()函数的时候,执行0xCC就触发了 int 3中断,然后通过内核中很重要的另一张表IDT(Interrupt Descriptor Table),找到中断函数do_int3()然后回调kprobe_handler()函数,达到了HOOK效果,如下图:

3. 最后聊到handler_pre()函数,也就是"typedef int (*kprobe_pre_handler_t) (struct kprobe *, struct pt_regs *);" 这个函数指针所对应的实际执行函数。第一个参数上面介绍过,第二个参数结构体struct pt_regs,在不同的架构下的定义是有很大差异的,这里我们只介绍X86-64的架构下的定义,位于内核原本文件(./linux-3.10.0/arch/x86/include/asm/ptrace.h)中,如下图定义:
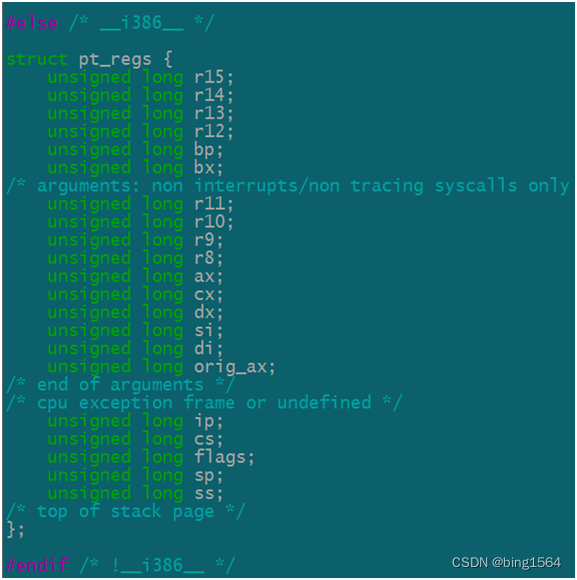
这个文件中,有两个结构体,分布是x86的32位系统定义和图上的64位系统定义,这个结构体的成员变量就是Intel CPU中对应的寄存器的映射值。当调用函数时候截取下来当做参数传入到handler_pre()函数内,而通过下图,我们得知X64的寄存器传参使用规则。

故而,第一个参数的值就放在了rdi寄存器中,也就是结构体变量regs->di中。所以通过strncpy_from_user()函数把rdi寄存器中地址指向的缓冲区复制到内核中打印出来,就成了open()函数的第一个变量” const char *pathname”咯。
kprobe的实战-隐藏进程
上面几种HOOK(或跟踪函数)的方式都是对一些开放函数的,在kallsyms中都可以找到这些函数,但是有时候我们还可以从回调函数下手来HOOK。还是先贴代码:
| /* file: hide.c */ #include <linux/kernel.h> #include <linux/kprobes.h> #include <linux/module.h> #include <linux/moduleparam.h> #include <linux/fs.h> int register_kprobe(struct kprobe *kp); static struct kprobe kp = { .symbol_name = "proc_pid_readdir", }; static filldir_t old_filldir; static int pid; module_param(pid, int, 0744); static int my_filldir(void * __buf, const char * name, int namlen, loff_t offset, u64 ino, unsigned int d_type) { int p; sscanf(name, "%d", &p); if (p == pid) return 0; return old_filldir(__buf, name, namlen, offset, ino, d_type); } static int handler_pre(struct kprobe *pr, struct pt_regs *regs) { old_filldir = (filldir_t)regs->dx; regs->dx = (typeof(regs->dx))my_filldir; return 0; } static int __init k_init(void) { int ret; kp.pre_handler = handler_pre; ret = register_kprobe(&kp); if (ret < 0) { printk(KERN_INFO "register_kprobe failed, returned %d\n", ret); return ret; } printk(KERN_INFO "Planted kprobe at %p; pid %d\n", kp.addr, pid); return 0; } static void __exit k_exit(void) { unregister_kprobe(&kp); printk(KERN_INFO "kprobe at %p unregistered\n", kp.addr); } module_init(k_init); module_exit(k_exit); MODULE_LICENSE("GPL"); |
Makefile:
| #obj-$(CONFIG_TOA) += hide.o obj-m += hide.o all: make -C /lib/modules/`uname -r`/build M=$(PWD) clean: make -C /lib/modules/`uname -r`/build M=$(PWD) clean |
看下效果,我这里隐藏了nginx的master进程,进程ID = 963,如下图:

其实nginx的进程还在,可以看到worker进程的父进程还显示着963,但是 ps -ef 和 /proc下面都找不到PID=963的进程信息,另外在top下面不指定进程号也是看不到的。
卸载这个驱动,又可以看到被隐藏的nginx进程了。如下图:

下面我们来分析下代码:
1. /proc是Linux系统下一个虚拟的文件系统,不是一个真实的目录。linux内核的VFS把proc当成一个文件系统来管理,所以在open打开/proc下的文件或者目录会走到proc管理的部分。实际上proc中内容有两种,一种是在内存中预先分配好的,外界读取的时候直接给数据,另一种是动态的,在外界读取的时候动态生成。而进程的pid号对应的目录就属于动态生成出来的。而很多用户态应用都是根据proc下的pid目录名来获取进程列表的,最典型的就是ps命令。
2. 那么我们只要对读取目录的系统调用进行hook后略作修改,就能实现隐藏进程的目的。如下表看下正常情况下的系统调用:
| sys_getdents: error = vfs_readdir(f.file, filldir, &buf); vfs_readdir: res = file->f_op->readdir(file, buf, filler); static const struct file_operations proc_root_operations = { .read = generic_read_dir, .readdir = proc_root_readdir, .llseek = default_llseek, }; proc_root_readdir: ret = proc_pid_readdir(filp, dirent, filldir); proc_pid_readdir: if (proc_pid_fill_cache(filp, dirent, __filldir, iter) < 0) proc_pid_fill_cache: return proc_fill_cache(filp, dirent, filldir, name, len, proc_pid_instantiate, iter.task, NULL); proc_fill_cache: return filldir(dirent, name, len, filp->f_pos, ino, type); |
可以看到系统调用getdents从入口处就设置了一个回调函数filldir(),一直到最后一步proc_fill_cache()函数中才进行循环调用,用于填充响应的数据(也就是/proc下的pid目录名)。我们在proc_root_readdir()处下手,把它的第三个参数给修改了。也就是代码中handler_pre()函数实现的事情,把regs->dx保存并替换,就等于修改了proc_root_readdir()的第三个参数(参考上面的x64架构传参表)。这样在proc_fill_cache()函数中调用的回调函数就变成我们的my_filldir()函数了,在我们自己函数中,发现如果是我们要隐藏的pid的目录名,就跳过正常的调用即可。
3. module_param 用于在驱动初始化的时候获取传参。
内核中一些函数指针结构体的hook
我们观察内核代码的时候,很多时候一些函数调用都初始化的时候设置成回调函数的,例如上一个例子读取文件目录,那么proc有自己独有的读取目录处理函数,相对于的ext4、ceph、hpfs等等文件系统都有自己的处理函数,那么getdents的时候如何能调用到正确的处理函数呢?其实在open()的时候就确定好了,在打开这个文件目录的时候就确定了这个文件系统交给proc来处理了,所以file->f_op的回调函数指向了proc文件系统的处理函数,而不是给ext4等其他的处理函数。
在如下图的内核代码(./linux-3.10.0/net/ipv4/tcp_ipv4.c):
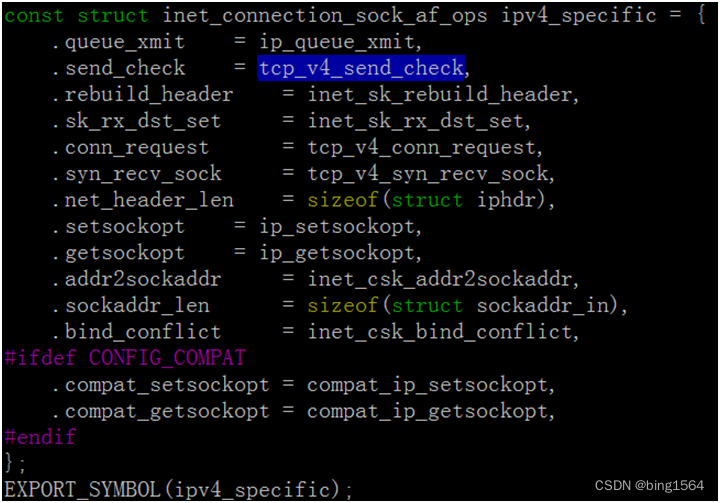
我们可以看到全局的结构体ipv4_specific,其中一个成员变量send_check指向了函数tcp_v4_send_check(),而同样的结构体在另一个目录ipv6下也有,如下图:

而在应用程序建立套接字的时候选择了v4还是v6,都是同一个系统调用(sys_socket),只是传入的参数是不一样的,那么内核根据传参的差异,灵活的选择使用不同函数来初始化套接字,不同的函数又使用各自对应的结构体来初始化后续的调用函数。这类函数的指针结构体在内核中非常多,那么这些结构体成员变量就是天生的HOOK点,只需要拿到表的地址,然后修改其中的参数变量就可以完成HOOK安装了。而这类表的地址可以轻易的拿到,如下图:

可能最大的问题在于要对目标函数要非常熟悉,明白函数用于什么地方,并且hook处理函数不能写错,毕竟这样写是没有kprobe的异常处理函数来兜底的。比如我们可以hook住tcp_v4_send_check()来统计某个协议发送了多少流量,也可以HOOK住TCP的握手处理函数,在服务端端统计TCP建立连接用了多长时间等等。
| inline HOOK:“现在我双手抱头,被打的不敢还手。” |
最后看看网络技术上的HOOK技术应用
大家在linux主机上最熟悉的防火墙应该就是iptables了,但是究其实现原理就要聊到Netfilter。Netfilter是挂载在linux内核网络协议栈中的报文处理/过滤/修改的框架。它在内核中报文的关键流动路径上定义了5个HOOK点,各种协议(IPv4、IPv6、ARP、ICMP等)可以在这些HOOK点安装HOOK处理函数,报文流经此地,内核会按照优先级调用这些HOOK函数,这些函数最终会决定报文是被NF_ACCEPT(放行)还是NF_DROP(丢弃)。如下图:

Netfilter中常提到的5链4表,这里表就不讨论了,而5链就是指在5个HOOK点上设置的HOOK处理函数的链表。
5个HOOK点:
PRE_ROUTING:数据包进入路由表之前
LOCAL_IN:通过路由表后目的地为本机
FORWARD:通过路由表后,目的地不为本机
LOCAL_OUT:由本机产生,向外发送
POST_ROUTING:发送到网卡接口之前。
我们去内核的IPV4的协议栈实现的源码目录里搜索下,遍地都是HOOK点:


我们可以看到Netfilter就在关键的函数点等着去过滤网络报文,这算是官方认证的HOOK么?
我们再到./linux-3.10.0/include/linux/netfilter.h里看下NF_HOOK的实现:

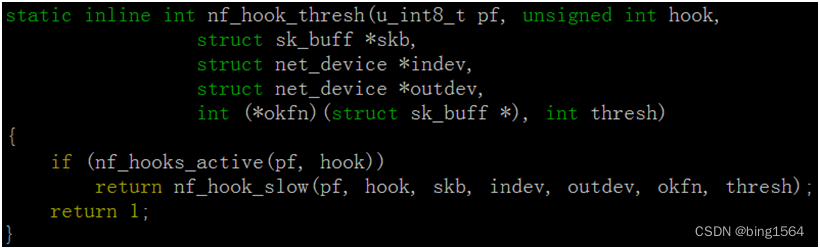
到这里HOOK执行完成,nf_hook_thresh()就是HOOK函数,根据返回值,看是否继续走下面的流程,如果返回1则走正常协议栈调用okfn(),如果返回其他值,则流程结束,这个报文也就被丢弃了。
但是Netfilter带来了两个问题,路径太长和规则过滤太多:报文需要经过链路层,IP层才能被处理,如果是需要丢弃的报文,会白白浪费很多CPU资源,影响整体性能;Netfilter 框架类似一套可以自由添加策略规则专家系统,并没有对添加规则进行合并优化,这些都严重依赖操作人员技术水平,随着规模的增大,规则数量N成指数级增长,而报文处理又是O(N)复杂度,最终性能会直线下降。随着互联网的流量越来越大,内核的协议栈因为历史包袱的缘故,效率上捉襟见肘,而多队列网卡、网卡分流RSS、中断线程化都是治标不治本,就目前而言唯有绕过内核(kernel-bypass)是出路。
绕过内核有两种选择:a. 让应用程序独享CPU直接读取网卡从而绕过内核协议栈的DPDK是一种。b. 而反其道而行的让网卡NPU直接处理业务逻辑的eBPF-XDP则是另一种。eBPF的历史以及如何从BPF到eBPF的,请自行百度,笔者只是介绍下BPF如同通过钩子挂载到内核里的,而不讨论这个技术本身。eBPF因为其一些特性和最近流行的“可观测”相辅相成/狼狈为奸,见下图文章:

是不是真能走向神坛,我保留意见,这里我们只欣赏下eBPF的下钩机制。

展开上图的钩子,下图展示HOOK点:

最后抽取个HOOK点贴下代码,3.10的内核源码不能满足要求,下面的代码会使用5.15的内核源码做介绍。

如上图所示,在tcp_output.c的函数tcp_make_synack()中生成SYN的ACK响应包的时候下钩子,来操纵响应的报文。
笔者要表达的是钩子在linux内核中随处可见,相比说它是门技术笔者觉得它更像是一种编程思路,利用钩子对庞大的内核修修补补,可观测、审查、旁路、实现业务等等。

