
- 1Python3 df.loc和df.iloc函数用法及提取指定行列位置处数值_df.loc用法
- 2docker 修改config_V2.json hostconfig.json hostname 添加静态ip。无需commit。运行中的容器。_conf.v2.json
- 3报错:java.lang.IllegalArgumentException
- 4TeamSpeak3服务器搭建_ts3美化
- 5teamSpeak Server搭建Linux_teamspeak3linux搭建
- 6大数据旅游数据分析:基于Python旅游数据采集可视化分析推荐系统_python旅游数据分析可视化协同过滤算法推荐系统
- 7基于Python爬虫辽宁大连酒店宾馆数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 8江科大stm32学习笔记——【5-1】EXIT外部中断
- 9TreeMap红黑树解析_treemap 红黑树
- 10Python基于微博的舆情分析、热搜可视化系统_微博热搜数据可视化分析系统
女友问粉丝过万如何庆祝,我发长文《保姆级大数据入门篇》感恩粉丝们支持,学姐|学弟看了就懂_apache kwaibi
赞
踩

文章目录
粉丝破万了
5月14日报名参加新星计划至今已经有一个多月,现在迎来历史性的时刻,粉丝超过1万

新星计划申请时粉丝数
刚申请的原力计划时候,就被运营姐姐说粉丝数只有240粉丝数审核驳回;CSDN的个人博客的发展离不开扶持活动,这我只能参加当时有导师带领我们写作的新星计划,那时也就只有240粉;一天也就增长1粉的速度,2000粉的目标是何等困难


新星内卷抢热榜之旅
进入活动后我们就每天开始原创文章,在导师的带领下攻占CSDN热榜排名,每天相互一键关连扶持队友,队伍越来越多强大,评论也开始进行刷评,粉丝猛涨,不到一个月时间粉丝就达到5000多,终于可以达到申请认证标准
运营整顿新星执行新规
美好的日子都是短暂的,这一切都在运营掌控中,很快群通告出来,不能互相一键三连,不得刷评论了,而且刷评论达到顶峰的我处罚了,直接减去30000积分,账号冻结3天处罚,周排名直接降为0,当天的热榜文章也直接拉下来,可谓一波三折,痛失三天涨粉良机。
- 处罚前积分

- 处罚后积分
- 账号冻结

重整旗鼓输出内容为王
不管过程多么曲折,还是回归初心,分享好的博文,输出高质量的文章给广大粉丝才是正道,很快权重被恢复,周榜排名也重新回前20名
女友问粉丝过万如何庆祝
我会写一篇万字以上的博文《保姆级大数据入门篇》感恩1万多名的粉丝支持

保姆级大数据入门篇
一、学习重点划定
大数据主要侧重数据处理和分析,我们只是使用Java来调用相关大数据框架的API
大数据中的数据分析,大部分都是通过SQL完成的,SQL需要重点掌握
大数据需要掌握Java的知识点:
Java基础语法,面向对象,字符串,异常,集合,IO,线程、数据库、JDBC,Maven
使用Java的大数据框架:




使用SQL的大数据框架:


二、Java和大数据关系
- Java语言是目前最为广泛使用的编程语言,功能强大而且简单易用。
- Hadoop 的创始人 Doug Cutting 曾说过:“ Java 在开发者的生产率和运行效率之间取得很好的权衡。开发者可以使用广泛存在的高质量类库,切身受益于这种简洁、功能强大、类型安全的语言。
- 没有 Hadoop 就不存在大数据,没有 Java 就没有 Hadoop。
- 大数据的很多框架都是用Java语言编写的 很多大数据框架都提供了Java相关的API


三、云计算
1、云计算初心
云计算最初的目标是对资源的管理,管理的主要是计算资源、网络资源、存储资源三个方面。
2、云计算本质
资源到架构的全面弹性

- 可以把云计算当作一种商业计算模型,它是将计算的任务发布在大量的计算机的资源池里,让用户可以根据所需求来获取计算力、存储的空间以及信息上的服务。
- "云"是可以进行自我维护和管理的虚拟化的计算资源,一般都是大型的服务器集群 一起,包括计算服务器、存储服务和其他的宽带资源。
- 所谓云计算就是将资源池里的数据集中起来,并通过自动管理实现了无人参与,让用户在使用的时候可以自动调用资源,支持各种各样的程序进行运转,不再为细节而烦恼,可以专心于自己的 业务。云计算的核心理念就是在资源池里进行运算。
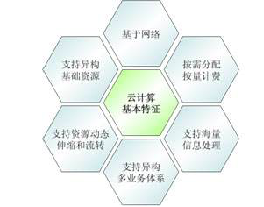

3、云计算分类
公有云
公有云是现在最主流也就是最受欢迎的云计算模式。公有云由云供应商运行,云供应商负责从应用程序、软件运行环境到物理基础设施等IT资源的管理、部署和维护。在使用IT资源时,用户只需为其所使用的资源付费,无需任何前期投入,所以非常经济。
私有云
私有云主要为企业内部提供云服务,不对公众开放,并且企业IT人员能对其数据、安全性和服务质量进行有效地控制。与传统的企业数据中心相比,私有云可以支持动态灵活的基础设施,降低IT架构的复杂度,使各种IT资源得以整合。
混合云
混合云是把公有云和私有云结合到一起的方式,即它是让用户在私有云的私密性和公有云灵活的低廉之间做一定权衡的模式。比如,企业可以将非关键的应用部署到公有云上来降低成本,而将安全性要求很高、非常关键的核心应用部署到完全私密的私有云上。
4、常见公有云

5、云计算企业-国际

6、云计算公司-国际

AWS 全称Amazon web service(亚马逊网络服务),是亚马逊公司旗下云计算服务平台,为全世界各个国家和地区的客户提供一整套基础设施和云解决方案。
作为称雄全球云服务市场的亚马逊来说,长期以来在云服务市场独领风骚,是全球规模最大的云厂商。AWS云服务营收规模继2020年第一季度突破百亿美元大关后,第二季度继续保持稳健增长。2020年第二季度来自AWS营收规模达到108亿美元(约745亿元人民币)。

Microsoft Azure是微软基于云计算的操作系统,原名“Windows Azure”,和Azure Services Platform一样,是微软“软件和服务”技术的名称。Microsoft Azure的主要目标是为开发者提供一个平台,帮助开发可运行在云服务器、数据中心、Web和PC上的应用程序。云计算的开发者能使用微软全球数据中心的储存、计算能力和网络基础服务

2019年2月12日,在旧金山举行的高盛技术与互联网大会上,Google Cloud CEO Thomas Kurian 首次公开露面,表示Google Cloud正在追赶行业领导者AWS和微软,将招聘更多行业优秀人才加入团队中。
报告认为,从2019年到2022年,Google Cloud的收入将以每年55%的速度增长,达到2022年170亿美元的收入,届时将为Google贡献约7%的税前收入。

VMware(Virtual Machine ware)是“虚拟PC”软件公司,提供服务器、桌面虚拟化解决方案。
VMware(威睿) 是全球桌面到数据中心虚拟化解决方案的领导厂商。全球不同规模的客户依靠VMware来降低成本和运营费用、确保业务持续性、加强安全性并走向绿色。VMware使企业可以采用能够解决其独有业务难题的云计算模式。

Salesforce这家靠做中小企业SaaS CRM起家的公司在这20年间业务获得了陡峭的增长,其市值从2004年上市时11亿美元跃增至1300亿美元,在全球企业服务级软件公司中最快实现了百亿美元年营收,超过了前辈甲骨文创造的23年记录。截止2018年,Salesforce在全球CRM市场份额中占据第一,市场份额为20%以上,遥遥领先于第二名的SAP(8.3%)和第三名甲骨文(5.5%)。

IBM 云计算提供了最开放、最安全的企业公有云,它作为下一代混合多云平台,具备诸多先进的数据和 AI 功能以及 20 个行业的深厚企业专业知识。
7、云计算企业-国内


阿里云创立于2009年,是亚洲最大的云计算平台和云计算服务提供商,和亚马逊AWS、微软Azure共同构成了全球云计算市场第一阵营。阿里云在全球21个区域部署了上百个数据中心,管理的服务器规模在百万台。阿里云凭借着自主研发的飞天云操作系统,占据了国内50%左右的云计算市场份额,是国内云计算市场公认的领头羊和行业巨头。
阿里云的服务群体中,活跃着淘宝、支付宝、12306、中石化、中国银行、中科院、中国联通、微博、知乎、锤子科技等一大批明星产品和公司。在天猫双11全球狂欢节、12306春运购票等极富挑战的应用场景中,阿里云保持着良好的运行纪录。


腾讯云于2013年9月正式对外全面开放,腾讯云经过QQ、QQ 空间、微信、腾讯游戏等业务的技术锤炼,从基础架构到精细化运营,从平台实力到生态能力建设,腾讯云得到了全面的发展,使之能够为企业和创业者提供集云计算、云数据、云运营于一体的云端服务体验。
腾讯云在国内市场占据18%的市场份额,紧随阿里云之后。腾讯云业务主要包括:云计算基础服务、存储与网络、安全、数据库服务、人工智能、行业解决方案等。腾讯云凭借着在“社交、游戏”两大领域的庞大客户群和生态系统构建,腾讯云具备了与阿里云一较高下的实力。


华为云成立于2011年,专注于云计算中“公有云”领域的技术研究与生态拓展,致力于为用户提供一站式的云计算基础设施服务,是目前国内大型的公有云服务与解决方案提供商之一。华为云在国内市场占据8%左右的市场份额。
华为云,立足于互联网领域,依托华为公司雄厚的资本和强大的云计算研发实力,面向互联网增值服务运营商、大中小型企业、政府机构、科研院所等广大企业、事业单位的用户,提供各种解决方案。


百度云于2015年正式开放运营,相对于其他厂商,百度对“人工智能”和“边缘计算”这两块的投入相对较大,目前百度云提供的主要业务,包括“云计算,云存储、AI人工智能、智能互联网、智能大数据”等四大类。


金山云,创立于2012年,是金山集团旗下的云计算企业,金山云已推出云服务器、云物理主机、关系型数据库、缓存、表格数据库、对象存储、负载均衡、虚拟私有网络、CDN、托管Hadoop、云安全、云解析等在内的完整云产品,以及适用于游戏、视频、政务、医疗、教育等垂直行业的云服务解决方案。


UCloud云成立于2012年3月,是上海优刻得科技股份有限公司的云产品,UCloud核心团队来自腾讯、阿里、百度、盛大、华为、微软等国内外互联网和IT企业。
UCloud长期专注于移动互联网领域,深度了解移动互联网业务场景和用户需求。针对特定场景,UCloud通过自主研发提供一系列专业解决方案,已为上万家企业级客户在全球的业务提供云服务支持,行业涉及制造、零售、金融、游戏、直播等。


京东智联云是京东集团旗下的云计算综合服务提供商,拥有全球领先的云计算技术和完整的服务平台。依托京东集团在云计算、大数据、物联网和移动互联应用等多方面的长期业务实践和技术积淀,致力于打造社会化的云服务平台,向全社会提供安全、专业、稳定、便捷的云服务。

H3Cloud云隶属于杭州的新华三技术有限公司,该公司归属于紫光集团。
H3Cloud云计算解决方案涵盖了网络、云软件、计算、存储四大类产品。目标是为用户在以太网和云计算相关技术基础上,实现数据中心资源高效利用、虚拟化环境下云网融合、基于混合云理念的资源动态扩展以及针对用户具体业务交付的行业应用交付。结合本地强大研发、服务实施能力带给用户"一站式"的"交钥匙"交付体验。

网易云是网易集团旗下云计算和大数据品牌,致力于提供开放、稳定、安全、高性能的基础技术平台和完善的云生态体系,帮助客户实现数字化转型与创新,促进其商业蜕变与持续发展,推动产业数字化升级。
依托20余年技术积淀,网易云打造了轻舟微服务、瀚海私有云、大数据基础平台(猛犸)、可视化分析平台(有数)、专属云、云计算基础服务、通信与视频(云信)、云安全(易盾)、服务营销一体化方案(七鱼)、云邮箱(网易邮箱)等多类型产品,以及工业、电商、金融、教育、医疗、游戏等行业解决方案,并拥有完善的知识服务。

浪潮云,创立于2015年,面向政府机构和企业组织提供覆盖“云计算基础产品、云安全、政府政务、企业应用、工业互联网、行业场景解决方案”等在内的多种服务,致力于以云服务的方式,输出安全、可信的计算能力和数据处理能力。近年来,浪潮云的优势在于政府政务的“政务云”,根据 IDC 报告,浪潮云多年稳居中国“政务云”服务运营商的市场占有率第一。
四、大数据和云计算的关系
1、大数据拥抱云计算
大数据通俗的来讲就是一台机器的资源不够,需要很多台机器一块做,想什么时候要计算资源就什么时候要,想要多少台就要多少台。
只有云计算,可以为大数据的运算提供资源层的灵活性。而云计算也会部署大数据放到它的平台上,作为一个非常非常重要的通用应用。因为大数据平台能够使得多台机器一起干一个事儿。
一个小公司需要大数据平台的时候,不需要采购一千台机器,只要到公有云上一点,这一千台机器都出来了,并且上面已经部署好了的大数据平台,只要把数据放进去算就可以了。 云计算需要大数据,大数据需要云计算,二者就这样结合了。
五、人工智能AI
人工智能就是通过人工开发,使得机器拥有人类的智慧,就是让机器模仿人类,达到可以像人一样思考。

主要应用在三个方面:
机器视觉
机器视觉即让机器能够“看”,如人脸识别,图片搜索等等。
语音处理
语音处理即让机器能够听,还能够发音。比如讯飞的语音智能输入法、高德的语音导航等等。
自然语言处理
自然语言处理即通过计算机技术让机器理解并运用自然语言的学科,比如聊天机器人,文本纠错,文本分类等等。
AI已经在各行业均有了较大的应用,比如汽车行业的自动驾驶,广告业的智能广告推荐,电商的商品推荐,金融行业的异常转账监测,快递物流行业的路径智能规划,公告交通的智慧交通,零售行业的无人超市等等。
人工智能、机器学习、深度学习
人工智能、机器学习、深度学习是我们经常听到的三个热词。关于三者的关系,简单来说,机器学习是实现人工智能的一种方法,深度学习是实现机器学习的一种技术。机器学习使计算机能够自动解析数据、从中学习,然后对真实世界中的事件做出决策和预测;深度学习是利用一系列“深层次”的神经网络模型来解决更复杂问题的技术。

六、大数据和AI的关系
人工智能和大数据的关系是非常紧密的,实际上大数据的发展在很大程度上推动了人工智能技术的发展,因为数据是人工智能技术的基础之一。
一方面人工智能需要大量的数据作为”思考”和”决策”的基础;
另一方面大数据也需要人工智能技术进行数据价值化操作,为智能体(人工智能产品)提供的数据量越大,智能体运行的效果就会越好,因为智能体通常需要大量的数据进行训练和验证,从而保障运行的可靠性和稳定性;


七、传统业务处理和大数据分析处理
1、场景分析
场景一:在线购物,需要什么体验?
- 极致流畅的交互
- 低延迟的数据处理
- 处理过程的安全性
- 状态的最终一致性

场景二:支付宝年度账单,需要什么体验?
- 多维度组织细分
- 数据的对比呈现
- 视觉效果诱人

技术角度分析,应用背后数据存储有何特点?如何处理?

- 面向业务、支撑业务
- 捕捉业务状态的改变
- 事务的保证 单次操作数据量小
- 很少涉及历史数据处理
- 需要很高的并发处理能力

- 面向分析、支撑分析
- 挖掘历史数据中的价值
- 单次操作数据规模大
- 大量的读取分析操作
- 处理时效性一般要求不高
2、OLTP、OLAP
上述两种业务场景,正对应着两种数据系统
OLTP(On-Line Transaction Processing)联机事务处理
OLAP(On-Line Analytical Processing) 联机分析处理

3、OLTP、OLAP区别
下面从几个方面来区别两个系统
| 参数 | OLTP | OLAP |
| 目的 | 捕获和存储交易数据以支持日常业务运营 | 获取业务见解,解决问题,支持决策 |
| 数据管理 | 传统关系数据库管理系统(RDBMS) | 数据仓库(DW) |
| 数据源 | 日常业务交易 | 整合来自多个来源的数据,包括OLTP和外部来源 |
| 焦点 | 当下 | 过去,现在和未来(使用历史数据来计划和预测未来事件) |
| 任务 | 插入,更新,删除,排序,过滤 | 汇总和分析数据以支持决策 |
| 查询 | 简单 | 复杂 |
| 响应时间 | 毫秒 | 秒,分钟,小时或天,具体取决于数据量,查询的复杂性以及EDW的功能 |
4、OLTP系统
联机事务处理系统:RDBMS关系型数据库管理系统

5、OLAP系统
联机分析处理系统:Data Warehouse 数据仓库

6、思考一个问题
业务数据是存储在OLTP系统中,直接开展数据分析可以吗?

7、OLTP和OLAP关系
企业中数据库和数据仓库一般都会存在,如何正确区分很关键


八、大数据时代对数据存储的挑战
1、当前数据存储新要求:
1、高并发读写需求
对于实时性、动态性要求较高的的社交网站,如论坛、微博等,往往需要达到每秒上万次的读写请求,这种很高的并发性对数据库的并发负载相当大,特别是对与传统关系数据库的硬盘I/O是个很大的负担。
2、海量非结构化数据存储需求
非结构化数据,指的是数据结构不规则或不完整,没有任何预定义的数据模型,不方便用二维逻辑表 来表现的数据,例如办公文档(Word)、文本、图片、HTML、各类报表。
3.高扩展性
对于传统数据库来讲,可以通过纵向扩展来提高数据存储能力,当数据量增加到一定程度是就会遇到瓶颈。
2、NoSQL(Not Only SQL)

意思是"不仅仅是 SQL",指的是非关系型数据库,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL 用于超大规模数据的存储。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
- 灵活存储结构;
- 容量水平扩张;
- 高可用特性;
- 可以大数据框架集成;
1、键值数据库
相关产品:Redis、Riak、SimpleDB、Chordless、Scalaris、Memcached 应用:内容缓存,适用于数据变化快且数据库大小可遇见(适合内存容量)的应用程序 优点:扩展性好、灵活性好、大量写操作时性能高 缺点:无法存储结构化信息、条件查询效率较低 使用者:百度云(Redis)、GitHub(Riak)、BestBuy(Riak)、Twitter(Ridis和Memcached)

2、列族数据库
相关产品:BigTable、HBase、Cassandra、HadoopDB、GreenPlum、PNUTS 应用:分布式数据存储与管理,并且需要对大数据进行随机、实时访问的场合。 优点:查找速度快、可扩展性强、容易进行分布式扩展、复杂性低 使用者:Ebay(Cassandra)、Instagram(Cassandra)、NASA(Cassandra)、Facebook(Hbase)

3、文档数据库
相关产品:MongoDB、CouchDB、ThruDB、CloudKit 应用:存储、索引并管理面向文档的数据或者类似的半结构化数据 优点:性能好、灵活性高、复杂性低、数据结构灵活 缺点:缺乏统一的查询语言 使用者:百度云数据库(MongoDB)、SAP(MongoDB)
4、图形数据库
图形数据库-使用图作为数据模型来存储数据。 相关产品:Neo4J、OrientDB、InfoGrid、GraphDB 应用:大量复杂、互连接、低结构化的图结构场合,如社交网络、推荐系统等,社会关系,公共交通网络,地图及网络拓谱 优点:灵活性高、支持复杂的图形算法、可用于构建复杂的关系图谱 缺点:复杂性高、只能支持一定的数据规模 使用者:Adobe(Neo4J)、Cisco(Neo4J)、T-Mobile(Neo4J)

3、NoSQL和RDBMS区别

4、关系型数据库尚能饭否?
随着关系型数据库的不足之处暴露得越来越明显,NoSQL的出现成为了有益补充。不过NoSQL并非为了取代关系型数据库,而是指Not Only SQL,提供了在SQL之外的另一种选择。
正如NoSQL的定义所说,它们仅仅是基于SQL的关系型数据库的有益补充,而非关系型数据库的替代者
传统数据库的优势:
开发优势
对于开发人员来说,关系型数据库的首要优势是面向SQL。此外,SQL语言,流行度非常广泛,降低招聘成本,除了SQL语言本身,各种开发语言对关系型数据库的支持也十分完善。
运维优势
成熟的关系型数据库都有自己完善的生态圈,有成熟的配套工具。
系统优势
关系型数据库经历了几十年的考验,已经有超大规模的使用,其存储引擎已经十分成熟。基于ACID的事务支持可以最大限度的保证数据的正确性和完整性:
NoSQL数据库的不足:
不同的NoSQL数据库都有自己的查询语言,相比于SQL,制定应用程序标准接口比较难。并且NoSQL对事务的支持不够强大。
九、分布式系统
- 数据处理中经常发生的问题
1、服务器宕机

2、网络异常

3、磁盘故障

- 分布式是指将多台服务器集中在一起,每台服务器都实现总体中的不同业务,做不同的事情。


- 分布式的优点是细化了应用程序的功能模块,同时也减轻了一个完整的应用程序部署在一台服务器上的负担,用了分布式拆分后,就相当于把一个应用程序的多个功能分配到多台服务器上去处理了。
- 分布式系统容易产生单点故障。


1、分布式存储
分布式存储系统面向海量数据的存储访问与共享需求,提供基于多存储节点的高性能,高可靠和可伸缩性的数据存储和访问能力,实现分布式存储节点上多用户的访问共享。
常见的分布式文件系统:HDFS、OpenStack Swift、Ceph、GlusterFS、Lustre、AFS、OSS等。


2、分布式计算

十、集群系统
- 所谓集群是指一组独立的计算机系统构成的一个松耦合的多处理器系统,它们之间通过网络实现进程间的通信,让若干台计算机联合起来工作(服务),可以是并行的,也可以是做备份。

1、集群
集群的分类
- (1)高可靠性(HA)
利用集群管理软件,当主服务器故障时,备份服务器能够自动接管主服务器的工作,并及时切换过去,以实现对用户的不间断服务。
(2)高性能计算(HP)
即充分利用集群中的每一台计算机的资源,实现复杂运算的并行处理,通常用于科学计算领域,比如基因分析、化学分析等
2、集群和分布式区别
分布式 :分布式的主要工作是分解任务,将职能拆解,多个人在一起做不同的事
集群:集群主要是将同一个业务,部署在多个服务器上 ,多个人在一起做同样的事
十一、大数据计算引擎
- 批量计算(batch computing)
- 流式计算(stream computing) –实时计算
- 图计算(graph computing) ---pregel
1、第一代计算引擎

2、第二代计算引擎


3、第三代计算引擎

4、第四代计算引擎

十二、大数据流式计算
1、流式计算-概念

流式计算处理数据的速度在秒级甚至毫秒级。
2、流式计算-应用场景
- 设备故障告警:极其迅速感知到故障的发生,并及时进行告警。
- 实时监控:实时分析设备的监控数据,实现对设备各项指标的实时监控。
- 动态跟踪:实时跟踪并显示设备(比如汽车)的位置。
- 欺诈探测:实时分析用户行为,并及时辨识到可疑欺诈行为。
- 个性化推荐:根据视频用户的访问内容,实时为视频用户推荐个性化内容。
- 实时统计:实时统计当前直播间运营情况,包括热门视频、用户走势等等。
- 个性化精准推荐:实时掌握用户的需求和喜好,进行个性化精准推荐。
- 实时报表:多维度实时了解PV\UV、销量、销售额、地域分布等。
- 实时感知变化趋势:对商品整体的热度和关注量进行动态监测,感知商品关注度变化趋势。
3、流式计算-发展


4、流式计算-sparkstreaming


5、流式计算-storm



1、美团开店宝的实时经营数据卡片。

2、美团点评金融合作门店的实时热度标签。

7、流式计算-storm小结

8、Storm VS Flink

9、流式计算-Flink

10、流式计算-Flink在快手的应用





十三、程序员要突破的瓶颈
程序员本身是有很多优势的,也有很多闪光点,但俗话说,有一利必有一弊,由于职业的属性特点,他们有会受到相应的限制。程序员们如何突破自身局限性,也许就能找到真正意义上通向人生巅峰的道路。


1、选择瓶颈


2、 技术瓶颈


3、薪资瓶颈


4、学习瓶颈


5、职业发展瓶颈

- 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/232884
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

