
- 1CSP历年试题记录-(更新中ing...)_csp2023九月题目
- 2Nginx服务器及其配置与应用
- 3Python基于微博的舆情分析,情感分析可视化系统(V2.0),附源码,数据库
- 4uniapp模仿下拉框实现文字联想功能 - uniapp输入联想(官方样式-附源码)
- 5K8S中部署apisix(非ingress)_k8s apisix
- 6LeetCode解法汇总232. 用栈实现队列
- 7tomcat是什么?它有什么功能和特性?它值不值得我们去学习?我们该如何去学习呢?_tomcat的作用和特点
- 8常见的反爬虫技术_反爬虫手段有哪些
- 9MongoDB精简入门(体系结构、Docker安装MangoDB、常用命令)_docker安装的mongodb如何查看配置
- 10Linux系统常用的基本命令_linnux常见的基本命令
LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODELS_lora: low-rank adaptation of large lan- guage mode
赞
踩
Paper name
LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODELS
Paper Reading Note
Paper URL: https://arxiv.org/pdf/2106.09685.pdf
Code URL:
- huggingface 集成: https://github.com/huggingface/peft
- 官方代码: https://github.com/microsoft/LoRA
TL;DR
- 本文提出了低秩自适应 (Low-Rank Adaptation, LoRA),它冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层,极大地减少了下游任务的可训练参数的数量,有效提升预训练模型在下游任务上的 finetune 效率
Introduction
背景
- 自然语言处理的一个重要范式包括对一般领域数据的大规模预训练(pretrain)和对特定任务或领域的适应(finetune)
- 当预训练模型的参数量较大时,完全的微调(重新训练所有模型参数)变得不太可行
- 以GPT-3 175B为例,部署经过微调的模型的独立实例,每个实例都有175B参数,这是非常昂贵的
本文方案
-
本文提出了低秩自适应 (Low-Rank Adaptation, LoRA),它冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层,极大地减少了下游任务的可训练参数的数量
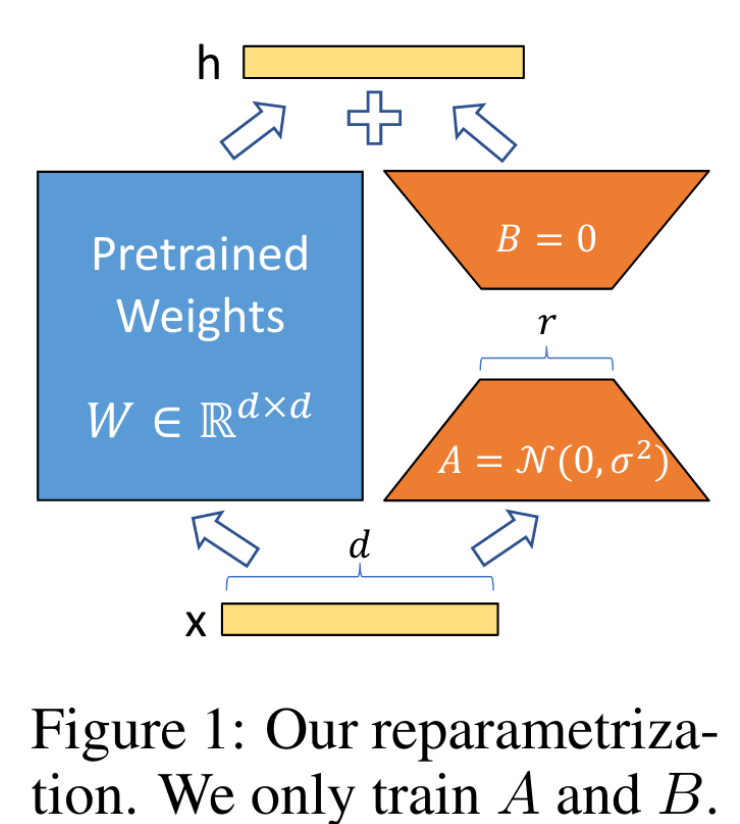
LoRA 通过优化 dense layer 的变化的秩分解矩阵来间接训练 dense layer,保持预训练模型参数冻结。上图中的矩阵秩 ® 可以非常低,比如对于 GPT-3 175B 模型,rank-1 或 rank-2 就能基本对齐原始 rank-12288 的效果 -
与 Adam 微调的 GPT-3 175B 相比,LoRA 可训练参数数量减少了 1 万倍,GPU 内存需求减少了 3 倍
-
在 RoBERTa、DeBERTa、GPT-2 和GPT-3 等大语言模型上,LoRA 在模型质量方面的表现与微调相当或更好,尽管它具有更少的可训练参数、更高的训练吞吐量,并且与适配器不同,没有额外的推断延迟
Dataset/Algorithm/Model/Experiment Detail
实现方式
问题定义
-
给定一个自回归语言模型 PΦ(y|x),比如可以是基于通用多任务训练的 GPT 模型,需要将这个模型在下游任务上进行 finetune,比如机器阅读理解 (MRC) 和自然语言转换为 SQL (NL2SQL) 这两个任务上,这些任务的数据通常是上下文与目标对:Z = {(xi, yi)}i=1,…,N,其中 xi 和 yi 都是 token 序列
- 比如在 NL2SQL 中,xi 是自然语言查询,yi 是对应的 SQL 指令
-
对于全模型参数 finetune,模型初始化为预训练权重Φ0,需要通过训练更新为Φ0 +∆Φ
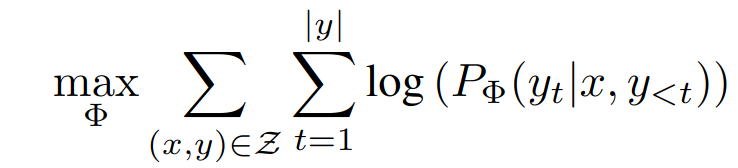
这种方式缺点是更新的参数 ∆Φ 数量级与原始参数数据集一致,训练开销大 -
本文的方法是使 finetune 的参数的量极大降低,∆Φ = ∆Φ(Θ) ,其中训练的参数量 |Θ| 远小于原始模型的参数量 |Φ0|.
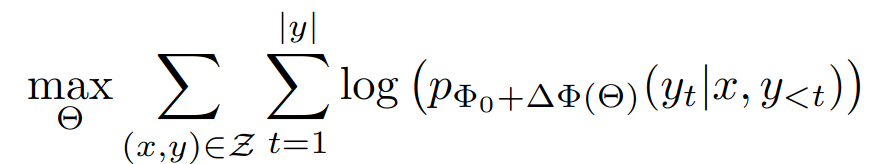
基于本文方法,对于 GPT-3 175B 模型来说,可训练的模型参数可以是原始模型 0.01%
LOW-RANK-PARAMETRIZED UPDATE MATRICES
- 神经网络包含许多密集的层,这些层执行矩阵乘法。这些层中的权重矩阵通常具有全秩。当适应特定的任务时,预训练的语言模型往往具有较低的“instrisic dimension”,尽管随机投影到较小的子空间,但仍然可以有效地学习
- 受此启发,本文假设在适应过程中对权重的更新也具有较低的“intrinsic rank”,比如对于一个预训练的参数矩阵
W
0
∈
R
d
×
k
W_{0} \in R^{d \times k}
W0∈Rd×k ,通过用低秩分解表示后者来约束它的更新
W 0 + ∆ W = W 0 + B A W_{0} + ∆W = W_{0} + BA W0+∆W=W0+BA ,其中 B ∈ R d × r B \in R^{d \times r} B∈Rd×r , A ∈ R r × k A \in R^{r \times k} A∈Rr×k ,其中秩 r 远小于 min(k, d) - 训练过程中模型原始参数
W
0
W_{0}
W0 保持冻结, A 和 B 参数可训练,
W
0
W_{0}
W0 和
∆
W
=
B
A
∆W=BA
∆W=BA 有相同的 input, 它们各自的输出向量按坐标求和,整体过程如图一所示
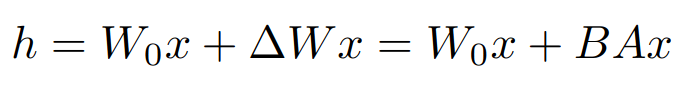
对 A 使用随机高斯初始化,对 B 使用零初始化,这样 ∆ W = B A ∆W=BA ∆W=BA 在刚开始训练的时候输出是 0,不会对原始模型的映射产生影响 - 然后需要对 ∆ W x ∆Wx ∆Wx 利用 α r \frac{\alpha}{r} rα 进行缩放, α \alpha α 是 r 中的常数。当用 Adam 进行优化时,如果适当缩放初始化,调优 α \alpha α 与调优学习率大致相同。因此,本文简单地将 α \alpha α 设置为尝试的第一个 r,而不调整它。这种缩放有助于在变化 r 时减少重新调优超参数
Lora 性质 1:全面微调的推广
- 通过将 LoRA 秩 r 设置为预训练的权重矩阵的秩,大致恢复了完整微调的表达性。换句话说,当增加可训练参数的数量时,训练LoRA大致收敛于训练原始模型
Lora 性质 2:没有额外的推断延迟
- 在生产中部署时,可以显式地计算和存储 W = W0 + BA,并像往常一样执行推理,也即将 LoRA 权重和原始模型权重合并,不增加任何的推断耗时
- W0 和 BA 都是 Rd×k
- 当我们需要切换到另一个下游任务时,我们可以通过减去 BA 然后添加不同的 B’A’ 来恢复 W0,这是一个内存开销很小的快速操作
APPLYING LORA TO TRANSFORMER
-
transformer 自注意模块中有四个权重矩阵 Wq , Wk, Wv , Wo,以及 MLP 中的两个权重矩阵,本文为了简介和节省计算量,做的实验是只在 attention 矩阵上加 LoRA
-
在 transformer 上实践 LoRA 的好处
- 对于基于 Adam 训练的 Transformer 结构,如果 r 远小于原始权重矩阵维度,VRAM 使用减少 2/3,因为不需要存储冻结参数的优化状态。在 GPT-3 175B 上,将训练期间的 VRAM 消耗从 1.2TB 降低到 350GB
- 当 r = 4 并且只调整 q 和 v 投影矩阵时,checkpoint 的大小减小了大约 10,000× (从 350GB 减小到 35MB)
- 观察到在 GPT-3 175B 训练期间,lora 与完全微调相比,加速了 25%。因为对于大部分模型参数都不需要计算梯度了
-
在 transformer 上实践 LoRA 的缺点
- 如果选择将 LoRA 的参数 A 和 B 吸收到原始模型权重 W0 中以消除额外的推理延迟,那么在一次转发传递中批量输入不同的任务并不是一件简单的事情。在延迟不是很严重的情况下,可以不合并权重并动态地选择要用于批处理样例的 LoRA 模块
实验结果
对比实验
-
与 finetune 相比精度基本对齐
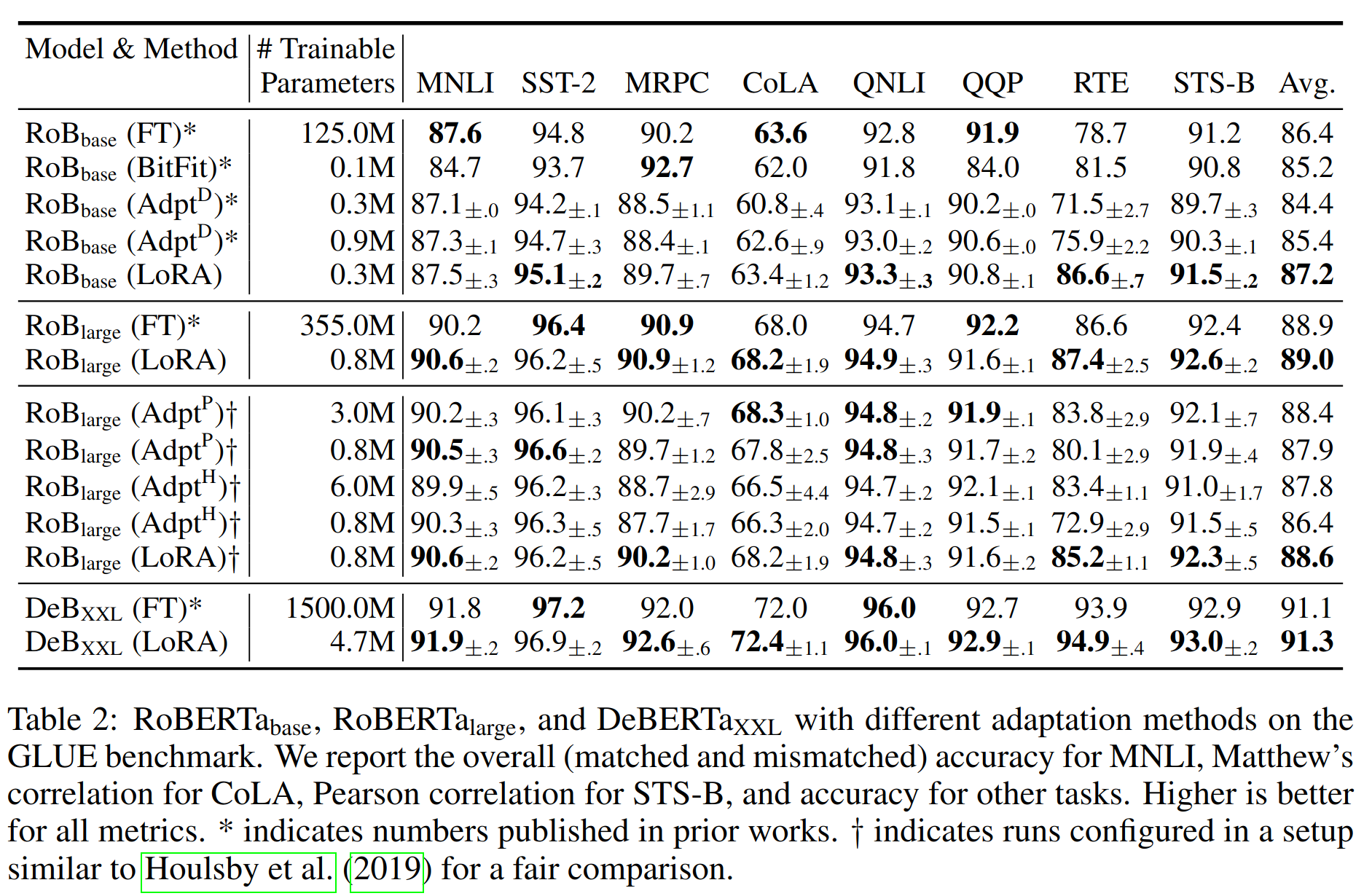
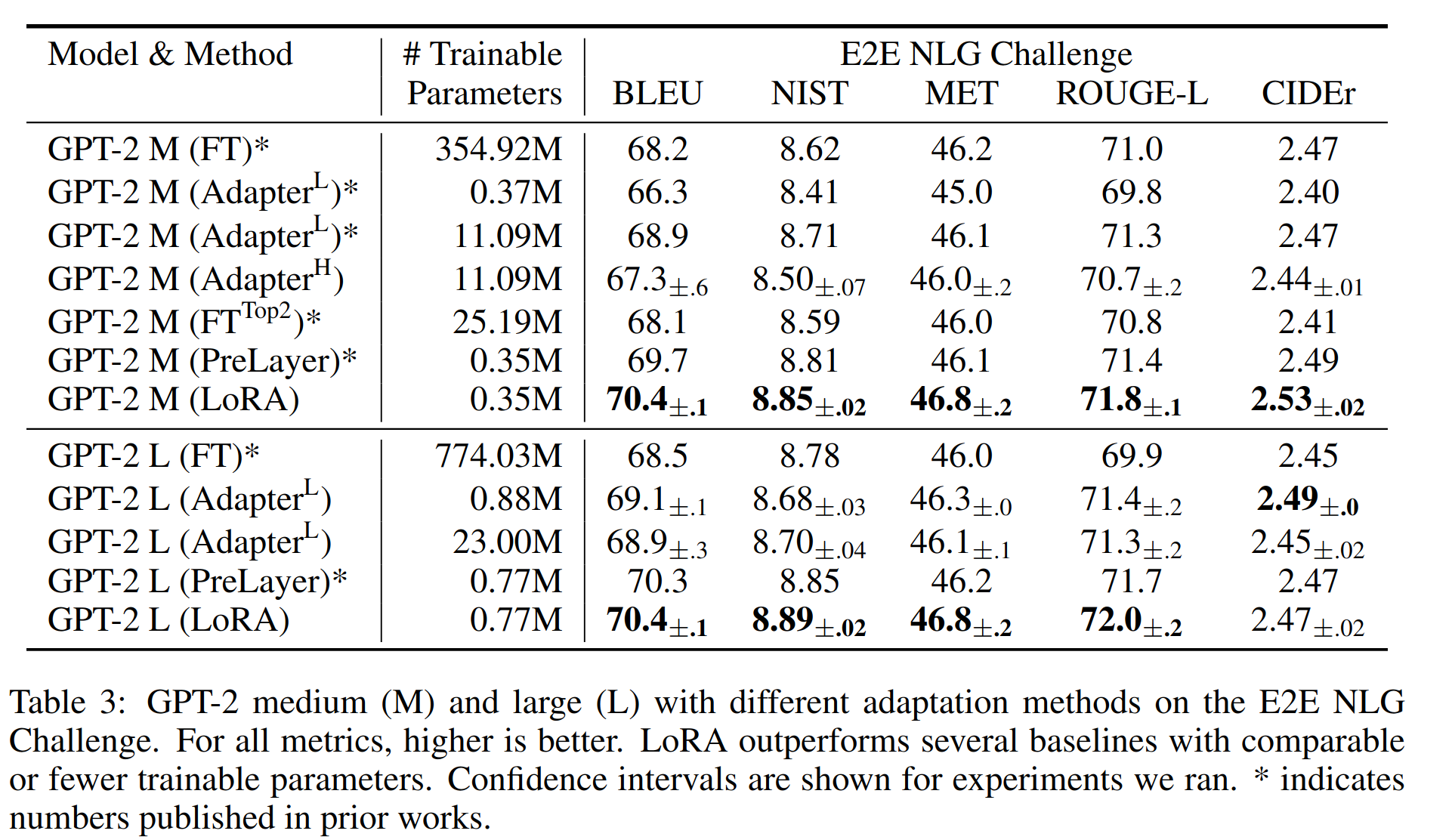
-
与当前的一些主流 Adapter 方法对比延时明显降低

Thoughts
- 在 LLM 和 StableDiffusion 中被广泛使用的模型加速 finetune 的方案,能够在不增加推理耗时的情况下基本对齐或超过完全参数 finetune 的方法,在实际应用部署中很有价值

