
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构)。
本文为了方便理解会与excel或者sql操作行或列来进行联想类比
1.重新索引:reindex和ix
上一篇中介绍过数据读取后默认的行索引是0,1,2,3...这样的顺序号。列索引相当于字段名(即第一行数据),这里重新索引意思就是可以将默认的索引重新修改成自己想要的样子。
1.1 Series
比方说:data=Series([4,5,6],index=['a','b','c']),行索引为a,b,c。
我们用data.reindex(['a','c','d','e'])修改索引后则输出:

可以理解成我们用reindex设了索引后,根据索引去原来data里面匹配对应的值,没匹配上的就是NaN。
1.2 DataFrame
(1)行索引修改:DataFrame行索引同Series
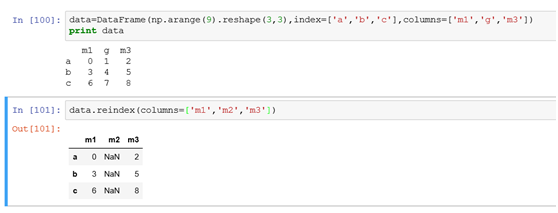
(2)列索引修改:列索引用reindex(columns=['m1','m2','m3']),用参数columns来指定对列索引进行修改。修改逻辑类似行索引,也是相当于用新列索引去匹配原来的数据,没匹配上的置NaN
例:
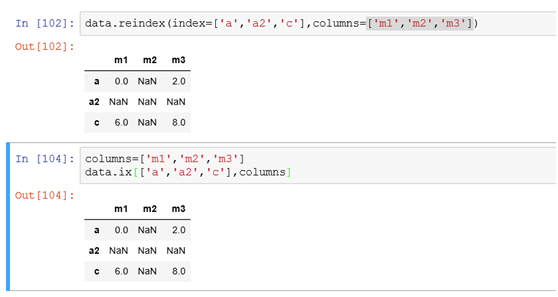
(3)同时对行和列索引进行修改可以用
2.丢弃指定轴上的列(通俗的说法就是删除行或者列):drop
通过索引进行选择删除哪一行或者哪一列
data.drop(['a','c']) 相当于delete table a where xid='a' or xid='c'
data.drop('m1',axis=1)相当于delete table a where yid='m1'
3.选取和过滤(通俗的说就是sql中按照条件筛选查询)
python中因为有行列索引,在做数据的筛选会比较方便
3.1 Series
(1)按照行索引进行选择如

- obj['b']相当于select * from tb where xid='b'
- obj['b','a','c']相当于select * from tb where xid in ('a','b','c'),且结果按照b ,a ,c 的顺序排列后进行展示,这是与sql的区别
- obj[0:1]和obj['a':'b']的区别如下:
#前者是不包含末端,后者是包含了末端

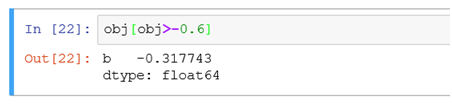
(2)按照值的大小进行筛选obj[obj>-0.6]相当于在obj数据中找出值比-0.6大的记录进行展示
3.2 DataFrame
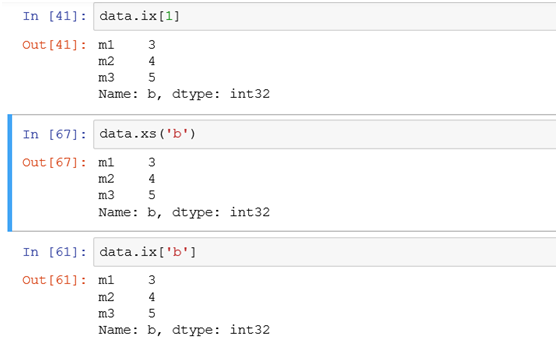
(1)选择单行用ix或者xs:
如筛选索引为b的那条行记录用以下三种方式
(2)选择多行:
筛选索引为a,b的两条行记录的方式
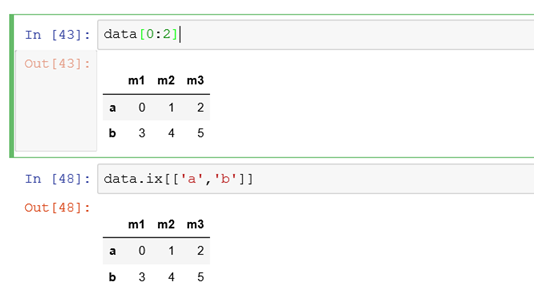
#以上不能直接写成data[['a','b']]
data[0:2]表示从第一行到第二行的记录。第一行默认从0开始数,不包含末端的2。
(3)选择单列
筛选m1列的所有行记录数据
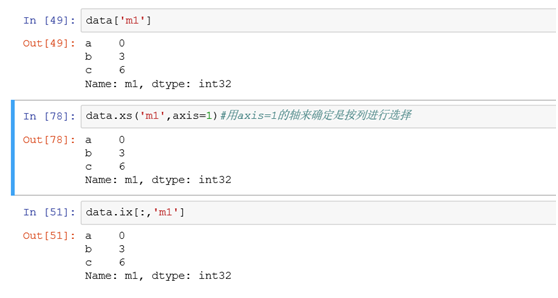
(4)选择多列
筛选m1,m3两个列,所有行记录的数据

ix[:,['m1','m2']]前面的:表示所有的行都筛选进来。
(5)根据值的大小条件筛选行或者列
如筛选出某一列值大于4的所有记录相当于select * from tb where 列名>4
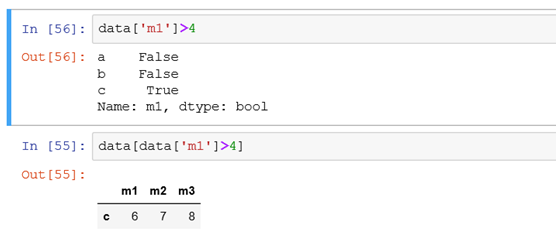
(6)如果筛选某列值大于4的所有记录,且只需展示部分列的情况时

行用条件进行筛选,列用[0,2]筛选第一列和第三列的数据

