
- 1银河麒麟V10桌面操作系统下安装Qt(5.12.10)_麒麟v10系统离线安装qt编译器
- 2Vue之在$notify中添加样式和事件_this.$notify dangerouslyusehtmlstring message
- 3windows kernel exploitation基础教程
- 4微软杀入Web3:打造基于区块链的AI产品
- 5【Axure】使用中继器实现登陆注册功能_axure注册登录页面
- 6如何通过OTG免Root给其他手机进行刷机救砖_otg刷机
- 7Windows11+VS2019+CUDA11.8配置过程_cuda11.8下载
- 8JSP&EL表达式&MVC&三层结构综合案例_编程el 的综合应用。 结合自己的应用,运用 mvc+dao 设计模式完成信息的访问。
- 9代码: 0x80131500:应用商店崩溃了修复_0x80131500 csdn
- 10linux系统git仓库
网络原理 - HTTP/HTTPS(1)
赞
踩
HTTP
HTTP是什么
HTTP("全程超文本协议")是一种应用非常广泛的应用层协议.
文本:字符串(能在utf8/gbk)码表上找到合法字符.
超文本:不仅是字符串,还能携带图片啥的(HTML).
富文本:类似于word文档这种.
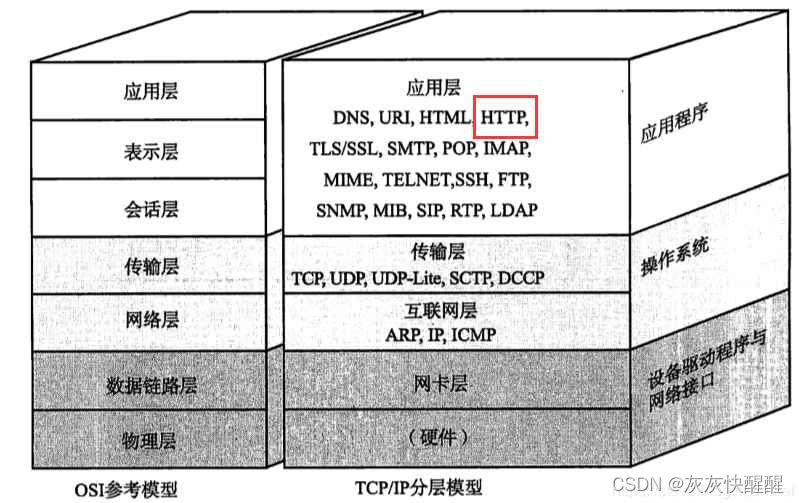
HTTP诞生于1991年.目前已经发展为最主流使用的一种应用层协议.

实际上HTTP/1.1是目前使用最广泛的HTTP协议版本,之后的讨论也以HTTP1.1为主.
HTTP往往是基于传输层的TCP协议实现的.(HTTP1.0,HTTP1.1,HTTP2.0均属于TCP,HTTP3.0基于UDP实现).
我们平时打开一个网站,就是通过HTTP协议来传输数据的.

当我们在浏览器中输入一个搜狗搜索的"网址"(URL)时,浏览器就给搜狗的服务器发送了一个HTTP请求,搜狗的服务器返回了一个HTTP响应.(浏览器和服务器之间传输数据)
这个响应结果被浏览器解析之后,就展示成我们看到的页面内容.(这个过程浏览器可能给服务器发送多个HTTP请求,服务器会对应返回多个响应,这些响应里就包含了页面HTML,CSS,JavaScript,(前端开发三剑客)图片,字体等信息).
理解"应用层协议"
我们之前讲过TCP/IP,已经知道目前数据能从客户端进程经过路径选择跨网络传送到服务器端进程[IP + Port].
可是,仅仅把数据从A点传送到B点就完了吗?
这就好比,在淘宝上买了一部手机,卖家[客户端]把手机通过顺丰[传送 + 路径选择]送到买家[服务器]手里就完了吗?
不是的,买家还要使用这款产品,使用完之后也可能要给卖家打分评论.
所以,我们把数据从A端传送到B端,TCP/IP解决的是顺丰的功能,而两端还要对数据进行加工处理或者使用,所以我们还需要一层协议,不关心通信细节,关心应用细节!
这层协议叫做应用层协议.而是用是有不同场景的,所有应用层协议是不同种类的,其中经典协议之一的HTTP就是其中的佼佼者.
理解HTTP协议的工作过程
当我们在浏览器中输入一个"网址",此时浏览器就会给对应的服务器发送一个HTTP请求.对方服务器收到这个请求之后,经过计算处理,就会返回一个HTTP响应.(一问一答)

但是,在类似于消息推送等场景时,需要服务器主动给浏览器发送消息,这里HTTP就难以胜任了.
应用层这里还提供了一个和HTTP搭配的协议,websocket(HTTP的跟班,针对HTTP能力进行补充的).
HTTP协议格式
HTTP是一个文本格式的协议.通过抓包工具进行抓包,分析HTTP请求/响应的细节.
抓包工具的使用
以Fidder为例.(下载:https://www.telerik.com/fiddler/)
如果安装配置ok,fiddler就能抓到很多数据包,打开一个网站,其实浏览器和服务器之间的HTTP交互不是只有一次,而是多次.经过反复拉扯,才能页面获取.

左侧窗口显示了所有HTTP请求/响应,可以选中查看详细.
右侧上方显示了HTTP的报文内容.(切换到Raw标签页可以查看详细的数据格式)
右侧下方显示了HTTP的报文内容.(切换到Raw标签页可以查看详细的数据格式)
请求和响应的详细数据,可以通过右下角的View in Notepad通过记事本打开.
可以使用ctrl+a全选左侧的抓包结果,delete键删除所有的被选中结果.
抓包工具的原理
对了,在使用fiddler之前,还需要关闭电脑上其它的代理程序.因为Fiddler也是个代理程序,可能会与其它的程序出现冲突.
代理分成两种: 1.正向代理(是客户端的代言人) 2.反向代理(是服务器的代言人)
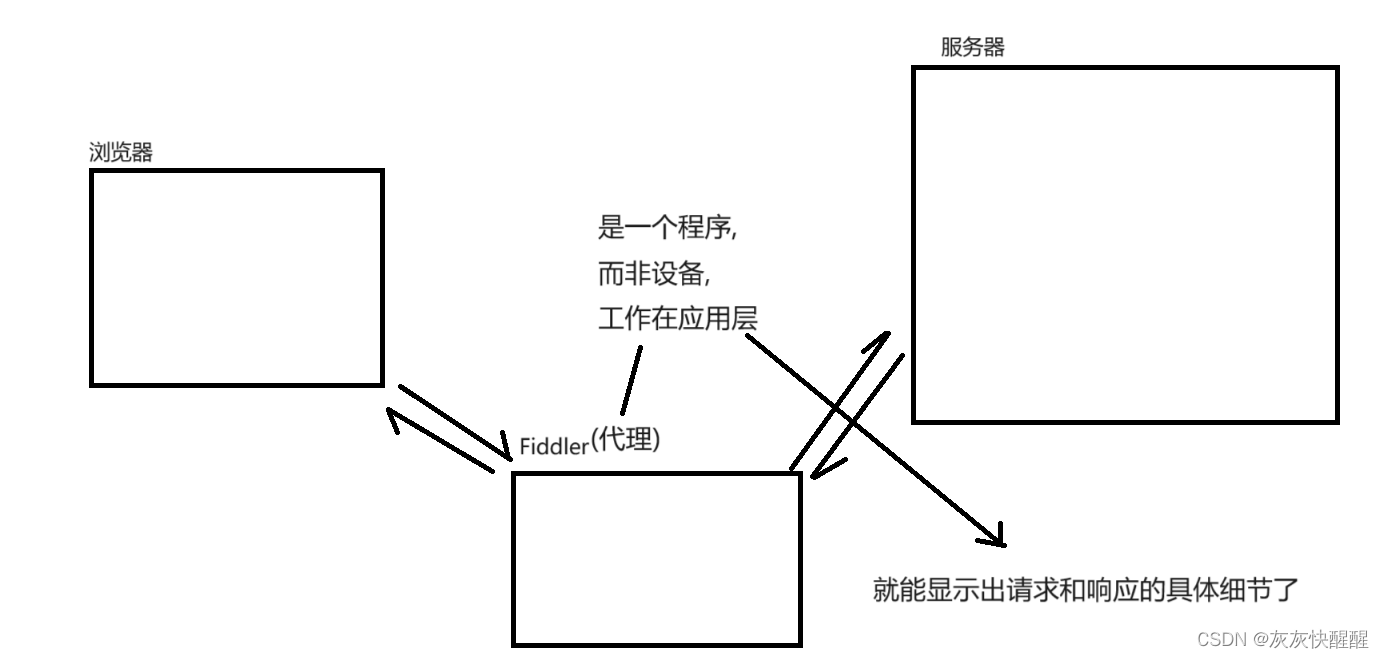
代理就可以简单理解为跑腿小弟.你想买罐冰可乐,又不想下楼去超市,那么就可以把钱给你的跑腿小弟(正向代理),跑腿小弟来到超市把钱给超市老板(老板也可能不想看店,让儿子看店(反向代理)),再把冰可乐拿回来交到你的手上.这个过程中,这个跑腿小弟对于"你"和"超市老板"的交易细节,是非常清楚的.
抓包结果
HTTP请求:
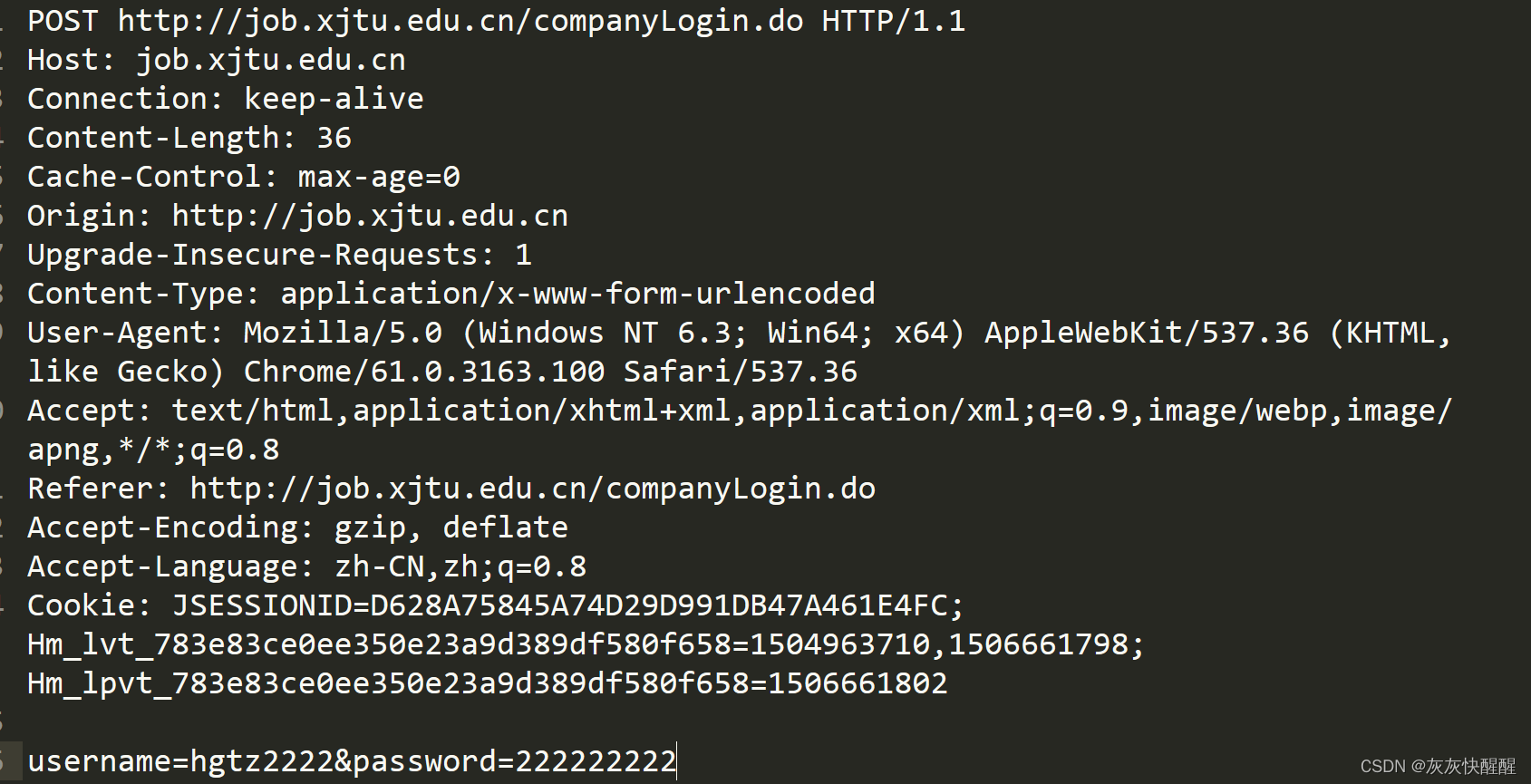
首行:[方法] + [url] + [版本]
Header:请求的属性,冒号分割的键值对;每组属性之间用\n分隔; 遇到空行表示Header部分结束
Body(http载荷部分):空行后面的内容都是Body.Body允许为空字符串.如果Body存在,则在Header中会有一个Content-Length来标识Body的长度;(有的http请求有body,有的没有)
HTTP响应:
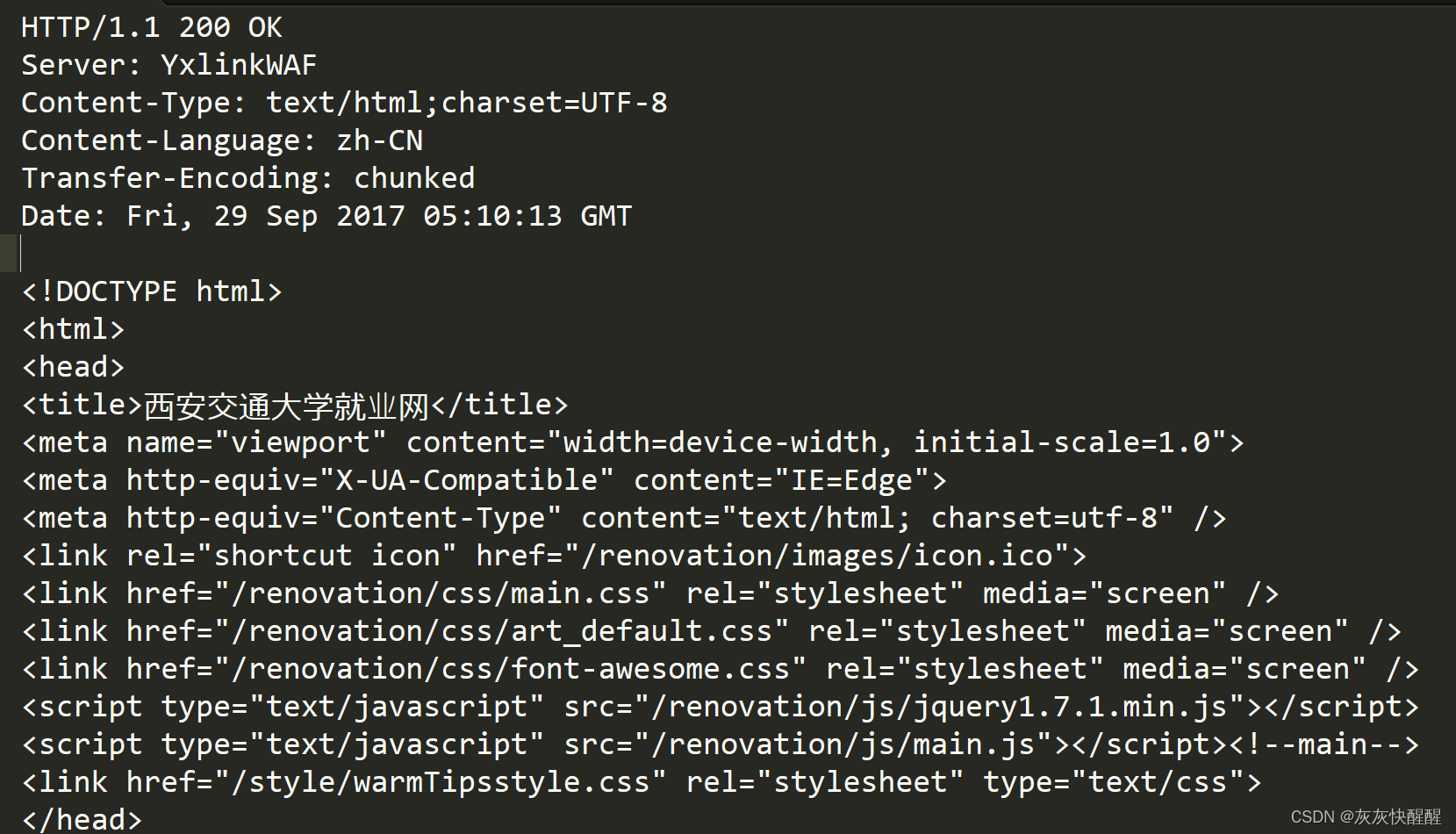
首行:[版本号] + [状态码] + [状态码解释](请求成功/失败)
Header:请求的属性,冒号分隔的键值对;每组属性之间使用\n分隔;遇到空行表示Header结束
Body:空行后面的内容都是body.Body允许为空字符串.如果Body存在,则在Header中会有一个Content-Length属性来标识Body的长度;如果服务器返回了一个html页面,那么html页面内容就是在body中.
协议格式总结
思考问题:为什么HTTP报文中要存在"空行"?
因为HTTP协议中并没有规定报头部分的键值对有多少个.空行就是"报头结束的标记",或者是"报头和正文之间的分隔符".
HTTP在传输层依赖TCP协议,TCP是面向字节流的.如果没有这个空行,就会出现"粘包问题".

