
系统:Centos 7,内核版本3.10
本文介绍如何从0利用Docker搭建Hadoop环境,制作的镜像文件已经分享,也可以直接使用制作好的镜像文件。
一、宿主机准备工作
0、宿主机(Centos7)安装Java(非必须,这里是为了方便搭建用于调试的伪分布式环境)
1、宿主机安装Docker并启动Docker服务
- 安装:
yum install -y docker
- 启动:
service docker start
二、制作Hadoop镜像
(本文制作的镜像文件已经上传,如果直接使用制作好的镜像,可以忽略本步,直接跳转至步骤三)
1、从官方下载Centos镜像
docker pull centos
下载后查看镜像 docker images 可以看到刚刚拉取的Centos镜像
2、为镜像安装Hadoop
1)启动centos容器
docker run -it centos
2)容器内安装java
- https://www.oracle.com/technetwork/java/javase/downloads/index.html下载java,根据需要选择合适版本,如果下载历史版本拉到页面底端,这里我安装了java8

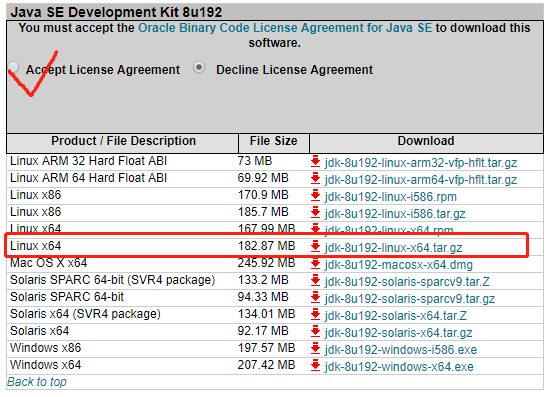
- /usr下创建java文件夹,并将java安装包在java文件下解压
tar -zxvf jdk-8u192-linux-x64.tar.gz

- 解压后文件夹改名(非必需)
mv jdk1.8.0_192 jdk1.8

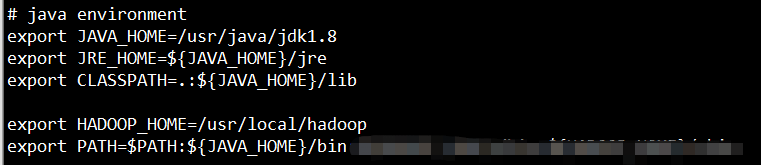
- 配置java环境变量 vi ~/.bashrc ,添加内容,保存后退出
export JAVA_HOME=/usr/java/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin
使环境变量生效 source ~/.bashrc
验证安装结果 java -version

这里注意,因为是在容器中安装,修改的是~/.bashrc而非我们使用更多的/etc/profile,否则再次启动容器的时候会环境变量会失效。
3)容器内安装hadoop
- 选择需要的Hadoop版本,下载https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
- 在容器的/usr/local目录下解压,并修改文件夹名为hadoop
tar -zxvf hadoop-2.7.6.tar.gz
mv hadoop-2.7.6.tar.gz hadoop
- 设置Hadoop的java-home
进入hadoop安装目录(以下操作均为hadoop的安装目录的相对路径)
cd /usr/local/hadoop/


export JAVA_HOME=/usr/java/jdk1.8

- 检查安装的hadoop是否可用 ./bin/hadoop version (注意要在hadoop的安装目录下执行)

- 配置hadoop环境变量
前面在验证hadoop命令的时候需要在hadoop的安装目录下执行./bin/hadoop,为了方便在任意地方执行hadoop命令,配置hadoop的全局环境变量,与java一样,修改~/.bashrc文件
执行 vi ~/.bashrc
添加内容
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin

(P.S. “HADOOP_HOME=”后面配置hadoop安装目录;
这里的PATH变量是java和hadoop结合的;
这样配置之后,可以在任意位置执行hadoop命令)
source ~/.bashrc 使环境变量生效
hadoop version 验证变量生效

4)为容器安装辅助程序
下面安装的程序都是在制作镜像过程中需要用的工具或踩到的坑,提前装好避免一些奇怪问题
- 配置时间同步服务器
安装ntpdate yum install -y ntpdate
配置时间同步服务器
ntpdate ntp1.aliyun.com
ntp1.aliyun.com为时间同步服务器地址,百度可以查到可用服务器
- 安装ssh
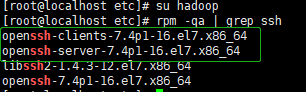
检查是否已经默认安装SSHClient和SSH Server
rpm -qa | grep ssh
出现如下结果表示已经安装
yum install openssh-clients
yum install openssh-server
测试ssh是否可用
ssh localhost
测试之后就是通过ssh登陆了本机,输入 exit 退回到普通终端登陆。
- 安装rsync
yum -y install rsync
- 安装dbus
yum -y install dbus
5)将容器制作成镜像
宿主机打开新终端,注意打包镜像操作都是在宿主机内做的,(即你安装Docker的那台机器)。
- 查看容器id
在宿主机内查看刚刚使用的容器ID
docker ps

- 打包
docker commit -m "centos7 with hadoop" c0905da23733 centos7/hadoop

命令说明:
docker commit [OPTIONS] 容器ID [镜像[:版本标签]]
-m 提交说明
centos7/hadoop 镜像名称,如果不叫版本标签,默认为latest
- 查看打包结果 docker images

- 提交镜像
完成上述后已经交将容器打包为本地镜像,下面将本地镜像提交到远程仓库,这里上传到阿里云的镜像仓库,需要事先注册阿里云账号。
阿里云创建仓库https://cr.console.aliyun.com/
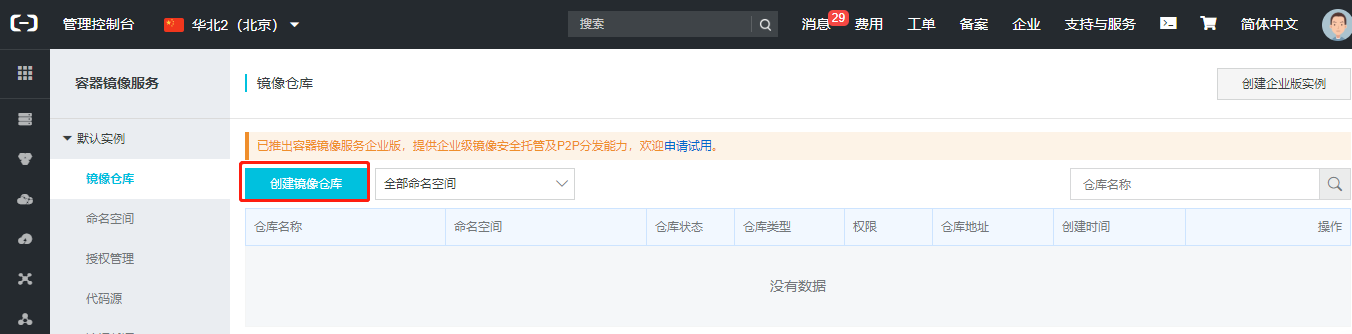
仓库创建成功后打开仓库可以看到操作指南,在宿主机终端按照指南进行后续操作
终端登陆
docker login --username=魔女小豚 registry.cn-beijing.aliyuncs.com
推送
$ sudo docker login --username=魔女小豚 registry.cn-beijing.aliyuncs.com $ sudo docker tag [ImageId] registry.cn-beijing.aliyuncs.com/jing-studio/centos7-hadoop:[镜像版本号] $ sudo docker push registry.cn-beijing.aliyuncs.com/jing-studio/centos7-hadoop:[镜像版本号]
根据实际镜像信息替换示例中的[ImageId]和[镜像版本号]参数。


三、Hadoop集群配置
1、从registry中拉取镜像
$ sudo docker pull registry.cn-beijing.aliyuncs.com/jing-studio/centos7-hadoop

2、启动镜像
按照下述方式,根据需要的节点数启动相应数量的容器(注意为每个容器指定不同的容器名和主机名),这里启动3个容器作为示例
$ docker run -d --name hadoop0 -h hadoop0 -p 50070:50070 --privileged=true registry.cn-beijing.aliyuncs.com/jing-studio/centos7-hadoop /usr/sbin/init
其中,-d指定容器启动的终端在后台执行(在需要使用的容器终端的时候再显示进入容器,如3-3所述),--name hadoop0 指定容器名称,-h hadoop0 指定容器的主机名(这里千万注意,主机名不要包含下划线,对,就是它"_",不要包含下划线、不要包含下划线!!!否则不能启动集群。当初因为这问题采坑好久,都是泪),--privileged=true 指定容器获得全部权限, registry.cn-……指定镜像, /usr/sbin/init指定运行终端
需要开放的端口:namenode开放50070,9000,sourcemanager开放8088
检查容器是否启动 $ docker ps

3、进入容器,查看容器ip
$ docker exec -it hadoop0 /bin/bash
其中,-it表明显式打开容器终端,
查看全部容器ip
$ ip addr
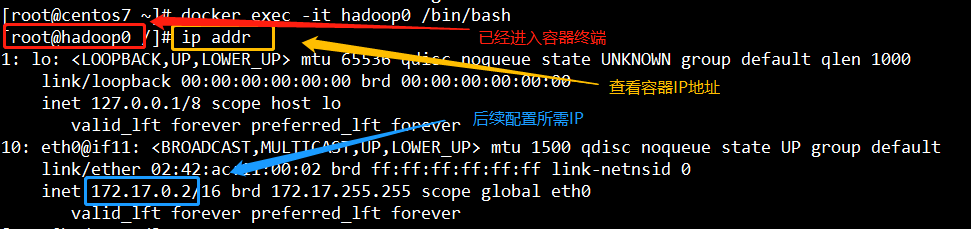
建议使用3-2启动镜像以及3-3进入容器的方式运行,在开始搭建的时候各种采坑,才找到这种合适的方式,在容器使用过程中不会出现系统服务无法启动的情况。
4、配置主机映射
$ vi /etc/hosts
将每个容器的Ip地址和主机名添加到hosts文件中
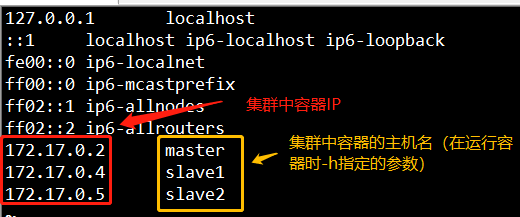
注意集群中每个节点都需要配置上述主机映射。
5、为各个集群节点配置彼此间的ssh免密登陆
- 生成本机公钥私钥
cd ~/.ssh/ #若没有~/.ssh/目录,先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以,产生公钥私钥
在~/.ssh目录下生成密钥文件,id_dsa: 为私钥;id_dsa.pub: 为公钥
- 彼此发送密钥
ssh-copy-id ha_slave1
注意要在每个集群节点上生成密钥、并为其他全部集群节点发送密钥,即在master上执行一次生成密钥,然后执行两次发送密钥,分别发送给slave1 、slave2;然后再在slave1上生成密钥发送密钥给其他节点,再在slave2上再次执行。
5.1 关闭防火墙
service iptables stop
完成上述准备工作后对hadoop集群进行配置,在配置之前,考虑集群中节点规划,即,哪些节点作为HDFS的namenode、datanode、secnamenode,哪些节点作为yarn的sourcemanager、nodemanager。本文示例集群规划如下:
| hdfs | yarn | |
| master | namenoder + datanode | nodemanager |
| slave1 | datanode | sourcemanager + nodemanger |
| slave2 | secnamenode + datanode | nodemanger |
6、选择一个节点,进入节点,进行HDFS配置(注意进入到hadoop安装目录,在我的镜像里是 /usr/local/hadoop )
- 配置core-site.xml文件,指定HDFS主节点
vi etc/hadoop/core-site.xml
添加配置内容
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://had0:9000</value> </property>
<property> <name>hadoop.tmp.dir</name> <value>/home/data/hadoopdata</value> </property> </configuration>
指定hdfs主节点,并指定临时文件目录,存储hadoop运行过程中产生的文件的目录(注意一定配置在有权限的目录下)
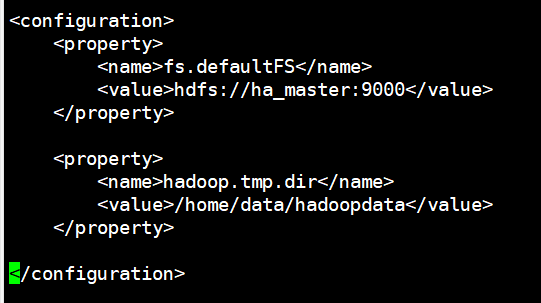
- 配置hdfs-site.xml
vi etc/hadoop/hdfs-site.xml
添加内容
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/data/hadoopdata/name</value>
</property>
<!--配置存储namenode数据的目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/data/hadoopdata/data</value>
</property>
<!--配置存储datanode数据的目录-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--配置部分数量-->
<property>
<name>dfs.secondary.http.address</name>
<value>had2:50090</value>
</property>
<!--配置第二名称节点 -->
</configuration>
7、YARN配置(依然在上述选择的节点进行配置)
- 配置yarn-site.xml
vi etc/hadoop/yarn-site.xml
添加内容
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
<!--配置yarn主节点-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置执行的计算框架-->
</configuration>
- 配置mapred-site.xml
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
vi etc/hadoop/mapred-site.xml
添加内容
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
<!--配置mapreduce任务所在的资源调度平台--> </configuration>
- 配置slaves
vi etc/hadoop/slaves
添加内容
master
slave1
slave2
8、将HDFS和YARN配置发送到全部节点
需要给集群中全部节点进行3-5、3-6的配置操作,在一个节点上配置完成后,通过远程发送配置文件,对其他节点进行配置。上述配置文件都在"hadoop安装目录/etc”下,方便起见,通过将etc文件夹发送到其他节点容器来完成配置。注意,此操作也要在hadoop安装目录下执行;通过此操作要把配置文件发送到所有集群节点上。
scp -r etc ha_slave1:/usr/local/hadoop/
四、启动HDFS
- 初始化NameNode的元数据目录,格式化文件系统
此操作在namenode节点上初始化一个全新的namenode的元数据存储目录(为hdfs-site.xml中配置的namenode数据的目录),生成记录元数据的文件fsimage,生成集群的相关标识,必须在HDFS的NameNode节点执行操作。
hadoop namenode -format

上图表示格式化成功
- 启动HDFS,可以在任意节点启动
start-dfs.sh
- 验证启动结果(可以在每个节点上都进行验证)
jps
可以看到当前节点上已经启动了DataNode和NameNode(节点上启动哪些进程取决于集群规划)
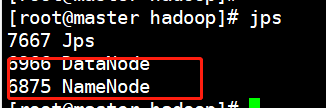
补充:关于HDFS的格式化,如果格式化成功,则只能格式化一次,如果HDFS启动后需要重新格式化,格式化的步骤:
1)删除namenode数据目录、datanode数据目录(在配置文件中指定的路径)
2)重新格式化
datanode 的想过数据信息在启动hdfs的时候生成,两个文件(version)中的cluster ID相同时候才认为节点属于同一集群,datanode才能受namenode管理,如果没有删除目录就去进行格式化,会造成节点不属于同一集群的问题。
五、启动YARN
- 必须在SourceManager上启动
start-yarn.sh
- 验证结果
jps
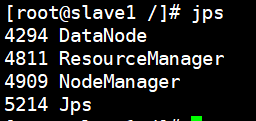
由于前面启动了HDFS,所以此时节点上可以看到hdfs和yarn的进程。
至此,使用Docker进行hadoop完全分布式搭建的工作完成。
datanode可以在线扩容,只需要把一个datanode的namenode配置成当前使用的namenode,然后启动。如果想删除datanode,则需要重新格式化namenode节点。

