
- 1Tutorial: Storyboard in XCode 4.2 with Navigation Controller and Tabbar Controller (Part 1)_pnsnavigationcontroller
- 2内网映射外网之80端口映射和全端口映射的实现和发布网站应用、外网访问内网_内网80端口映射到公网
- 3【资料下载】IMG RISC-V RTXM-2200 用作存储器控制器
- 4【深度学习目标检测】二十三、基于深度学习的行人检测计数系统-含数据集、GUI和源码(python,yolov8)
- 5关于 arm 和 x86 架构的思考_为什么同一份代码内存泄漏x86架构不会报错 arm架构报错
- 6Unity3D四、This application has requested the Runtime to terminate it in an unusual way。Please contact_unity this app;ocation
- 7【力扣143. 重排链表】寻找链表中点 + 链表逆序 + 合并链表(python3)
- 8uni-app心得体会_为啥开发app不建议uniapp
- 9人工智能
- 10Mysql数据库---python连接Mysql数据库_db = pymysql.connect
人脸识别之人脸对齐(一)--定义及作用
赞
踩
原文:
http://www.thinkface.cn/thread-4354-1-1.html
http://www.thinkface.cn/thread-4488-1-1.html
人脸对齐任务即根据输入的人脸图像,自动定位出面部关键特征点,如眼睛、鼻尖、嘴角点、眉毛以及人脸各部件轮廓点等,如下图所示。
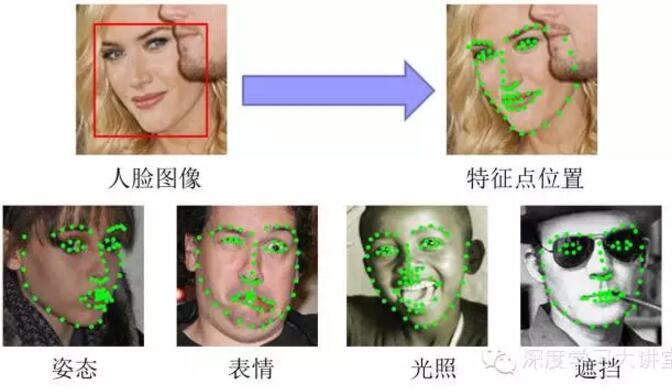
这项技术的应用很广泛,比如自动人脸识别,表情识别以及人脸动画自动合成等。由于不同的姿态、表情、光照以及遮挡等因素的影响,准确地定位出各个关键特征点看似很困难。我们简单地分析一下这个问题,不难发现这个任务其实可以拆分出三个子问题:
1. 如何对人脸表观图像(输入)建模
2. 如何对人脸形状(输出)建模
3.如何建立人脸表观图像(模型)与人脸形状(模型)的关联
以往的研究工作也离不开这三个方面。人脸形状建模典型的方法有可变形模板(Deformable Template)、点分布模型(主动形状模型Active Shape Model)、图模型等。
人脸表观建模又可分为全局表观建模和局部表观建模。全局表观建模简单的说就是考虑如何建模整张人脸的表观信息,典型的方法有主动表观模型Active Appearance Model(产生式模型)和Boosted Appearance Model(判别式模型)。对应的局部表观建模则是对局部区域的表观信息建模,包括颜色模型、投影模型、侧剖线模型等。
近来,级联形状回归模型在特征点定位任务上取得了重大突破,该方法使用回归模型,直接学习从人脸表观到人脸形状(或者人脸形状模型的参数)的映射函数,进而建立从表观到形状的对应关系。此类方法不需要复杂的人脸形状和表观建模,简单高效,在可控场景(实验室条件下采集的人脸)和非可控场景(网络人脸图像等)均取得不错的定位效果。此外,基于深度学习的人脸对齐方法也取得令人瞩目的结果。深度学习结合形状回归框架可以进一步提升定位模型的精度,成为当前特征定位的主流方法之一。下面将具体介绍级联形状回归和深度学习这两大类方法的研究进展。
级联线性回归模型
人脸对齐问题可以看作是学习一个回归函数F,以图象I作为输入,输出θ为特征点的位置(人脸形状):θ = F(I)。
简单的说,级联回归模型可以统一为以下框架:学习多个回归函数{f1 ,…, fn-1, fn}来逼近函数F:
θ = F(I)= fn (fn-1 (…f1(θ0, I) ,I) , I)
θi= fi (θi-1, I), i=1,…,n
所谓的级联,即当前函数fi的输入依赖于上一级函数fi-1的输出θi-1,而每一个fi的学习目标都是逼近特征点的真实位置θ,θ0为初始形状。通常情况,fi不是直接回归真实位置θ,而回归当前形状θi-1与真实位置θ之间的差:Δθi = θ - θi-1。
接下来我将详细介绍几个典型的形状回归方法,他们根本的不同点在于函数fi的设计不同以及输入特征不同。
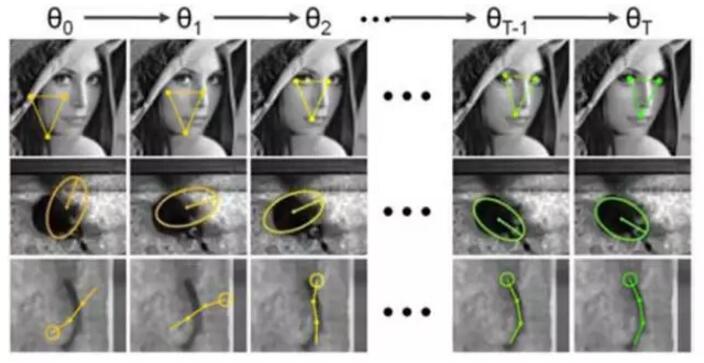
在加州理工学院从事博士后研究的Piotr Dollár于2010年首次提出级联形状回归模型CascadedPose Regression(CPR),来预测物体的形状,该工作发表在国际计算机视觉与模式识别会议CVPR上。如下图所示,如下图所示,给定初始形状θ0,通常为平均形状,根据初始形状θ0提取特征(两个像素点的差值)作为函数f1的输入。每个函数fi建模成Random Fern回归器,来预测当前形状θi-1与目标形状θ的差Δθi,并根据Δθi预测结果更新当前形状得θ i = θi-1+Δθi,作为下一级函数fi+1的输入。该方法在人脸、老鼠和鱼三个数据集上取得不错的实验结果,通用的算法框架亦可用于其他形状估计任务,比如人体姿态估计等。该方法的不足之处在于对初始化形状θ0比较敏感,使用不同的初始化做多次测试并融合多次预测结果可以一定程度上缓解初始化对于算法的影响,但并不能完全解决该问题,且多次测试会带来额外的运算开销。当目标物体被遮挡时,性能也会变差。
与上一个工作来自同一课题组的Xavier P. Burgos-Artizzu,针对CPR方法的不足,进一步提出Robust Cascaded Pose Regression(RCPR)方法,并发表在2013年国际计算视觉会议ICCV上。为了解决遮挡问题,Piotr Dollár提出同时预测人脸形状和特征点是否被遮挡的状态,即fi的输出包含Δθi和每个特征点是否被遮挡的状态pi:
{Δθi , pi }= fi(θi-1, I), i=1,…,n
当某些特征点被遮挡时,则不选取该特征点所在区域的特征作为输入,从而避免遮挡对定位的干扰。此外,作者提出智能重启技术来解决形状初始化敏感的问题:随机初始化一组形状,运行{f1 ,…,fn-1, fn}的前10%的函数,统计形状预测的方差,如果方差小于一定阈值,说明这组初始化不错,则跑完剩下的90%的级联函数,得到最终的预测结果;如果方差大于一定阈值,则说明初始化不理想,选择重新初始化一组形状。该策略想法直接,但效果很不错。
另外一个很有趣的工作Supervised Descent Method(SDM),从另一个角度思考问题,即考虑如何使用监督梯度下降的方法来求解非线性最小二乘问题,并成功地应用在人脸对齐任务上。不难发现,该方法最终的算法框架也是一个级联回归模型。与CPR和RCPR不同的地方在于:fi建模成了线性回归模型;fi的输入为与人脸形状相关的SIFT特征。该特征的提取也很简单,即在当前人脸形状θi-1的每个特征点上提取一个128维的SIFT特征,并将所有SIFT特征串联到一起作为fi的输入。该方法在LFPW和LFW-A&C数据集上取得不错的定位结果。同时期的另一个工作DRMF则是使用支持向量回归SVR来建模回归函数fi,并使用形状相关的HOG特征(提取方式与形状相关的SIFT类似)作为fi输入,来级联预测人脸形状。与SDM最大的不同在于,DRMF对于人脸形状做了参数化的建模。fi的目标变为预测这些形状参数而不再是直接的人脸形状。这两个工作同时发表在CVPR 2013上。由于人脸形状参数化模型很难完美地刻画所有形状变化,SDM的实测效果要优于DRMF。
微软亚洲研究院孙剑研究员的团队在CVPR 2014上提出更加高效的级联形状回归方法Regressing LocalBinary Features(LBF)。和SDM类似,fi也是建模成线性回归模型;不同的地方在于,SDM直接使用SIFT特征,LBF则基于随机森林回归模型在局部区域学习稀疏二值化特征。通过学习稀疏二值化特征,大大减少了运算开销,比CRP、RCPR、SDM、DRMF等方法具有更高的运行效率(LBF可以在手机上跑到300FPS),并且在IBUG公开评测集上取得优于SDM、RCPR的性能。

级联形状回归模型成功的关键在于:
1. 使用了形状相关特征,即函数fi的输入和当前的人脸形状θi-1紧密相关;
2. 函数fi的目标也与当前的人脸形状θi-1相关,即fi的优化目标为当前形状θi-1与真实位置θ之间的差Δθi。
此类方法在可控和非可控的场景下均取得良好的定位效果,且具有很好的实时性。
深度模型
以上介绍的级联形状回归方法每一个回归函数fi都是浅层模型(线性回归模型、Random Fern等)。深度网络模型,比如卷积神经网络(CNN)、深度自编码器(DAE)和受限玻尔兹曼机(RBM)在计算机视觉的诸多问题,如场景分类,目标跟踪,图像分割等任务中有着广泛的应用,当然也包括特征定位问题。具体的方法可以分为两大类:使用深度模型建模人脸形状和表观的变化和基于深度网络学习从人脸表观到形状的非线性映射函数。
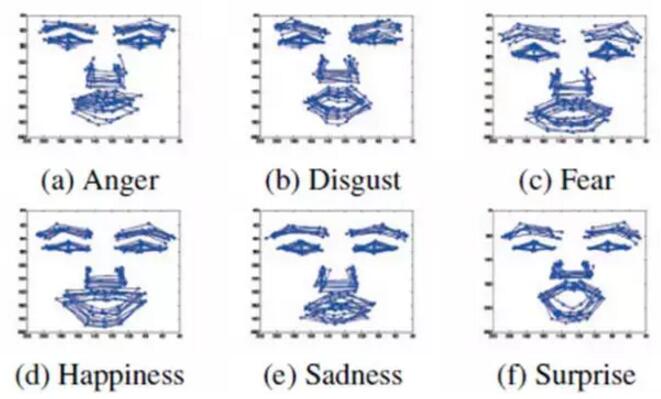
主动形状模型ASM和主动表观模型AAM使用主成分分析(PCA)来建模人脸形状的变化。由于姿态表情等因素的影响,线性PCA模型很难完美地刻画不同表情和姿态下的人脸形状变化。来自伦斯勒理工学院JiQiang教授的课题组在CVPR2013提出使用深度置信网络(DBN)来刻画不同表情下人脸形状的复杂非线性变化。此外,为了处理不同姿态的特征点定位问题,进一步使用3向RBM网络建模从正面到非正面的人脸形状变化。最终该方法在表情数据库CK+上取得比线性模型AAM更好的定位结果。该方法在同时具备多姿态多表情的数据库
ISL上也取得较好的定位效果,但对同时出现极端姿态和夸张表情变化的情况还不够理想。
下图是深度置信网络(DBN):建模不同表情下的人脸形状变化的示意图。
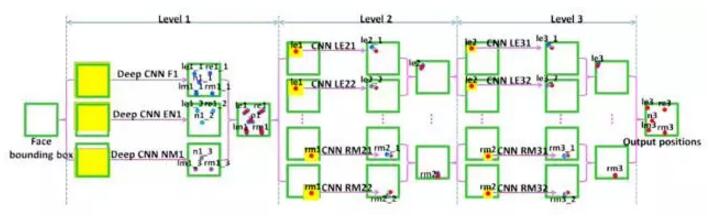
香港中文大学唐晓鸥教授的课题组在CVPR 2013上提出3级卷积神经网络DCNN来实现人脸对齐的方法。该方法也可以统一在级联形状回归模型的大框架下,和CPR、RCPR、SDM、LBF等方法不一样的是,DCNN使用深度模型-卷积神经网络,来实现fi。第一级f1使用人脸图像的三块不同区域(整张人脸,眼睛和鼻子区域,鼻子和嘴唇区域)作为输入,分别训练3个卷积神经网络来预测特征点的位置,网络结构包含4个卷积层,3个Pooling层和2个全连接层,并融合三个网络的预测来得到更加稳定的定位结果。后面两级f2, f3在每个特征点附近抽取特征,针对每个特征点单独训练一个卷积神经网络(2个卷积层,2个Pooling层和1个全连接层)来修正定位的结果。该方法在LFPW数据集上取得当时最好的定位结果。
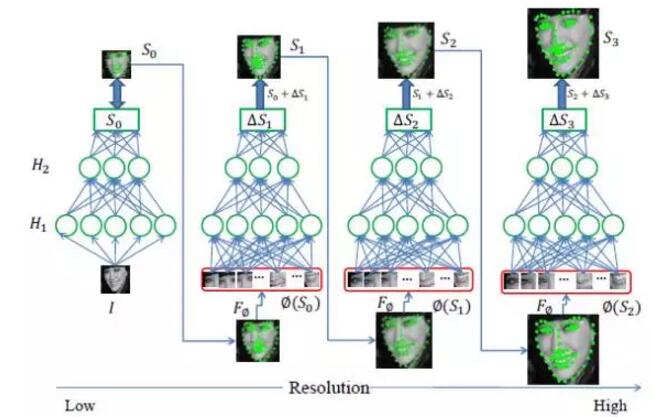
另外一种由粗到精的自编码器网络(CFAN)来描述从人脸表观到人脸形状的复杂非线性映射过程。该方法级联了多个栈式自编码器网络fi,每一个fi刻画从人脸表观到人脸形状的部分非线性映射。具体来说,输入一个低分辨率的人脸图像I,第一层自编码器网络f1可以快速地估计大致的人脸形状,记作基于全局特征的栈式自编码网络。网络f1包含三个隐层,隐层节点数分别为1600,900,400。然后提高人脸图像的分辨率,并根据f1得到的初始人脸形状θ1,抽取联合局部特征,输入到下一层自编码器网络f2来同时优化、调整所有特征点的位置,记作基于局部特征的栈式自编码网络。该方法级联了3个局部栈式自编码网络{f2 , f3, f4}直到在训练集上收敛。每一个局部栈式自编码网络包含三个隐层,隐层节点数分别为1296,784,400。得益于深度模型强大的非线性刻画能力,该方法在XM2VTS,LFPW,HELEN数据集上取得比DRMF、SDM更好的结果。此外,CFAN可以实时地完成人脸人脸对齐(在I7的台式机上达到23毫秒/张),比DCNN(120毫秒/张)具有更快的处理速度。
下图是CFAN:基于由粗到精自编码器网络的实时人脸对齐方法的示意图。
以上基于级联形状回归和深度学习的方法对于大姿态(左右旋转-60°~+60°)、各种表情变化都能得到较好的定位结果,处理速度快,具备很好的产品应用前景。针对纯侧面(±90°)、部分遮挡以及人脸检测与特征定位联合估计等问题的解决仍是目前的研究热点。
目前有很多的人脸对齐算法,比较传统的有ASM、AAM、CLM和一些列改进算法,而目前比较流行的有ESR、3D-ESR、SPR、LBF、SDM、CFSS等。
ASM算法相对容易,其中STASM是目前正面脸当中比较好的算法,原作者和CLM比较过。但是STASM速度较慢,大概10frame/s左右。ASM对齐在精度上不如AAM,AAM由于使用全局纹理信息,因此精度较高,但是遇到光照和多姿态时,对初始化Shape要求很高,不然容易陷入局部优化。CLM分别继承了ASM和AAM的一些特征,效果得到了提升。对局部器官特征的概率假设和优化算法的选择,是CLM各种算法的本质区别。CLM比较好的论文和文献有:
automati feature localtion with constraint models David Cristinacce, Tim Cootes
Face Alignment through Subspace ConstrainedMean-Shifts 这篇文章综述了ASM/CLM
CLM开源代码较少,但是有很好的从算法到工程实现的代码。
Constrained LocalModel (CLM) Implementation - Xiaoguang Yan
很多学者刚接触到人脸对齐时,不知道它有什么用处,下面就列举出人脸对齐的应用领域:
(1)人脸器官定位、器官跟踪。通过人脸对齐,我们能够定位到人脸的每个部件,提取相应的部件特征。

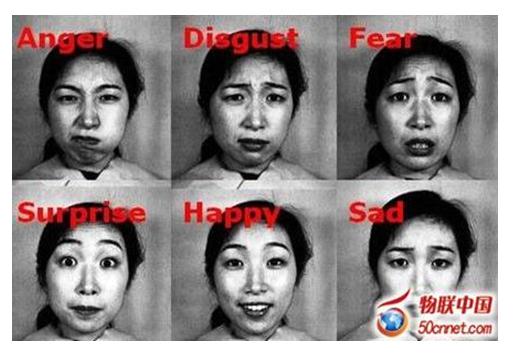
(2)表情识别。通过人脸对齐后,我们能够利用对齐后的人脸形状分析人脸的表情状态。

(3)人脸漫画/素描图像生成。通过人脸对齐后,我们能够进行人脸漫画和素描生成。
如:魔漫相机

(4)虚拟现实和增强现实。通过人脸对齐后,我们能够做出很多好玩的应用。如
2D应用:

3D应用:

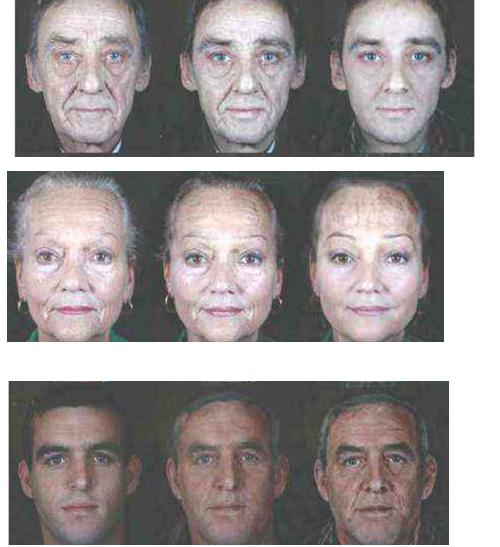
(5)人脸老化、年轻化、年龄推断。特征融合/图像增强。通过人脸对齐后,我们能够有效提取人脸特征,并分析人脸年龄、人脸老化等。
(6)纹理过渡。如:长得很像某人的狗脸。
换脸

7)性别鉴别。通过人脸对齐,能够对人脸进行性别识别,男女之间的人脸形状有一定的差异性。

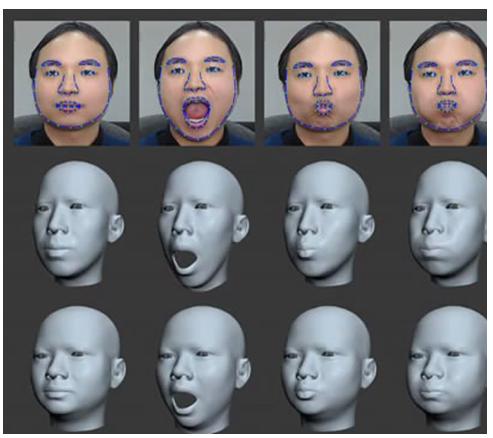
8)3D卡通。通过人脸对齐能够进行3D卡通模拟。

人脸对齐应用广泛,有着巨大的研究价值。学者们一定要好好研究哦!

