
热门标签
热门文章
- 1AQS及其原理_aqs的waitstatus
- 2node-npm 设置淘宝镜像_npm 淘宝
- 3【Linux取经路】基础I/O之重定向的实现原理
- 4阿里云服务器-攻击方法:GET攻击类型:其他_中国北京 阿里云 get类型共计
- 5思科防火墙应用NAT_思科防火墙nat
- 6chatgpt赋能Python-python编写程序怎么保存
- 7logback 配置 日志_logback 配置level 为info 为什么会打印debug日志
- 8Linux -1.4工作目录切换命令(pwd,cd,ls)_、使用cd切换到根目录,pwd输出当前路径,ls查看当前路径详情
- 9使用Xshell调用linux的图形界面!_xshell 运行linux ui
- 10shell脚本中使用top命令查看cpu或内存情况的技巧_shell top
当前位置: article > 正文
李沐动手学习深度学习——3.2练习
作者:从前慢现在也慢 | 2024-02-29 11:53:38
赞
踩
李沐动手学习深度学习——3.2练习
以下是个人理解,希望进行讨论求解。
练习
1. 如果我们将权重初始化为零,会发生什么。算法仍然有效吗?
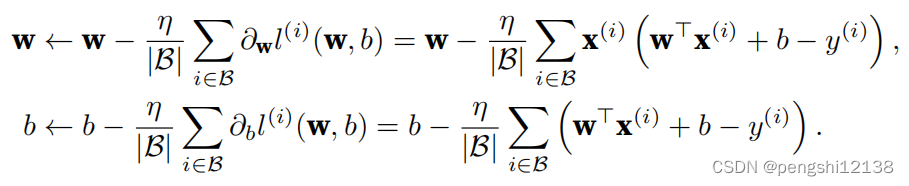
根据SGD算法公式如上,第一次迭代的值可知w只与b相关,而对于b的迭代更新,只是与b的初始值相关,x没有参与迭代的计算过程中,不能够达到收敛的目的。
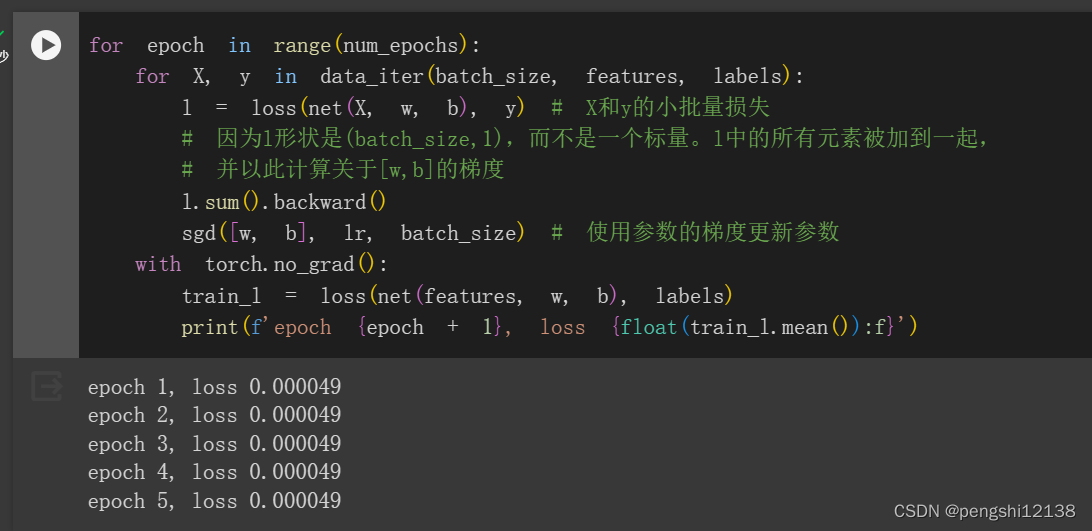
进行运行可以如下结果:

2. 假设试图为电压和电流的关系建立一个模型。自动微分可以用来学习模型的参数吗?
显而易见可行,因为 UR=I,I和U的关系是线性关系。
3. 能基于普朗克定律使用光谱能量密度来确定物体的温度吗?
能基于普朗克定律使用光谱能量密度如下:
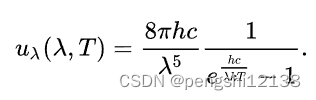
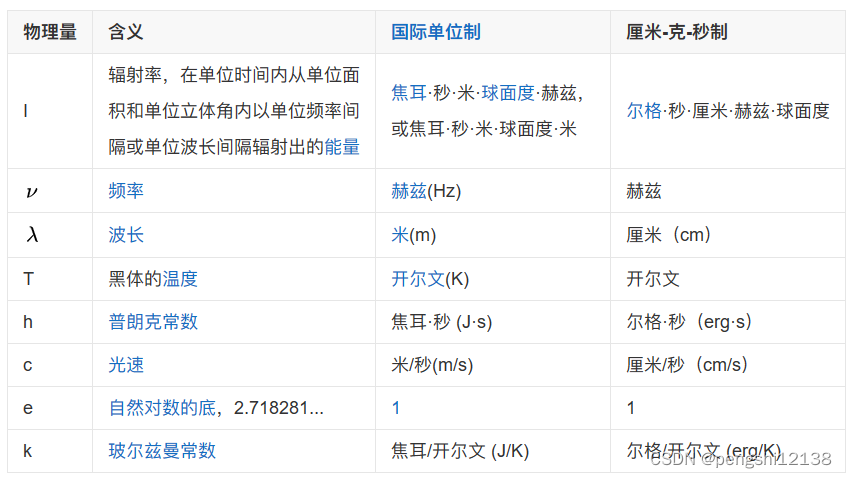
推导公式最后如下,可得其u与T之间是线性关系,是正比情况,所以可以利用SGD的方法通过数据进行拟合。
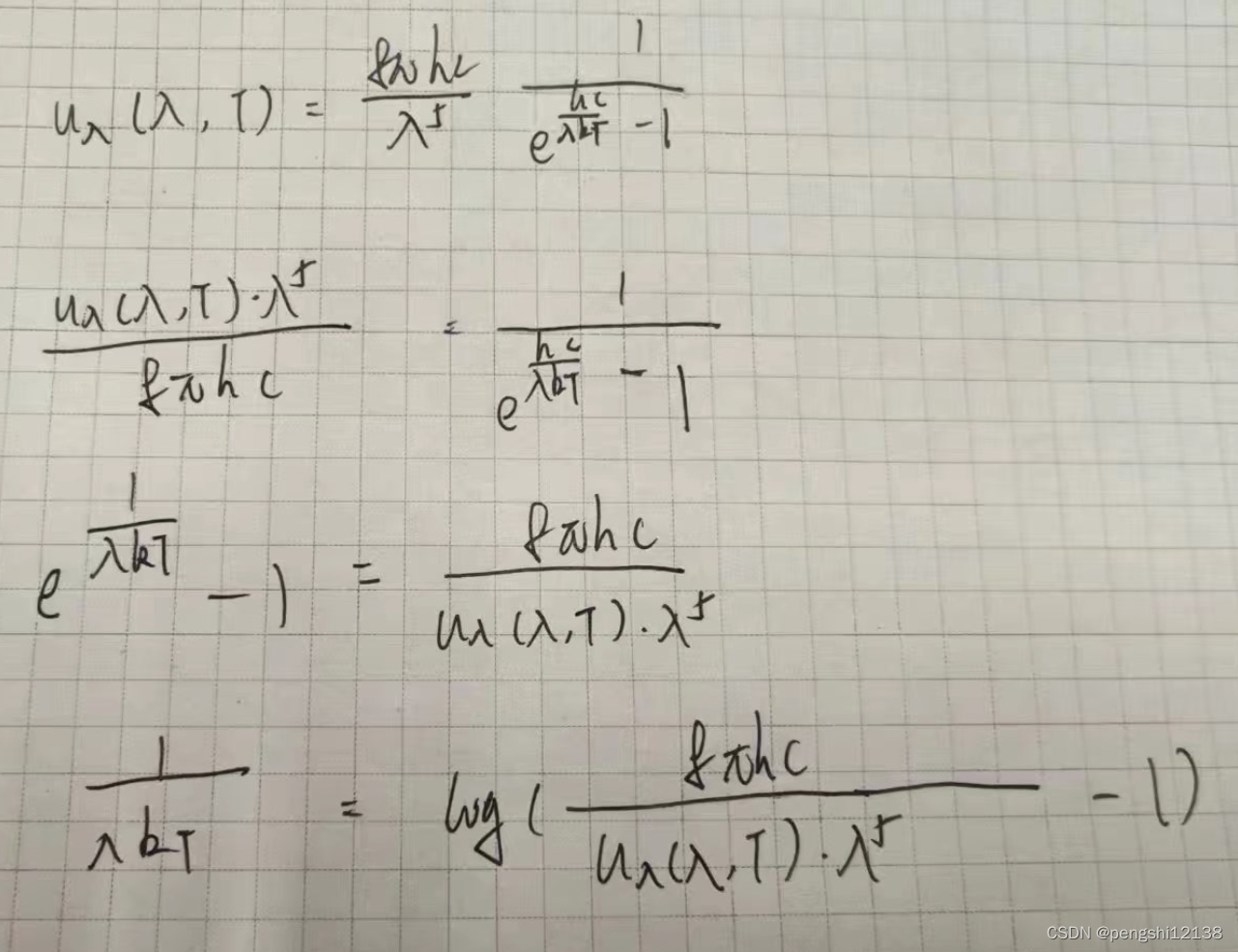
4. 计算二阶导数时可能会遇到什么问题?这些问题可以如何解决?
显而易见存在一阶导数光滑,但是二阶导数曲线不光滑的情况,类似于一阶导数驻点突变问题。利用阈值判断停止计算,或者调整学习率等,参考上一章的答案。以上是我能够想到的问题。显然不是足够,所以动用一下gpt帮忙:

5. 为什么在squared_loss函数中需要使用reshape函数?
要将真实值y的形状转换为和预测值y_hat的形状相同。根据函数矩阵计算可知,x是102大小,w是21,得出的y_hat是101,但是y是110,所以需要转置。
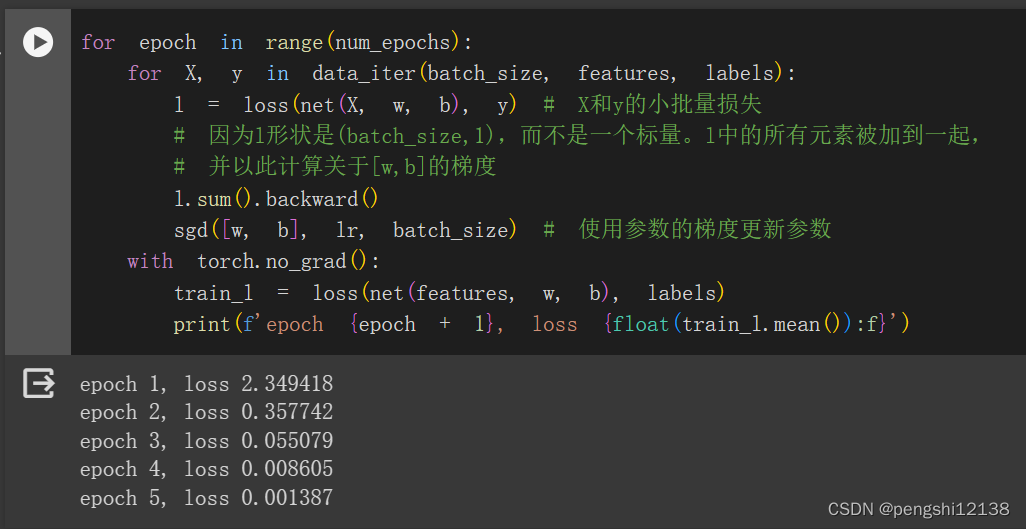
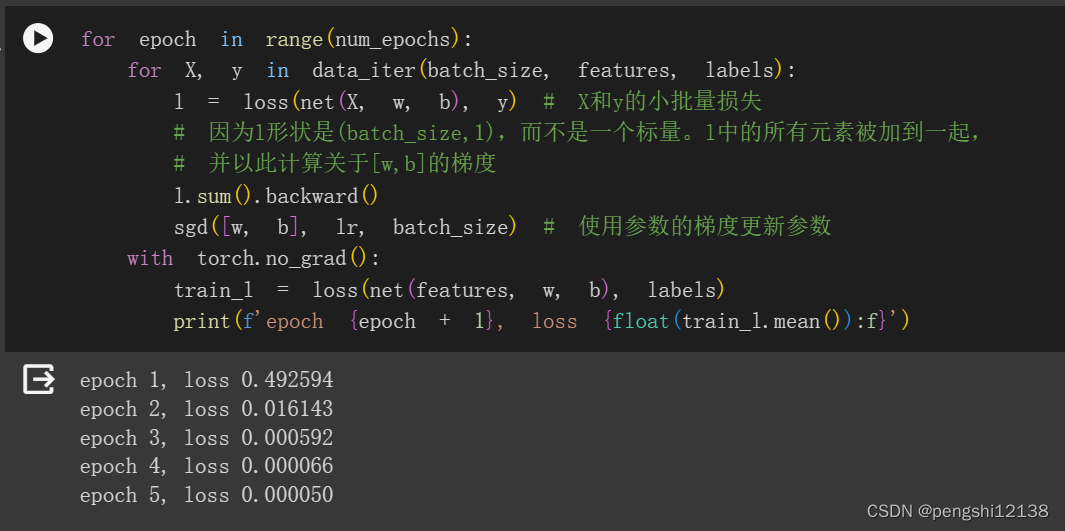
6. 尝试使用不同的学习率,观察损失函数值下降的快慢。
学习率0.01的时候
学习率0.02的时候
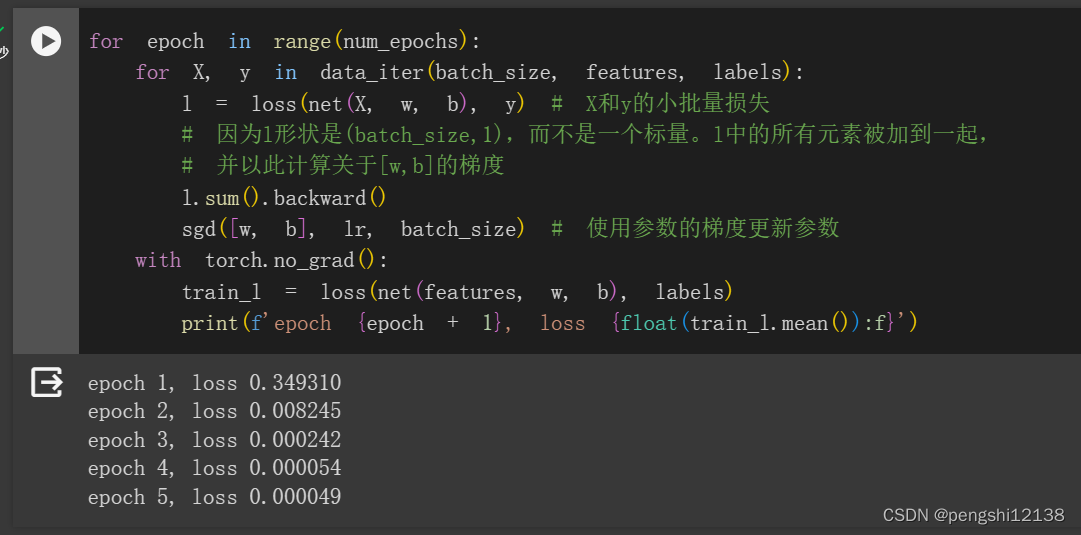
可知道收敛速度不同,收敛精度不同
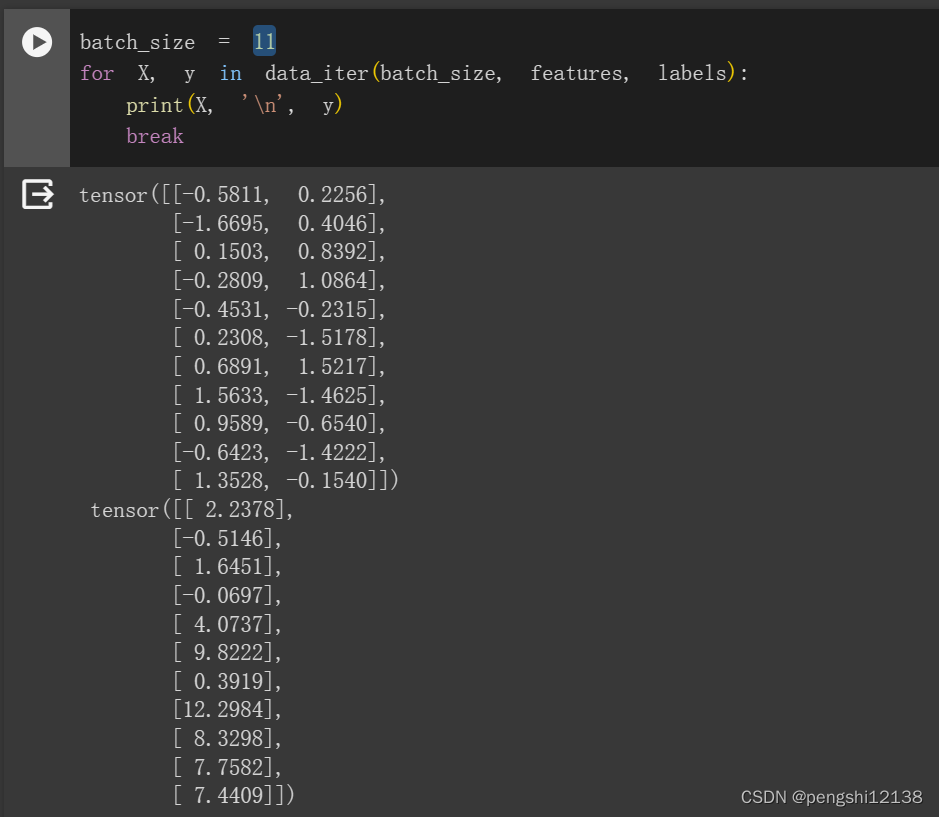
7. 如果样本个数不能被批量大小整除,data_iter函数的行为会有什么变化?
修改代码batch_size设置为11,进行运行,发现可运行,说明了最后一个batch直接被运算抛弃了,不参与计算。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/165445
推荐阅读

相关标签

