
[机器学习] LightGBM on Spark (MMLSpark) 使用完全手册_spark lightgbm
赞
踩
一 Spark上训练模型优势与劣势
(1)机器学习算法一般都有很多个步骤迭代计算的过程,机器学习的计算需要在多次迭代后获得足够小的误差或者足够收敛才会停止,迭代时如果使用一般的Hadoop分布式计算框架,每次计算都要读 / 写磁盘以及任务的启动等工作,这回导致非常大的 I/O 和 CPU 消耗。而 Spark 基于内存的计算模型天生就擅长迭代计算,多个步骤计算直接在内存中完成.
(2)从通信的角度讲,如果使用 Hadoop分布式计算框架, 工作和任务之间由于是通过 heartbeat 的方式来进行的通信和传递数据,会导致非常慢的执行速度,正常来说会减缓机器学习的速度.spark通讯效率极高,可以解决这个问题.
目前发现的spark训练模型的劣势:
(1)配置繁琐,使用之前要先配置spark集群,scala编译器,java编译器
(2)要按照spark指定的数据格式进行训练,一般机器学习可以直接读取数据例如csv,指定特征列后进行特征处理训练,spark的训练格式要把数据里面类型,标签提前整理好
二 Lightgbm on Spark 介绍
LigthGBM训练速度更快,效率更高。LightGBM比XGBoost快将近10倍。
降低内存使用率。内存占用率大约为XGBoost的1/6。
准确性有相应提升。
支持并行和GPU学习。
能够处理大规模数据。
大部分使用和分析LigthGBM的都是在python单机版本上。要在spark上使用LightGBM,需要安装微软的MMLSpark包.
mmlspark
MMLSpark是一个工具生态系统,旨在将Apache Spark的分布式计算框架扩展到 几个新的方向。MMLSpark为Spark生态系统添加了许多深度学习和数据科学工具,Microsoft Cognitive Toolkit(CNTK),LightGBM和 OpenCV的无缝集成。这些工具可为各种数据源提供功能强大且可高度扩展的预测和分析模型。
MMLSpark需要Scala 2.11,Spark 2.3+ (没能测试过Spark 3.0, 应该还不支持) 以及Python 2.7或Python 3.5+
项目地址:https://github.com/Azure/mmlspark
在Python(或Conda)安装上尝试MMLSpark,首先通过pip安装PySpark, pip安装pyspark, mmlspark
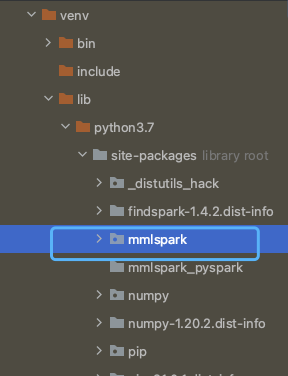
(如果pip安装后,运行时找不到部分py, 可以从mmlspark_2.11-0.18.1.jar) 下解压出mmlspark包 copy到 python env site-packages中

1. 使用Spark packages (会自动下载依赖的jars)
spark.jars.packages com.microsoft.ml.spark:mmlspark_2.11:0.18.1
- spark = SparkSession \
- .builder \
- .appName("Python Lightgbm") \
- .config('spark.jars.packages', "com.microsoft.ml.spark:mmlspark_2.11:0.18.1") \
- .getOrCreate()
2.使用Spark jars (提前下载jars)
Spark集群一般不能连接公网下载对应jars,一般是用户自己提前下载好
spark.jars lightgbmlib-2.2.350.jar,mmlspark_2.11-0.18.1.jar'
- spark = SparkSession \
- .builder \
- .appName("Python Lightgbm") \
- .config('spark.jars',
- '/Users/jars/lightgbmlib-2.2.350.jar,/Users/jars/mmlspark_2.11-0.18.1.jar') \
- .getOrCreate()
三 Lightgbm on Spark 代码介绍
- import findspark
-
- findspark.init()
-
- from mmlspark.lightgbm import LightGBMClassifier
- from pyspark.ml.feature import VectorAssembler
- # from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
- from pyspark.ml.evaluation import BinaryClassificationEvaluator
- from pyspark.ml import Pipeline
- from pyspark.sql import SparkSession
-
- # spark = SparkSession \
- # .builder \
- # .appName("Python Lightgbm") \
- # .config('spark.jars',
- # './jars/lightgbmlib-2.2.350.jar,./jars/mmlspark_2.11-0.18.1.jar') \
- # .getOrCreate()
-
- spark = SparkSession \
- .builder \
- .appName("Python Lightgbm") \
- .config('spark.jars.packages', "com.microsoft.ml.spark:mmlspark_2.11:0.18.1") \
- .getOrCreate()
-
- df_train = spark.read.format("csv") \
- .option("inferSchema", "true") \
- .option("header", "true") \
- .option("sep", ",") \
- .load("./data/csv_data/train.csv")
- df_val = spark.read.format("csv") \
- .option("inferSchema", "true") \
- .option("header", "true") \
- .option("sep", ",") \
- .load("./data/csv_data/test.csv")
- df_test = spark.read.format("csv") \
- .option("inferSchema", "true") \
- .option("header", "true") \
- .option("sep", ",") \
- .load("./data/csv_data/test.csv")
-
- feature_cols = list(df_train.columns)
- feature_cols.remove("label") # 从列名当中删除label才是真正的特征列表
- assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
-
- lgb = LightGBMClassifier(
- objective="binary",
- boostingType='gbdt',
- isUnbalance=True,
- featuresCol='features',
- labelCol='label',
- maxBin=60,
- baggingFreq=1,
- baggingSeed=696,
- earlyStoppingRound=30,
- learningRate=0.1,
- lambdaL1=1.0,
- lambdaL2=45.0,
- maxDepth=3,
- numLeaves=128,
- baggingFraction=0.7,
- featureFraction=0.7,
- # minSumHessianInLeaf=1,
- numIterations=100,
- verbosity=50
- )
-
- stages = [assembler, lgb]
- pipeline_model = Pipeline(stages=stages)
- model = pipeline_model.fit(df_train)
-
- train_preds = model.transform(df_train)
- val_preds = model.transform(df_val)
- test_preds = model.transform(df_test)
-
- binaryEvaluator = BinaryClassificationEvaluator()
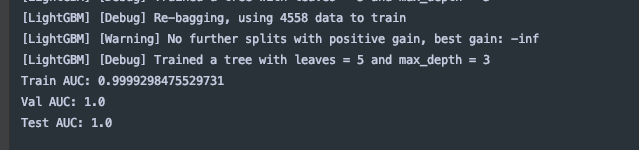
- print("Train AUC: " + str(binaryEvaluator.evaluate(train_preds, {binaryEvaluator.metricName: "areaUnderROC"})))
- print("Val AUC: " + str(binaryEvaluator.evaluate(val_preds, {binaryEvaluator.metricName: "areaUnderROC"})))
- print("Test AUC: " + str(binaryEvaluator.evaluate(test_preds, {binaryEvaluator.metricName: "areaUnderROC"})))

lightgbmlib-2.2.350.jar lightgbm_python.py mmlspark_2.11-0.18.1.jar

四 模型其他相关代码
LibSVM训练与评估

1. 数据读取与切分

2. 模型训练

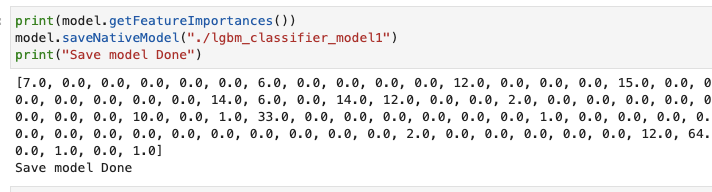
3. 模型特征重要度,保存模型
4 模型指标计算

五 提交代码到Spark集群中跑
需要准备文件

- /home/work/cloud-hadoop-client/spark232/bin/spark-submit \
- --master yarn \
- --queue survey \
- --deploy-mode cluster \
- --name "development_lightgbm" \
- --conf spark.yarn.dist.archives=hdfs://shanghai/tools/pylightgbm.tar.gz#pyenv \
- --conf spark.pyspark.python=./pyenv/pylightgbm/bin/python \
- --jars mmlspark_2.11-0.18.1.jar,lightgbmlib-2.2.350.jar \
- --executor-memory 2G \
- --driver-memory 4G \
- --conf spark.driver.host=10.157.18.46 \
- --conf spark.driver.maxResultSize=5g \
- --executor-cores 2 \
- --num-executors 2 \
- lightgbm_python.py

