
- 1【信息融合与状态估计】基于Kalman滤波和现代时间序列分析方法,利用集中式融合估计、分布式融合估计(按矩阵加权、按对角阵加权、按标量加权)、 协方差交叉融合等方法实现对状态的融合估计(Matlab)
- 2Node.js开发-fs模块
- 3KMeans算法,采用肘部法则获取类簇中心个数K的值。_k-means肘部法
- 4k8s创建资源_k8s 创建资源实例
- 5快速入门:配置 Visual Studio 以使用 Unity 进行跨平台开发_visual studio unity
- 6数字图像处理课程设计---基于CNN(卷积神经网络)的医学影像识别_.构建cnn网络实现图像处理
- 73D Gaussian Splatting学习记录11.3_3dgaussian splatting与传统三维重建的对比
- 8基于单片机的红绿黄灯设计(单片机实验交通灯设计)_单片机红绿灯的设计实验报告
- 9Cassandra(一)之linux中的下载和安装_cassandra linux 客户端
- 10广州蓝景分享—快速了解Typescript 5.0 中重要的新功能_import '.tsx' 'allowimportingtsex
Python3 正则表达式
赞
踩
正则表达式(Regular Expression)是一段字符串,它可以表示一段有规律的信息。Python自带一个正则表达式模块,通过这个模块可以查找、提取、替换一段有规律的信息。
比如,在程序开发中,要让计算机程序从一大段文本中找到需要的内容,就可以使用正则表达式来实现。使用正则表达式有如下步骤。
(1)寻找规律。
(2)使用正则符号表示规律。
(3)提取信息。
一、正则表达式的基本符号
1.点号“.”
一个点号可以代替除了换行符以外的任何一个字符,包括但不限于英文字母、数字、汉字、英文标点符号和中文标点符号。
2.星号“*”
一个星号可以表示它前面的一个子表达式(普通字符、另一个或几个正则表达式符号)0次到无限次。既然星号可以表示它前面的字符,那么如果它前面的字符是一个点号呢?
猿.*猴子
它表示在“猿”和“猴子”中间出现“任意多个除了换行符以外的任意字符”。这句话看起来有点绕,用下面几个字符串来说明,它们全部都可以用上面的这个正则表达式来表示:
猿猴子
猿小猴子
猿我不知道猴子
猿PythonJsGo猴子
3.问号“? ”
问号表示它前面的子表达式0次或者1次。注意,这里的问号是英文问号。问号最大的用处是与点号和星号配合起来使用,构成“.*? ”。通过正则表达式来提取信息的时候,用到最多的也是这个组合。
4.反斜杠“\”
反斜杠在正则表达式里面不能单独使用,甚至在整个Python里都不能单独使用。反斜杠需要和其他的字符配合使用来把特殊符号变成普通符号,把普通符号变成特殊符号。
在正则表达式里面,很多符号都是有特殊意义的,例如问号、星号、大括号、中括号和小括号。反斜杠不仅可以把特殊符号变成普通符号,还可以把普通符号变成特殊符号。例如“n”只是一个普通的字母,但是“\n”代表换行符。在Python开发中,经常遇到的转义字符,如表所示。
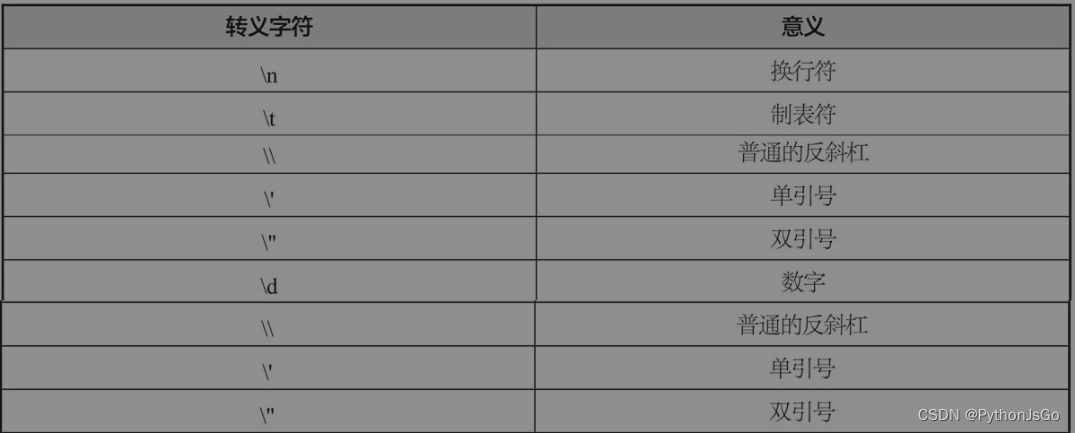
在使用了反斜杠以后,反斜杠和它后面的一个字符构成一个整体,因此应该将“\n”看成一个字符,而不是两个字符。
5.数字“\d”
正则表达式里面使用“\d”来表示一位数字。为什么要用字母d呢?因为d是英文“digital(数字)”的首字母。再次强调一下,“\d”虽然是由反斜杠和字母d构成的,但是要把“\d”看成一个正则表达式符号整体。如果要提取两个数字,可以使用\d\d;如果要提取3个数字,可以使用\d\d\d。但是如果不知道这个数有多少位怎么办呢?就需要用*号来表示一个任意位数的数字。
6.小括号“()”
小括号可以把括号里面的内容提取出来。前面讲到的符号仅仅能让正则表达式“表示”一串字符串。但是如果要从一段字符串中“提取”出一部分的内容应该怎么办呢?这个时候就需要使用小括号了。
二、在Python中使用正则表达式
Python已经自带了一个功能非常强大的正则表达式模块。使用这个模块可以非常方便地通过正则表达式来从一大段文字中提取有规律的信息。Python的正则表达式模块名字为“re”,也就是“regular expression”的首字母缩写。在Python中需要首先导入这个模块再进行使用。导入的语句为:
import re
1.findall
Python的正则表达式模块包含一个findall方法,它能够以列表的形式返回所有满足要求的字符串。findall的函数原型为:
re.findall(pattern, string, flags=0)
pattern表示正则表达式,string表示原来的字符串,flags表示一些特殊功能的标志。findall的结果是一个列表,包含了所有的匹配到的结果。如果没有匹配到结果,就会返回空列表。
当需要提取某些内容的时候,使用小括号将这些内容括起来,这样才不会得到不相干的信息。如果包含多个“(.*? )”怎么返回呢?返回的仍然是一个列表,但是列表里面的元素变为了元组。
函数原型中有一个flags参数。这个参数是可以省略的。当不省略的时候,具有一些辅助功能,例如忽略大小写、忽略换行符等。这里以忽略换行符为例来进行说明,在爬虫的开发过程中非常容易出现这样的情况,要匹配的内容存在换行符“\n”。要忽略换行符,就需要使用到“re.S”这个flag。虽然说匹配到的结果中出现了“\n”这个符号,不过总比什么都得不到强。内容里面的换行符在后期清洗数据的时候把它替换掉即可。
2.search
search()的用法和findall()的用法一样,但是search()只会返回第1个满足要求的字符串。一旦找到符合要求的内容,它就会停止查找。对于从超级大的文本里面只找第1个数据特别有用,可以大大提高程序的运行效率。search()的函数原型为:
re.search(pattern, string, flags=0)
对于结果,如果匹配成功,则是一个正则表达式的对象;如果没有匹配到任何数据,就是None。如果需要得到匹配到的结果,则需要通过.group()这个方法来获取里面的值,只有在.group()里面的参数为1的时候,才会把正则表达式里面的括号中的结果打印出来。.group()的参数最大不能超过正则表达式里面括号的个数。参数为1表示读取第1个括号中的内容,参数为2表示读取第2个括号中的内容,以此类推。
3.“.*”和“.*? ”的区别
在爬虫开发中,.*?这3个符号大多数情况下一起使用。点号表示任意非换行符的字符,星号表示匹配它前面的字符0次或者任意多次。所以“.*”表示匹配一串任意长度的字符串任意次。这个时候必须在“.*”的前后加其他的符号来限定范围,否则得到的结果就是原来的整个字符串。如果在“.*”的后面加一个问号,变成“.*? ”,那么可以得到什么样的结果呢?问号表示匹配它前面的符号0次或者1次。于是.*?的意思就是匹配一个能满足要求的最短字符串。
使用“(.*)”得到的是只有一个元素的列表,里面是一个很长的字符串。使用第2个正则表达式“(.*? )”,得到的结果是包含4个元素的列表,每个元素直接对应原来文本中的每个密码。举一个例子,10个人肩并肩并排站着,使用“(.*)”取到了第1个人左手到第10个人右手之间的所有东西,而使用“(.*? )”取到的是“每个人”的左手和右手之间的东西。一句话总结如下:
①“.*”:贪婪模式,获取最长的满足条件的字符串。
②“.*? ”:非贪婪模式,获取最短的能满足条件的字符串。
三、正则表达式提取技巧
1.不需要compile
网上很多人的文章中,正则表达式使用re.compile()这个方法,导致代码变成下面这样:
import re
example_text = ’我是pYTHONjSgO, 我的微博账号是:猿小猴子, 密码是:12345678, QQ账号是:99999, 密
码是:666666, 银行卡账号是:000001, 密码是:888888, Github账号是:99999@qq.com, 密码
是:520520, 请记住他们。'
new_pattern=re.compile(’账号是:(.*? ), 密码是:(.*? ), ', re.S)
user_pass = re.findall(new_pattern, example_text)
print(user_pass)
这种写法虽然结果正确,但纯粹是画蛇添足,是对Python的正则表达式模块没有理解透彻的体现,是从其他编程语言中带来的坏习惯。如果阅读Python的正则表达式模块的源代码,就可以看出re.compile()是完全没有必要的。对比re.compile()和re.findall()在源代码中的写法:
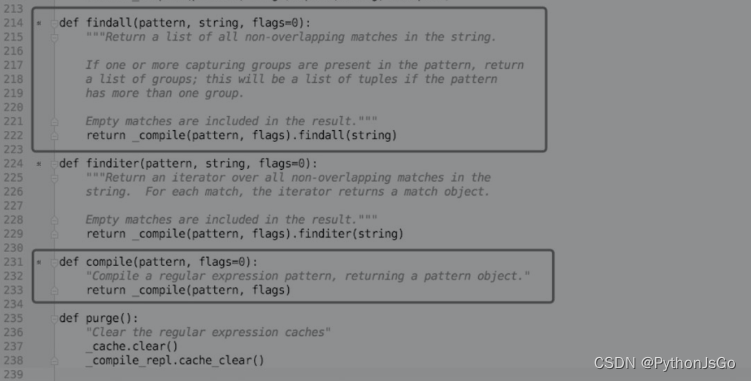
使用re.compile()的时候,程序内部调用的是_compile()方法;当使用re.finall()的时候,在模块内部自动先调用了_compile()方法,再调用findall()方法。re.findall()自带re.compile()的功能,所以没有必要使用re.compile()。Python 3中正则表达式模块的源代码的入口文件为re.py (re.py在Python 3安装文件夹下面的Lib文件夹中)。这个文件里面的注释就是学习Python正则表达式模块非常好的文档,它包含了正则表达式各种符号的简单说明和这个模块内部各个方法的使用。
2.先抓大再抓小
一些无效内容和有效内容可能具有相同的规则。这种情况下很容易把有效内容和无效内容混在一起,要解决这个问题,就需要使用先抓大再抓小的技巧。先把有效的这个整体匹配出来,再从有效整体里面匹配出想要的精确信息。先抓大再抓小的思想会贯穿整个爬虫开发过程。
3.括号内和括号外
在上面的例子中,括号和“.*? ”都是一起使用的,因此可能会认为括号内只能有这3种字符,不能有其他普通的字符。但实际上,括号内也可以有其他字符。
如果括号里面有其他普通字符,那么这些普通字符就会出现在获取的结果里面。举一个例子,如果说“左手和右手之间”,一般指的是躯干这一部分。但如果说“左手和右手之间,包括左手和右手”,那么就是指的整个人。而把普通的字符放在括号里面,就表示结果中需要包含它们。
--------------------------------------
版权声明:本文为【PythonJsGo】博主的文章,同步在【猿小猴子】公众号平台,转载请附上原文出处链接及本声明。

