
热门标签
热门文章
- 1【vscode】Could not establish connection to “xxx(IP)“: Downloading VS Code Serverfailed - please insta_未能下载vs code服务器
- 2python之turtle画花_python画花瓣代码
- 3html定位的四种状态,HTML5定位的使用,及定位失败的原因
- 4jQuery MiniUI 开发教程 CRUD之:表单编辑(三)
- 52024年腾讯云、阿里云、华为云搭建幻兽帕鲁游戏联机服务器步骤_华为云搭建帕鲁
- 6VS2019.Net Core智能提示英文转换中文教程_将vs2019的智能提示改为中文
- 7Jmeter教程-JMeter 环境安装及配置_jmeter安装及环境配置
- 815个精美的 HTML5 单页网站作品欣赏
- 9基于Python爬虫江苏无锡天气预报数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 10【Linux】软件包管理器 yum | vim编辑器
当前位置: article > 正文
不止最佳长论文,腾讯AI在ACL上还有这些NLP成果
作者:从前慢现在也慢 | 2024-02-26 21:05:14
赞
踩
acl自然语言处理成果

编辑 | Jane 出品 | AI科技大本营(ID:rgznai100)
【导语】7 月 31 日晚,自然语言处理领域最大顶会 ACL 2019 公布了今年的八个论文奖项,其中最佳长论文的获奖者被来自中国科学院大学、中国科学院计算技术研究所、腾讯 WeChat AI、华为诺亚方舟实验室、伍斯特理工学院等机构的联合论文所斩获。除了这篇最佳长论文,腾讯在今年的 ACL 会议上还有哪些研究论文被录取?今天,我们就用这篇文章为大家做介绍。
1、《Bridging the Gap between Training and Inference for Neural Machine Translation》桥接神经网络机器翻译训练和推导
该论文是今年 ACL 的最佳长论文,该论文由腾讯微信AI与中科院计算所、华为诺亚方舟实验室联合完成。本文的工作解释了暴露偏差和过度校正现象,并将所提出的方法与试图决该类问题的其他方法进行了对比。这项工作中提出的方法对学术研究以及实际应用都有非常重要的意义。

论文地址: https://www.aclweb.org/anthology/P19-1426
当前主流的神经网络机器翻译(NMT)以自回归的方式逐词产生译文。在训练时,模型以参考译文中的词语作为翻译历史进行预测;而在推导时,模型必须从头开始生成整个序列,即以模型的输出为历史,依赖的上文分布与训练时不同,这会导致推导时翻译序列上的误差累积,该问题被称为Exposure Bias(暴露偏差)。
此外,词级别的训练方法要求所预测的序列与参考译文序列之间严格匹配,这会导致模型对那些与参考译文不同但是合理的译文做过度校正。 为了解决上述问题,在模型训练期间,作者从参考译文序列与模型自身预测出的序列中采样出历史词语,作为模型的输入。除了词级别采样,本文的另一个贡献在于作者提出了句子级的采样方法。
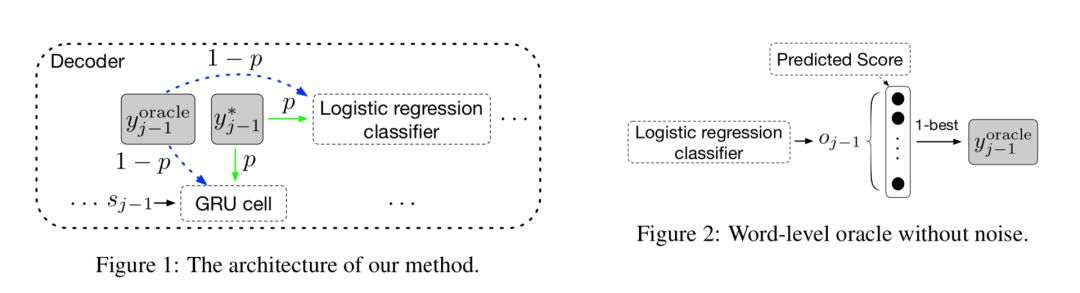 在NIST中英和WMT14英德翻译任务的实验结果表明,我们的方法在多个数据集上比强基线系统(深层的RNMT和Transformer)得到了显著性地提升。
在NIST中英和WMT14英德翻译任务的实验结果表明,我们的方法在多个数据集上比强基线系统(深层的RNMT和Transformer)得到了显著性地提升。
2、《Incremental Transformer with Deliberation Decoder for Document Grounded Conversations》基于文档级知识的对话: 带有推敲解码机制的增量式 Transformer
本文由腾讯微信AI与华中科技大学等联合完成。本文主要研究基于文档知识的对话,在给定文档的内容时生成上下文连贯、正确利用知识的回复。 论文地址:
https://www.aclweb.org/anthology/P19-1002
文档知识在我们日常对话中起着至关重要的作用,而现有的对话模型并没有有效地利用这类知识。在本文中,作者提出了一种新的基于Transformer的基于文档知识的多轮对话模型。
作者设计了一个增量式Transformer来编码多轮对话以及相关文档中的知识。此外,在人类认知过程的启发下,作者还设计了一个具有两次解码过程的推敲解码器,来提高上下文的一致性和知识应用的正确性。
论文地址:
https://www.aclweb.org/anthology/P19-1002
文档知识在我们日常对话中起着至关重要的作用,而现有的对话模型并没有有效地利用这类知识。在本文中,作者提出了一种新的基于Transformer的基于文档知识的多轮对话模型。
作者设计了一个增量式Transformer来编码多轮对话以及相关文档中的知识。此外,在人类认知过程的启发下,作者还设计了一个具有两次解码过程的推敲解码器,来提高上下文的一致性和知识应用的正确性。
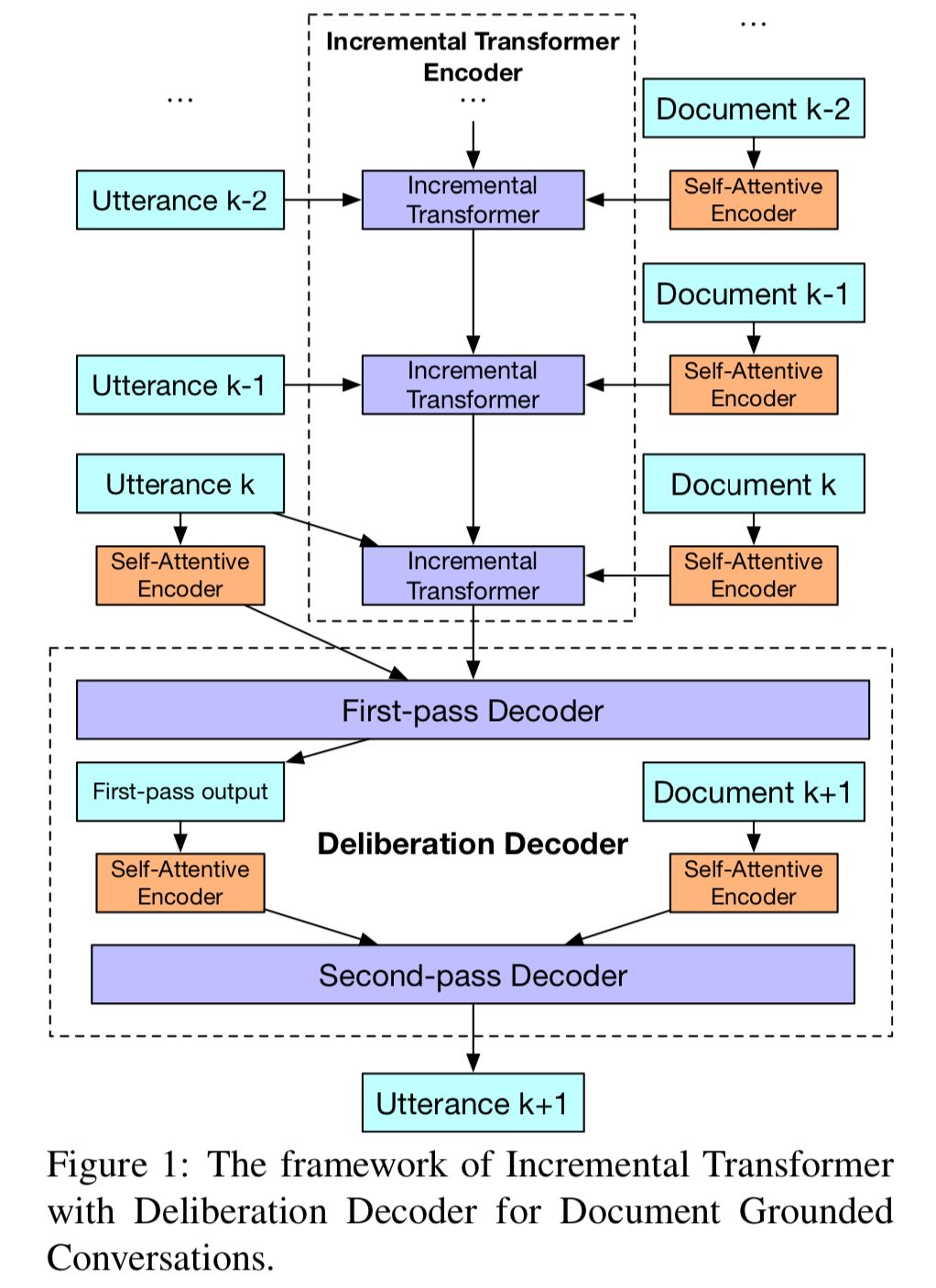
 第一次解码过程注重上下文回复的一致性,第二次解码过程注重知识应用的正确性。在真实的基于文档的多轮对话数据集的实验研究证明,模型生成的回复在上下文一致性和知识相关性方面都显著优于其他基线模型。
第一次解码过程注重上下文回复的一致性,第二次解码过程注重知识应用的正确性。在真实的基于文档的多轮对话数据集的实验研究证明,模型生成的回复在上下文一致性和知识相关性方面都显著优于其他基线模型。
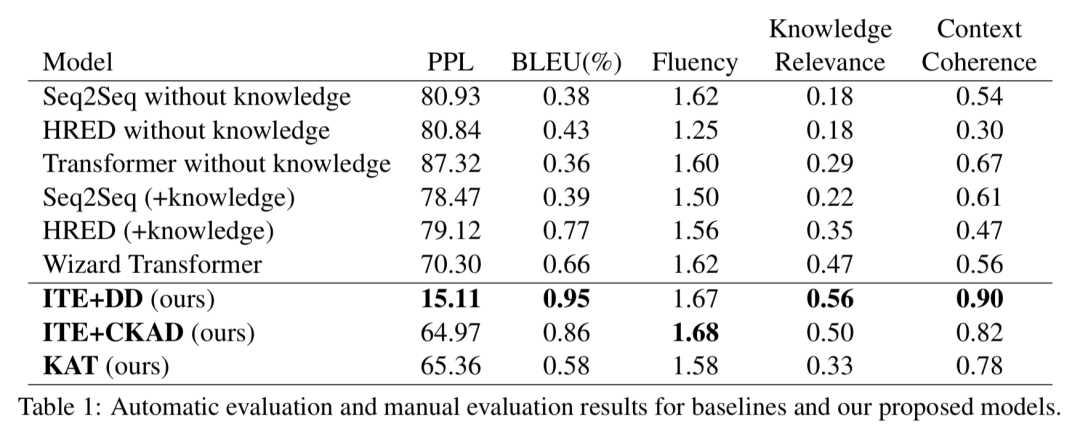
3、《GCDT: A Global Context Enhanced Deep Transition Architecture for Sequence Labeling》GCDT:全局上下文增强的深度转换架构序列标注模型
该论文由腾讯微信AI与北京交通大学联合完成。在本文中,作者提出了一个利用全局上下文增强的深度转换架构 GCDT(Global Context Enhanced Deep Transition)用于序列标注任务。 论文地址:
https://www.aclweb.org/anthology/P19-1233
序列标注是一类基础的NLP任务,目前最佳的模型通常基于循环神经网络(RNNs)。然而RNN模型在相邻词之间的隐状态连接较浅,并且对于全局信息建模不够充分,从而限制RNN模型的潜在性能。作者试图解决这个问题,在论文中提出了一个利用全局上下文增强的深度转换架构——GCDT(text Enhanced Deep Transition)用于序列标注任务。
论文地址:
https://www.aclweb.org/anthology/P19-1233
序列标注是一类基础的NLP任务,目前最佳的模型通常基于循环神经网络(RNNs)。然而RNN模型在相邻词之间的隐状态连接较浅,并且对于全局信息建模不够充分,从而限制RNN模型的潜在性能。作者试图解决这个问题,在论文中提出了一个利用全局上下文增强的深度转换架构——GCDT(text Enhanced Deep Transition)用于序列标注任务。
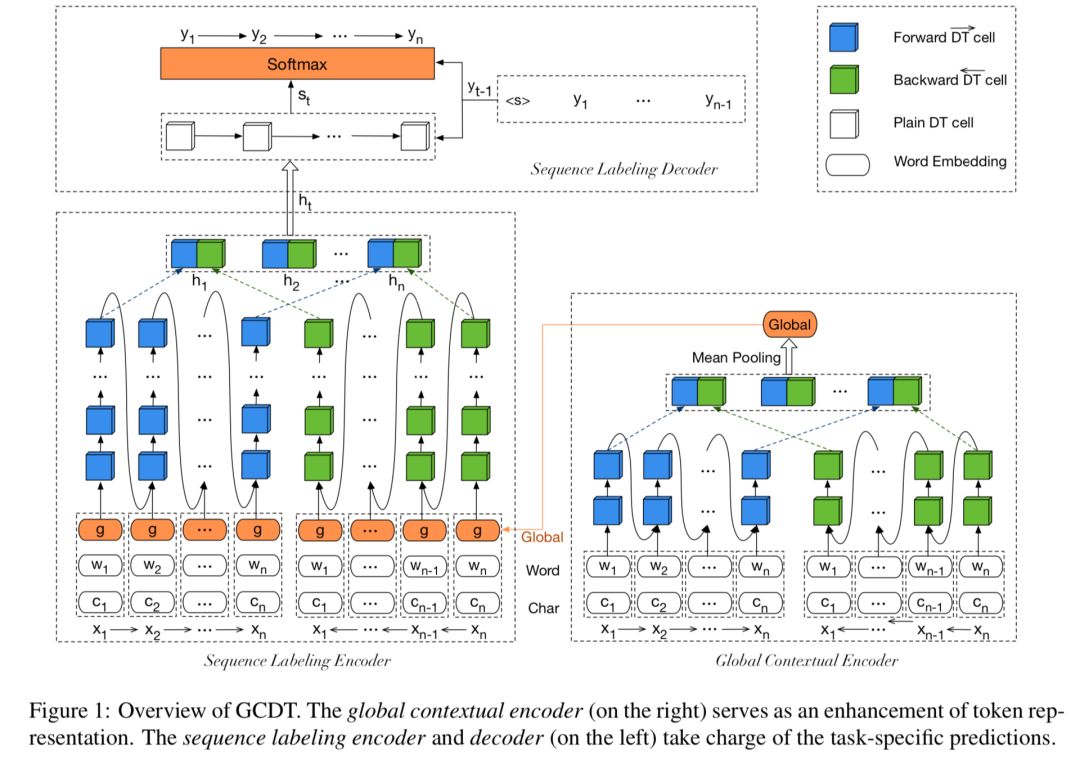 首先,通过设计特有的门控单元,加深句中的每个词位置的状态转换路径,并进一步利用句子级的全局信息来增强每个词的局部表示。
实验中,在两项标准任务上验证模型的有效性,分别是命令实体识别(NER)和语法块识别(Chunking)实验结果表明,在只利用训练数据和预训练词向量的情况下,作者提出的GCDT模型在两项任务上分别达到 91.96(NER)和 95.43(Chunking)的F1值,超过同等设置下的最佳模型。
首先,通过设计特有的门控单元,加深句中的每个词位置的状态转换路径,并进一步利用句子级的全局信息来增强每个词的局部表示。
实验中,在两项标准任务上验证模型的有效性,分别是命令实体识别(NER)和语法块识别(Chunking)实验结果表明,在只利用训练数据和预训练词向量的情况下,作者提出的GCDT模型在两项任务上分别达到 91.96(NER)和 95.43(Chunking)的F1值,超过同等设置下的最佳模型。
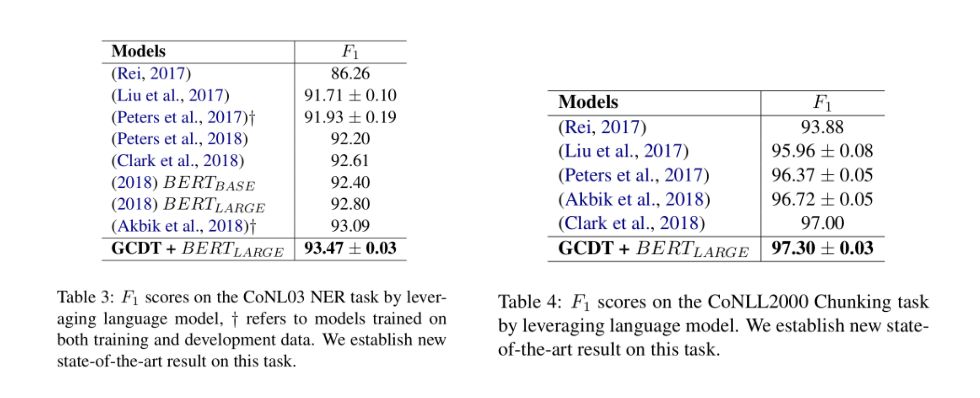
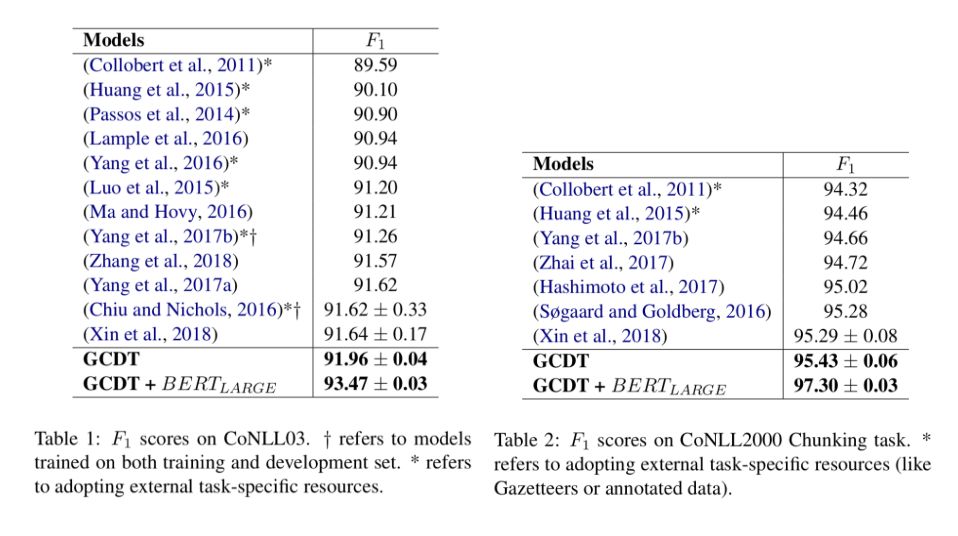 此外,通过利用BERT作为额外的语义知识,在两项数据集上得到了新的state-of-the-art结果: 93.50(NER)和 97.30(Chunking)。
此外,通过利用BERT作为额外的语义知识,在两项数据集上得到了新的state-of-the-art结果: 93.50(NER)和 97.30(Chunking)。
4、《Retrieving Sequential Information for Non-Autoregressive Neural Machine Translation》序列信息指导的非自回归神经机器翻译
该论文由腾讯微信AI与中科院计算所联合完成。在论文中,针对神经机器翻译模型。非自回归模型容易产生过翻译和漏翻译错误的训练缺陷,作者提出了两种方法来为非自回归模型引入序列信息。 论文地址:
https://www.aclweb.org/anthology/P19-1288
论文地址:
https://www.aclweb.org/anthology/P19-1288
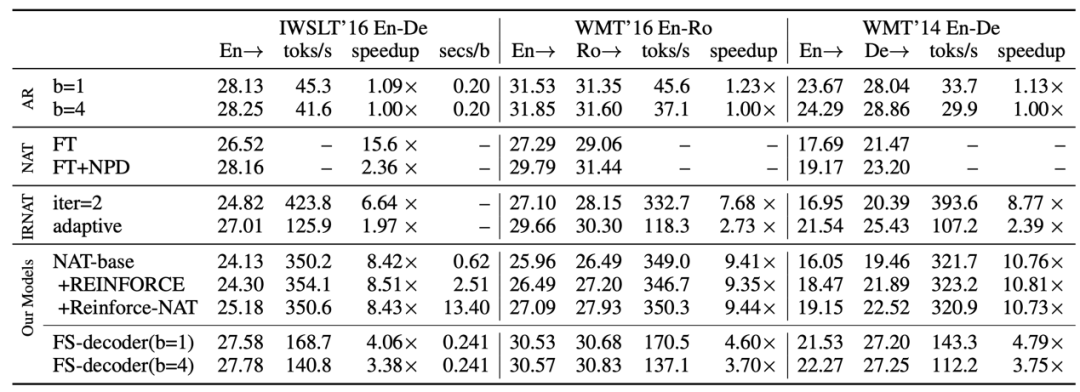 主流的神经机器翻译模型采用自回归的解码机制,即逐词生成翻译结果,翻译的延迟较高。非自回归机器翻译对每个词的翻译概率独立建模,因此能并行解码出整个译文,大幅提升翻译速度。然而,非自回归模型在训练时缺乏目标端序列信息的指导,容易产生过翻译和漏翻译的错误。基于此,作者提出了两种方法来为非自回归模型引入序列信息。
在第一种方法中,基于非自回归模型的特性,设计了基于强化学习的高效、稳定的序列级训练方法(Reinforce-NAT)。
主流的神经机器翻译模型采用自回归的解码机制,即逐词生成翻译结果,翻译的延迟较高。非自回归机器翻译对每个词的翻译概率独立建模,因此能并行解码出整个译文,大幅提升翻译速度。然而,非自回归模型在训练时缺乏目标端序列信息的指导,容易产生过翻译和漏翻译的错误。基于此,作者提出了两种方法来为非自回归模型引入序列信息。
在第一种方法中,基于非自回归模型的特性,设计了基于强化学习的高效、稳定的序列级训练方法(Reinforce-NAT)。
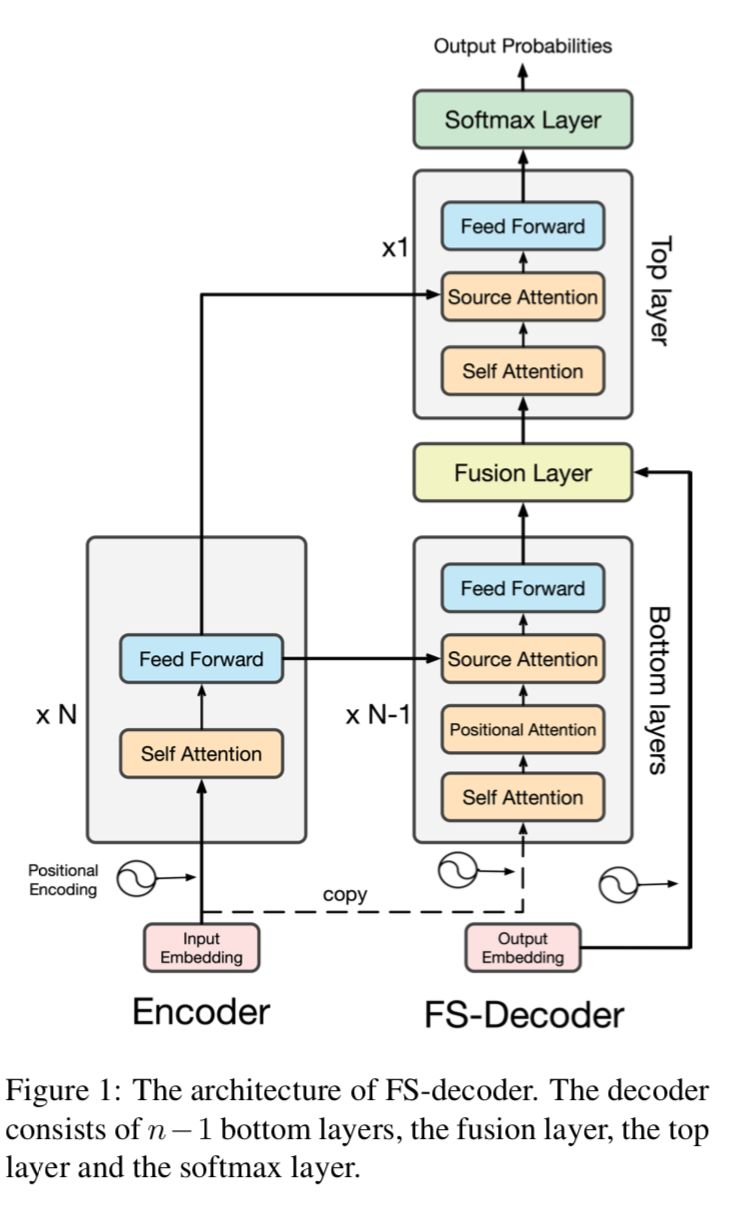
 在第二种方法中,设计了一种新的解码器结构,将序列信息融入到解码器的顶层中(FS-Decoder)。
在第二种方法中,设计了一种新的解码器结构,将序列信息融入到解码器的顶层中(FS-Decoder)。
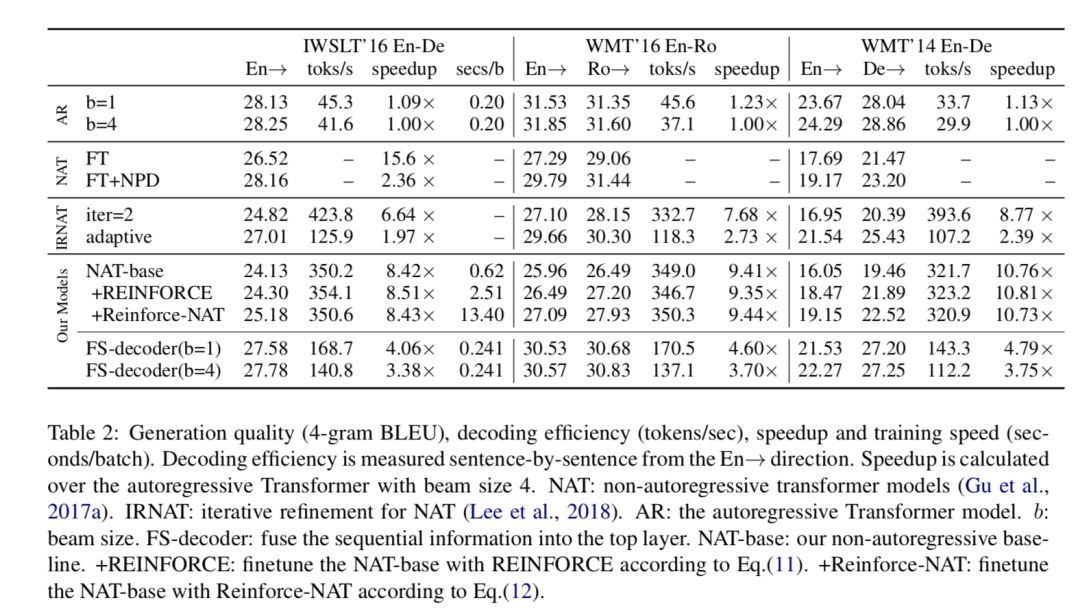
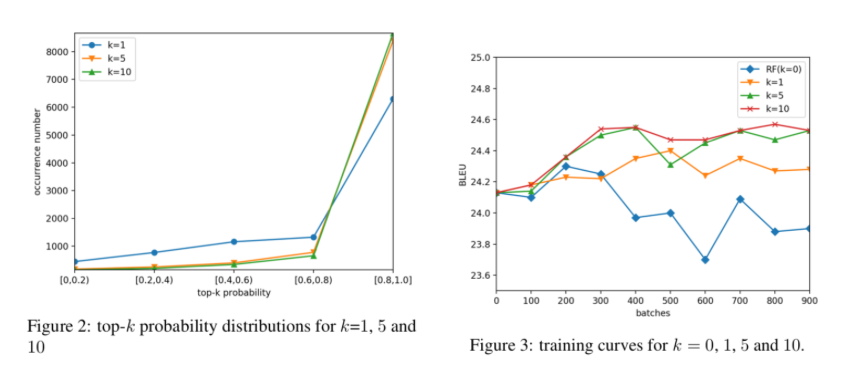
 实验结果显示,Reinforce-NAT方法能显著提升模型的翻译质量,并不损失解码速度,FS-Decoder能达到接近自回归模型的翻译效果,并仍保持非常可观的翻译解码速度提升。
实验结果显示,Reinforce-NAT方法能显著提升模型的翻译质量,并不损失解码速度,FS-Decoder能达到接近自回归模型的翻译效果,并仍保持非常可观的翻译解码速度提升。
5、《Rhetorically Controlled Encoder-Decoder for Modern Chinese Poetry Generation》基于修辞控制编码解码的现代汉语诗歌生成
本文由腾讯微信AI与美国罗格斯大学等合作完成。在这篇论文中,作者提出一种基于修辞控制的编码-解码模型,尝试将比喻、拟人等常用修辞融入用于现代汉语诗歌自动创作中。
论文地址: https://www.aclweb.org/anthology/P19-1192 近年来诗歌生成在文本自动生成领域得到了较大的关注。现代汉语诗歌中修辞是一种增强诗艺术效果的常用方法,在这篇论文中,作者尝试将比喻、拟人等常用修辞融入诗歌自动创作中。 具体而言,本文提出一种基于修辞控制的编码-解码模型用于现代汉语诗歌生成。该论文也是第一个将修辞引入文本生成任务中,以解决现有生成结果多样性不足的问题。
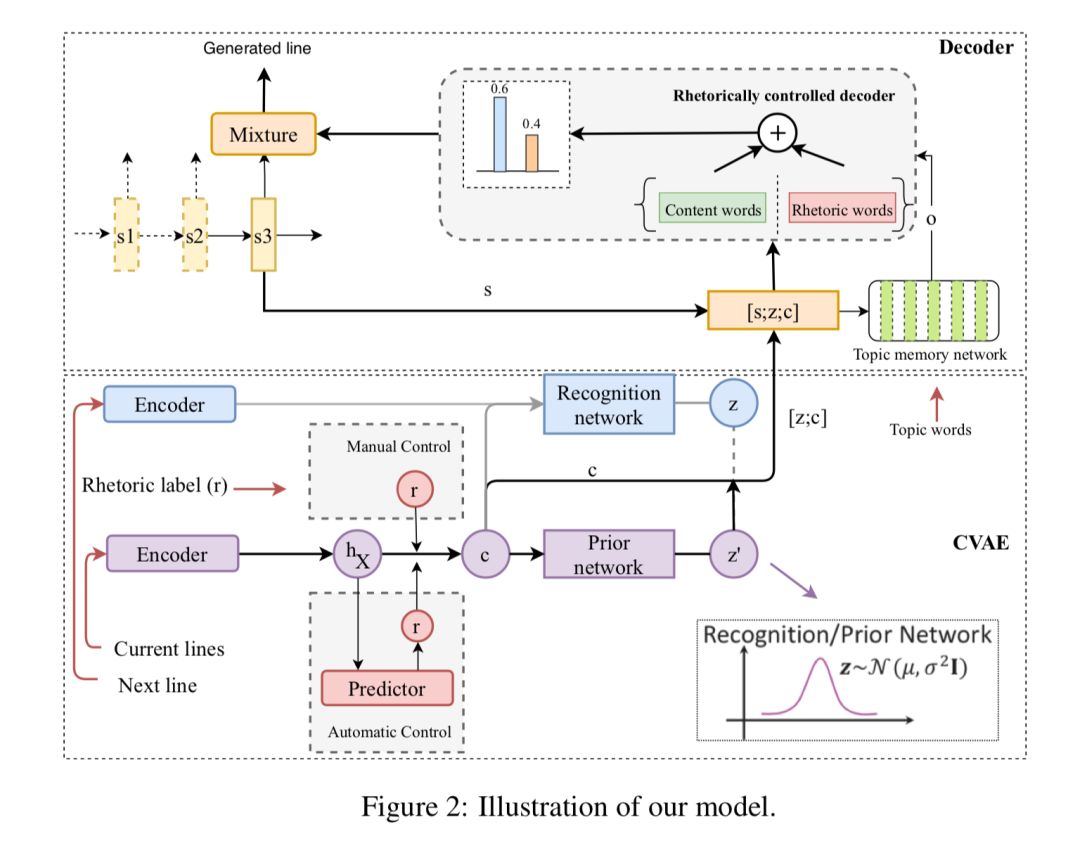 自动以及人工评测实验结果表明,该模型在现代汉语诗歌数据集生成修辞等效果显著,有效地增强了文本自动创作的多样性和艺术性。该模型在其他风格控制文本生成的场景下也有广泛的应用。
自动以及人工评测实验结果表明,该模型在现代汉语诗歌数据集生成修辞等效果显著,有效地增强了文本自动创作的多样性和艺术性。该模型在其他风格控制文本生成的场景下也有广泛的应用。

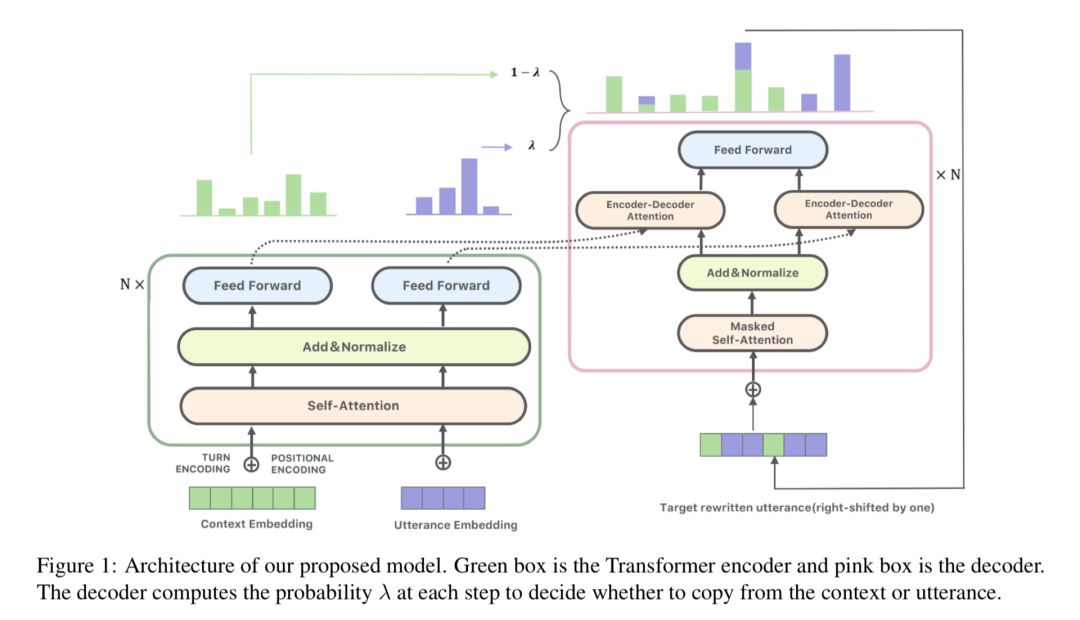
6、《Improving Multi-turn Dialogue Modelling with Utterance ReWriter》通过表达改写提升多轮对话系统效果
本文由腾讯微信AI与马克思普朗克研究所(Max Planck Institute Informatics)等联合完成。指代消解和信息省略是多轮对话系统面临的主要挑战之一。本文构建了一个高质量的中文对话改写数据集用于指代消解和信息补全,同时提出了一种表达(utterance)改写模型。 论文地址:
https://www.aclweb.org/anthology/P19-1003
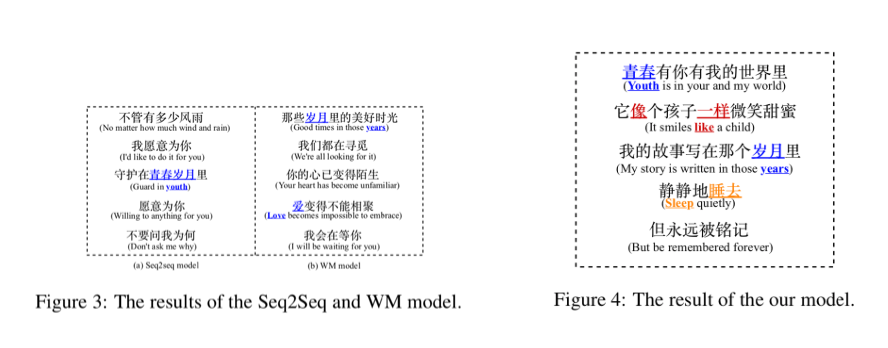
多轮对话系统旨在通过与用户进行多次问答的方式,更好的获取用户需求,并作出相应反应。指代消解和信息省略是多轮对话系统面临的主要挑战之一。
以下图为例,对于 Context 1 中的例子,用户的第二个问题“他和C罗谁是最好的球员?”中使用“他”来指代“梅西”;而对于Context 2 中的例子,用户的第二问题则并没有提及“最喜欢泰坦尼克”这一被发问对象。两种情况下,系统均需要对上下文进行分析,才能恢复回答相应问题所需要的信息。
论文地址:
https://www.aclweb.org/anthology/P19-1003
多轮对话系统旨在通过与用户进行多次问答的方式,更好的获取用户需求,并作出相应反应。指代消解和信息省略是多轮对话系统面临的主要挑战之一。
以下图为例,对于 Context 1 中的例子,用户的第二个问题“他和C罗谁是最好的球员?”中使用“他”来指代“梅西”;而对于Context 2 中的例子,用户的第二问题则并没有提及“最喜欢泰坦尼克”这一被发问对象。两种情况下,系统均需要对上下文进行分析,才能恢复回答相应问题所需要的信息。
 针对这两个挑战,本文构建了一个高质量的中文对话改写数据集用于指代消解和信息补全。同时提出了一种表达(utterance)改写模型,该模型通过将用户问题进行指代消解和信息补全后再生成回复的方式,实现用更成熟的单轮对话技术解决多轮对话问题的效果。
针对这两个挑战,本文构建了一个高质量的中文对话改写数据集用于指代消解和信息补全。同时提出了一种表达(utterance)改写模型,该模型通过将用户问题进行指代消解和信息补全后再生成回复的方式,实现用更成熟的单轮对话技术解决多轮对话问题的效果。
 以上图为例,Context 1 例子中,“他”被改写为“梅西”,而 Context 2 中,则补充了“最喜欢泰坦尼克”这一信息。
以上图为例,Context 1 例子中,“他”被改写为“梅西”,而 Context 2 中,则补充了“最喜欢泰坦尼克”这一信息。
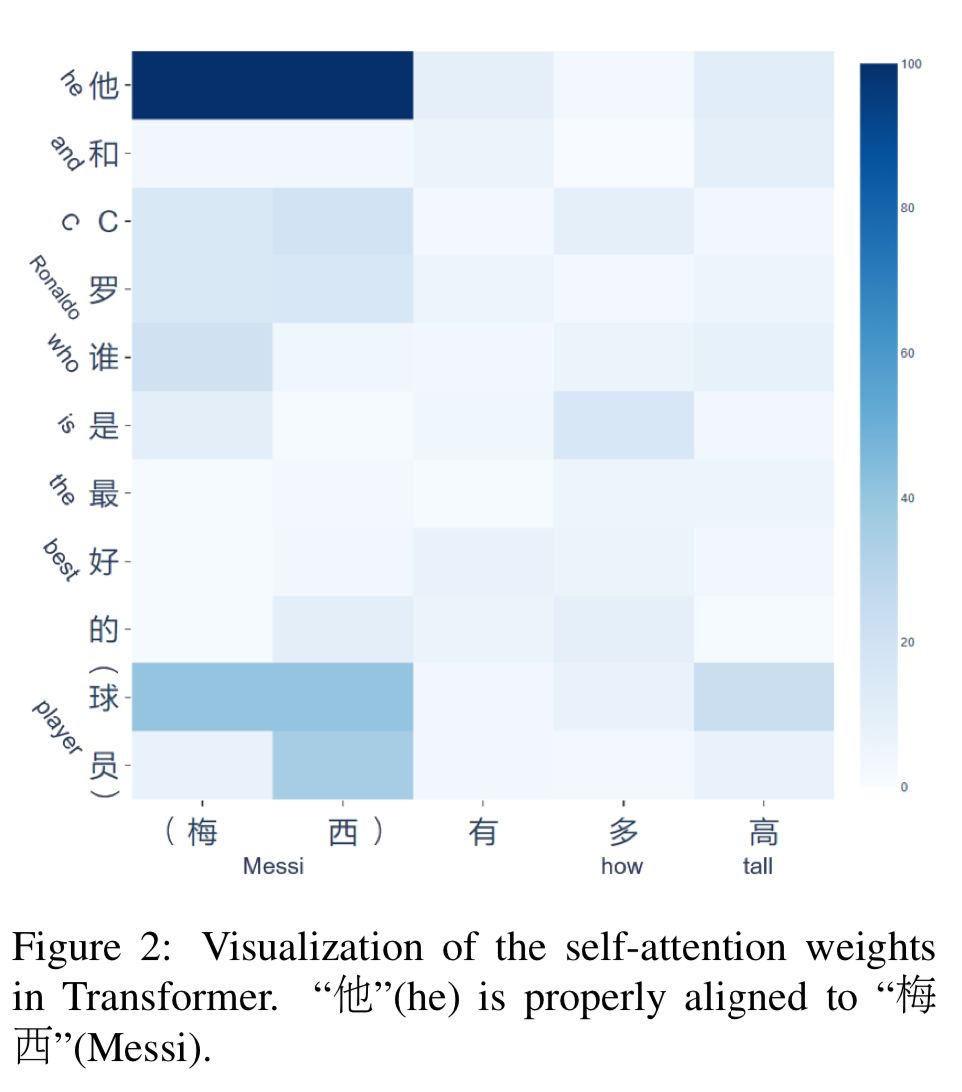
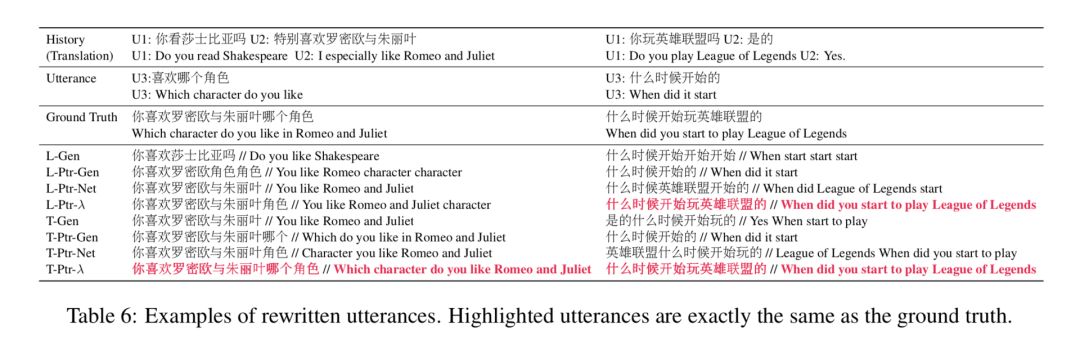 经过改写后,两个问题均无需查看上下文信息即可回答。实验结果显示,该方法对于任务导向型对话系统和闲聊型对话系统均有效果提升,为解决多轮对话问题提供了一种全新的思路。
经过改写后,两个问题均无需查看上下文信息即可回答。实验结果显示,该方法对于任务导向型对话系统和闲聊型对话系统均有效果提升,为解决多轮对话问题提供了一种全新的思路。

7、《Towards Fine-grained Text Sentiment Transfer》细粒度情感转换
本文由腾讯微信AI与北京大学联合完成。本文提出了一种细粒度情感转换模型Seq2SentiSeq,实现细粒度情感控制;另一方面,本文提出了一种环路强化学习(CycleRL)训练方法,解决标注数据稀缺的问题。
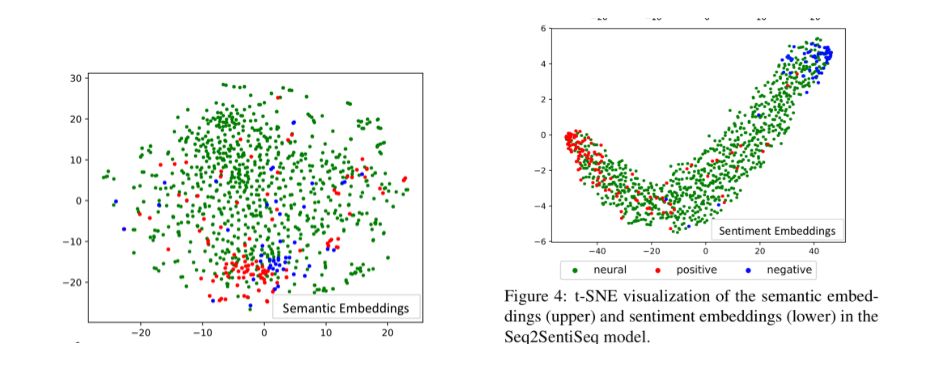
论文地址: https://www.aclweb.org/anthology/P19-1194 细粒度情感转换是指给定文本和实数值情感强度,在保持文本语义的前提下,对文本进行改写,使之表达相应情感的任务。示例见下图,其中情感强度0表示最负面,1表示最正面。
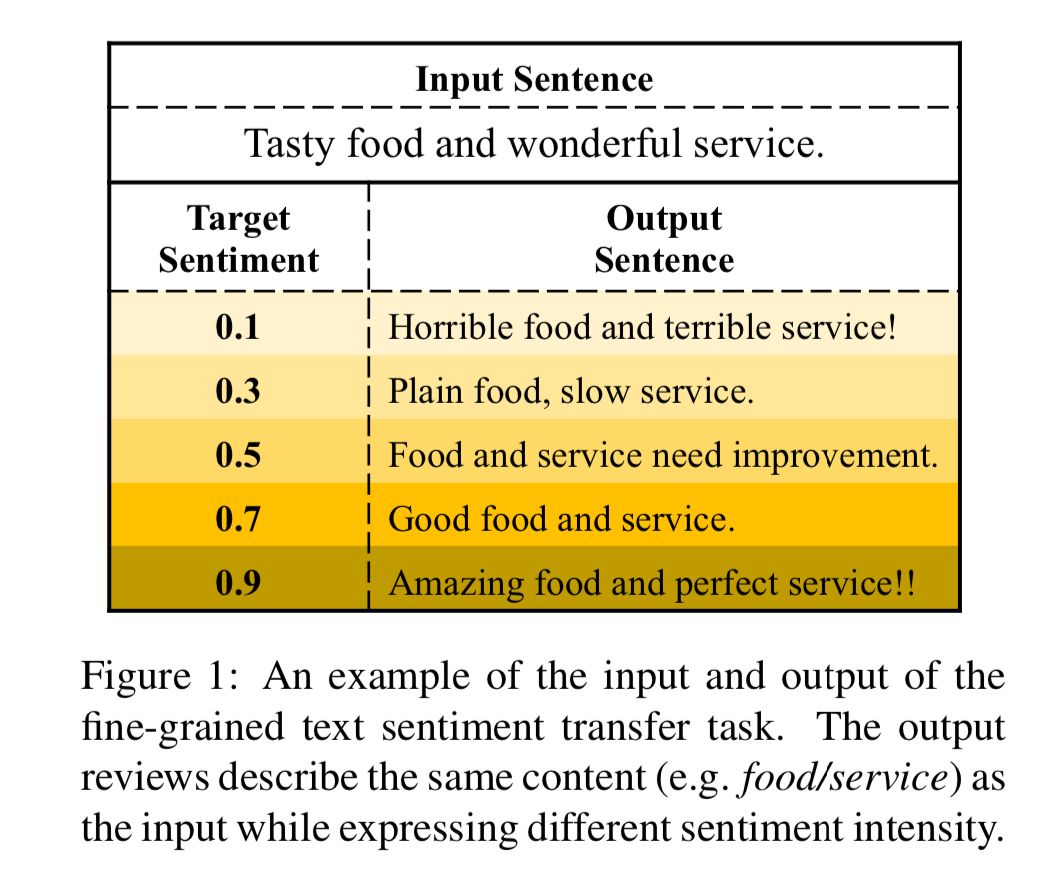 以往的情感转换工作只关注粗粒度的情感(如正向和负向情感),无法应用于情感强度连续变化的场景;同时这些工作都面临标注数据稀缺的问题。
针对以上两个挑战,本文提出了一种细粒度情感转换模型Seq2SentiSeq,该模型通过高斯核层(Gaussian kernel layer)将实数值情感强度信息融入模型,实现细粒度情感控制;另外,本文还提出了一种环路强化学习(CycleRL)训练方法,利用情感分类器和文本重构构造回报函数(reward),解决标注数据稀缺的问题。
以往的情感转换工作只关注粗粒度的情感(如正向和负向情感),无法应用于情感强度连续变化的场景;同时这些工作都面临标注数据稀缺的问题。
针对以上两个挑战,本文提出了一种细粒度情感转换模型Seq2SentiSeq,该模型通过高斯核层(Gaussian kernel layer)将实数值情感强度信息融入模型,实现细粒度情感控制;另外,本文还提出了一种环路强化学习(CycleRL)训练方法,利用情感分类器和文本重构构造回报函数(reward),解决标注数据稀缺的问题。
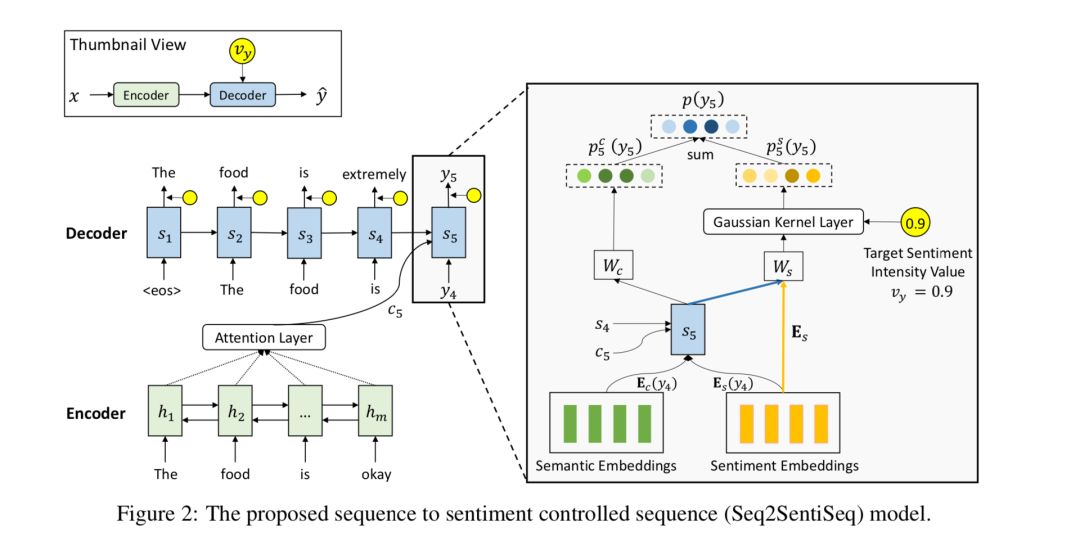
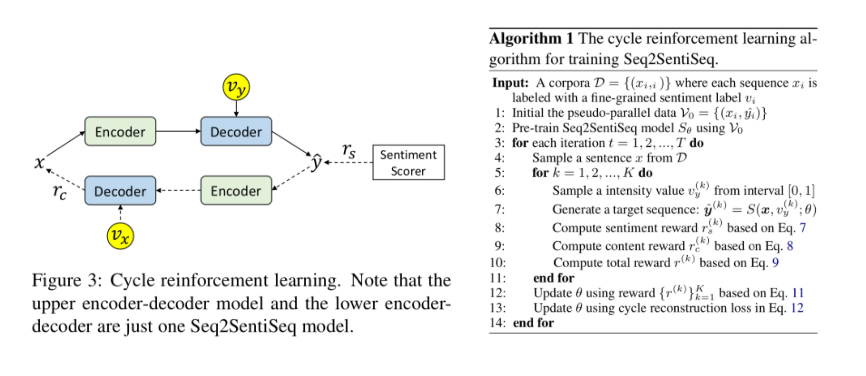 实验结果显示,本文方法在多个自动评估指标和人工评估指标下,均显著超过已有基线系统。人工检查转换结果也证实模型初步具备了细粒度情感转换的能力。
实验结果显示,本文方法在多个自动评估指标和人工评估指标下,均显著超过已有基线系统。人工检查转换结果也证实模型初步具备了细粒度情感转换的能力。
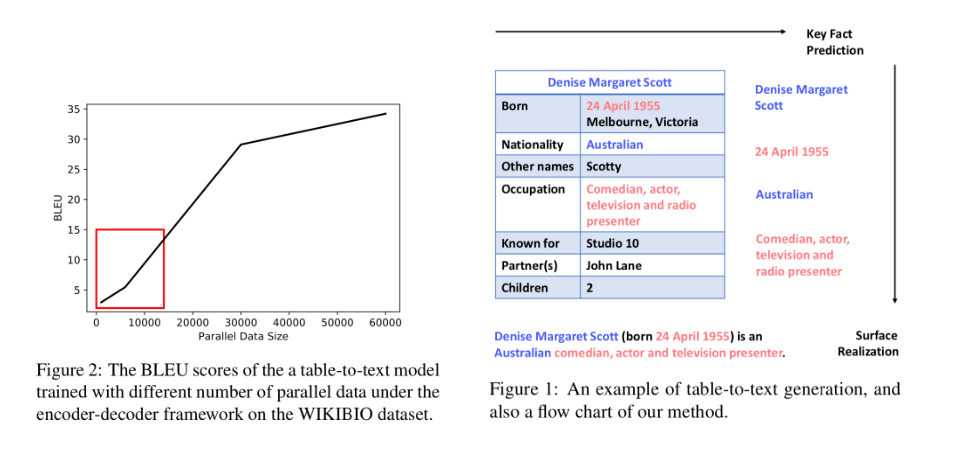
8、《Key Fact as Pivot: A Two-Stage Model for Low Resource Table-to-Text Generation》以关键事实为枢轴:一种两阶段的低资源的表格到文本生成模型
本文由腾讯微信AI与北京大学联合完成。这篇论文中,作者希望通过只使用少量“表格-文本”形式的样本即可实现表格到文本生成模型的训练。
论文地址: https://www.aclweb.org/anthology/P19-1197 将结构化的表格转换成非结构化的文本在自动内容生成方面具有重要应用(如天气预报生成、NBA新闻生成、人物生平生成等)。已有工作通常使用序列到序列模型(seq2seq model)来对这一问题建模,但序列到序列模型需要使用海量“表格-文本”形式的样本进行训练,而这种样本在实际场景中构造代价巨大,制约了这些模型的实际应用。
 本文希望通过只使用少量“表格-文本”形式的样本即可实现表格到文本生成模型的训练。本文中将表格到文本生成转换成两个阶段,在第一阶段,模型通过序列标注(sequence labeling)模型从表格中抽取关键事实,在第二阶段,以关键事实(一些短语序列)作为输入,使用序列到序列模型将其转换成目标文本。
本文希望通过只使用少量“表格-文本”形式的样本即可实现表格到文本生成模型的训练。本文中将表格到文本生成转换成两个阶段,在第一阶段,模型通过序列标注(sequence labeling)模型从表格中抽取关键事实,在第二阶段,以关键事实(一些短语序列)作为输入,使用序列到序列模型将其转换成目标文本。
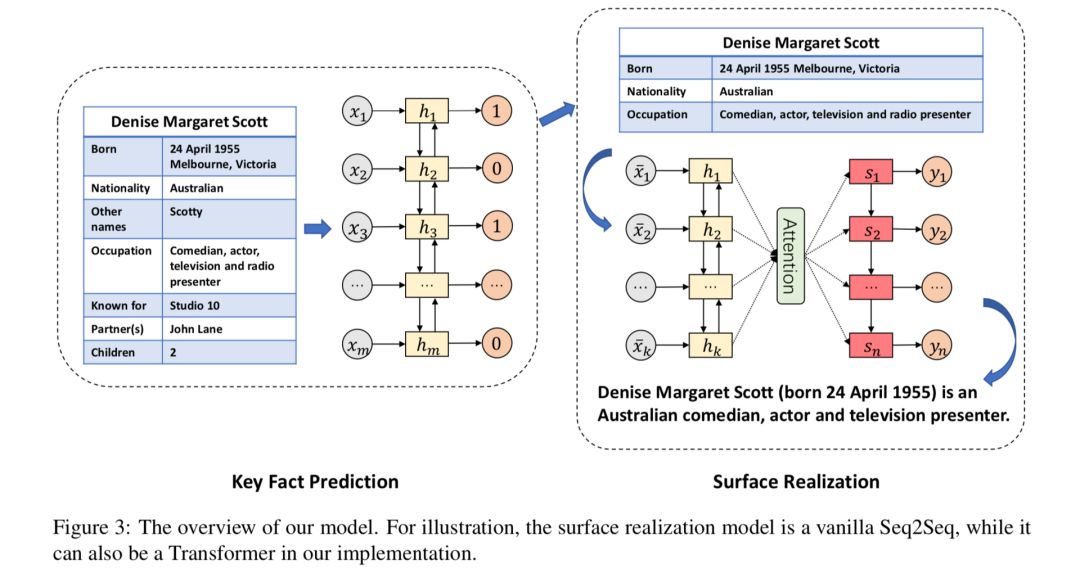 在第一阶段,实验显示,只需要1000条“表格-文本”形式的样本,即可训练得到效果可用的序列标注模型;在第二阶段模型训练过程中,将自然语言句子中的实词作为伪关键事实,自动生成大量伪训练样本用于训练序列到序列模型,同时通过增词和删词的方式构造对抗样本,提升模型的鲁棒性,从而实现不依赖于“表格-文本”形式的样本即可训练该阶段模型的效果。
在第一阶段,实验显示,只需要1000条“表格-文本”形式的样本,即可训练得到效果可用的序列标注模型;在第二阶段模型训练过程中,将自然语言句子中的实词作为伪关键事实,自动生成大量伪训练样本用于训练序列到序列模型,同时通过增词和删词的方式构造对抗样本,提升模型的鲁棒性,从而实现不依赖于“表格-文本”形式的样本即可训练该阶段模型的效果。
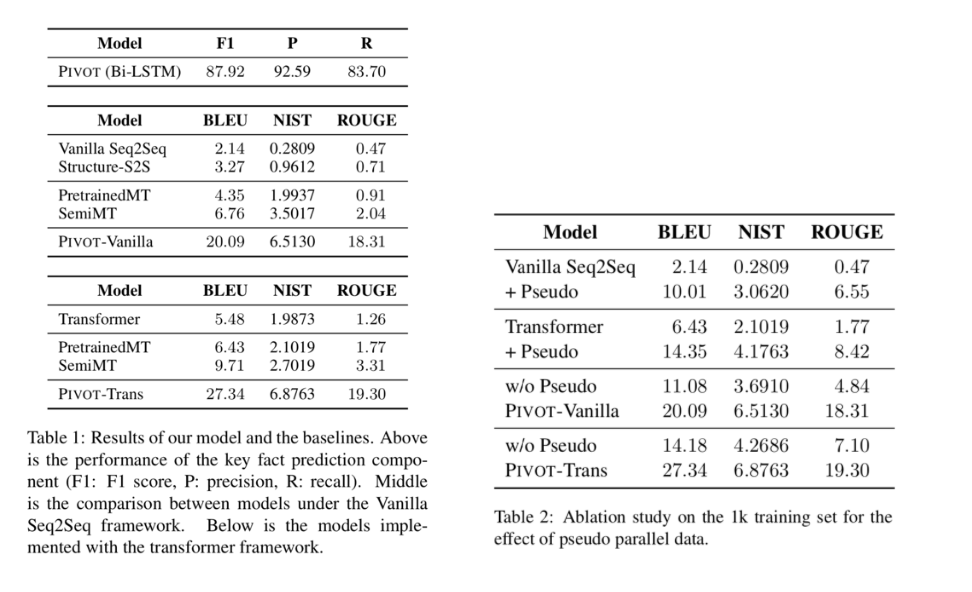 实验结果显示,在只使用1000条“表格-文本” 形式的样本的条件下,本文模型显著超过已往的有监督方法,同时模型的实际效果与使用大规模“表格-文本”形式的样本训练的有监督模型可比。
9、《DocRED: A Large-Scale Document-Level Relation Extraction Dataset》DocRED:大规模篇章级关系抽取数据集
实验结果显示,在只使用1000条“表格-文本” 形式的样本的条件下,本文模型显著超过已往的有监督方法,同时模型的实际效果与使用大规模“表格-文本”形式的样本训练的有监督模型可比。
9、《DocRED: A Large-Scale Document-Level Relation Extraction Dataset》DocRED:大规模篇章级关系抽取数据集
本文由腾讯微信AI与清华大学联合完成。本文提出了目前最大的篇章级精标注关系抽取数据集DocRED。目前DocRED已可公开获取,同时,还有相关竞赛,对这个领域感兴趣的小伙伴们可以关注,参与一波~

 在该数据集中,超过40.7%的关系事实必须联合多个句子的信息才能被正确抽取,对关系抽取模型提出了更高的要求。此外,该数据集还额外提供了大规模的采用远距离监督技术标注的数据,以支持半监督方法的研究。
在该数据集中,超过40.7%的关系事实必须联合多个句子的信息才能被正确抽取,对关系抽取模型提出了更高的要求。此外,该数据集还额外提供了大规模的采用远距离监督技术标注的数据,以支持半监督方法的研究。
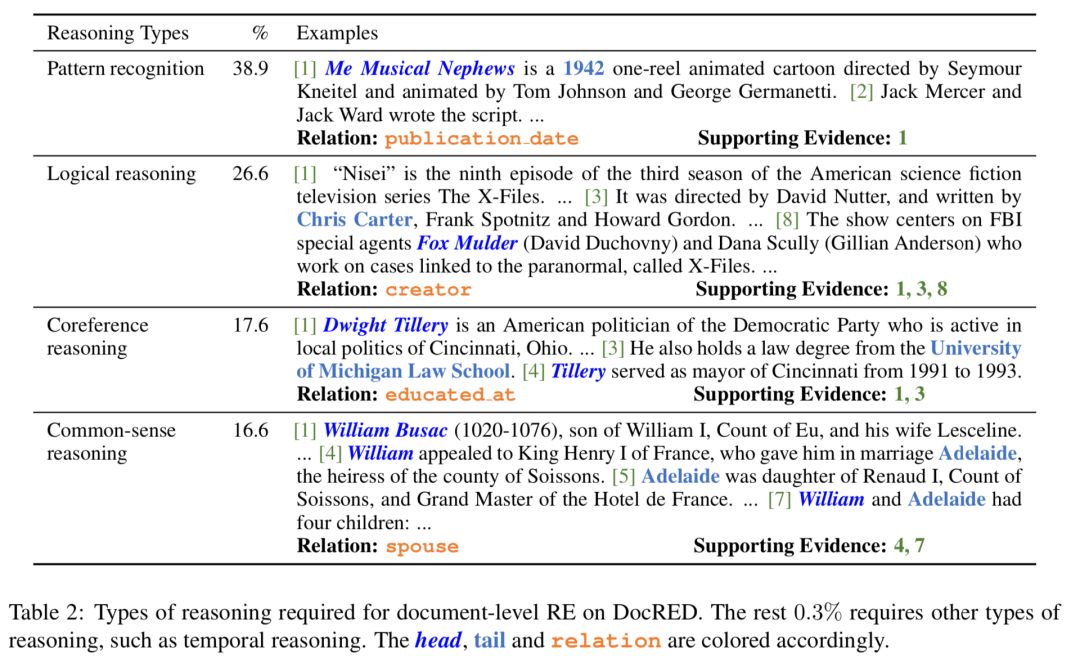 数据示例:每篇文章都被标注了实体(entity mention,蓝色或下划线)、句内/间关系(intra-/inter-sentence relation,橙色),以及支持证据(supporting evidence)。该例子展示了该篇文章中19个关系事实中的2个。需特别说明的是,同一个实体的不同别称会被归并(如Kungliga Hovkapellet和Royal Court Orchestra)。
数据示例:每篇文章都被标注了实体(entity mention,蓝色或下划线)、句内/间关系(intra-/inter-sentence relation,橙色),以及支持证据(supporting evidence)。该例子展示了该篇文章中19个关系事实中的2个。需特别说明的是,同一个实体的不同别称会被归并(如Kungliga Hovkapellet和Royal Court Orchestra)。
(*本文为 AI科技大本营整理文章,转载请联系微信 1092722531)
社群福利
扫码添加小助手,回复:大会,加入2019 AI开发者大会福利群,每周一、三、五更新技术福利,还有不定期的抽奖活动~

◆
精彩推荐
◆
60+技术大咖与你相约 2019 AI ProCon!大会早鸟票已售罄,优惠票速抢进行中......2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。
推荐阅读
认知智能的突围:NLP、知识图谱是AI下一个“掘金地”?
自动驾驶激荡风云录:来自圈内人的冷眼解读
华人“霸榜”ACL最佳长短论文、杰出论文一作,华为、南理工等获奖
5G+AI重新定义生老病死
干货 | 20个Python教程,掌握时间序列的特征分析(附代码)
2019 年度程序员吸金榜:你排第几?
字节跳动入局全网搜索;思科回应中国区裁员;IntelliJ IDEA 新版发布! | 极客头条
AI+DevOps正当时
知名饮料制造商股价暴涨500%惊动FBI,只因在名字中加入了"区块链" ?
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
![解决python报错[SSL: CERTIFICATE_VERIFY_FAILED] certifi](https://img-blog.csdnimg.cn/img_convert/fad536e972e14ce4b37803185dc3b00c.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)
相关标签

