
- 1Java计算机毕业设计电影管理系统设计(开题报告+源码+论文)
- 2【Arduino学习笔记】手把手教你使用ESP8266----①接线篇_esp8266接线接线说明
- 3【在线+sdwebui】在线免费运行stable-diffusion-webui (无需配置环境)_sd webui在线版
- 4地推话术,地推人员的语言技巧和表达方式_地推话术技巧开场白
- 5程序员能力矩阵_研发人员矩阵
- 6Vue 生命周期详解含demo、面试常问问题案例
- 7代码总是被嫌弃写的太烂?装上这个IDEA插件再试试!
- 8大模型(LLM)的推理加速_大模型推理加速
- 9Kithara使用管道轻松安全地进行数据交换
- 10【Linux】VMware虚拟机配置静态IP_arpl改ip
大模型 | Llama3.1的工具调用解析及上手使用示例_llama 3.1怎么使用
赞
踩
今天来聊聊Meta最新发布的Llama 3.1系列模型中的新功能 —— 工具调用能力。这个功能不仅仅是Llama3.1独有,最近发布的Mistral NeMo和Mistral Lager2也都已经支持了工具调用能力。我觉得其本质还是为了减少LLM的”幻觉“现象。
一、Llama3.1工具调用
简单来说,工具调用允许大语言模型(LLM)在对话过程中直接使用预定义的工具,就像我们使用各种App一样。这大大扩展了AI的能力范围,使它能够更好地解决实际问题。
- Llama 3.1内置了三种特定工具:Brave Search、Wolfram Alpha和Code Interpreter。
- 这些工具直接集成在模型中,很重要一点,搜索引擎的API还是需要的。
- 工具调用是模型训练的一部分,模型知道如何和何时使用这些工具。
二、Llama 3.1的内置工具
Llama 3.1内置了三种强大的工具:
- Brave Search: 用于网络搜索,让AI能获取最新信息,这里指的网络搜索并不是直接在网上搜索信息,而是需要通过搜索引擎的API接口才能进行网络搜索。
- Wolfram Alpha: 用于复杂数学计算,提升AI的数学能力。
- Code Interpreter: 允许AI直接输出和执行Python代码。
这些工具使Llama 3.1能够执行从信息查询到数学计算,再到编程任务的广泛操作。
三、Llama 3.1的工具调用的工作原理
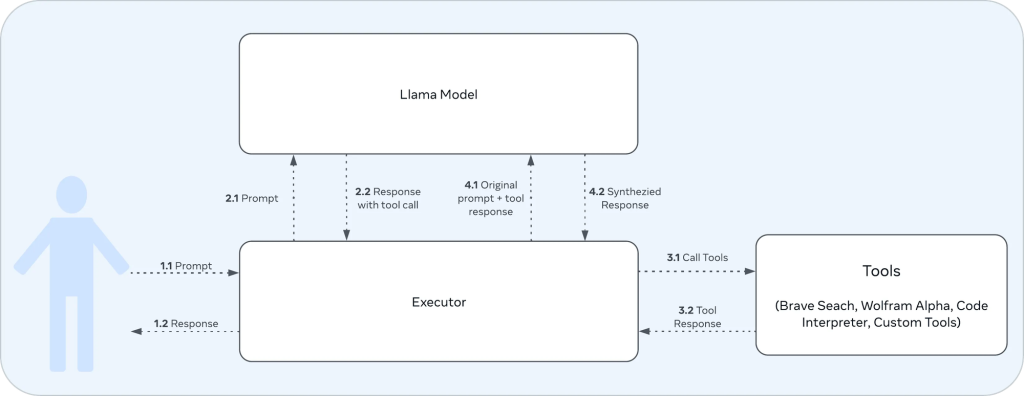
工具调用的工作流程大致如下:
1. 用户交互:
- 1.1: 用户向执行器(Executor)发送提示(Prompt)。
- 1.2: 执行器最终将响应(Response)返回给用户。
2. 执行器与Llama模型的交互:
- 2.1: 执行器将用户的提示传递给Llama模型。
- 2.2: Llama模型生成包含工具调用的响应。
3. 执行器与工具的交互:
- 3.1: 执行器根据Llama模型的响应调用相应的工具。
- 3.2: 工具执行后返回结果给执行器。
7. 执行器再次与Llama模型交互:
- 4.1: 执行器将原始提示和工具调用结果一起发送给Llama模型。
- 4.2: Llama模型生成最终的综合响应。
这张图就是一个完整的工具调用循环,从用户输入到最终输出,包括了Llama3.1模型的决策过程、工具的调用,以及如何将工具的结果整合到最终响应中。这种设计允许Llama3.1模型利用其内置的工具来增强能力,能够快速、精准地回答用户的问题,减少”幻觉“现象。
举一个例子:
我们先拟人化三个角色,你(用户),你的天才朋友(Llama3.1),你的小助手(Executor)
1. 你问一个问题,比如:今朝上海天气哪能讲?
2. 小助手把问题转交给你的天才朋友,你的小助手说:有则赤佬问上海天气情况。
3. 天才朋友思考后决定需要查看天气预报,他说:阿拉得查查天气预报App。
4. 小助手去查天气预报App(这就是调用工具)打开APP查上海天气。
5. 小助手把上海天气信息告诉天才朋友,他说:今朝上海天气哈捏有36度,伐落雨。
6. 天才朋友结合这条信息给出完整回答”根据天气预报App,今天上海是个晴朗得好天气,温度36度,适合待在家里吹空调。“
7. 小助手把这个回答告诉你(用户)。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
所以,通过这种方式,大语言模型给到用户得回答即高效又精准。
四、参数说明
我们结合Meta的官方文档(建议刚开始玩llama系列模型的小伙伴还是先去看一下原文档),提取一些比较重要的内容和参数拎出来讲一讲。
这次的提示词格式有所变动,尤其是角色方面分别是:
-
system :设置与 AI 模型交互的上下文。它通常包括帮助模型有效响应的规则、准则或必要信息。
-
user : 表示与模型交互的人类。它包括模型的输入、命令和问题。
-
ipython : Llama 3.1 中引入的新角色。从语义上讲,这个角色的意思是“工具”。此角色用于在从执行器发送回模型时,使用工具调用的输出标记消息。
-
assistant : 表示 AI 模型根据 ‘system’、’ipython’ 和 ‘user’ 提示中提供的上下文生成的响应。
Python示例如下:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
Environment: ipython
Tools: brave_search, wolfram_alpha
Cutting Knowledge Date: December 2023
Today Date: 23 Jul 2024
You are a helpful assistant<|eot_id|>
<|start_header_id|>user<|end_header_id|>
What is the current weather in Menlo Park, California?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Environment 这里的环境定义为:
- ipython:我理解就是代码解释器
Tools 这里的工具定义为:
- brave_search:网络搜索
- wolfram_alpha:数学计算器
示例说明
我们用下面这段脚本来试试最新的Llama3.1的网络搜索能力,以下是一些前置条件:
- 安装Python语言
- Ollama框架已安装;
- Llama3.1系列模型已下载;
- Python的requests库已安装;
- 搜索引擎的API已开通;
以下示例在Windows环境下运行:
import json import requests import re # Bing API 设置 subscription_key = "BING API KEY" # 请替换为您的实际 Bing API 密钥 endpoint = "https://api.bing.microsoft.com/v7.0/search" def call_ollama(prompt, system_prompt): url = "http://localhost:11434/api/generate" data = { "model": "llama3.1:8b", "prompt": prompt, "system": system_prompt, "stream": False } response = requests.post(url, json=data) return response.json()['response'] def brave_search(query): headers = {"Ocp-Apim-Subscription-Key": subscription_key} params = {"q": query, "textDecorations": True, "textFormat": "HTML"} try: response = requests.get(endpoint, headers=headers, params=params) response.raise_for_status() search_results = response.json() if "webPages" in search_results and "value" in search_results["webPages"]: results = [] for item in search_results["webPages"]["value"][:3]: results.append(f"Title: {item['name']}\nURL: {item['url']}\nSnippet: {item['snippet']}\n") return "\n".join(results) else: return "No results found." except Exception as ex: return f"Error during search: {str(ex)}" def process_model_output(response): match = re.search(r'<function=brave_search>\s*({.*?})\s*</function>', response) if match: return match.group(1) match = re.search(r'(?:<\|python_tag\|>)?function=brave_search>\s*({.*?})\s*(?:<\|eom_id\|>)?', response) if match: return match.group(1) return None def main(): system_prompt = """ Environment: ipython Tools: brave_search # 工具使用说明 - 当需要搜索信息时,务必使用 brave_search 函数。 - 必须使用这个精确格式进行搜索:<function=brave_search>{"query": "你的搜索查询"}</function> - 不要使用 <|python_tag|> 或其他标签。 - 在收到搜索结果后,总结找到的信息。 - 只使用搜索结果中的信息,不要使用预先存在的知识。 你是一个能够搜索实时信息的有用助手。请始终用中文回答用户的问题。 """ print("Welcome to the Llama 3.1:8b assistant with web search integration!") print("Type 'quit' to end the conversation.") while True: user_prompt = input("\nPlease enter your question: ") if user_prompt.lower() == 'quit': print("Thank you for using the assistant. Goodbye!") break response = call_ollama(user_prompt, system_prompt) print("\nLlama 3.1:8b:", response) search_query_json = process_model_output(response) if search_query_json: try: search_query = json.loads(search_query_json).get("query", "") if search_query: print(f"\nPerforming web search for: {search_query}") search_result = brave_search(search_query) print("Search results:", search_result) follow_up_prompt = f"Based on the search results: '{search_result}', please provide a brief summary or answer to the original question: '{user_prompt}'" follow_up_response = call_ollama(follow_up_prompt, system_prompt) print("\nLlama 3.1:8b:", follow_up_response) else: print("Search query is empty.") except json.JSONDecodeError: print(f"Error parsing JSON: {search_query_json}") else: print("No valid search function call detected.") if __name__ == "__main__": main()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
1. 导入必要的库:
import json
import requests
import re
- 1
- 2
- 3
- json: 用于处理JSON数据
- requests: 用于发送HTTP请求
- re: 用于正则表达式操作
2. Bing API 设置:这里不一定要使用bing,各大搜索引擎都可以,只要是开放API的
# Bing API 设置
subscription_key = "BING API KEY" # 请替换为您的实际 Bing API 密钥
endpoint = "https://api.bing.microsoft.com/v7.0/search"
- 1
- 2
- 3
这里设置了Bing搜索API的密钥和接口地址。
3. call_ollama 函数:
def call_ollama(prompt, system_prompt):
# ...
- 1
- 2
这个函数用于调用Llama 3.1模型。它向本地运行的Ollama服务发送请求,获取AI的回应。
4. brave_search 函数:
def brave_search(query):
# ...
- 1
- 2
这个函数实际上使用Bing API进行搜索。它发送搜索请求并处理结果,返回前三个搜索结果的摘要。
5. process_model_output 函数:
def process_model_output(response):
# ...
- 1
- 2
这个函数用正则表达式从AI的回应中提取搜索查询,它能处理不同格式的函数调用,经过验证效果并不好,同时我也没太多时间在这里做优化,有兴趣的小伙伴可以尝试不同函数。
6. main 函数:
def main():
# ...
- 1
- 2
7. 系统提示:
system_prompt = """
# ...
"""
- 1
- 2
- 3
这里的system_prompt还是蛮重要的,在使用8B尺寸的模型时尽量简单些,70B以上可以复杂一些。
8. 主循环:
- 接受用户输入
- 调用AI获取回应
- 如果AI要搜索,就执行搜索
- 将搜索结果给AI,获取最终回答
9. 脚本入口:
if __name__ == "__main__":
main()
- 1
- 2
使用示例
1. 首先,我们得创建一个空的文件夹(随便命名),在该文件夹内创建一个空的文件,把以上这段示例代码复制到一个空的文件里,txt文件也是可以的,但是文件保存要把文件格式改成*.py;

2. 接着,我们在该文件夹下“右击”再“点击”在终端中打开;
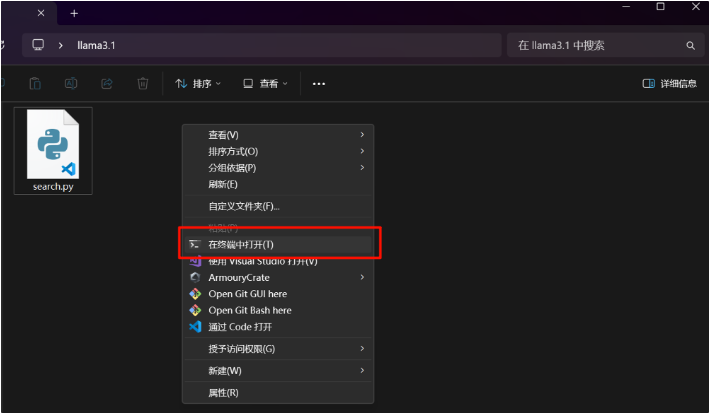
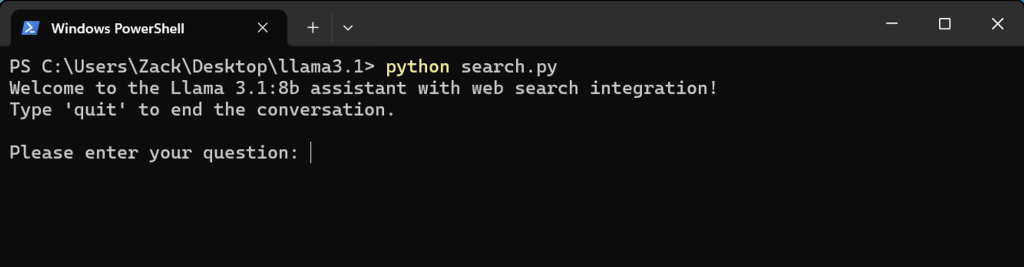
3. 在保证前置条件都已安装完成的情况下,输入
python search.py
- 1
这条命令开始执行该脚本;
4. 输入问题,比如:请总结下kunpuai.com这个网站;
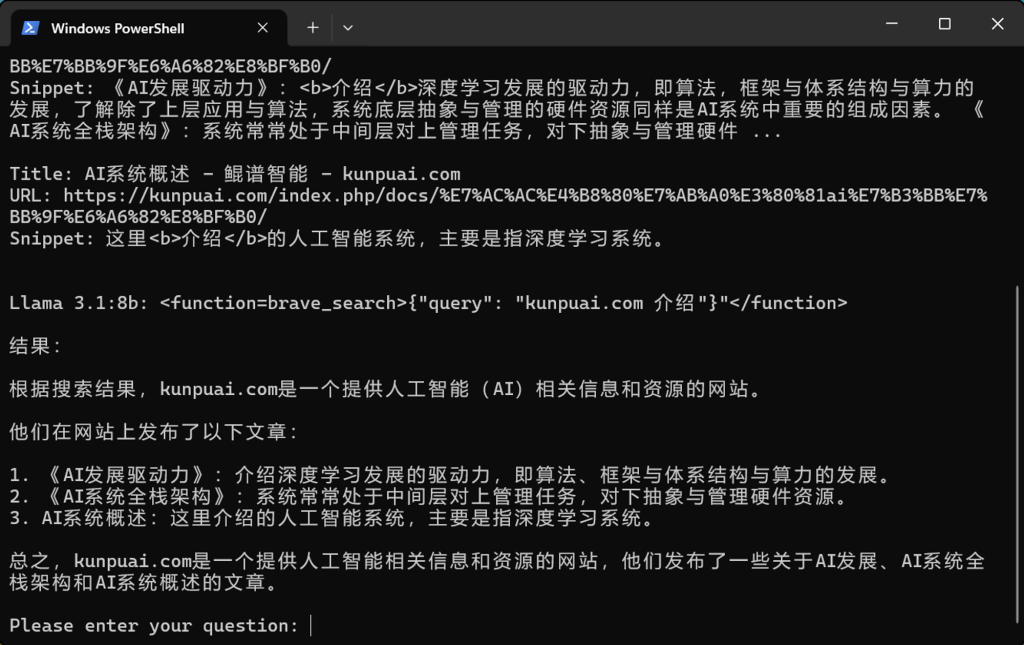
5. 这是Llama3.1 8B总结的效果,由于在brave_search 变量里设置了3,所以会有3条结果。
好了,以上便是这次网络搜索工具的示例,8b的模型推理非常流畅,但是推理结果却显得很一般,可以尝试更大尺寸的模型。
文章最后
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频,免费分享!

一、大模型全套的学习路线
L1级别:AI大模型时代的华丽登场
L2级别:AI大模型API应用开发工程
L3级别:大模型应用架构进阶实践
L4级别:大模型微调与私有化部署

达到L4级别也就意味着你具备了在大多数技术岗位上胜任的能力,想要达到顶尖水平,可能还需要更多的专业技能和实战经验。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人在大模型时代,需要不断提升自己的技术和认知水平,同时还需要具备责任感和伦理意识,为人工智能的健康发展贡献力量。
有需要全套的AI大模型学习资源的小伙伴,可以微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

如有侵权,请联系删除。

