
- 1【武汉理工大学主办 | 连续九届实现EI和Scopus稳定检索!SPIE (ISSN: 0277-786X)独立出版】2024年第十届机械工程、材料和自动化技术国际会议(MMEAT 2024)
- 2微信小程序静默登录:用户无感的入口艺术
- 3Java最新java开源项目jeecgboot全解析,怒斩腾讯和阿里的Offer_jeecg-boot csdn
- 4【小知识】CVPR会议_cvprworkshop和cvpr一样吗
- 5Maven的settings.xml配置详解_maven setting配置
- 6【AI 大模型】提示工程 ③ ( 提示词用法 | 提示词 Prompt 构成 | 提示词位置对权重的影响 | 提示词 Prompt 调优 | OpenAI 的 API 类型 | 提示词重要参数说明 )_ai有效提问词的文献有哪些
- 7Python程序设计实例 | 学生管理数据库系统的开发_数据库管理系统开发
- 8vue+lodop实现web端打印功能_clodop vue
- 9Multi-Concept Customization of Text-to-Image Diffusion # 论文阅读
- 10Midjourney该怎么用?从零基础到落地实践_midjourney下载值不值
丝滑小连招,部署 Vision Language 模型_miniinternvl
赞
踩
LMDeploy 自 v0.4.2 开始,支持 VL 模型 4bit 量化及推理部署。包括:
-
llava
-
internvl
-
internlm-xcomposer2
-
qwen-vl
-
deepseek-vl
-
minigemini
-
yi-vl
LMDeploy 项目链接
https://github.com/InternLM/lmdeploy
(文末点击阅读原文可直达,觉得好有欢迎点亮小星星)
以上模型,除了 InternLM-XComposer2 外均采用 Llama 模型结构作为语言模块,而视觉模块则各有不同。LMDeploy 采用 AWQ 算法量化语言模块,并用 TurboMind 引擎进行加速,而视觉部分仍采用原有的 Transformers 对图片进行 encode。InternLM-XComposer2 模型的语言模块,使用了 Plora 对原本的 Llama 模型进行了微调。LMDeploy 在进行量化时,略过了 Plora 部分的权重,推理时 Plora 保持 w16a16 计算不变。我们挑选了 3 款模型,在 MMBench 数据集上,评测并对比了其量化前后的模型精度。如下表所示,LLaVA、InternVL-Chat 量化后,精度几乎无损,InternLM-XComposer2 略有损失。
| model | llava-v1.6-vicuna-7b | InternVL-Chat-V1-5 | xcomposer2-vl-7b |
| Average score | 55.8 | 78.8 | 77.3 |
| Average score (AWQ) | 55.3 | 79.2 | 74.7 |
LMDeploy 除了支持 w4a16 的计算外,也支持 kv cache 的在线量化。我们对 Mini-InternVL-Chat-2B-V1-5 模型的不同量化方式,在 MMBench 数据集上进行了精度测试。
| Mini-InternVL-Chat-2B-V1-5 | w16a16 | w4a16 | w4a16 kv8 | w4a16 kv4 |
| Average score | 64.1 | 62.9 | 63.1 | 61.6 |
可以看到,即使采用最激进的 w4a16 kv4 量化方案,精度掉点仍然在可接受范围。当然,用户可以根据实际情况自己选择需要的量化配置,在显存,吞吐量和精度间取得平衡。接下来,我们将以 Mini-InternVL-Chat-2B-V1-5 模型为例,介绍如何用 LMDeploy 丝滑部署 VL 模型。
配置环境
LMDeploy 可以直接通过 pip 安装预编译包,或者源码安装。
- conda create -n lmdeploy python==3.10
- pip install lmdeploy
LMDeploy 的预编译包默认是基于 CUDA 12 编译的。如果需要在 CUDA 11+ 下安装 LMDeploy,请执行以下命令:
- export LMDEPLOY_VERSION=0.4.2
- export PYTHON_VERSION=310
- pip install https://github.com/InternLM/lmdeploy/releases/download/v${LMDEPLOY_VERSION}/lmdeploy-${LMDEPLOY_VERSION}+cu118-cp${PYTHON_VERSION}-cp${PYTHON_VERSION}-manylinux2014_x86_64.whl --extra-index-url https://download.pytorch.org/whl/cu118
量化模型
LMDeploy 的推理引擎 TurboMind 提供了非常高效的 4bit 推理 CUDA kernel,性能是 FP16 的 2.4 倍以上。它支持以下 NVIDIA 显卡:
-
图灵架构(sm75):20系列、T4
-
安培架构(sm80,sm86):30系列、A10、A16、A30、A100
-
Ada Lovelace架构(sm89):40 系列
用户可以一行命令量化一个 VL 模型,以 Mini-InternVL-Chat-2B-V1-5 为例:
- export HF_MODEL=OpenGVLab/Mini-InternVL-Chat-2B-V1-5
- export WORK_DIR=Mini-InternVL-Chat-2B-V1-5-4bit
-
- lmdeploy lite auto_awq \
- $HF_MODEL \
- --calib-dataset 'ptb' \
- --calib-samples 128 \
- --calib-seqlen 2048 \
- --w-bits 4 \
- --w-group-size 128 \
- --batch-size 1 \
- --search-scale False \
- --work-dir $WORK_DIR
需要注意的是,LMDeploy 的量化是将 Llama 模型逐层量化的,每层量化前都会进行一次从 CPU 加载到 GPU,量化完成后又将其从 GPU 卸载回 CPU。这样量化过程的显存压力小。此外,每层的量化都会按 --batch-size 个批次大小进行,这样可以进一步减小显存占用。但是相应的,量化的时间将会变长。如果 GPU 显存充足,可以将 --batch-size 设置大一些。最后,如果量化模型的精度不如预期,可以开启 --search-scale。如果不开启,默认会按 smooth quant 的方式进行量化。
pipeline
LMDeploy 把视觉-语言模型(VLM)复杂的推理过程,抽象为简单好用的 pipeline。它的用法与大语言模型(LLM)推理 pipeline 类似。
- from lmdeploy import pipeline
- from lmdeploy.messages import TurbomindEngineConfig
- from lmdeploy.vl import load_image
-
- model = 'Mini-InternVL-Chat-2B-V1-5-4bit'
- image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
- backend_config = TurbomindEngineConfig(model_format='awq')
- pipe = pipeline(model, backend_config=backend_config, log_level='INFO')
-
- response = pipe(('describe this image', image))
- print(response)
上面的例子,使用我们量化好的 Mini-InternVL-Chat-2B-V1-5-4bit 模型,可以发现模型成功识别了图片中的老虎并给出描述。如果是单机多卡的用户,希望能更充分地利用硬件资源,可以参考下面的例子使用张量并行功能。
- from lmdeploy import pipeline
- from lmdeploy.messages import TurbomindEngineConfig
- from lmdeploy.vl import load_image
-
- model = 'Mini-InternVL-Chat-2B-V1-5-4bit'
- image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
- backend_config = TurbomindEngineConfig(model_format='awq', tp=2)
- pipe = pipeline(model, backend_config=backend_config, log_level='INFO')
-
- response = pipe(('describe this image', image))
- print(response)
这里,语言模型和视觉模型都会被均匀地分到两块卡上进行推理。关于 pipline 的更多的用法,可以参考 LMDeploy 的文档。
服务化
使用 LMDeploy cli 工具一行命令启动 VL 模型的服务:
lmdeploy serve api_server Mini-InternVL-Chat-2B-V1-5-4bit --max-batch-size 256 --vision-max-batch-size 16这里,--max-batch-size 是 server 端 LLM 部分最大的并发数,而 --vision-max-batch-size 是 server 端 vision 部分的最大并发数。这就意味着,假如每个 client 端的请求都带有一个图片,那么 server 端的实际运行的最大并发数将是 --vision-max-batch-size。更多的服务化相关的使用技巧,可以参考 LMDeploy 的服务化的文档。
Benchmark
在 A100-SMX4-80G 显卡上部署一个 Mini-InternVL-Chat-2B-V1-5 的量化模型,实际测试模型每秒生成的 token 数,结果绘制成下图。图中的每个请求均带有一张分辨率 512*512 的图像。
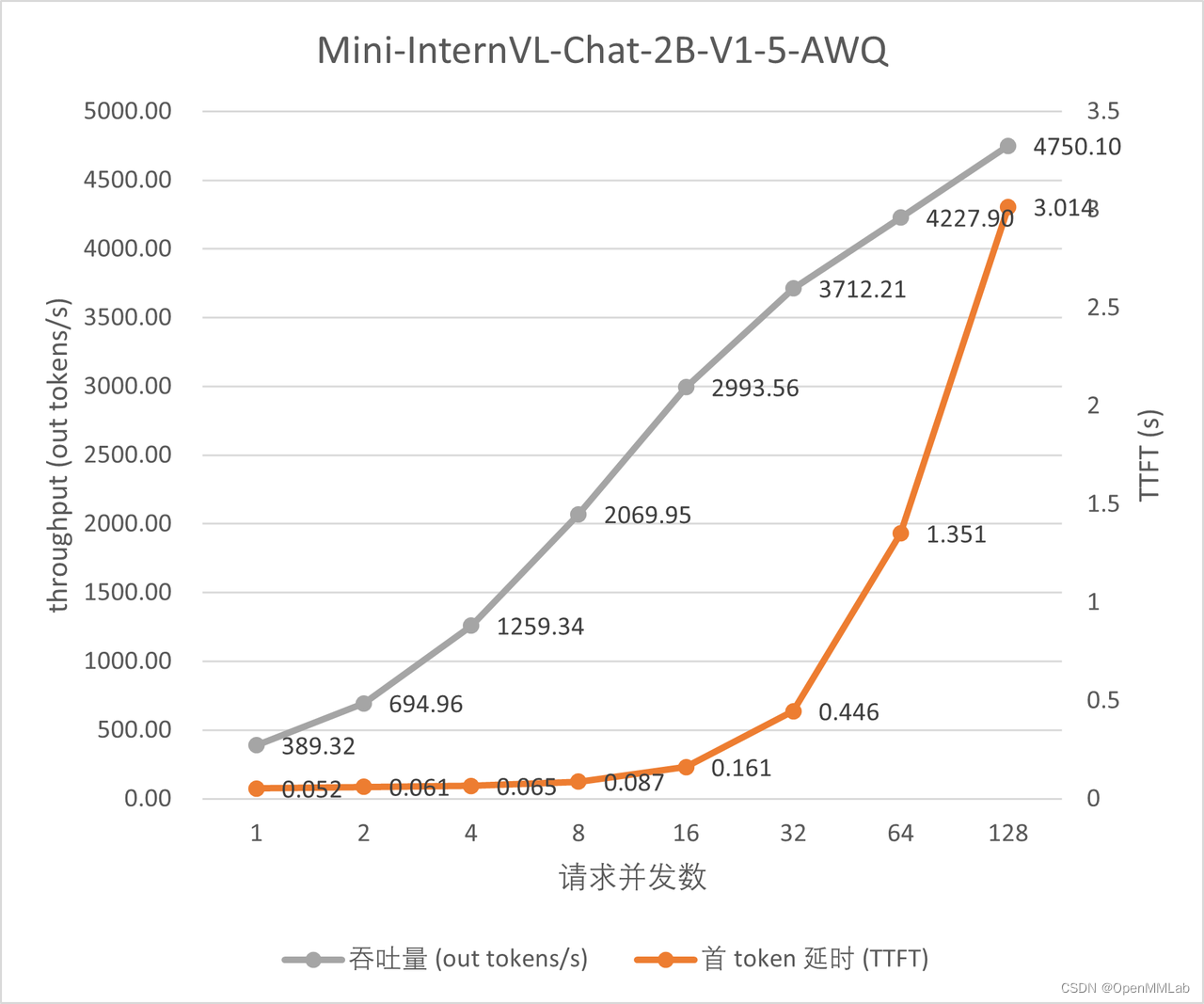
通过上图可以看到,模型在并发度 16 以后,吞吐量(out tokens/s) 增长变缓了。同时随着并发数进一步提高,首个 token 延时急剧上升,这是因为服务启动时,vision模型推理的batch size 配置为 16。当请求并发超过它时,后到的请求不得不等待先到的请求处理完,才能接着被处理。所以,用户需要根据自己的实际使用情况合理分配 --max-batch-size和--vision-max-batch-size两个参数的大小。此外,我们使用了相同的方式,分别测试了模型量化前后的吞吐量。两者的对比结果如下图所示:

通过上面的折线图可以看到,量化后的模型拥有更高的吞吐量。综合上面的数据,用户可以考虑通过量化工具将模型量化后进行部署,服务将具有更好的推理性能。

