
- 1大模型新贵还是绕不过云计算大佬
- 2video2frames - 把视频切割成一帧帧的图片_video2frame-frame2video
- 3简单的自我介绍_简历自我介绍怎么写 csdn
- 4数据结构:链表经典算法OJ题
- 5【TS】TypeScript声明文件:打通JavaScript和TypeScript的桥梁_.ts typescript
- 6如何将数据从Android传输到 iPhone 15 Pro/14/13?完整指南_coolmuster mobile transfer
- 7Python常用模块大全_python模块库大全
- 8electron vue 多开窗口,新开窗口_electron 多开browserwindow
- 9Servlet调用操作业务时显示请求的资源不可用_servlet请求资源不可用
- 10手把手带你从0开始搭建个人网站,小白可懂的保姆级教程_怎么创建网站免费建立个人网站
介绍 Whisper 模型_whisper模型
赞
踩
介绍 Whisper 模型
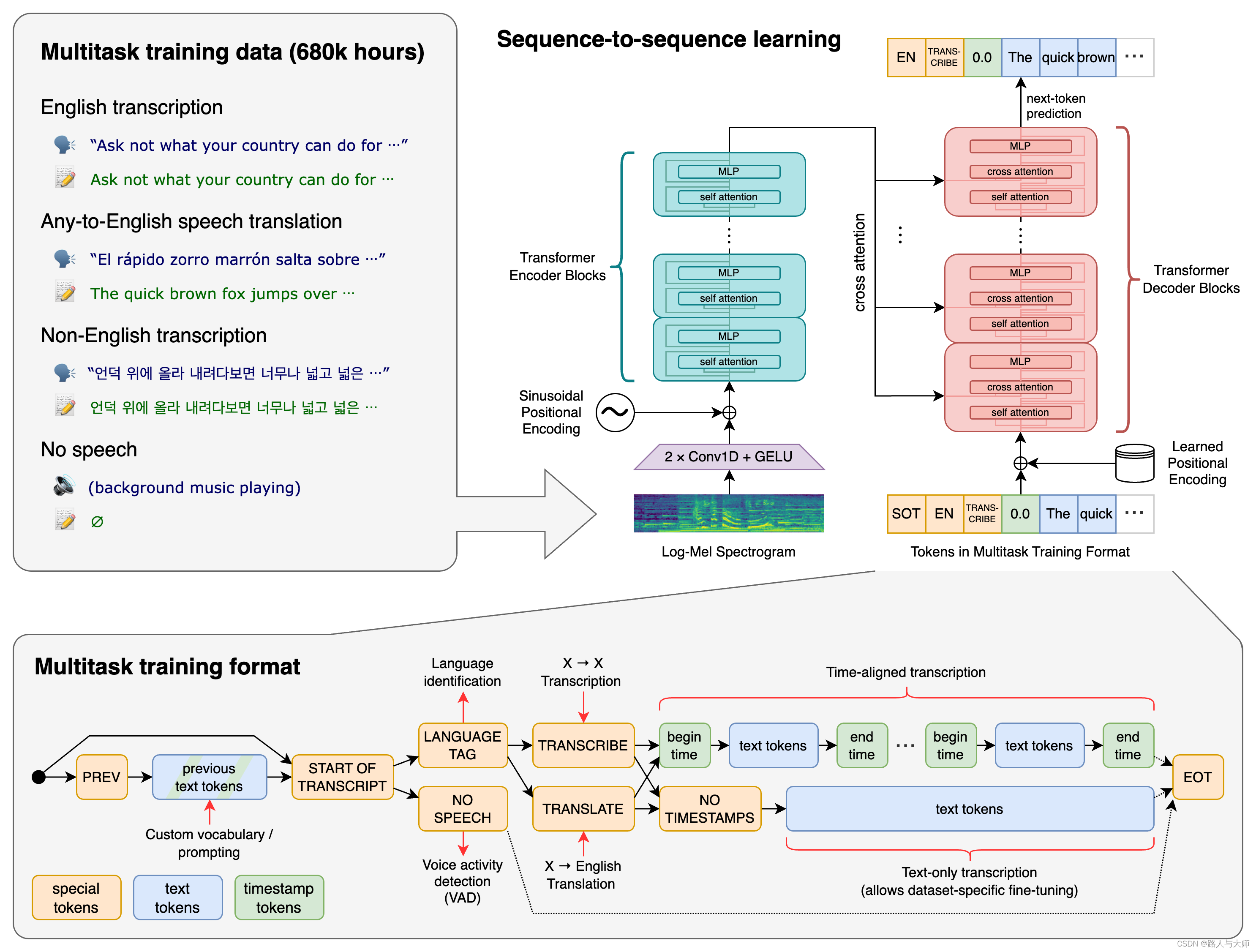
Whisper 是一个通用的语音识别模型。它在大规模多样化的音频数据集上进行训练,并且能够执行多任务处理,包括多语言语音识别、语音翻译和语言识别。
核心方法
Whisper 使用的是 Transformer 序列到序列模型,训练于多种语音处理任务。这些任务包括多语言语音识别、语音翻译、口语语言识别和语音活动检测。这些任务被联合表示为解码器需要预测的一系列标记,这样一个模型可以取代传统语音处理管道中的多个阶段。多任务训练格式使用了一组特殊标记,作为任务说明符或分类目标。
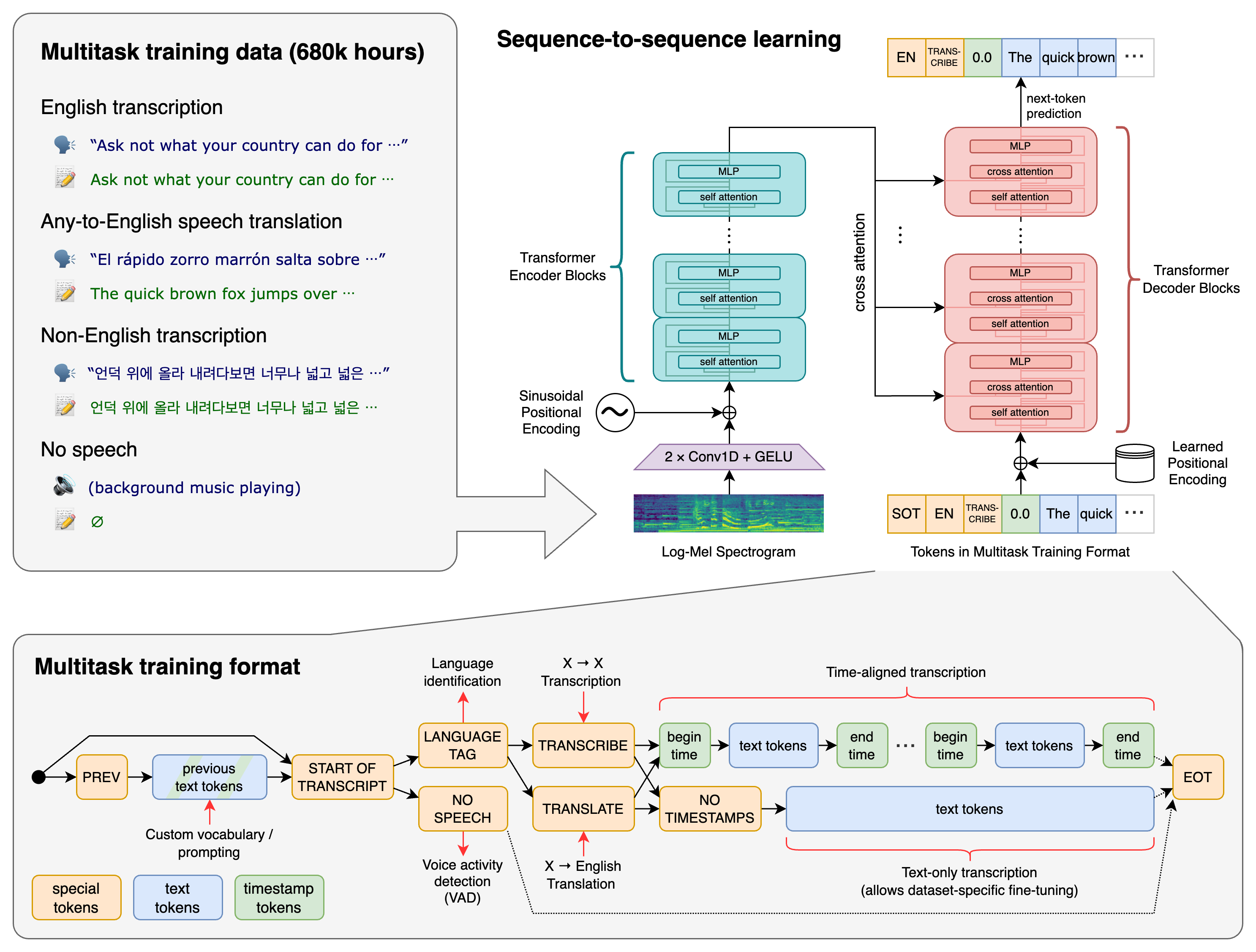
环境设置
我们使用 Python 3.9.9 和 PyTorch 1.10.1 来训练和测试我们的模型,但代码库预计兼容 Python 3.8-3.11 和最新的 PyTorch 版本。代码库还依赖于几个 Python 包,最显著的是 OpenAI’s tiktoken 用于快速分词实现。
安装或更新 Whisper 最新版本的命令:
pip install -U openai-whisper
- 1
或者,以下命令将拉取并安装该仓库的最新提交以及其 Python 依赖项:
pip install git+https://github.com/openai/whisper.git
- 1
更新包到最新版本的命令:
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
- 1
还需要在系统上安装命令行工具 ffmpeg,可以从大多数包管理器中获取:
# 在 Ubuntu 或 Debian 上
sudo apt update && sudo apt install ffmpeg
# 在 Arch Linux 上
sudo pacman -S ffmpeg
# 在 MacOS 上使用 Homebrew (https://brew.sh/)
brew install ffmpeg
# 在 Windows 上使用 Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# 在 Windows 上使用 Scoop (https://scoop.sh/)
scoop install ffmpeg
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
可能还需要安装 rust,以防 tiktoken 未提供适用于你平台的预构建轮子。如果在上述 pip install 命令期间看到安装错误,请按照 Getting started page 安装 Rust 开发环境。另外,可能需要配置 PATH 环境变量,例如 export PATH="$HOME/.cargo/bin:$PATH"。如果安装失败并提示 No module named 'setuptools_rust',需要安装 setuptools_rust,例如运行:
pip install setuptools-rust
- 1
可用模型和语言
Whisper 提供五种模型尺寸,四种具有仅英文版本,提供速度和准确性之间的权衡。以下是可用模型的名称及其近似内存需求和相对于大模型的推理速度;实际速度可能因多种因素(包括可用硬件)而有所不同。
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
针对仅英文应用的 .en 模型通常表现更好,特别是 tiny.en 和 base.en 模型。对于 small.en 和 medium.en 模型,这种差异变得不太显著。
Whisper 的性能因语言而异。下图展示了 large-v3 和 large-v2 模型按语言划分的性能,使用 WERs(词错误率)或 CER(字符错误率,以 Italic 表示)在 Common Voice 15 和 Fleurs 数据集上进行评估。其他模型和数据集的 WER/CER 指标可以在 论文 的附录 D.1、D.2 和 D.4 中找到,翻译的 BLEU(Bilingual Evaluation Understudy)分数在附录 D.3 中。
命令行使用
以下命令将使用 medium 模型转录音频文件中的语音:
whisper audio.flac audio.mp3 audio.wav --model medium
- 1
默认设置(选择 small 模型)适用于转录英语。要转录包含非英语语音的音频文件,可以使用 --language 选项指定语言:
whisper japanese.wav --language Japanese
- 1
添加 --task translate 将语音翻译成英语:
whisper japanese.wav --language Japanese --task translate
- 1
运行以下命令查看所有可用选项:
whisper --help
- 1
查看 tokenizer.py 获取所有可用语言列表。
Python 使用
也可以在 Python 中执行转录:
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])
- 1
- 2
- 3
- 4
- 5
在内部,transcribe() 方法读取整个文件,并使用滑动的 30 秒窗口处理音频,对每个窗口进行自回归序列到序列的预测。
以下是 whisper.detect_language() 和 whisper.decode() 的示例用法,它们提供了对模型的低级访问。
import whisper model = whisper.load_model("base") # 加载音频并填充/修剪至 30 秒 audio = whisper.load_audio("audio.mp3") audio = whisper.pad_or_trim(audio) # 制作 log-Mel 频谱图并移至与模型相同的设备 mel = whisper.log_mel_spectrogram(audio).to(model.device) # 检测口语语言 _, probs = model.detect_language(mel) print(f"Detected language: {max(probs, key=probs.get)}") # 解码音频 options = whisper.DecodingOptions() result = whisper.decode(model, mel, options) # 打印识别的文本 print(result.text)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
更多示例
请使用
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

