
热门标签
热门文章
- 1python web 前后端分离_前后端分离篇
- 2uni-app小程序提示信息(信息提示)_uniapp提示信息
- 3探索深度感知新境界:MiDaS——跨数据集零样本迁移的鲁棒单目深度估计
- 4Edge-TTS:微软推出的,免费、开源、支持多种中文语音语色的AI工具_edge tts
- 5数据结构-----算法复杂度(大O表示法)_o(n!)
- 6hive优化:让一个MR做更多的事情_如何让hive任务只跑一个mr
- 7AI深入应用,生态越加开放,开发者的机会在哪里?
- 8前端npm项目启动报错:error:0308010C:digital envelope routines::unsupported_angular前端工程运行npm run dev提示:0308010c:digital envelo
- 9Postman接口测试之断言
- 10python建立窗口并美化_Python GUI教程(十六):在PyQt5中美化和装扮图形界面
当前位置: article > 正文
Qwen2来了_qwen2下载
作者:人工智能uu | 2024-07-31 10:19:33
赞
踩
qwen2下载
变化
1、增大了上下文长度支持,Qwen2-72B-Instruct支持128K tokens,并且处理完美
2、代码和数学能力显著提升
3、多个评测基准上的领先表现
4、中英之外增加了27种语言相关的高质量数据
5、开源了Agent解决方案,用于高效处理 1000K tokens的上下文
「大量精力:如何扩展多语言预训练 和指令微调数据的规模并提升质量,提升模型的多语言能力」
Agent 应用
核心:通过分块+能处理8K上下文的LLM 不断总结归纳,来解决1000K上下文的理解任务。

方案:构建三个级别的Agent,这一部分建议详读,很不错。
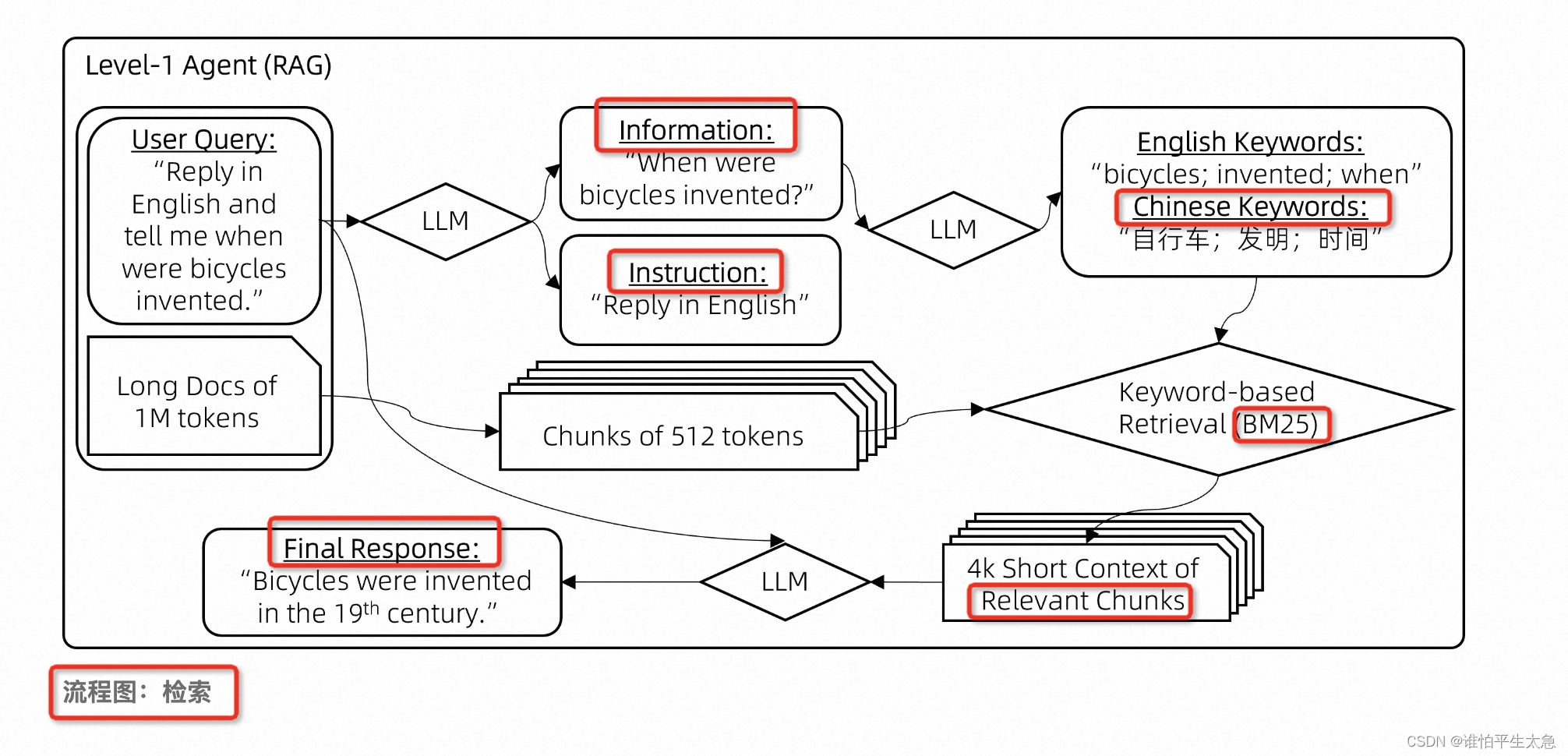
级别一:先用LLM来对user query进行“信息”和“指令”的抽取,然后用LLM对信息进行翻译,多语言的角度用BM25来提取相关块…
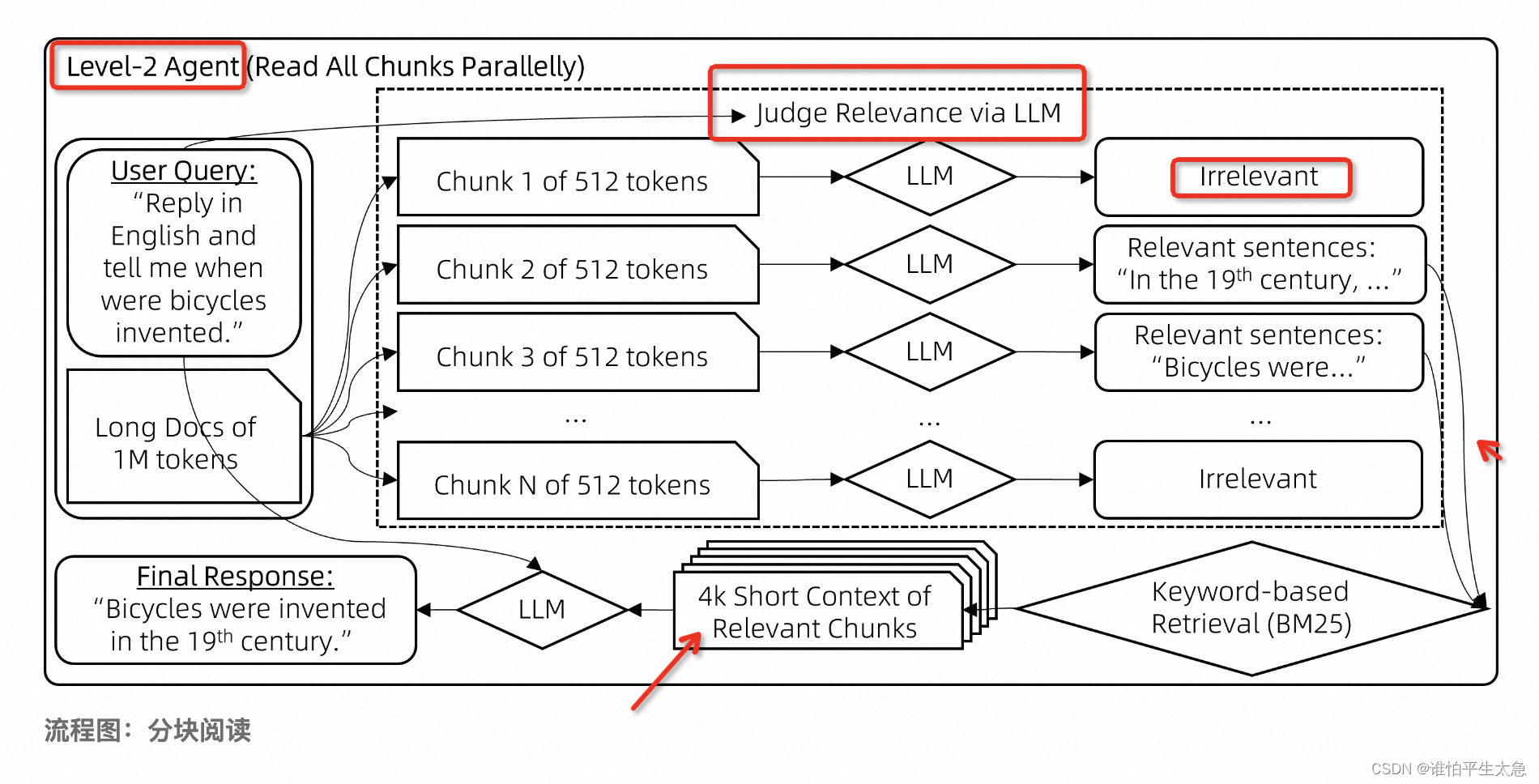
级别二:为了减少 因关键词重叠度不足导致的 上下文错过 的问题,用LLM来判断块和query的相关度,用相关块的相关句子 而不是 query当中的 关键词来检索 最相关的块。
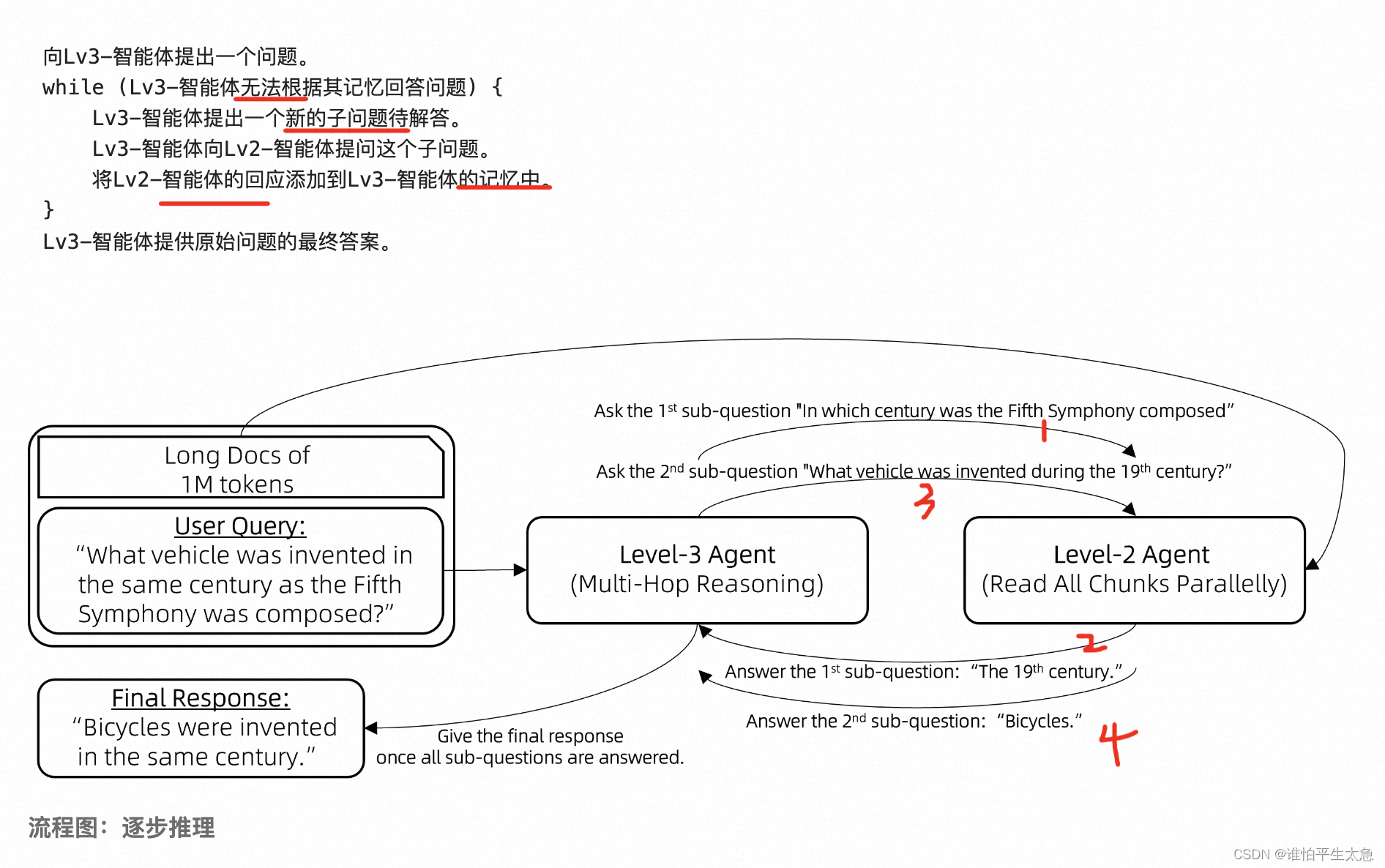
级别三:另外训练一个用于规划的LLM,用级别二的llm作为tool,实现逐级推理
基础
GQA
作用:推理加速、降低显存占用
tie embedding
场景:针对7B以下的小模型,比如0.5B、1.5B的
作用:让输入和输出层共享参数,增加非embedding参数的占比
长文本处理
YARN
Dual Chunk Attention
开源生态

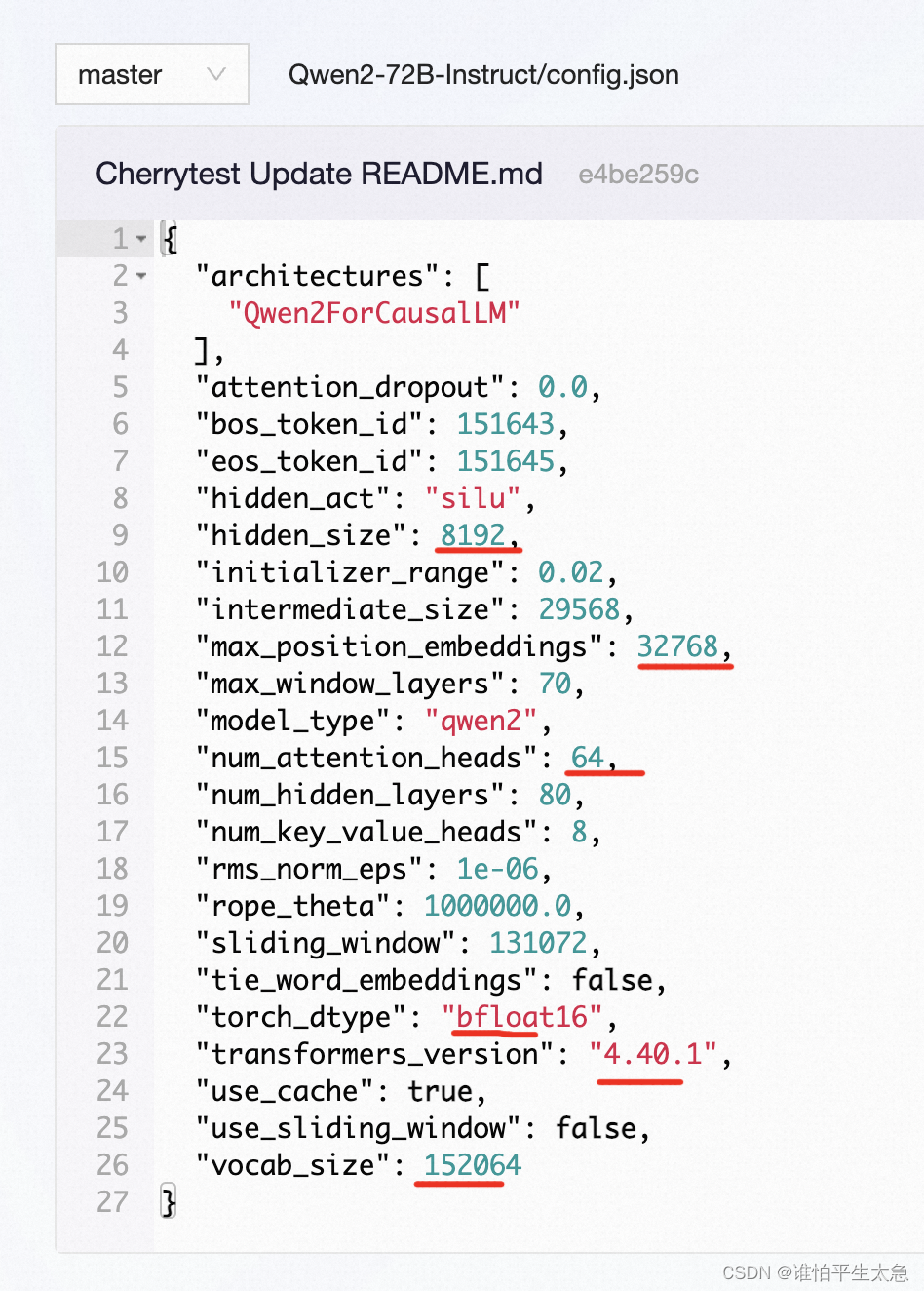
一些数字
期待
期待QwenVL开源版本的更新
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/人工智能uu/article/detail/908408
推荐阅读
相关标签

