
- 1本科毕业生个人简历23篇_包含从大学本科起的个人学习、科研、工作经历(时间不间断)
- 2避坑必看:很详尽的MyBatis返回自增主键实验(包括插入或更新SQL语句insert on duplicate key update的自增主键返回情况)_mybatis on duplicate key update 返回主键
- 3玩转树莓派之 安装opencv_libopencv-dev
- 4MySQL 索引的分类和优化_统计和分组适合使用什么索引
- 5TortoiseGit操作失败并提示Another git process seems to be running in this repository, e.g. an editor ..._an editor opened by 'git commit'. please make sure
- 6Python每日一题:回文数
- 7人工智能 -- NLP : 零基础学习深度学习系列文章_零基础学习nlp 如何开始
- 8python_求球体数据_python求球的体积代码
- 9前端JavaScript疑问简答题面试题_3.实现一个函数clone 可以对javascript中的五种主要数据类型(number、strin
- 10anaconda,jupyter打开某文件夹下的项目代码python_jupyter只能运行文件夹里的代码吗
如何训练一个大语言模型(LLMs)_大语言模型训练过程
赞
踩
前言
在当今数字时代,语言模型已经成为自然语言处理任务的强大工具,从文本生成到情感分析和机器翻译等各个方面都有涉猎。然而,训练这些模型需要仔细的规划、大量的计算资源以及机器学习技术方面的专业知识。
那么一个大型语言模型(LLMs)到底是如何训练出来的呢?在查阅了解之后,我们将相关内容整理出来。在本文中,将和大家一起探讨训练LLMs所涉及的步骤,欢迎各位读者指正与补充。

大语言模型 Vs机器学习模型
大语言模型和传统机器学习模型在模型训练步骤方面有一些相同点,比如它们都需要:
- 准备和整理训练数据
- 选择合适的模型架构和超参数
- 进行模型训练和评估
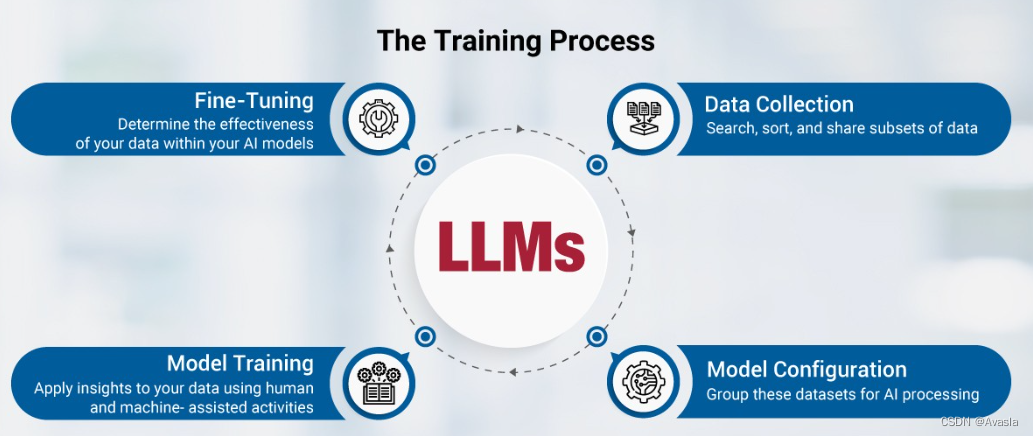
不过,它们也存在一些不同点,和机器学习模型相比,大语言模型通常:
- 更复杂,需要大量微调以适应特定任务
- 需要大量的文本数据,然后再进行
- 需要更大的计算资源和时间。
而传统机器学习模型可能更加灵活,可以根据任务的需求选择不同的特征工程和算法,在较小的数据集和资源下也能取得良好的效果。
- 更灵活
- 根据任务需求选择算法
- 较小的数据集和资源
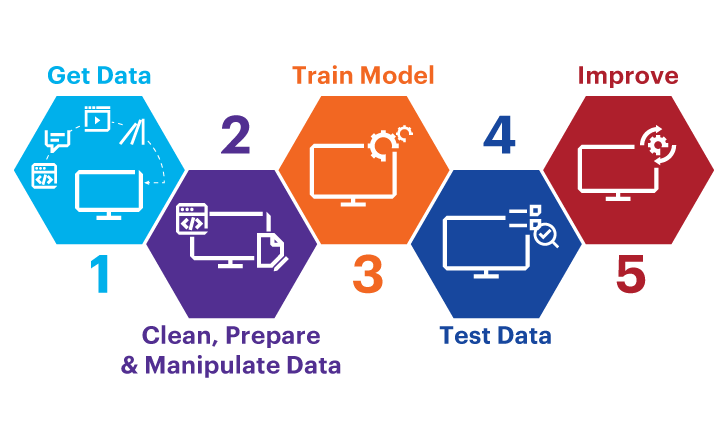
训练过程
步骤1:数据策划(Data Curation)
在大模型训练过程中,数据清洗不单单是删除一些错误数据、重复项,还包括对不同语料数据的重新组织整合,同时,这些数据也可以重复训练不同的模型任务。因此,这里没有选择更佳熟悉的Data Cleaning,而是选用了Data Curation一词,感觉更佳恰当。
来自维基百科翻译:
数据策划是对从各种来源收集的数据进行组织和整合的过程。它涉及数据的标注、发布和呈现,以确保数据的价值随着时间的推移得以保持,并且数据仍然可以用于重复使用和保存。数据策划包括“所有为了原则性和受控的数据创建、维护和管理所需的过程,以及增加数据价值的能力”。
在训练数据整理阶段,收集大量的数据是关键。训练数据的质量和数量对LLMs的性能有着重要影响。收集的数据应该与模型的目标相关,多样化并且具有代表性的数据集,包括书籍、文章、网站或特定领域的语料库的文本。
数据收集完毕后,不能直接用于模型训练,还要进行各种处理,比如:
- 语言选择:收集的语料包含了各种语言,要选择哪几种语言进行训练。
- 质量检查:确保数据符合期望的质量标准,适合预期的用途
- 去重:删除相似性高的内容,以提高训练的准确性,同时减少占用的存储空间。
- 删除个人敏感信息 PII( Personally Identifiable Information)
- 数据净化:识别和删除污染物、异常以及不需要的元素,有助于减轻使用受污染数据所带来的风险,例如偏见分析或不准确的见解。
步骤2:格式化与预处理
在将数据提供给模型之前,需要对其进行格式化和预处理。确保数据清洁、统一,以提高模型的训练效果。这包括:
- 格式化:将文本转换为模型可接受的输入格式
- 清洗文本:清洗文本以去除不必要的字符、标点符号、HTML标签、特殊字符或噪音等。
- 移除停用词:在语言中频繁出现但通常没有特定的含义或信息量,例如英文中的 “the”, “is”, “and” 等。
- 标记化/分词 (Tokenization):将一句话切割成词组、短语或字符等离散单元,可以通过空格、标点符号或特定规则进行分割。
这个步骤最常用的工具库就是Tokenizers,支持多种算法和语言,能快速对文本进行清洗和预处理。
步骤3:训练模型
选择合适的训练框架是至关重要的,常用的框架包括TensorFlow、PyTorch等,根据需求和技术熟练程度选择合适的框架。同样重要的还有配置训练环境,包括硬件资源和软件依赖项,并确保训练过程的顺利运行。
配置训练环境:
- 硬件资源:
- GPU:训练LLMs需要大量的图形处理单元(GPU)来加速计算。通常使用NVIDIA的GPU,如Tesla V100、Tesla T4等。
- TPU:谷歌的Tensor Processing Units(TPU)也可以用于训练大型语言模型,提供了高效的计算能力。
- 内存:大规模语言模型需要大量内存来存储模型参数和中间结果,通常需要数百GB甚至数TB的内存。
- 软件资源:
- CUDA和cuDNN:如果使用GPU,需要安装NVIDIA的CUDA和cuDNN库来加速深度学习计算。
- 深度学习框架:安装所选框架的最新版本,例如TensorFlow或PyTorch。
- 预训练模型:如果使用预训练的语言模型作为基础,需要下载或准备相应的预训练模型权重。
训练框架:
- TensorFlow:由Google开发的开源深度学习框架,提供了丰富的工具和资源来训练大规模的语言模型。
- PyTorch:由Facebook开发的深度学习框架,因其灵活性和易用性而受到青睐。
- Hugging Face Transformers:提供了一系列预训练的语言模型和自然语言处理模型的实现,包括BERT、GPT、RoBERTa等,基于PyTorch实现,提供了方便的模型和预训练权重加载。
- DeepSpeed:微软开发的深度学习框架,专注于大规模分布式训练和高效模型优化。它使ChatGPT等模型训练仅需一键操作即可完成,同时在各个规模上实现了前所未有的成本降低。
- Llama:Llama是一系列预训练和微调的LLM,参数范围从70亿到700亿。它是Meta(Facebook的母公司)AI团队开发的。Llama 2 Chat LLMs专为对话用例进行了优化,并已在各种基准测试中表现出色,超过了许多开源聊天模型。
- LangChain:是一个 Python 库和框架,旨在赋能开发者创建由语言模型驱动的应用程序,特别关注像 OpenAI 的 GPT-3 这样的大型语言模型。它配备了多种功能和模块,旨在优化与语言模型合作时的效率和可用性。
步骤4:模型评估
在训练完成后,对模型进行评估是必不可少的。
在机器学习模型训练中,我们会通常比较看重预测结果的准确性,使用准确度、召回率、F1分数等这些评估指标来衡量模型的性能,同时,将模型在测试集上进行评估,以确保其在未见数据上的泛化能力。
而在LLM中,使用者希望模型能够完成问答、总结、文本分析、翻译等等文本处理任务,因此,评估一个大语言模型(LLM)涉及多个方面,包括模型的语言能力、生成能力、语义理解、文本生成质量等,所使用的指标也各有不同。
下面选取了几个:
- 困惑度(Perplexity):用于衡量语言模型在给定文本序列下预测下一个单词的准确性,困惑度越低表示模型预测越准确。
- BLEU分数:评估生成文本与参考文本之间的相似度,尤其在机器翻译任务中常用,分数越高表示生成结果越接近参考文本。
- ROUGE指标:评估生成文本与参考文本之间的重叠程度,特别适用于自动摘要生成任务,ROUGE值越高表示生成结果与参考文本越接近。
- ARC: AI2 Reasoning Challenge 涉及推理和逻辑推断的任务,用于评估语言模型在逻辑推理方面的能力。
- HellaSwag:用于评估语言模型(LM)能否理解具有挑战性的自然语言理解任务的指标。
- MMLU: Massive Multitask Language Understanding,评估LLM在多任务处理方面的表现能力。
- TruthfulQA:用于评估语言模型的知识和推理能力的问答(QA)基准
LLM Leaderboard
这是在收集资料过程中,发现的一些大模型排行榜, 通过不同的指标对比现在大模型的各种性能表现。
LLM Leaderboard 2024
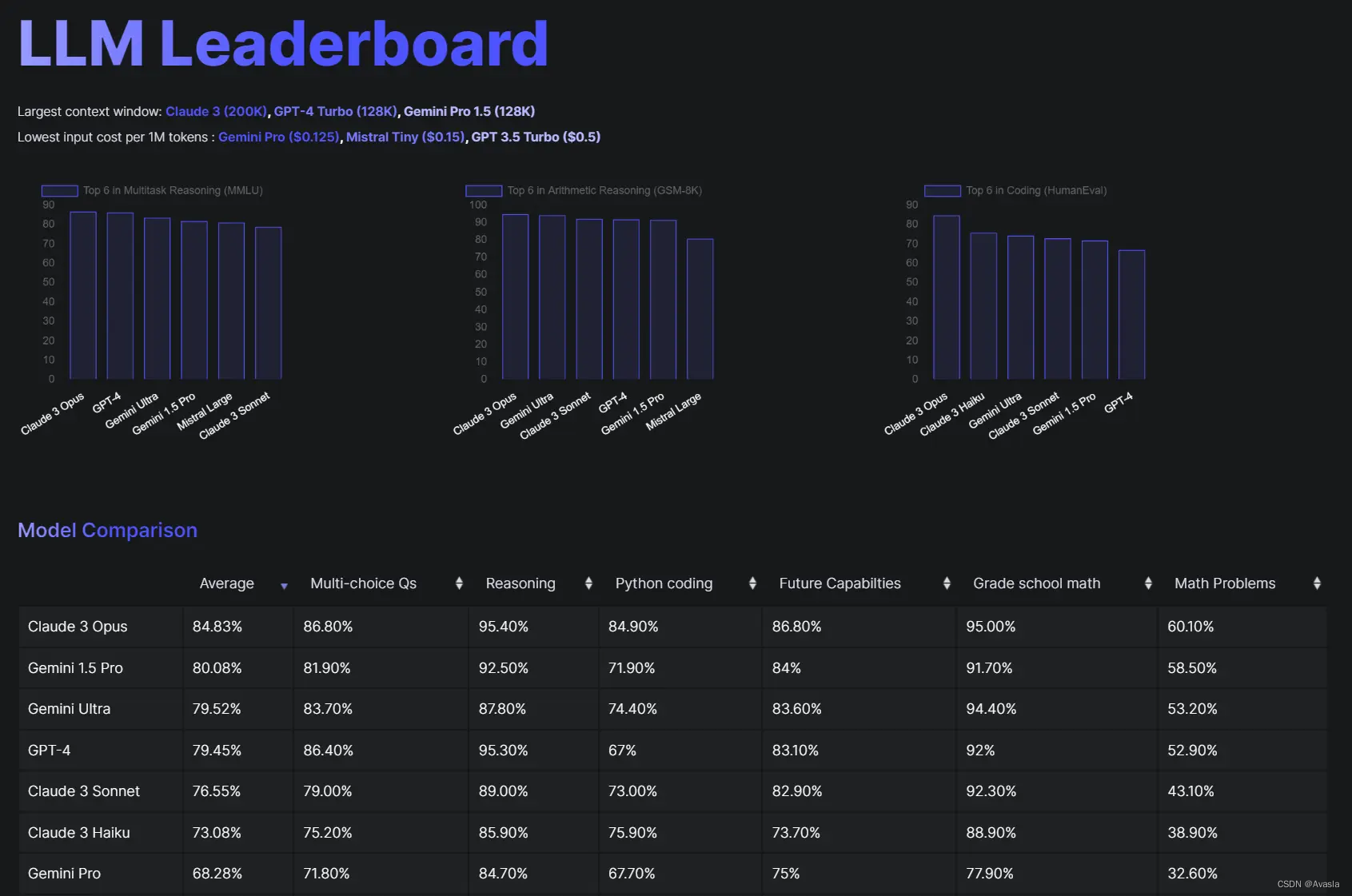
Open LLM Leaderboard - Hugging Face
![![[未命名 1-20240418160003018.webp]]](https://img-blog.csdnimg.cn/direct/32ed11bfdada429da11f6b0ee947038b.png)
CompassRank
![![[未命名 1-20240418155713975.webp]]](https://img-blog.csdnimg.cn/direct/dbf8256ae2684d758b6da1e3dc773a2e.png)
Arena Leaderboard
![![[未命名 1-20240418155507763.webp]]](https://img-blog.csdnimg.cn/direct/736ad43b552549c2a094ea23f837cc34.png)
总结
本文探讨了训练大型语言模型(LLMs)的过程步骤,从数据处理到模型评估和实际应用。LLMs在解决文本任务中发挥着重要作用,随着自然语言处理技术的进步,它们在日常工作和生活中的应用也日益广泛。
在查阅资料的过程中,我们也发现了各种教程、指南和代码示例,以及多样的评估指标和领域专用模型,如图片和视频生成模型,这表明了LLMs在不断进步和创新,其复杂性和多样性也在日益变化。
希望本文能够为读者提供一些有价值的信息和启发,激发大家对于LLMs和自然语言处理技术的兴趣和探索欲望。让我们共同期待着LLMs在未来的发展中发挥更大的作用,为我们的生活和工作带来更多便利和可能性。
参考文章链接
A Step-by-Step Guide to Training Your Own Large Language Models (LLMs)
What are Large Language Models(LLMs)?
Large language model - Wikipedia
Frameworks for Serving LLMs. A comprehensive guide into LLMs inference and serving | by Sergei Savvov | Jul, 2023 | Medium | Better Programming
Understanding LangChain - A Framework for LLM Applications
Evaluating Large Language Model (LLM) systems: Metrics, challenges, and best practices | by Jane Huang | Data Science at Microsoft | Mar, 2024 | Medium
An In-depth Guide to Benchmarking LLMs | Symbl.ai
LLM Benchmarks: MMLU, HellaSwag, BBH, and Beyond - Confident AI
LLM Benchmarks: Guide to Evaluating Language Models | Deepgram
How to Evaluate LLMs: A Complete Metric Framework - Microsoft Research
Evaluating Large Language Models
How to Evaluate LLMs? - Analytics Vidhya

