
- 12024最新GPT4.0使用教程,AI绘画,一站式解决
- 2超分辨率技术AI人工智能老照片修复自动人像脑补照片高清重建人脸模糊图片变清晰软件_人像照片自动补全
- 3Java循环与数组_java 循环建立数组
- 4org.apache.rocketmq.remoting.exception.RemotingConnectException: connection to ip : 10911 failed
- 5【暂缓更新说明】鸿蒙应用项目分享:我的鸿蒙毕设:基于HarmonyOS的任务看板平台【四】:登录注册模块页面_鸿蒙开发注册界面设计
- 6cortex系列处理器排行_Arm中国“星辰”处理器量产!与Cortex-M有何区别?
- 7JavaScript 进阶面向对象ES6_javascript '@localizer[""]
- 8VMware15安装centos7_vm15 c
- 9MyBatis-Plus 可视化代码生成器_代码生成器 mybatis-plus
- 10QT5.14 QTextEdit的内容保存到文件的方法_qt中保存文本框内容
昆仑天工AIGC——基于Stable Diffusion的多语言AI作画大模型测评_aigc stable diffusion
赞
踩
1. AIGC
今年掀起了一股AI 艺术的创作热潮,随着Stable Diffusion的出现,人工智能生成内容模型(Artificial Inteligence Generated Content,AIGC)终于接近了商用化标准,然而目前可用的AIGC模型都需要在英文场景下使用。在这样的背景下,昆仑天工针对AIGC模型在中文领域劣势结合Chinese-CLIP模型推出了全系列的AIGC大模型,AI生成能力覆盖图像、音乐、编程、文本等全模态领域。
2. 技术背景
2.1. Stable Diffusion
Stable Diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。

它包含三个模块:感知压缩、扩散模型和条件机制。
2.1.1. 图像感知压缩(Perceptual Image Compression)
图像感知压缩通过VAE自编码模型对原图进行处理,忽略掉原图中的高频细节信息,只保留一些重要、基础的特征。该模块并非必要,但是它的加入能够大幅降低训练和采样的计算成本,大大降低了图文生成任务的实现门槛。
基于感知压缩的扩散模型的训练过程有两个阶段:(1)训练一个自编码器;(2)训练扩散模型。在训练自编码器时,为了避免潜在表示空间出现高度的异化,作者使用了两种正则化方法,一种是KL-reg,另一种是VQ-reg,因此在官方发布的一阶段预训练模型中,会看到KL和VQ两种实现。在Stable Diffusion中主要采用AutoencoderKL这种正则化实现。
具体来说,图像感知压缩模型的训练过程如下:给定图像 x ∈ R H × W × 3 x\in \mathbb{R}^{H\times W\times 3} x∈RH×W×3,我们先利用一个编码器 ε \varepsilon ε来将图像从原图编码到潜在表示空间(即提取图像的特征) z = ε ( x ) z=\varepsilon(x) z=ε(x),其中 z ∈ R h × w × c z\in \mathbb{R}^{h\times w\times c} z∈Rh×w×c。然后,用解码器从潜在表示空间重建图片 x ~ = D ( z ) = D ( ε ( x ) ) \widetilde{x}=\mathcal{D}(z)=\mathcal{D}(\varepsilon(x)) x =D(z)=D(ε(x))。训练的目标是使 x = x ~ x=\widetilde{x} x=x 。
2.1.2. 隐扩散模型(Latent Diffusion Models)
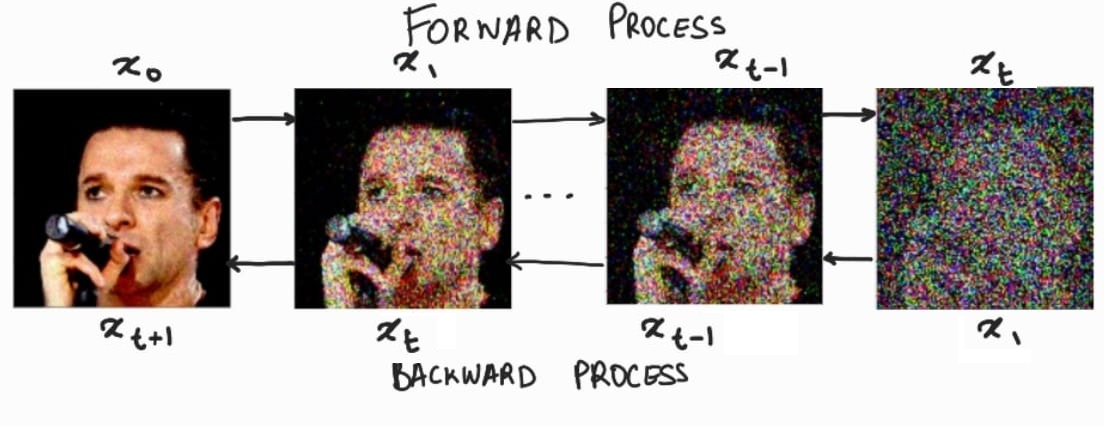
扩散模型(DM)从本质上来说,是一个基于马尔科夫过程的去噪器。其反向去噪过程的目标是根据输入的图像 x t x_t xt去预测一个对应去噪后的图像 x t + 1 x_{t+1} xt+1,即 x t + 1 = ϵ t ( x t , t ) , t = 1 , . . . , T x_{t+1}=\epsilon_t(x_t,t),\ t=1,...,T xt+1=ϵt(xt,t), t=1,...,T。相应的目标函数可以写成如下形式: L D M = E x , ϵ ∼ N ( 0 , 1 ) , t = [ ∣ ∣ ϵ − ϵ θ ( x t , t ) ∣ ∣ 2 2 ] L_{DM}=\mathbb{E}_{x,\epsilon\sim\mathcal{N(0,1),t}}=[||\epsilon-\epsilon_\theta(x_t,t)||_{2}^{2}] LDM=Ex,ϵ∼N(0,1),t=[∣∣ϵ−ϵθ(xt,t)∣∣22]这里默认噪声的分布是高斯分布 N ( 0 , 1 ) \mathcal{N(0,1)} N(0,1),这是因为高斯分布可以应用重参数化技巧简化计算;此处的 x x x指的是原图。
而在潜在扩散模型中(LDM),引入了预训练的感知压缩模型,它包括一个编码器 ε \varepsilon ε 和一个解码器 D \mathcal{D} D。这样在训练时就可以利用编码器得到 z t = ε ( x t ) z_t=\varepsilon(x_t) zt=ε(xt),从而让模型在潜在表示空间中学习,相应的目标函数可以写成如下形式: L L D M = E ε ( x ) , ϵ ∼ N ( 0 , 1 ) , t = [ ∣ ∣ ϵ − ϵ θ ( z t , t ) ∣ ∣ 2 2 ] L_{LDM}=\mathbb{E}_{\varepsilon(x),\epsilon\sim\mathcal{N(0,1),t}}=[||\epsilon-\epsilon_\theta(z_t,t)||_{2}^{2}] LLDM=Eε(x),ϵ∼N(0,1),t=[∣∣ϵ−ϵθ(zt,t)∣∣22]
2.1.3. 条件机制(Conditioning Mechanisms)
条件机制,指的是通过输入某些参数来控制图像的生成结果。这主要是通过拓展得到一个条件时序去噪自编码器(Conditional Denoising Autoencoder,CDA) ϵ θ ( z t , t , y ) \epsilon_\theta(z_t,t,y) ϵθ(zt,t,y)来实现的,这样一来我们就可通过输入参数 y y y 来控制图像生成的过程。
具体来说,论文通过在UNet主干网络上增加cross-attention机制来实现CDA,选用UNet网络是因为实践中Diffusion在UNet网络上效果最好。为了能够从多个不同的模态预处理参数
y
y
y,论文引入了一个领域专用编码器(Domain Specific Encoder)
τ
θ
\tau_\theta
τθ,它将
y
y
y映射为一个中间表示
τ
θ
(
y
)
∈
R
M
×
d
r
\tau_\theta(y)\in\mathbb{R}^{M\times d_r}
τθ(y)∈RM×dr,这样我们就可以很方便的将
y
y
y设置为各种模态的条件(文本、类别等等)。最终模型就可以通过一个cross-attention层映射将控制信息融入到UNet的中间层,cross-attention层的实现如下:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
⊤
d
)
⋅
V
Attention(Q,K,V)=softmax(\frac{QK^\top}{\sqrt{d}})\cdot V
Attention(Q,K,V)=softmax(d
QK⊤)⋅V
Q
=
W
Q
(
i
)
⋅
φ
i
(
z
t
)
,
K
=
W
K
(
i
)
⋅
τ
θ
(
y
)
,
V
=
W
V
(
i
)
⋅
τ
θ
(
y
)
Q=W_{Q}^{(i)}\cdot \varphi_i(z_t),\quad K=W_{K}^{(i)}\cdot \tau_\theta(y),\quad V=W_{V}^{(i)}\cdot \tau_\theta(y)
Q=WQ(i)⋅φi(zt),K=WK(i)⋅τθ(y),V=WV(i)⋅τθ(y)其中
φ
i
(
z
t
)
∈
R
N
×
d
ϵ
i
\varphi_i(z_t)\in \mathbb{R}^{N\times d_{\epsilon}^{i}}
φi(zt)∈RN×dϵi 是UNet的一个中间表征;
W
Q
(
i
)
W_{Q}^{(i)}
WQ(i)、
W
K
(
i
)
W_{K}^{(i)}
WK(i)和
W
V
(
i
)
W_{V}^{(i)}
WV(i)分别是三个权重矩阵。此时,带有条件机制的隐扩散模型的目标函数可以写成如下形式:
L
L
D
M
=
E
ε
(
x
)
,
y
,
ϵ
∼
N
(
0
,
1
)
,
t
=
[
∣
∣
ϵ
−
ϵ
θ
(
z
t
,
t
,
τ
θ
(
y
)
)
∣
∣
2
2
]
L_{LDM}=\mathbb{E}_{\varepsilon(x),\ y,\ \epsilon\sim\mathcal{N(0,1),\ t}}=[||\epsilon-\epsilon_\theta(z_t,\ t,\ \tau_\theta(y))||_{2}^{2}]
LLDM=Eε(x), y, ϵ∼N(0,1), t=[∣∣ϵ−ϵθ(zt, t, τθ(y))∣∣22]
2.2. Chinese-CLIP
Chinese-CLIP是OpenAI训练的大规模语言模型,在今年7月份开源在Github上,详情可点击 Chinese-CLIP 查看。它是 CLIP 模型的一个变体,使用大规模中文数据进行训练(超过2亿图文对)。它基于open_clip project建设,经过训练可以识别和分类图像和文本,并针对中文领域数据以及在中文数据上实现更好的效果做了优化,专门适用于处理中文语言和文本。Chinese-CLIP可以理解并生成自然语言文本,以帮助用户快速实现中文领域的图文特征&相似度计算、跨模态检索、零样本图片分类等任务。

3. 昆仑天工AIGC
3.1. 模型贡献和展望
昆仑天工的这款AI绘画大模型在Stable Diffusion的基础上,利用Chinese-CLIP构造了大规模的中文图文对数据集进行训练,这使得该模型支持中英双语提示词输入实现文字生成图像。总体来说,该模型相较于现有模型有三个大的共享:
- 在增加中文提示词输入能力的同时兼容原版stable_diffusion的英文提示词模型,之前用户积累的英文提示词手册依然可以在昆仑天工的模型上使用。
- 使用超过1.5亿级别的平行语料优化提示词模型实现中英文对照,不仅涉及翻译任务语料,还包括了用户使用频率高的提示词中英语料,古诗词中英语料,字幕语料,百科语料,图片文字描述语料等多场景多任务的海量语料集合。
- 训练时采用模型蒸馏方案和双语对齐方案,使用教师模型对学生模型蒸馏的同时辅以解码器语言对齐任务辅助模型训练,提高模型性能。
同时,该模型具备功能可扩展性,对于之后的技术发展趋势和展望主要集中在:
- 除中英文外,更多语言的提示词输入支持 ;
- 更强大的语言生成模型指导图像生成,而非局限于Stable Diffusion;
- 绘画风格更加多样,增加更多艺术风格的支持;
- 支持用户对生成的图像进行二次提示词编辑图像功能,方便用户调整生成图像。
3.2. 性能对比
昆仑天工的AIGC模型(prev_online、hide77_gpt2)在Flickr30K-CN数据集上与6个基准算法进行了对比。
实验设置:
- Benchmark:采用Chinese-CLIP(CN_CLIP),先根据模型的encoder得到text和image的embedding,再经过统一的KNN检索,Recall,从而计算出检索任务的Recall@1/5/10和mean recall(Recall@1/5/10的均值),得到实验结果。
- 评估数据集:Flickr30K-CN的Test数据集
- 采用同级别image encoder模型:ViT-L/14
实验结果如下表所示:

可以看到,不论是文本生成图像还是图像生成文本任务,昆仑天工在Recall指标上都超越了绝大多数模型。
3.3. 效果展示
为了展示昆仑天工AIGC大模型的效果,我们对多种艺术风格和画面主题的提示词进行了试用,结果如下:
-
人物立绘(动漫、CG、剪纸、古风)

-
风景景像(城市、原野、未来、古代)

-
艺术绘画(油画、水彩、版画、水墨)
-

-
平面设计(线性、面性、扁平、手绘)

-
细节质感(毛发、4K、色彩、局部)

-
英文提示词

4. 小结
昆仑天工的AIGC大模型包括三大功能:
本次我们测评和解析的是绘画功能,文本及代码两大功能也十分实用,就不在此赘述,感兴趣的伙伴们可以去官网感受体验,一定会有新发现~

昆仑万维集团作为中国领先的互联网平台出海企业,逐渐在全球范围内形成了海外信息分发及元宇宙平台Opera、海外社交娱乐平台StarX、全球移动游戏平台Ark Games、休闲娱乐平台闲徕互娱、投资板块等五大业务,市场遍及中国、东南亚、非洲、中东、北美、南美、欧洲等地,为全球互联网用户提供社交、资讯、娱乐等信息化服务。截至2022年上半年,全球平均月活跃用户近 4 亿, 海外收入占比达 75%。昆仑万维于2015年登陆创业板,集团旗下的业务和子公司已先后拓展至美国、俄罗斯、日本、韩国、印度,以及欧洲、非洲、东南亚等地的其他国家。

