
- 1Ubuntu服务器更改远程端口号的方法_ubuntu网络port怎么设置
- 2CloudFlare域名管理系统_cloudflare批量管理
- 3php论坛源代码,php论坛源代码下载
- 4AutoCompress: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates
- 5Strongswan与Andriod野蛮模式L2TPoverIPsec对接有时候不成功。_strongswan ipsec不生效
- 6算法32:环形链表(有双指针)_求环形链表的节点数java
- 7idea2018项目导入2020.1idea依赖包失败的解决方法_getloadedimportedassetsandartifactids called with
- 8Python爬虫:代理ip电商数据实战
- 9聚类分析之 K均值_k均值聚类适用于什么样的数据
- 10python uiautomator2 安装及使用_python uiautomatic2 使用方法
统一多场景自动编译加速——支持动态shape场景,一套架构搞定训推需求
赞
踩

为了让飞桨开发者们掌握第一手技术动态、让企业落地更加高效,飞桨官方在7月至10月特设《飞桨框架3.0全面解析》系列技术稿件及直播课程。技术解析加代码实战,带大家掌握包括核心框架、分布式计算、产业级大模型套件及低代码工具、前沿科学计算技术案例等多个方面的框架技术及大模型训推优化经验。本文是该系列第三篇技术解读,文末附对应直播课程详情。
近些年,在深度学习场景如何更好的借助编译器技术来提升任务表现变得越来越重要,在工业界和学术界均有大量基于编译器技术的探索和落地。为什么深度学习场景非常依赖编译器技术,整体趋势上的有3大原因:
1)硬件发展趋势:结合硬件发展历史和技术演进特点,算力发展速度远大于访存性能、CPU性能和总线带宽;其中访存性能影响访存密集型算子(norm类,activation等)性能,CPU性能和总线带宽影响调度性能。通过手工融合的方式,覆盖场景较窄,优化成本较高。基于编译器的自动融合的通用优化技术,将多个算子融合成一个大算子,通过减少访存量和算子数量,能够大幅提升模型端到端性能,编译器技术会成为深度学习框架标配组件。
2)模型发展趋势:模型结构存在多样性的特点,多样性的需求非常依赖编译器的通用优化来降低整体的研发成本。虽然在文本领域模型主流结构趋同,但是Transformer架构的推理成本较高,研究者也在积极探索如Mamba等结构,从模型结构角度来降低推理成本;在多模态、自动驾驶和科学计算等领域,模型结构还在探索中。
3)多硬件优化:当前市面存在有多款硬件,不同的硬件平台有不同的特性和优化需求,每个硬件均需要投入大量的人力进行优化,借助编译器技术,理论上仅需实现新硬件 IR 层面的对接,以及相应的硬件 IR 优化策略就能完成与深度学习框架的对接,相比于实现几百个硬件 Kernel,开发的工作量会大幅减少。
让我们通过一个实例来阐释针对模型多样性的趋势,自动融合优化的好处。我们以 Llama 模型中经常使用的 RMS Normalization (Root Mean Square Layer Normalization)为例,其计算公式相对简单明了。
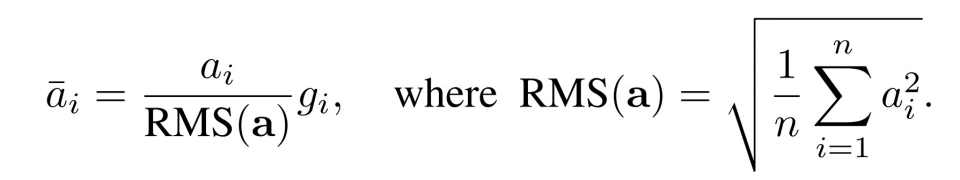
RMS Norm 计算公式
假设我们需要是实现 RMS Normalization 的计算,最简单的办法是,我们可以使用飞桨框架提供的张量运算开发接口,调用平方、求和、除法、开根号等操作来完成,代码如下:
- class RMSNorm(paddle.nn.Layer):
- def __init__(self):
- super().__init__()
- self.variance_epsilon = 1e-6
- self.size = 768
- self.weight = paddle.create_parameter(
- shape=[self.size],
- dtype=paddle.get_default_dtype(),
- default_initializer=nn.initializer.Constant(1.0),
- )
-
- def forward(self, x):
- variance = x.pow(2).mean(-1, keepdim=True)
- x = paddle.rsqrt(variance + self.variance_epsilon) * x
- return x * self.weight
上述代码开发简单,但是性能较差,且显存占比较多;开发者可以实现一个 FusedRMSNorm的实现,但是对于开发者要求更高,成本也更高。
借助神经网络编译器自动融合优化技术,我们能够在维持高度灵活性基础上,大幅降低了用户的优化成本,且实现性能的显著提升。以下 A100 平台上 RMSNorm 算子的性能测试结果便是一个明证:相较于采用 Python 开发接口组合实现的方式,经过编译优化后的算子运行速度提升了 4 倍;即便与手动算子融合的方式相比,也实现了 14%的性能提升。这一成果充分展示了飞桨框架在保证灵活性基础上,也低成本的取得了较好的性能表现。
 飞桨神经网络编译器(CINN)
飞桨神经网络编译器(CINN)
神经网络编译器(也称为深度学习编译器)是一种专门为深度学习模型优化和部署而设计的工具,用于提高模型的计算效率、降低内存占用、加速训练推理过程等。其功能是将高层次的深度学习模型转换为低层次的、高效的、底层硬件可执行的代码。简单来说,深度学习编译器在深度学习框架和底层硬件之间充当了“翻译”的角色,能够将用户定义的神经网络模型描述转化为底层硬件能够理解和执行的指令。编译器在实现这种转换的过程中,应用了一系列优化技术,以提高模型在各种硬件平台上(包括CPU、GPU等硬件)的执行效率。

飞桨神经网络编译器架构图
飞桨神经网络编译器(CINN, Compiler Infrastructure for Neural Networks)整体架构如上图所示,大体可以分为两大模块,分别是编译器前端和编译器后端。飞桨神经网络编译器充分考虑训练和推理场景的需求,一套架构同时满足训推需求。为了满足动态shape场景,设计了符号推导模块,高效处理动态shape问题。执行体系充分考虑和算子库、执行器高效整合,框架原生支持编译器体系,调度性能极致。
编译器前端:
编译器前端主要是基于PIR(Paddle IR)实现的图层变换和优化,包含组合算子拆分、图优化、算子融合、维度推导等Pass组件,核心目的是通过图层变换,方便后端做更加极致的性能优化。同时在算子融合策略中,还包含一个关键的功能,是保证融合结果的正确性。
编译器后端:
编译器后端是将PIR中算子形式,“翻译”为一个后端可以融合优化的表达式,基于该表达式,进行schedule的变换,来达到最优的性能;最后将优化后的表达式“翻译”为特定硬件可执行的代码,并进行编译,生成可以被调用的“函数”指针。
最终自动生成的“函数”指针,会交给框架统一的执行器进行调度,保证一体的设计,并保障极致调度性能。
 CINN模块设计
CINN模块设计
下面将详细介绍编译器各个层的工作。
 编译器前端
编译器前端
一般来说编译器前端核心功能并进行图级别的优化,CINN 作为飞桨框架原生的编译器,可以直接使用飞桨框架提供的模型加载和中间表示(Paddle IR,简称 PIR)组件,因此 CINN 前端的主要功能是基于 PIR 进行图层级别的优化,并对子图进行划分为后端高性能 Kernel 代码生成提供支持。CINN 前端关键的流程可分为三部分:
1. 组合算子拆分
飞桨框架中将算子划分为基础算子(也称作原子算子,从性能和模型收敛正确性的角度,该类算子不适合进一步拆分)和非基础算子(非基础算子可以通过基础算子组合实现)两大类,由于非基础算子数量较多,会大幅增加编译器融合优化的难度,因此我们将组合算子拆分为等价的基础算子组合,借助编译器的自动融合技术可大幅提升性能的可优化空间。
经过组合算子拆分之后,在训练场景,由于有反向逻辑的存在,需要将前向算子的一些临时变量,保留到反向阶段,这会增加前向阶段Kernel输出和反向阶段Kernel输入的个数,通过使用重计算策略可以减少临时变量的输出和输入的个数,能够显著提升端到端的性能。
2. 图优化 Pass
在计算图层级进行 PIR 的 Pass 优化,常见的图优化 Pass 包括:常量折叠、死代码消除(DCE)、公共子表达式消除(CSE)、冗余算子消除、算子计算合并等。
3. 算子融合
算子融合是编译器前端非常重要的一个功能,主要是将多个算子打包到一个子图中(对应为一个 FusionOp),交给编译器后端生成一个高效的硬件相关计算 Kernel。算子融合的本质是通过 IO 优化加速访存密集算子,如果我们将两个连续 Kernel 合并为一个 Kernel 调用,我们会减少中间变量的读写开销,因此在访存密集型的 2 个 Op 上,融合可以获取更高的性能。举个例子,如下图:
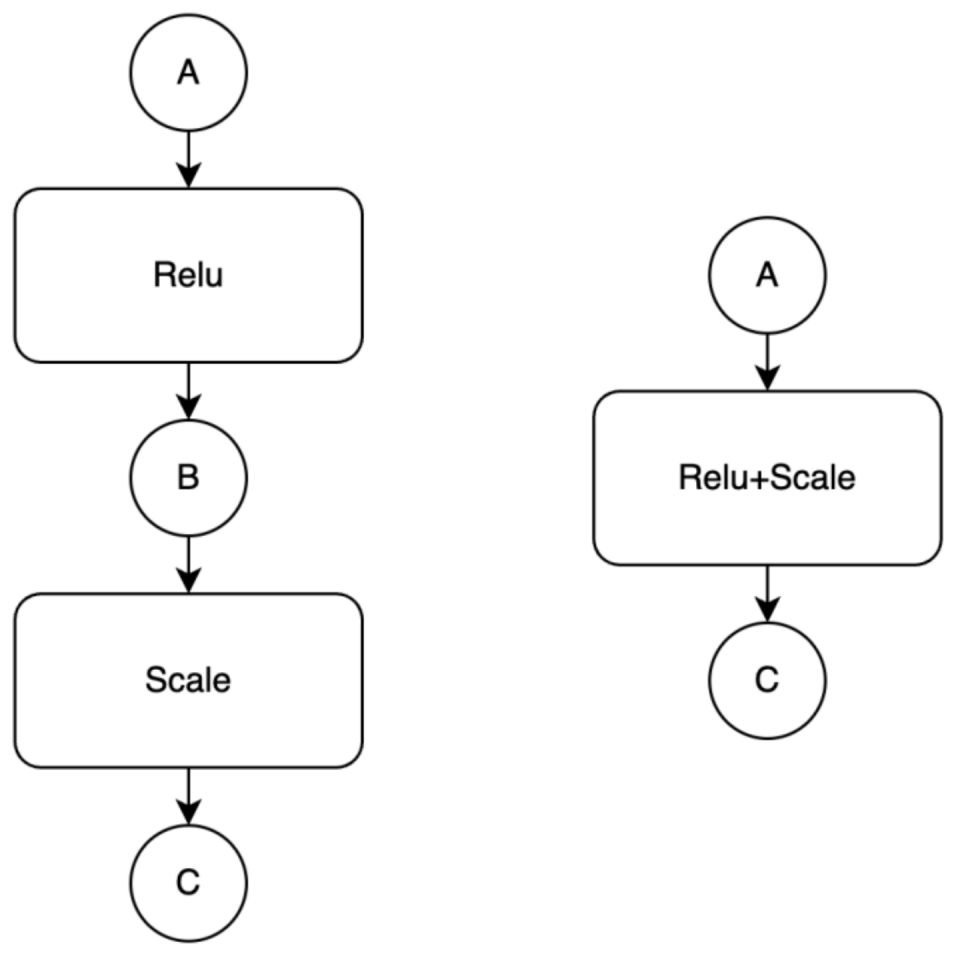
算子融合示例
我们有两个算子 Relu 和 Scale,因为两个算子都是 IO 密集型算子(计算复杂度不高)。正常情况下我们需要读取 A 和 B 一次,写 B 和 C 一次。但是对于融合之后的 Kernel(右图)而言,我们只需要读取 A 和写 C 一次,这样我们通过算子融合可以取得更少的访存次数,在 IO 密集算子而言,可以极大提高性能。具体的算子融合策略实现非常复杂,这里不做展开介绍,感兴趣的读者可以阅读相关源码(地址请见文末)。
融合正确性保障
编译器期望通过尽可能大粒度的算子融合来保障端到端性能,但是大粒度融合强依赖正确性的保证。通过将当前可融合的算子分为两大类:TrivialOp和ReduceOp,通过理论论证TrivialOp和ReduceOp的融合正确性,来保障最终的正确性。
T+T融合:使用 inline 代换可以实现 T * T 的融合
T+R融合:使用 inline 代换来实现实现T+R的融合
R+R融合:融合场景较复杂的一个部分,为了解决 inline 不封闭性质,无法通过维护一个Op来包含所有的 ReduceOp + ReduceOp的信息,所以需要额外定义一个新的结构ReduceTree来实现封闭性,然后定义一个Lower操作在 ReduceTree上生成一个融合的Op Kernel代码,就可以实现多个Reduce的融合
R+T融合:是否需要融合需要考虑性能,因为 Reduce的重计算开销太大,仅融合 T 的输出尺寸比 R 的输入尺寸小的
通过这种融合正确性的保障,我们可以在保障正确性的前提下,最大程度保障融合kernel性能,下面是我们在一些子图上,对比和PyTorch 融合粒度的对比,CINN能够融合为一个Kernel。
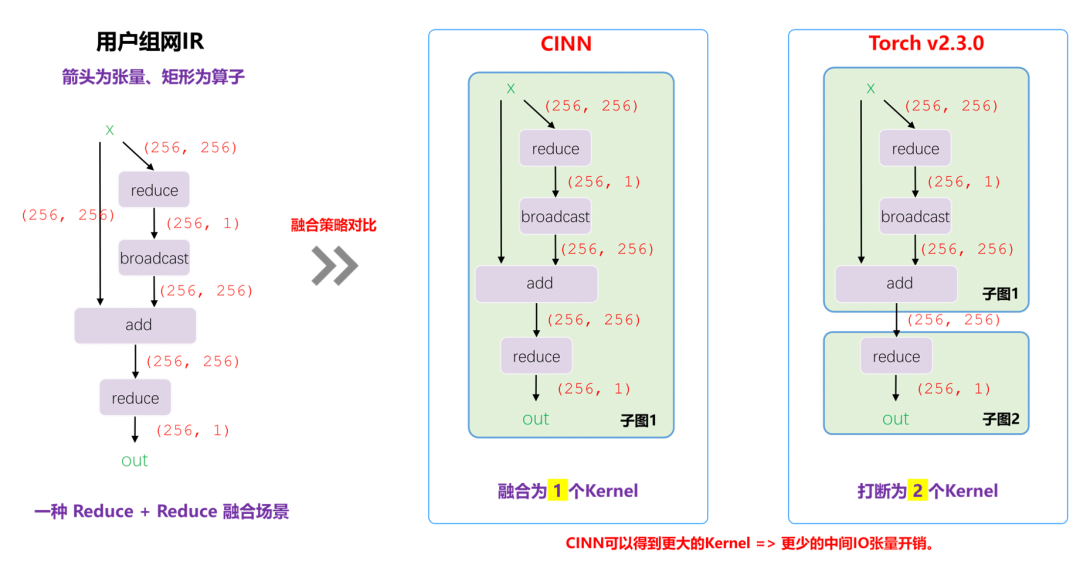 算子融合对比示意图
算子融合对比示意图
4. 维度推导
维度推导是当网络中存在动态shape时,在之前的静态图模式下,常用-1来表示,但是这种-1形式,有效信息太少,无法有效支持后端做性能优化,因此需要有一个完整的维度推导机制,提供尽可能多的确定信息,来提升动态shape下kernel的性能。
对于维度推导,有两个关键的模块,
算子层维度推导:对于特定的算子,给定输入的维度信息,可以推导出输出的维度信息,即可在整个网络中完成维度的推导
维度约束化简:当完成维度的推导之后,网络中可能存在多个符号维度信息,在一个合理的网络中,部分算子是存在一些约束信息,比如concat算子,除concat的维度之外,要求其余的维度信息完全相等,通过挖掘这类算子的约束信息,能够对符号进行化简。
下面是一个简单网络进行维度推导和约束化简的示意图。
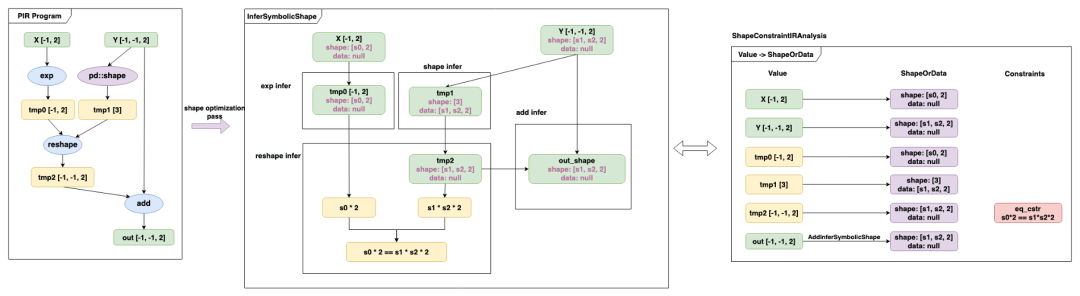
 编译器后端
编译器后端
编译器后端主要负责将前端处理后的 IR 转换为目标硬件可执行的代码或硬件描述。主要功能包括基于硬件特性的 IR 优化、高效内存管理和代码生成等。下面将详细介绍各个模块。
1. CINN AST IR
AST IR 打印示例:
- ScheduleBlock(root)
- {
- serial for (i, 0, 32)
- {
- serial for (j_0, 0, 64)
- {
- serial for (j_1, 0, 128)
- {
- ScheduleBlock(A)
- {
- vi, vj = axis.bind(i, j_0 * 64 + j_1) // tensor 下标与循环变量的仿射变换
- A[vi, vj] = X[vi, vj] * 2
- }
- }
- }
- }
- }

CINN AST IR 中包含了以下信息,但集合和映射并不显示使用某种数据结构进行存储。
集合:语句实例 & 内存单元
映射:
访存关系:语句实例 <---> 内存单元
依赖关系:语句实例 <---> 语句实例
执行顺序:语句实例 -----> 语句实例
执行顺序 = 语句实例的先后关系
语句实例集合范围 = 循环边界 + 循环步长 ------ 循环构成一个带约束的整数空间,即迭代空间,迭代空间决定了语句实例,语句实例充满了迭代空间。
2. 基于 AST IR 的 Schedule
Schedule 为定义在 CINN AST IR 上的优化策略,常见的 Schedule 包括:LoopAlignment, Tile, Inline, Vectorize, Unroll 等。
以一个组合算子为例模拟可能的 AST 变换过程:
[S1, S2, 1024] ==E=> [S1, S2, 1024] ==R=> [S1, S2] ==E=> [S1, S2] ==B=> [S1, S2, 1024] ==E=> [S1, S2, 1024]
(1) LowerToAst 得到的结果
- // Elemenwise-1
- serial for (i, 0, S1)
- serial for (j, 0, S2)
- serial for (k, 0, 1024)
- ScheduleBlock(A)
- vi, vj, vk = axis.bind(i, j, k)
- A[vi, vj, vk] = X[vi, vj, vk] * 2
- // Elemenwise-2
- serial for (i, 0, S1)
- serial for (j, 0, S2)
- serial for (k, 0, 1024)
- ScheduleBlock(B)
- vi, vj, vk = axis.bind(i, j, k)
- B[vi, vj, vk] = A[vi, vj, vk] + 1
- // Reduce-1
- serial for (i, 0, S1)
- serial for (j, 0, S2)
- ScheduleBlock(C__reduce_init)
- vi, vj = axis.bind(i, j)
- C_init[vi, vj] = 0
- serial for (i, 0, S1)
- serial for (j, 0, S2)
- serial for (k, 0, 1024) // Reduce
- ScheduleBlock(C)
- vi, vj, vk = axis.bind(i, j, k)
- C[vi, vj] = C[vi, vj] + B[vi, vj, vk]
- // Elemenwise-3
- serial for (i, 0, S1)
- serial for (j, 0, S2)
- ScheduleBlock(D)
- vi, vj = axis.bind(i, j)
- D[vi, vj] = C[vi, vj] * 2
- // Broadcast-1
- serial for (i, 0, S1)
- serial for (j, 0, S2)
- serial for (k, 0, 1024) // Broadcast
- ScheduleBlock(E)
- vi, vj, vk = axis.bind(i, j, k)
- E[vi, vj, vk] = D[vi, vj]
- // Elemenwise-4
- serial for (i, 0, S1)
- serial for (j, 0, S2)
- serial for (k, 0, 1024)
- ScheduleBlock(F)
- vi, vj, vk = axis.bind(i, j, k)
- F[vi, vj, vk] = E[vi, vj, vk] + 1
(2) 迭代空间对齐
- // 所有 ScheduleBlock 的 loop nest 都变为以下 2 种格式中的一种
- // 1
- serial for (sp, 0, S1 * S2) // pure_spatial_iter
- serial for (rb, 0, 1024) // impure_spatial_iter
- ScheduleBlock(XXX)
- vsp1, vsp2, vrb = axis.bind(sp / S2, sp % S2, rb)
- XXX = XXXXXX
- // 2
- serial for (sp, 0, S1 * S2) // pure_spatial_iter
- ScheduleBlock(XXX)
- vsp1, vsp2 = axis.bind(sp / S2, sp % S2)
- XXX = XXXXXX
(3) Tile: 对所有 ScheduleBlock 的 loop nest 做相同的 Tile
(4) ComputeInline
- // 例如 ScheduleBlock(A) inline 到 ScheduleBlock(B)
- serial for (sp1, 0, S1 * S2 / 1024)
- serial for (sp2, 0, 16)
- serial for (sp3, 0, 64)
- serial for (rb1, 0, 32)
- serial for (rb2, 0, 32)
- ScheduleBlock(A)
- predicate = sp1 * 1024 + sp2 * 16 + sp3 < S1 * S2
- vsp1 = axis.bind((sp1 * 1024 + sp2 * 16 + sp3) / S2)
- vsp2 = axis.bind((sp1 * 1024 + sp2 * 16 + sp3) % S2)
- vrb = axis.bind(rb1 * 32 + rb2)
- B[vsp1, vsp2, vrb] = (X[vsp1, vsp2, vrb] * 2) + 1
(5) Reduce 优化: two step reduce & 绑定部分 reduce 轴到 cuda
(6) 循环融合: ComputeAt && SimpleComputeAt,融合外层循环乘积相同的循环,并且保证不破坏图级别依赖(规则负责)和元素级别依赖(原语负责)
(7) Bind Cuda 轴:在第二步中,所有 ScheduleBlock 对应的循环要 bind 到同一 Cuda 轴
- serial for (sp1, 0, S1 * S2 / 1024)
- CudaBind[BlockIdx.x] for (sp2, 0, 16)
- CudaBind[ThreadIdx.y] for (sp3, 0, 64)
- CudaBind[ThreadIdx.x] for (rb1, 0, 32)
- serial for (rb2, 0, 32)
- ScheduleBlock(XXX)
3. 自动调优
在业务场景中,模型结构具备多样化的特性,不同的shape和网络结构场景下,性能优化策略有差异,同时为了能够充分发挥硬件的特定,达到极致的性能表现,飞桨神经网络编译器引入自动调优模块。对于输入的shape,通过对shape的自动分析,生成最优的Schedule变换策略,达到最优的极限性能。
4. Kernel 代码生成与编译
Codegen 在 CINN IR AST 上做前序遍历,打印出对应硬件的指令,并通过硬件相对应的编译器(如 llvm、nvcc 等)进行编译得到可运行的函数指针,该指针会被封装到 `JitKernelOp`` 中用于后续执行器的解析执行。
a. 以函数定义为例子,cuda kernel func 和 x86 kernel func 的不同的是,cuda kernel func 会在函数名前增加__global__
针对 x86 硬件,转义ir::_LoweredFunc_的代码如下:
- void CodeGenC::Visit(const ir::_LoweredFunc_ *op) {
- PrintFunctionDeclaration(op); // 前序遍历继续转义函数名、函数参数等
- str_ += "\n";
- ...
- ...
- }
在 NV GPU 上的转义代码如下:
- void CodeGenCUDA_Dev::Visit(const ir::_LoweredFunc_ *op) {
- str_ += "__global__\n"; // 和 x86 的不同,增加 __global__
- PrintFunctionDeclaration(op); // 前序遍历继续转义函数名、函数参数等
- str_ += "\n";
- ...
- ...
- }
b. 在动态形状场景下,还会 codegen 出 infer shape function, infer shape function 的 CINN IR 会在 Bucket Lowering 中得到,转义过程复用的 x86 硬件的 codegen。infer shape kernel 如下:
- // infer shape 函数名字的组成:kernel_name + "infer_shape"
- // 函数参数:
- // kernel_args: 指针数组,和 kernel func args 一致
- // kernel_args_num: kernel_args 的长度
- // tensor_shape_args: 指针数组,存储输出 tensor 的 shape
- function fn_exp_0_subtract_0_infer_shape (kernel_args, kernel_args_num, tensor_shape_args)
- {
- int64 S0 = cinn_get_value_in_cuda_kernel_args(kernel_args, 2)
- {
- // CINN IR 暂时不支持数据索引的语法,暂时用函数调用实现,下面 2 条语句等价于
- // tensor_shape_args[0] = {S0, 256ll};
- // 即第 0 个出 tensor 的 shape 为{S0, 256ll};
- infer_shape_set_value(0, 0, S0, tensor_shape_args)
- infer_shape_set_value(0, 1, 256ll, tensor_shape_args)
- }
- }
5. Kernel运行
编译器生成的 Kernel 代码需要与深度学习框架执行器完成交互和集成才能最终运行起来,因此需要基于执行器的运行调度接口对编译器生成的 Kernel 进行封装。接入执行器后在运行时对于经过编译器处理的子图将执行 CINN 生成的 Kernel, 否则将执行常规的 PHI 算子 Kernel。
 总结
总结
通过飞桨神经网络编译器的自动优化,我们在生成式推理模型上相比基础版本,性能提升30%;在科学计算场景(Nvidia modulus)上, 基于飞桨提供的高阶自动微分及编译优化技术,对比PyTorch模型训练性能整体领先60%。
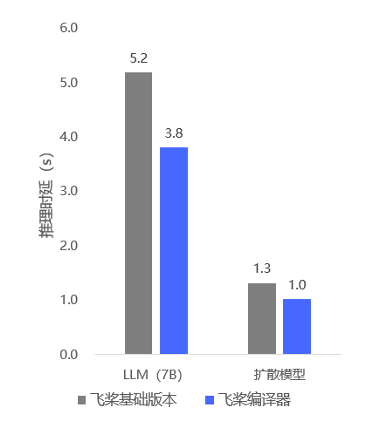
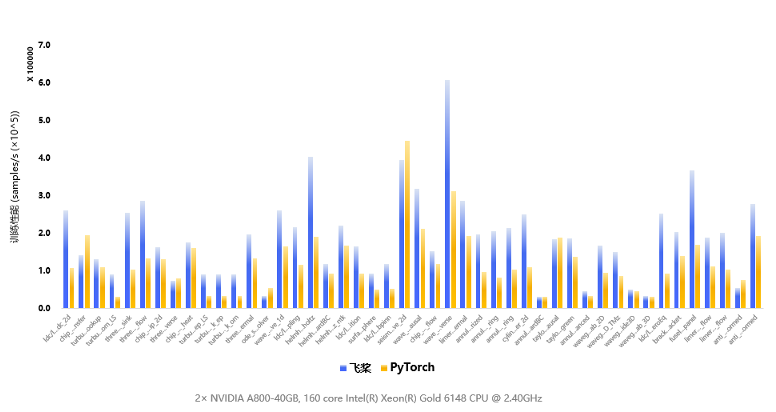
同时飞桨会持续在模型和多硬件场景上探索神经网络编译器的能力,借助这种前沿技术给更多的业务带来价值。
官方开放课程
7月至10月特设《飞桨框架3.0全面解析》直播课程,技术解析加代码实战,带大家掌握核心框架、分布式计算、产业级大模型套件及低代码工具、前沿科学计算技术案例等多个方面的框架技术及大模型训推优化经验,实打实地帮助大家用飞桨框架3.0在实际开发工作中提效创新!

飞桨动态早知道
为了让优秀的飞桨开发者们掌握第一手技术动态、让企业落地更加高效,根据大家的呼声安排史上最强飞桨技术大餐!涵盖飞桨框架3.0、低代码开发工具PaddleX、大语言模型开发套件PaddleNLP、多模态大模型开发套件PaddleMIX、典型产业场景下硬件适配技术等多个方向,一起来看吧!

拓展阅读
【算子融合策略源码】https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/cinn/hlir/dialect/operator/transforms/cinn_group_cluster_pass.cc
【前序技术稿件】
灵活可扩展的新一代IR技术——飞桨框架3.0基石技术深度解析(点击可查看)
飞桨新一代框架3.0:“动静统一自动并行、大模型训推一体”等新特性构筑大模型时代核心生产力(点击可查看)
【3.0-Beta 视频教程】
https://aistudio.baidu.com/course/introduce/31815
【3.0-Beta 官方文档】https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/index_cn.html
【开始使用】https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/overview_cn.html#jiukaishishiyong
【动转静 SOT 原理及使用】https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/sot_cn.html
【自动并行训练】https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/auto_parallel_cn.html
【神经网络编译器】https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/cinn_cn.html
【高阶自动微分功能】https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/higher_order_ad_cn.html
【PIR 基本概念和开发】https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/paddle_v3_features/paddle_ir_cn.html
【飞桨官网】https://www.paddlepaddle.org.cn/
【企业合作入口】https://paddle.wjx.cn/vm/m3sxpfF.aspx#




关注【飞桨PaddlePaddle】公众号
获取更多技术内容~

