
- 1RecyclerView的多种布局_recyclerview不同布局
- 2Data URI scheme_11.ptdown.woyaoxz.cn
- 3LeetCode——2367. 算术三元组的数目_leetcode 2367. number of arithmetic triplets
- 4数据结构--串_0号单元存放串的长度
- 5斯坦福大学课程 机器学习1 关于机器学习的介绍_field of study that gives computers the ability to
- 6【云原生】K8S超详细概述
- 7Selenium + Java系列三:常见报错_timed out receiving message from renderer
- 8git log --pretty= 显示提交者名字,并以简短方式显示
- 9mc一进服务器就没响应,求助:我的mc可以正常打开,但一进或新建地图就无响应怎么办...
- 10k8s学习-CKA真题-持久化存储_csi-driver-host-path
手把手教你玩Hugging Face
赞
踩
Hugging Face起初是一家总部位于纽约的聊天机器人初创服务商,他们本来打算创业做聊天机器人,然后在github上开源了一个Transformers库,虽然聊天机器人业务没搞起来,但是他们的这个库在机器学习社区迅速大火起来。目前已经共享了超100,000个预训练模型,10,000个数据集,变成了机器学习界的github。
打开它的网站:Hugging Face – The AI community building the future.
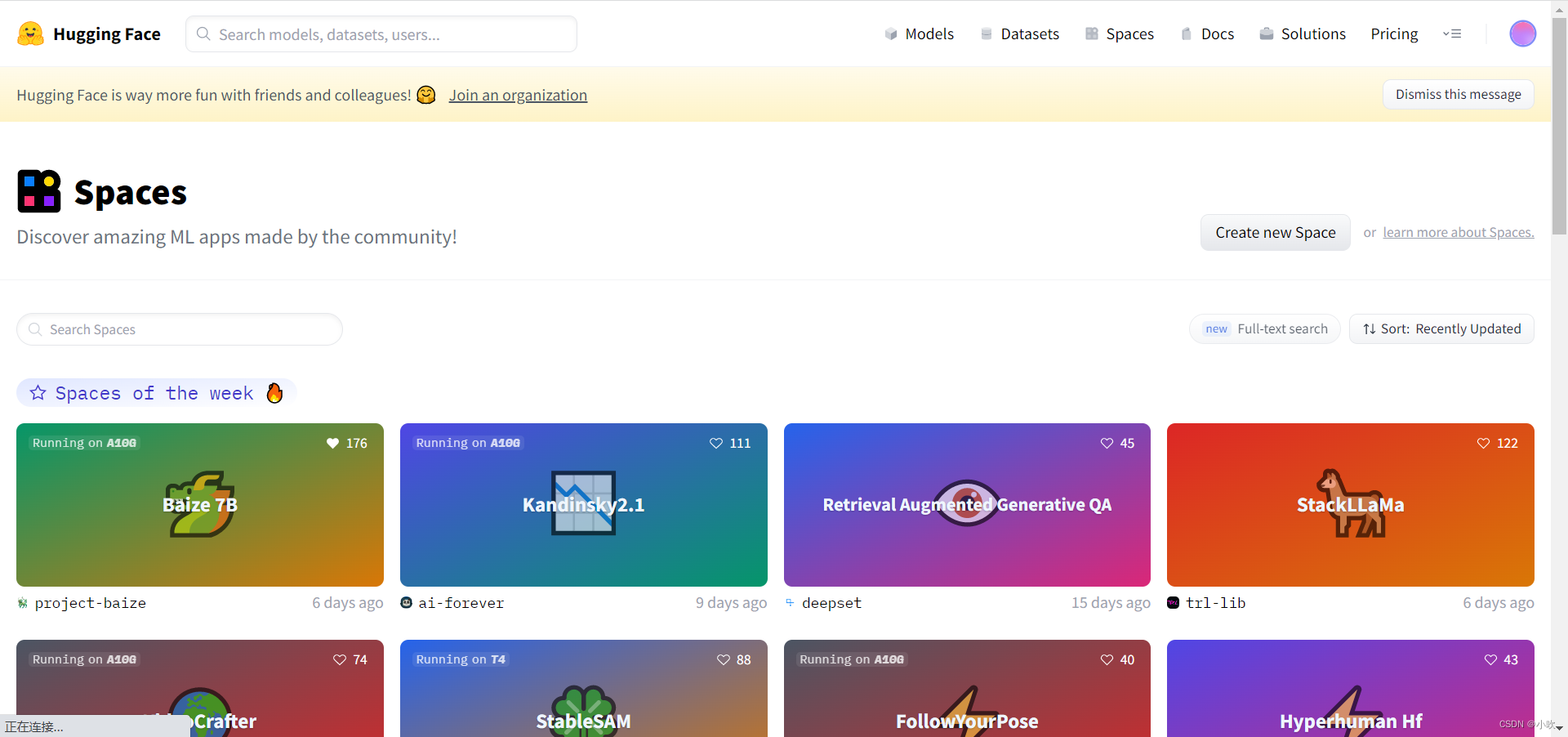
可以看到,Hugging Face的主要功能都在最上面的一行,包括:模型(Models)、数据集(Datasets)、空间(Spaces)。其他还有:说明文档(Docs)、解决方案(Solutions)、报价(Pricing)。另外在折叠的菜单里,还有交流社区(Community)、以及机器学习的一些课程等等。
在这里,我们先着重说一下这个Spaces。这是Hugging Face区别于github的一个特殊功能。就是可以把你的模型和代码运行在它的服务器上,并且可以公开提供给别人用!
具体怎么做呢?举个简单的例子:现在大火的ChatGPT很好玩,但是由于众所周知的原因,不给我们用了!爬墙又很麻烦,梯子有可能不稳定,普通人也不会用。Hugging Face这时候就派上用场了!因为它是个美国网站,且没有被墙,它的服务都运行在美国,所以在这上面用你的ChatGPT API Key就不会被封!
打开这个Space:Chatgpt Demo - a Hugging Face Space by cuiyuan605
就可以用你的OpenAI API Key跟ChatGPT畅聊了!
如果你觉得用别人的Space不放心,那可以将它一键克隆到你的账号:

这样,你就可以随意修改它的代码,妈妈再也不用担心你的Key被别人偷了!
如果你没有ChatGPT的API Key,这里还有一个可以将文字变成图像的小模型,你也可以克隆到你的账号里玩一玩:Text to Image - a Hugging Face Space by cuiyuan605
这个Space的功能,就是将你的代码,运行在Hugging Face的服务器上。App就是你的服务交互界面,Files是你的代码文件,Community是这个服务的相关讨论。另外,还可以在Settings里修改这个服务的设置,后面的菜单里是其他人对这个Space的一些操作。
那么,这个Space的交互原理是什么,如何从零构建一个自己的Space呢?
可以参考一下网站给的文档:Spaces
如果不想看英文文档,可以看我下面的简单介绍。
这个Space的主要原理,就是让你在它的服务器上跑一个web服务。然后将你生成的交互页面嵌入到App这个选项页里。
Hugging Face提供了三种动态交互的方式:Gradio、Streamlit和Docker。
这里重点说一下Gradio,这是一个python的web服务库。是专门为机器学习应用,封装的一个前后端库。用法很简单,详细文档可以参考这里:Quickstart
我们先用一个简单的例子,让你可以快速用起来。
首先,创建一个Space,Space SDK选择Gradio:

然后,在Files中创建文件requirements.txt,用于指定项目的依赖库。比如在这里,我们可以将文件内容编辑为:
- transformers
-
- torch
接下来,创建文件app.py,用于实现交互界面。我们将文件内容编辑为:
- import gradio as gr
-
-
-
- def greet(name):
-
- return "Hello " + name + "!!"
-
-
-
- iface = gr.Interface(fn=greet, inputs="text", outputs="text")
-
- iface.launch()
保存文件后,点击App选项页,等它build一会儿,一个简单的Gradio项目就成功啦!

之后每次更新仓库,都会重新构建和启动App,你也可以用git把项目拉到本地进行开发,开发完成后上传代码,方法和github一样。clone的地址在Settings后面那个三个点的菜单里。
是不是是很简单,是不是打开了一个新世界的大门,只要把项目设为public,就可以将服务提供给其他人用啦。不过免费的空间只有2CPU和16G内存,且每48小时就会将你的服务自动停止。需要更长的服务时间,更多硬件资源,甚至GPU资源,那就需要马内了,毕竟世上没有免费的午餐!
下面的Streamlit和Docker只做简单的介绍。
Streamlit也是一个python的前后端库,只不过它并不是专为机器学习应用开发的,而是更偏向于可视化数据展示。此外,它还有个重要的功能,就是能够把页面嵌入到其他的网站,也就是说你可以把Hugging Face上服务,嵌入到你的个人网站里!开不开心,意不意外!具体方法可以参考文档:Streamlit Spaces
至于Docker则是一个更加独立自由的空间,用过的都说好!具体使用方法可以参考官方文档:Your First Docker Space: Text Generation with T5
这里顺便说一下,Docker这个示例是跑不通的!官方文档写错了,需要把Dockerfile的最后一行:
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "7860"]改为:
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "7860"]除了Spaces以外,Hugging Face还提供了各路大佬上传的各种模型和数据集,让我们可以站在大佬的肩膀上看世界,不用苦逼的造轮子。
不过模型和数据文件一般都比较大,需要用到lfs(Large File Storge)大文件存储,用之前记得先装一下:
git lfs intall
然后git clone走起

我们除了可以直接下载这些模型和数据集以外,还可以对模型进行自动训练。

或者直接将模型部署为API或者Space

数据集的clone地址藏在这里哦:

下面,我们就开心的玩起来吧!
参考资料:
《Huggingface 超详细介绍》:Huggingface 超详细介绍 - 知乎

