
- 1华为、苹果、高通,谁在领跑?全面解读清华AI芯片报告
- 2Android移动应用开发教程⑦_移动开发教程
- 3Pipeline工程配置NodeJS环境_pipeline node
- 4点云地面点滤波(Progressive Morphological Filter)算法介绍(PCL库)_a progressive morphological filter for removing no
- 5华为手机可以下载鸿蒙系统吗_华为鸿蒙手机系统真的来了!会是大题材吗?
- 6深度学习模型ckpt转成pb模型(YOLOv3为例)_tensorflow模型文件(ckpt)转pb文件 yolov3
- 7使用SSM框架进行web项目的开发(SpringMVC+Spring+MyBatis)_网络工程的基于ssm框架
- 8基于SpringBoot的宿舍管理系统
- 9AI文章检测:揭秘真相,看穿假信息_虚假信息 ai 识别
- 10正则表达式 replace()替换
python进阶到高阶大全(强烈推荐)_python学习
赞
踩
关键字is 和 == 的区别
- a = 'hello world'
- b = 'hello world'
- a == b #返回True
- a is b #返回False
注意:is 判断是否是一个ID, == 判断内容是否一致。
深拷贝和浅拷贝
- import copy
- a = [1,2,3,4,5]
- b = a #浅拷贝,a,b同时指向一个id,当其中一个修改时,另外一个也会被修改。
- c = copy.deepcopy(a) #深拷贝,c单独开辟一个id,用来存储和a一样的内容。
- d =a[:] #这样也是深拷贝。
- e = copy.copy(a) #当拷贝内容是可变类型时,那么就会进行深拷贝,如果是不可变类型时,那么就会进行浅拷贝。
注意:深拷贝指的是复制内容,单独开辟一个内存,浅拷贝指的是两个变量同时指向一个内存ID。
私有化和Property
- class Test(object):
- def __init__(self):
- self.__num = 100
- @getNum.setter #等同步于 porperty(setNum,getNum)
- def setNum(self,num): #将self.__num的属性封装。
- self.__num = num
- @porperty #等于getNum = porperty(getNum) 默认的是getter方法。
- def getNum(self) #获取__num的值。
- return self.__num
- num = porperty(getNum,setNum) #使用关键字porperty将getNum和setNum方法打包使用,并将引用赋予属性num。
- t = Test()
- print(t.__num) #将会出错,表示输出私有属性,外部无法使用。
- t.__num = 200 #这里将会理解为添加属性 __num = 200,而不是重新赋值私有属性。
- print(t.__num) #这里输出的200是定义的属性__num,而不是self.__num。
- t.setNum(200) #通过set方法将私有属性重新赋值。
- t.getNum() #通过get方法获取__num的值。
- print(_Test__num) #私有属性其实是系统再私有属性前加上了一个_Test,就是一个下划线加类名。
-
- t.num = 300 #调用类属性num,并重新赋值,porperty会自动检测set方法和get方法,并将引用赋值给set方法。
- print(t.num) #输出类属性,并会自己检测使用get方法进行输出。

注意: num 前后没有下划线的是公有方法,_num 前边有一个下划线的为私有方法或属性,子类无法继承, 前边有两个下划线的 一般是为了避免于子类属性或者方法名冲突,无法在外部直接访问。前后都有双下划线的为系统方法或属性。后边单个下划线的可以避免与系统关键词冲突。
列表生成式
- range(1,100,5) #第一个参数表示开始位,第二个参数表示结束位(不含),第三个参数表示步长,就是每5个数返回一次。
- a = [i for i in range(1,10)] #列表生成式表示返回i的值,并且返回9次,每次返回的是i的值。
- a = [2 for i in range(1,10)] #这里表示返回2,并且返回9次,但是每次的值都是2。
- a = [i for i in range10 if i%2==0] #表示在生成式内部加入if判断,当i除以2的余数等于0的时候将数值返回。
- a = [(i,j) for i in range(5) for j in range(5)] #表示将i和j的值以元组为元素的形式返回,当i循环一次的时候j循环5次,以此类推。
生成器
- a = (i for i in range(1,10)) #将列表生成试外部的中括号改为小括号,就能将生成式转化为生成器。
- next(a),a.__next__() #生成器的取值方式只能使用next的方法。
- def num():
- a,b = 0,1
- for i in range(10):
- yield b #生成关键字yield,有yield的关键字的代码块就是yield的生成器。当运行到yield时代码就会停止,并返回运行结果,当在次运行时依旧是到yield停止,并返回结果。 切记:生成器只能使用next方法。
- a,b = b,a+b
- temp = yield b #这里并不是变量的定义,当运行到yield时就会停止,所以当运行到等号右边的时候就会停止运行,当在次使用next的时候,将会把一个None赋值给temp,因为b的值已经在上轮循环中输出。这里可以使用num().send()方法将一个新的值赋值给temp。
- a = num() #将生成器赋值给变量a。
- for n in a: #生成器可以使用for循环使用,并且不会出错。
- print(n)
注意:生成器占用内存小,在使用的时候取值,降低CPU和内存空间,提高效率。并且一般都使用for循环进行取值。
迭代器
- for i in '',[],(),{},{:}
- #可以for循环的对象是可迭代对象。
- a = (x for i in range(100))
- #列表生成式,把中括号改为小括号就可以变为一个列表生成器,是可迭代对象。
- from collections import Iterable #如果想验证是否是可迭代对象,可以使用isinstance()判断是否是可迭代对象。
- isinstance('abc',Ierable) #判断语法
- a = [1,2,3,4,5]
- b = iter(a) #使用iter()方法可以将可迭代对象转换为可迭代对象。
注意:生成器是可迭代对象,迭代器不一定是生成器。并且迭代器无法回取,只能向前取值。
注意:一个对象具有 iter 方法的才能称为可迭代对象,使用yield生成的迭代器函数,也有iter方法。凡是没有iter方法的对象不是可迭代对象,凡是没有__next__()方法的不是是生成器。(这里的方法都是魔法方法,是内置方法,可以使用dir()查看)
闭包
- def num(num): #定义函数
- def num_in(nim_in): #定义函数
- return num + num_in #返回两个参数的和。
- return num_in #返回内部函数的引用。(变量名)
-
- a = num(100) #将参数为100的函数num接收,并赋值给a,只不过这个返回值是一个函数的引用。等于 a = num_in,注意这里接收的不光是函数本身,还有已经传递的参数。
- b = a(100) #调用函数a,即num_in,并传递一个参数100,返回值给b。
注意:当一个函数定义在另一个函数内,且使用到了外部函数的参数。整个代码块称为闭包。当外部参数确定时,内部函数参数可以反复调用。
装饰器
装饰没有参数的函数
- def function(func): #定义了一个闭包
- def func_in(): #闭包内的函数
- print('这里是需要装饰的内容,就是需要添加的内容')
- func() #调用实参函数。
- return func_in
-
- def test(): #需要被装饰修改的函数。
- print('无参函数的测试')
-
- test = function(test) #装饰器的原理就是将原有的函数名重新定义为以原函数为参数的闭包。
- test() 这里再次掉用test()的时候,其实是将会调用闭包内的函数func_in()。所以将会起到装饰修改的作用,最后会再次调用原函数test()。
-
- @function #装饰器的python写法,等价于test = function(test),并且无需调用当代码运行道这里,Python会自动运行。
- def test():
- print('无参函数的测试')
- test() #这里再次调用函数时,将会产生修改后的效果。
-
装饰带有参数的函数
- def function(func): #定义了一个闭包
- def func_in(*args,**kwargs): #闭包内的函数,因为装饰器运行的实则是闭包内的函数,所以这里将需要有形参用来接收原函数的参数。
- print('这里是需要装饰的内容,就是需要添加的内容')
- func(*args,**kwargs) #调用实参函数,并传入一致的实参。
- return func_in
-
- @function #装饰器的python写法,等价于test = function(test) .
- def test():
- print('无参函数的测试')
-
- test(5,6) #这里再次掉用test()的时候,其实是将会调用闭包内的函数func_in()。所以将会起到装饰修改的作用,最后会再次调用原函数test()。
装饰带有返回值的函数
- def function(func): #定义了一个闭包
- def func_in(*args,**kwargs): #闭包内的函数,因为装饰器运行的实则是闭包内的函数,所以这里将需要有形参用来接收原函数的参数。
- print('这里是需要装饰的内容,就是需要添加的内容')
- num = func(*args,**kwargs) #调用实参函数,并传入一致的实参,并且用变量来接收原函数的返回值,
- return num #将接受到的返回值再次返回到新的test()函数中。
- return func_in
- @function
- def test(a,b): #定义一个函数
- return a+b #返回实参的和
通用装饰器
- def function(func): #定义了一个闭包
- def func_in(*args,**kwargs): #闭包内的函数,因为装饰器运行的实则是闭包内的函数,所以这里将需要有形参用来接收原函数的参数。
- print('这里是需要装饰的内容,就是需要添加的内容')
- num = func(*args,**kwargs) #调用实参函数,并传入一致的实参,并且用变量来接收原函数的返回值,
- return num #将接受到的返回值再次返回到新的test()函数中。
- return func_in
带有参数的装饰器
- def func(*args,**kwags):
- def function(func): #定义了一个闭包
- def func_in(*args,**kwargs): #闭包内的函数,因为装饰器运行的实则是闭包内的函数,所以这里将需要有形参用来接收原函数的参数。
- print('这里是需要装饰的内容,就是需要添加的内容')
- num = func(*args,**kwargs) #调用实参函数,并传入一致的实参,并且用变量来接收原函数的返回值,
- return num #将接受到的返回值再次返回到新的test()函数中。
- return func_in
- return function
-
- @func(50) #这里会先运行函数func,并切传入参数,之后会再次运行闭包函数进行装饰, @func(50)>>@function,然后将由@function继续进行装饰修改。
- def test(a,b):
- print('这是一个函数')
- return a+b
- class Test(object): #定义一个类
- def __init__(self,func):
- self.__func = func
- def __call__(self): #定义call方法,当直接调用类的时候,运行这里。
- print('这里是装饰的功能')
- self.__func()
- t = Test() #实例化对象
- t() #调用类,将会调用call方法。
-
- @Test #类装饰器等于test = Test(test),将函数test当作参数传入类中的init方法,并将函数名赋值给私有属性__func,当函数test被调用的时候,其实是运行Test类中的call方法.
- def test():
- print('被装饰的函数')
- test() #这里调用的不在是函数test,而是实例对象test的call方法,会先进行装饰,然后再调用私有属性__func(),__func 其实就是被装饰的函数test。
动态语言添加属性和方法
- class Person(): #创建一个类
- def __init__(self,name): #定义初始化信息。
- self.name = name
- li = Person('李') #实例化Person('李'),给变量li
- li.age = 20 #再程序没有停止下,将实例属性age传入。动态语言的特点。
- Person.age = None #这里使用类名来创建一个属性age给类,默认值是None。Python支持的动态属性添加。
- def eat(self): #定义一个方法,不过这个方法再类之外。
- print('%s正在吃东西。。'%self.name)
- import types #动态添加方法需要使用tpyes模块。
- li.eat = types.MethodType(eat,li) #使用types.MethodType,将函数名和实例对象传入,进行方法绑定。并且将结果返回给li.eat变量。实则是使用一个和li.eat方法一样的变量名用来调用。
- li.eat() #调用外部方法eat()方法。
-
- @staticmethod #定义静态方法。
- def test(): #定义静态方法,静态方法可以不用self参数。
- print('这是一个静态方法。')
- Person.test = test #使用类名.方法名 = test的形式来方便记忆和使用,Person.test其实只是一个变量名,没有特殊的含义。
- Person.test() #调用test方法。
-
- @classmethod #类方法
- def test(cls):
- print('这是一个类方法。')
- Person.test = test #定义一个类属性等于方法名。
- Person.test() #调用方法。
-
- class test(object): #定义一个类。
- __slots__ = ('name','age') #使用slots来将属性固定,不能进行动态添加修改。
元类
创建带有类属性的类
- Test = type('Test',(object,),{'num':0} #元类是只使用type创建的类,使用type会有3个参数,第一个是类名,第二个小括号内是父类名,需要使用元组。第三个字典中是类属性,使用type能够快速的动态创建一个类。
- class Test(object): #创建一个类,等价于上边
- num = 0
创建带有方法的类
- def eat(self): #定义一个函数,self作为第一个参数。
- print ('%s正在吃饭。。'%self.name)
- Person = type('Person',(object,), {'eat':eat,'name':None} #使用type创建一个类,但是有两个属性,一个是eat,一个是name,但是eat的值是函数eat的引用。
- p = Person() #实例化
- p.name = 'Tom' #类属性赋值
- p.eat() #调用eat()方法。
内建属性
- __init__ #构造初始化函数,__new__之后运行
- __new__ #创建实例所需的属性
- __class__ #实例所在的类,实例.__class__
- __str__ #实例的字符串表示,可读性高
- __repr__ #实例的字符串表示,准确性高
- __del__ #删除实例引用
- __dict__ #实力自定义属性,vars(实例.__dict__)
- __doc__ #类文档,help(类或者实例)
- __bases__ #当前类的所有父类
- __getattribute__ #属性访问拦截器。
内建方法
- range(start,stop,[,step]) #生成器
- map(function, iterable, ...) # map() 会根据提供的函数对指定序列做映射。
- filter(function, iterable) #filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
- reduce(function, iterable[, initializer]) #reduce() 函数会对参数序列中元素进行累积。
- sorted(iterable[, cmp[, key[, reverse]]]) #sorted() 函数对所有可迭代的对象进行排序操作。sort 与 sorted 区别:
- sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
- list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
PDB调试
- 1.python -m pdb xxx.py #在命令行输入以上命令,进入pdb调试模式。XXX.py表示需要打开的文件。
- 2.import pdb
- pdb.run('func(*args)') #第二种方式,当程序在运行中调试。
- 3.pdb.set_trace() #第三种方法,当程序运行到这行代码时,就会自动运行。
- l(list) # 显示全部代码
- n(next) # 向下执行一行代码
- c(contiune) # 执行余下的代码
- b(break) 10 # 设置断点,b 10表示将断点设置到第10行。clear 1,删除第一个断点
- p(print) a,b #打印变量的值
- a(args) #打印全部的形参数据
- s(step) #进入到一个函数
- r(return) #快速执行到函数的最后一行
进程和线程
进程
- import os
- pid = os.fork() #这里将会创建一个子进程,返回值会是子进程PID值。
- print('父子进程都会输出。') #这里没有判断语句,将会运行两次,一次是父进程,一次是子进程。
- if pid > 0: #判断,父进程的返回值会大于0。
- print('子进程的PID是%d,父进程的PID是%d'%(os.getpid(),os.getppid())) #getpid的获取当前进程的pid,如果子进程getpid的时候,会得到子进程的值,再子进程使用getppid的时候能够获取到父进程的pid。
- else: #子进程的返回值则会永远是0
- print('父进程的PID是%d'%os.getpid()) #当父进程使用getpid的时候获得的是父进程的pid。
**注意:**进程值PID是不能重复的,类似于端口。系统会为每个进程会分配不同的PID进行区分不同的软件进程。并且父子进程会独立运行,互不干扰。而且父子进程的调用需要系统来调度,没有固定性。
- import os
- pid = os.fork() #创建子进程,接收pid的返回值。
- if pid > 0: #判断是子进程还是父进程。
- print('父进程') #当pid的返回值是0的时候,会运行父进程
- else:
- print('子进程') #否则就是子进程
- pid =os.fork() #让之前的父子进程再次创建各自的子进程
- if pid > 0: #判断父子进程
- print('父进程的子进程') #这里会运行2次父进程
- else:
- print('子进程的子进程') #这里也会运行两次子进程
windons中的fork()-Process
- from multiprocessing import Process #导入模块类,这是一个类
- import time
- def test(): #定义一个函数
- while True:
- print('-1-')
- time.sleep(1)
- p = Process(target=test) #创建一个实例,就是一个新进程,并且执行的代码就是test()函数
- p.start() #调用start方法让子进程开始运行。
- p.join(10) #join表示延时时间,也就是等待子进程的时间,当10秒过了以后,则会运行主进程。
- while True: #这里是主进程。
- print('-2-')
- time.sleep(1)
注意:Process需要自己创建进程,以及调用开始进程,fork则是全自动运行。后期最好以Process为主,可实现跨平台运行。还有最主要的一点是Process的主进程会等待子进程。
Process实例
- from multiprocessing import Process
- import time
-
- class Process_class(Process): #创建一个Process的子类。
- def run(self): #重写run方法,当调用start方法时,则会默认调用run方法,所以不用再填写target参数。
- while True:
- print('--1--')
- time.sleep(1)
- p = Process_class() #实例化一个子进程。
- p.start() #运行子进程
- p.join(5) #这里将会等待子进程单独运行5秒。
- while True: #主进程,当join等待结束收,则会父子进程一起运行。但是如果当父进程运行完,子进程还没有结束,那么父进程会继续等子进程。
- print('--main--')
- time.sleep(1)
进程池Pool
- from multiprocessing import Pool #导入Pool模块类
- import os,time
- def work(num): #创建一个进程的工作函数。
- for i in range(2): #表示每次工作需要执行2次。
- print('进程的pid是%d,进程值是%d'%(os.getpid(),num)) #输出两次
- time.sleep(1)
-
- p = Pool(2) #实例化对象,参数2表示创建2个子进程,就是说每次只能执行2个进程。
-
- for i in range(6):
- print('--%d--'%i)
- p.apply_async(work,(i,)) #向实例对象添加6次任务,就是6个进程,但是实例对象的进程池只有2个,需要每次执行2个进程,当2个进程执行完以后则会再次执行下面2个。
-
- p.close() #关闭进程池,不再接收进程任务。
- p.join() #当子进程工作结束后,则会运行主进程。
Queue队列
Process的Queue用法
- from multiprocessing import Process,Queue #导入Process和Queue
- import os,time,random
-
- def write(q): #定义函数,接收Queue的实例参数
- for v in range(10):
- print('Put %s to Queue'%v)
- q.put(v) #添加数据到Queue
- time.sleep(1)
- def read(q): #定义函数,接收Queue的实例参数
- while True:
- if not q.empty(): #判断,如果Queue不为空则进行数据取出。
- v = q.get(True) #取出Queue中的数据,并返回保存。
- print('Get %s from Queue'%v)
- time.sleep(1)
- else: #如果Queue内没有数据则退出。
- break
-
- if __name__ == '__main__':
- q = Queue() #实例化Queue括号内可选填,输入数字表示有多少个存储单位。以堵塞方式运行。必须等里边有空余位置时,才能放入数据,或者只能等里边有数据时才能取出数据,取不出数据,或者存不进数据的时候则会一直在等待状态。
- pw = Process(target=write,args=(q,)) #实例化子进程pw,用来执行write函数,注意这里的函数不带括号,只是传递引用,参数需要使用args参数以元组的方式进行接收。
- pr = Process(target=read,args=(q,)) #实例化子进程pr,用来执行read函数,注意这里的函数不带括号,只是传递引用,参数需要使用args参数以元组的方式进行接收。
- pw.start() #开始执行pw。
- pr.start() #开始执行pr。
- pw.join() #等待pw结束
- pr.join() #等待pr结束
- print('Over') #主进程结束
Pool的Queue用法
- from multiprocessing import Manager,Pool #这里注意导入的是Manager和Pool
- import os,time,random
-
- def write(q):
- for v in range(10):
- print('Put %s to Queue'%v)
- q.put(v)
- time.sleep(1)
- def read(q):
- while True:
- if not q.empty():
- v = q.get(True)
- print('Get %s from Queue'%v)
- time.sleep(1)
- else:
- break
-
- if __name__ == '__main__':
- q = Manager().Queue() #这里实例化的时候是使用Manager的Queue
- p = Pool()
- p.apply_async(write,(q,)) #将任务加入Pool的进程池,注意这里的参数于Process不同。
- p.apply_async(read,(q,)) #将任务加入Pool的进程池,注意这里的参数于Process不同。
- p.close() #关闭进程池,不再接收进程。
- p.join() #子进程完毕,运行以下的主进程。
- print('Over')
线程
- from threading import Thread #导入Thread线程类。
- import time
-
- num = 0 #定义全局变量
-
- def work(): #定义函数内容
- global num
- for i in range(1000000):
- num += 1
- print('work的num是%d'%num)
-
- def works(): #定义函数
- global num
- for i in range(1000000):
- num += 1
- print('works的num是%d'%num)
-
- t = Thread(target=work) #创建第一个线程内置的self.name属性为Thread-1,并指向work
- tt = Thread(target=works) #创建第二个线程内置的self.name属性为Thread-2,并指向works
- t.start() #开始执行
- tt.start() #开始执行
- time.sleep(1) #主线程休息一秒
- print('最后的num值是%d'%num) #输出最后的结果。
注意:线程中的变量数据是可以共享的,进程与线程的区别在于,父子进程是两个单独的个体,子进程类似于直接拷贝的一份父进程的代码独立运行,相当于两个文件。线程则是再主进程的内部分裂运行。举例子来说一个工厂需要做100万件衣服,但是工期太紧,自己做太慢,老板现在有两个选择,一个是雇佣另外一个同样规模的工厂一起来做,两个工厂一起做——进程,另外一个选择就是在自己的工厂内大批量的招募工人用来赶工——线程。总得来说线程的消耗成本会比进程低很多。
互斥锁
- from threading import Thread,Lock #导入互斥锁Lock
-
- num = 0
-
- def work():
- global num
- l.acquire() #这里表示调用互斥锁上锁方法,如果work函数先运行l.acquire的话,那么后边的程序就不能再修改和使用变量num。直到将其解锁后才能使用。
- for i in range(1000000):
- num += 1
- print('work的num是%d'%num)
- l.release() #这里表示调用互斥锁解锁方法。
-
- def works():
- global num
- l.acquire() #这里表示调用互斥锁上锁方法。
- for i in range(1000000):
- num += 1
- print('works的num是%d'%num)
- l.release() #这里表示调用互斥锁解锁方法。
-
-
- l = Lock() #实例化互斥锁,互斥锁是为了保护子线程不争抢数据而使用的一个类。
- t = Thread(target=work)
- tt = Thread(target=works)
- t.start()
- tt.start()
- print('最后的num值是%d'%num) #输出最后的结果,如果实验过的可能会发现这个结果并不是2000000,为什么呢?
- 这里需要明白,主线程和子线程是同时进行的,因为创建子进程在前,最后输出再后,所以当最后线程输出的时候,子线程还在运行,也就是说当子线程的加法运算加到95222的时候你的
- 主进程刚好运行到最后的输出语句,所以就把95222拿过来进行输出。你也可以试试将最后的输出语句放到实例化的前边,看看结果是不是0,因为子线程还没有开始工作,所以并没有进行加法运算。
注意:因为线程的数据是共享数据,不用Queue就能实现,所以也会存在一些弊端,因为线程是在进程间独立运行的,所以共享数据会有一定的延时性和不准确性,举例家里有10个馒头,2个孩子,第一个孩子拿走一个会记得还剩下9个,第二个孩子去拿的时候会记得还剩下8个,但是当第一个孩子再去拿的时候会发现只剩下7个了,但是之前明明还剩下9个,这样就会出现问题。互斥锁的作用就是再厨房装上一把锁,当第一个孩子饿的时候就进去吃馒头,将门反锁,这样第二个孩子就吃不到再门口等着,当第一个吃饱的时候第二个再进去,也把门锁上。这样一个一个的来避免冲突。
同步、异步
- import threading
- import time
-
- class MyThread(threading.Thread):
- def run(self):
- global num
- time.sleep(1)
-
- if mutex.acquire(1):
- num = num+1
- msg = self.name+' set num to '+str(num)
- print msg
- mutex.release()
- num = 0
- mutex = threading.Lock()
- def test():
- for i in range(5):
- t = MyThread()
- t.start()
- if __name__ == '__main__':
- test()
- Thread-3 set num to 1
- Thread-4 set num to 2
- Thread-5 set num to 3
- Thread-2 set num to 4
- Thread-1 set num to 5
注意:这里就是一个简单的同步,使用互斥锁来实现,因为每个线程在创建运行的时候都是各自做各自的,如果没有互斥锁来约束步调,那么结果是1,2,3,4,5的概率是未知数,但是加上了互斥锁以后,就会对线程的运行顺序进行排队,达到预期的结果。而异步则是各个线程独立运行,谁先做完就休息,不用等待。
threadlocal
- import threading #导入模块
-
- l = threading.local() #实例化local,注意这个local和Lock互斥锁的名称不同。
-
- def work(name): #创建函数
- l.name = name #将参数name传递给local实例对象的name属性。注意:这里的l.name是创建的对象属性。
- works() #调用work函数
-
- def works(): #创建函数
- name = l.name
- print('hello,%s,线程的name是%s'%(name,threading.current_thread().name))
-
- t1 = threading.Thread(target=work,args=('小李',)) #实例化线程对象,并调用work,参数name是小李。
- t2 = threading.Thread(target=work,args=('小王',))#实例化线程对象,并调用work,参数name是小王。
- t1.start()
- t2.start()
- t1.join()
- t2.join()
注意:threadlocal是比较方便的共享数据处理办法,他的内部类似于一个字典,Thread.name作为Key,对应的属性作为Value,当Thread-1储存和取值的时候,对应的是它的值,从而避免多个线程对共有数据造成错误和丢失。
网络编程
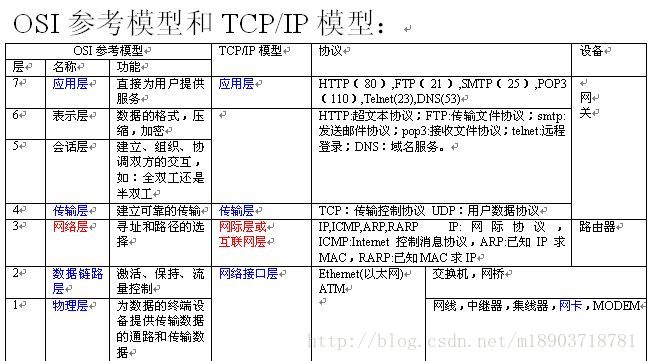
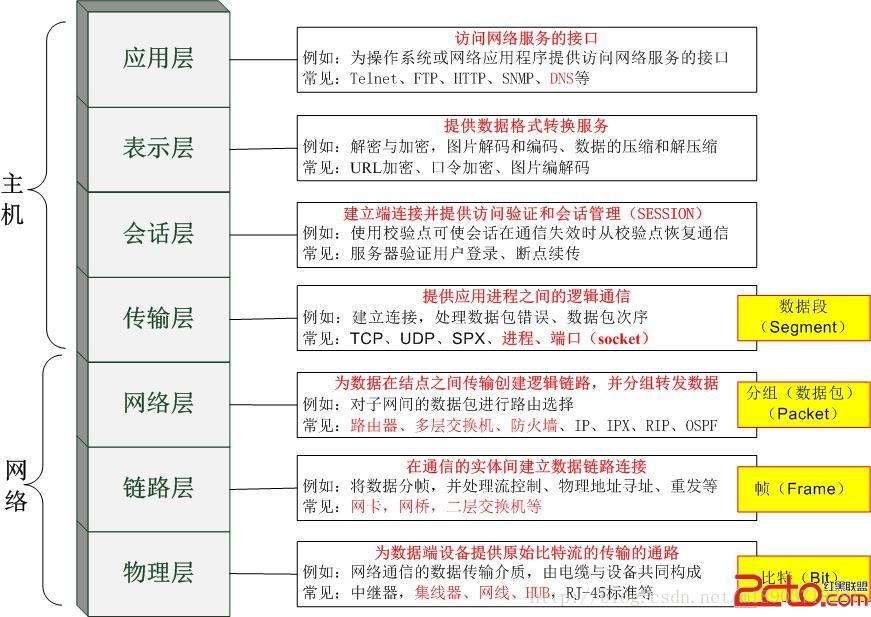
Tcp/Ip协议
早期的计算机网络,都是由各厂商自己规定一套协议,IBM、Apple和Microsoft都有各自的网络协议,互不兼容为了把全世界的所有不同类型的计算机都连接起来,就必须规定一套全球通用的协议,为了实现互联网这个目标,互联网协议簇(Internet ProtocolSuite)就是通用协议标准。
因为互联网协议包含了上百种协议标准,但是最重要的两个协议是TCP和IP协议,所以,大家把互联网的协议简称TCP/IP协议

端口
知名端口
知名端口是众所周知的端口号,范围从0到1023
例如:
80端口分配给HTTP服务
21端口分配给FTP服务
一般情况下,如果一个程序需要使用知名端口的需要有root权限
动态端口
动态端口的范围是从1024到65535
之所以称为动态端口,是因为它一般不固定分配某种服务,而是动态分配。
动态分配是指当一个系统进程或应用程序进程需要网络通信时,它向主机申请一个端口,主机从可用的端口号中分配一个供它使用。当这个进程关闭时,同时也就释放了所占用的端口号。
小结
端口有什么作用?在两台计算机通信时,只发 IP 地址是不够的,因为同一台计算机上跑着多个网络程序。一个 IP 包来了之后,到底是交给浏览器还是 QQ,就需要端口号来区分。每个网络程序都向操作系统申请唯一的端口号,这样,两个进程在两台计算机之间建立网络连接就需要各自的 IP 地址和各自的端口号。
Socket-套接字
udp-套接字
- from socket import * #导入socket
- from threading import * #导入threading
-
- udp = socket(AF_INET,SOCK_DGRAM) #创建套接字,基于UDP传输协议。相对于TCP比较快。AF_INET表示使用IPV4进行链接。如果使用IPV6则把参数修改为AF_INET6
-
- udp.bind(('',8080)) #绑定任意ip,和8080端口,如果不进行绑定,那么每创建一个套解字就会使用一个动态端口。
-
- sendip = input('输入接收方的IP:')
- sendport = int(input('输入接收方的端口:'))
-
- def sendinfo(): #定义发送函数
- while True:
- senddata = input('请输入发送的内容:')
- udp.sendto(senddata.encode('utf-8'),(sendip,sendport)) #调用套解字的sendto方法,第一个参数为编码后的数据,第二个参数为接收方的IP和端口。
-
- def receiveinfo(): #定义接收函数
- while True:
- recvdata = udp.recvfrom(1024) #调用recvfrom方法进行数据接收,并且以元祖的方式返回,第一个参数是数据,第二个参数为IP和端口。与发送格式一致。
- print(recvdata[1],recvdata[0].decode('utf-8')) #将接收到的数据进行打印,并将数据进行解码。
-
- def main():
- ts = Thread(target=sendinfo) #创建一个线程运行发送函数。
- tr = Thread(target=receiveinfo) #创建一个线程运行接收函数。
-
- ts.start()
- tr.start()
-
- ts.join()
- tr.join()
-
- if __name__ == '__main__':
- main()
注意:socket套接字是用来再网络间通信的模块。
tcp-套接字
tcp-套接字 服务器
- from socket import * #导入套接字
-
- tcp = socket(AF_INET,SOCK_STREAM) #创建tcp套接字
-
- tcp.bind(('',8800)) #绑定ip,和端口,客户端需要连接这个ip和端口进行服务器连接。
-
- tcp.listen(5) #tcp监听,参数为可连接的数量。
-
- newsocket,addr = tcp.accept() #接收客户端的连接,并返回一个新的socket和客户端地址。阻塞程序等待客户端的接入。
-
- while 1: # 表示while True,只要条件类型不是空类型、0和None的False类型则就表示while True。
- socketDate = newsocket.recv(1024) #接收客户端的数据。
- if len(socketDate)>0: #如果接收数据的长度大于0,则打印出接收到的信息,如果接收的数据长度为0,则表示客户端使用close方法关闭了套接字。
- print(socketDate.decode('utf-8')) #将接收数据解码为utf-8输出
- else: #如果客户端关闭了套接字,则跳出循环
- break
-
- sendDate = input('请输入要回复的内容:') #输入需要回复的数据
- newsocket.send(sendDate.encode('utf-8')) #使用send将数据编码为utf-8回复
-
- newsocket.close() #关闭与客户端通信的套接字。
- tcp.close() #关闭服务器的套接字,关闭后将不会再接收客户端的连接。
注意:在linux系统中listen的参数可以忽略,因为系统会自动按照内核进行最大连接数的操作,即使填写参数也没有效果,但是windons和mac中则会有效。以上是单线程案例。
tcp-套接字 客户端
- from socket import * #导入模块
-
- csocket = socket(AF_INET,SOCK_STREAM) #创建套接字
-
- serverIp = input('请输入服务器的IP:')
-
- csocket.connect((serverIp,8800)) #连接服务器
-
- while 1:
- sendData = input('请输入需要发送打内容:') #输入发送的内容
- csocket.send(sendData.encode('utf-8')) #编码发送
-
- recvData = csocket.recv(1024)
- print('recvData:%s'%recvData.decode('utf-8')) #解码输出
-
- csocket.close() #关闭套接字
注意:正常的编程工作中,会优先使用tcp套接字。
交换机、路由器
交换机:
转发过滤:当⼀个数据帧的⽬的地址在MAC地址表中有映射时,它被转发到连接⽬的节点的端⼝⽽不是所有端⼝(如该数据帧为⼴播帧则转发⾄所有端⼝)
学习功能:以太⽹交换机了解每⼀端⼝相连设备的MAC地址,并将地址同相应的端⼝映射起来存放在交换机缓存中的MAC地址表中
交换机能够完成多个电脑的链接每个数据包的发送都是以⼴播的形式进⾏的,容易堵塞⽹络如果PC不知⽬标IP所对应的的MAC,那么可以看出,pc会先发送arp⼴播,得到对⽅的MAC然后,在进⾏数据的传送当switch第⼀次收到arp⼴播数据,会把arp⼴播数据包转发给所有端⼝(除来源端⼝);如果以后还有pc询问此IP的MAC,那么只是向⽬标的端⼝进⾏转发数据。
路由器
路由器(Router)⼜称⽹关设备(Gateway)是⽤于连接多个逻辑上分开的⽹络所谓逻辑⽹络是代表⼀个单独的⽹络或者⼀个⼦⽹。当数据从⼀个⼦⽹传输到另⼀个⼦⽹时,可通过路由器的路由功能来完成具有判断⽹络地址和选择IP路径的功能
不在同⼀⽹段的pc,需要设置默认⽹关才能把数据传送过去 通常情况下,都会把路由器默认⽹关当路由器收到⼀个其它⽹段的数据包时,会根据“路由表”来决定,把此数据包发送到哪个端⼝;路由表的设定有静态和动态⽅法每经过⼀次路由器,那么TTL值就会减1
网段、ARP、DNS、MAC地址
网段
网段(network segment)一般指一个计算机网络中使用同一物理层设备(传输介质,中继器,集线器等)能够直接通讯的那一部分。例如,从192.168.0.1到192.168.255.255这之间就是一个网段。
A类IP段 0.0.0.0 到127.255.255.255 A类的默认子网掩码 255.0.0.0 一个子网最多可以容纳1677万多台电脑
B类IP段 128.0.0.0 到191.255.255.255 B类的默认子网掩码 255.255.0.0 一个子网最多可以容纳6万台电脑
C类IP段 192.0.0.0 到223.255.255.255 C类的默认子网掩码 255.255.255.0 一个子网最多可以容纳254台电脑
局域网保留地址:
A类:10.0.0.0/8 10.0.0.0-10.255.255.255
B类:172.16.0.0/12 172.16.0.0-172.31.255.255
C类:192.168.0.0/16 192.168.0.0~192.168.255.255
注意:C类地址必须前三位一致的才算是一个局域网,可以不使用路由器进行通信,例如192.168.1.1-192.168.1.254 是一个局域网,B类地址则必须前两位一致才算是一个局域网。以此类推。即子网掩码有几位相同的则需要有几位一致的。
ARP
地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址的一个TCP/IP协议。主机发送信息时将包含目标IP地址的ARP请求广播到网络上的所有主机,并接收返回消息,以此确定目标的物理地址;收到返回消息后将该IP地址和物理地址存入本机ARP缓存中并保留一定时间,下次请求时直接查询ARP缓存以节约资源。地址解析协议是建立在网络中各个主机互相信任的基础上的,网络上的主机可以自主发送ARP应答消息,其他主机收到应答报文时不会检测该报文的真实性就会将其记入本机ARP缓存;由此攻击者就可以向某一主机发送伪ARP应答报文,使其发送的信息无法到达预期的主机或到达错误的主机,这就构成了一个ARP欺骗。ARP命令可用于查询本机ARP缓存中IP地址和MAC地址的对应关系、添加或删除静态对应关系等。相关协议有RARP、代理ARP。NDP用于在IPv6中代替地址解析协议。
工作过程
主机A的IP地址为192.168.1.1,MAC地址为0A-11-22-33-44-01;
主机B的IP地址为192.168.1.2,MAC地址为0A-11-22-33-44-02;
当主机A要与主机B通信时,地址解析协议可以将主机B的IP地址(192.168.1.2)解析成主机B的MAC地址,以下为工作流程:
第1步:根据主机A上的路由表内容,IP确定用于访问主机B的转发IP地址是192.168.1.2。然后A主机在自己的本地ARP缓存中检查主机B的匹配MAC地址。
第2步:如果主机A在ARP缓存中没有找到映射,它将询问192.168.1.2的硬件地址,从而将ARP请求帧广播到本地网络上的所有主机。源主机A的IP地址和MAC地址都包括在ARP请求中。本地网络上的每台主机都接收到ARP请求并且检查是否与自己的IP地址匹配。如果主机发现请求的IP地址与自己的IP地址不匹配,它将丢弃ARP请求。
第3步:主机B确定ARP请求中的IP地址与自己的IP地址匹配,则将主机A的IP地址和MAC地址映射添加到本地ARP缓存中。
第4步:主机B将包含其MAC地址的ARP回复消息直接发送回主机A。
第5步:当主机A收到从主机B发来的ARP回复消息时,会用主机B的IP和MAC地址映射更新ARP缓存。本机缓存是有生存期的,生存期结束后,将再次重复上面的过程。主机B的MAC地址一旦确定,主机A就能向主机B发送IP通信了。
DNS
DNS服务器是(Domain Name System或者Domain Name Service)域名系统或者域名服务,域名系统为Internet上的主机分配域名地址和IP地址。用户使用域名地址,该系统就会自动把域名地址转为IP地址。域名服务是运行域名系统的Internet工具。执行域名服务的服务器称之为DNS服务器,通过DNS服务器来应答域名服务的查询。
MAC地址
MAC(Media Access Control或者Medium Access Control)地址,意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在OSI模型中,第三层网络层负责 IP地址,第二层数据链路层则负责 MAC地址。因此一个主机会有一个MAC地址,而每个网络位置会有一个专属于它的IP地址。
MAC(Medium/Media Access Control)地址,用来表示互联网上每一个站点的标识符,采用十六进制数表示,共六个字节(48位)。其中,前三个字节是由IEEE的注册管理机构RA负责给不同厂家分配的代码(高位24位),也称为"编制上唯一的标识符"(Organizationally Unique Identifier),后三个字节(低位24位)由各厂家自行指派给生产的适配器接口,称为扩展标识符(唯一性)。一个地址块可以生成2个不同的地址。MAC地址实际上就是适配器地址或适配器标识符EUI-48[1]
注意:在真正的信息传输中,发送者的ip和接收方的ip和数据包内容是不变的,期间会通过各个路由器的mac地址进行传输。简单可以理解为,在网上买了一件衣服,包裹的发送方是商家(可以理解为发送者的IP),包裹的接收方是自己(理解为接收者的IP),期间的各个快递中转站就可以理解为各个路由器的mac地址,最后由数据将会传递到自己手中。
TCP3次握手、4次挥手和10种状态
TCP3次握手
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接.
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认; SYN:同步序列编号(Synchronize Sequence Numbers)
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手.
完成三次握手,客户端与服务器开始传送数据

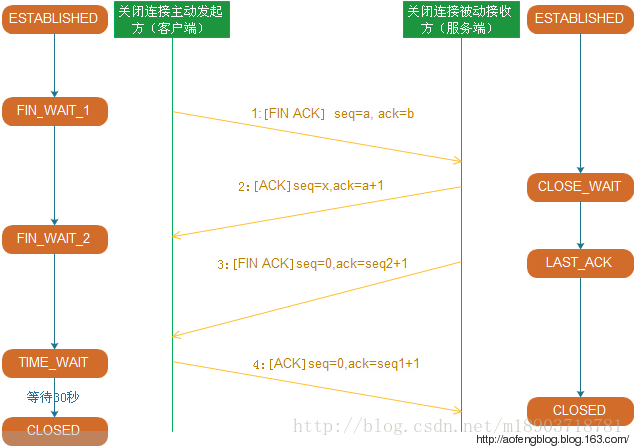
关闭连接(四次挥手)
第一次挥手:客户端发送FIN+ACK包(序号为seq=a,确认序号ack=b)给服务端,用来关闭客户端到服务端的数据传送,客户端进入FIN_WAIT_1状态。
第二次挥手:服务端收到FIN+ACK包后,发送ACK包给客户端进行确认,服务端进入CLOSE_WAIT状态。客户端收到ACK包后进入FIN_WAIT_2状态。到这里,关闭一个单向通道。
第三次挥手:服务端发送FIN+ACK包给客户端,服务端进入LAST_ACK状态。
第四次挥手:客户端收到FIN+ACK包后,发送ACK包给服务端进行确认,客户端进入TIME_WAIT状态,在等待30秒(可修改)后进入CLOSED状态。服务端收到ACK包后进入CLOSED状态,关闭另一个单向通道。
TCP十种状态
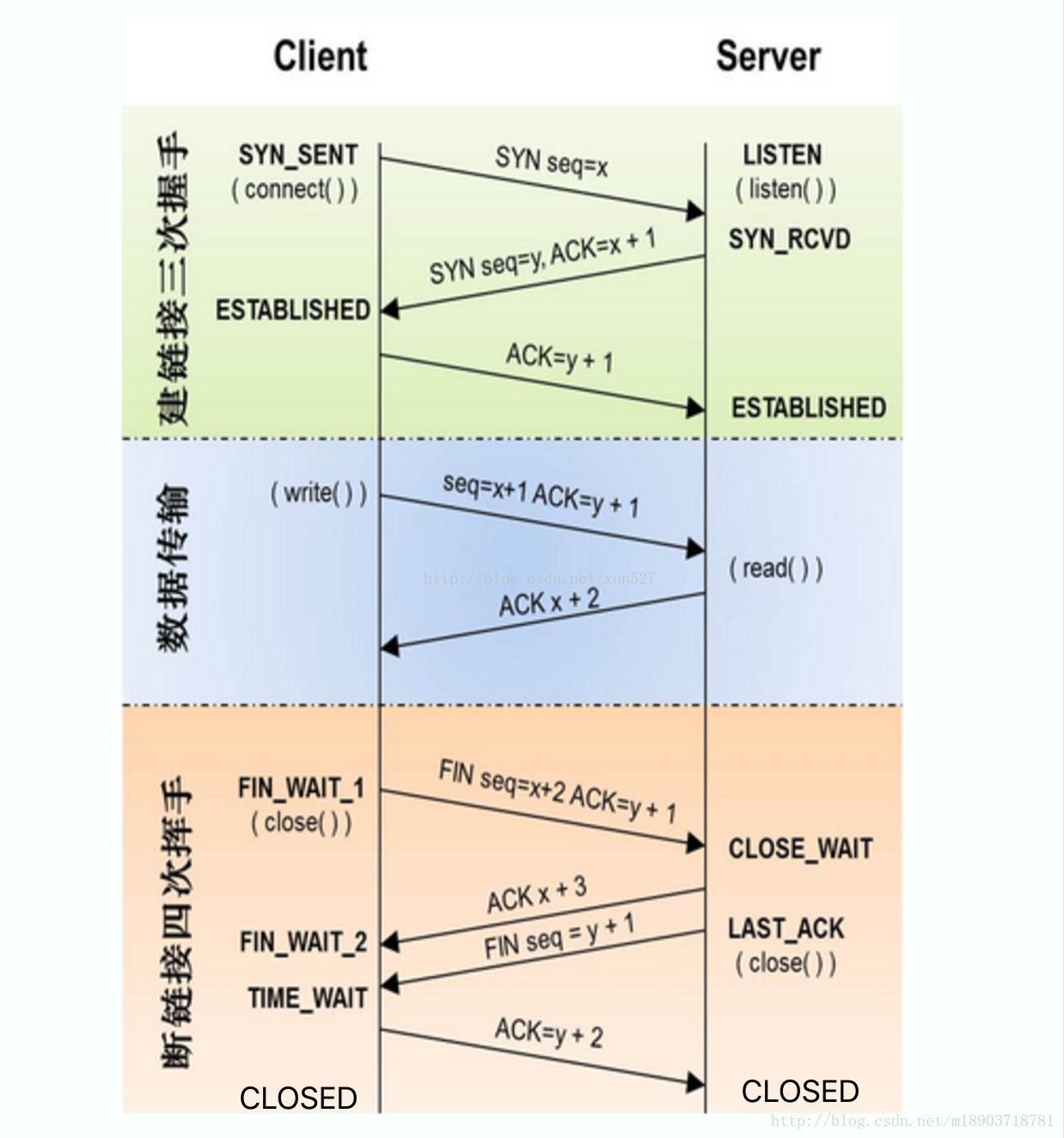
CLOSED:表示关闭状态(初始状态)。
LISTEN:该状态表示服务器端的某个SOCKET处于监听状态,可以接受连接。
SYN_SENT:这个状态与SYN_RCVD遥相呼应,当客户端SOCKET执行CONNECT连接时,它首先发送SYN报文,随即进入到了SYN_SENT状态,并等待服务端的发送三次握手中的第2个报文。SYN_SENT状态表示客户端已发送SYN报文。
SYN_RCVD: 该状态表示接收到SYN报文,在正常情况下,这个状态是服务器端的SOCKET在建立TCP连接时的三次握手会话过程中的一个中间状态,很短暂。此种状态时,当收到客户端的ACK报文后,会进入到ESTABLISHED状态。
ESTABLISHED:表示连接已经建立。
FIN_WAIT_1: FIN_WAIT_1和FIN_WAIT_2状态的真正含义都是表示等待对方的FIN报文。区别是: FIN_WAIT_1状态是当socket在ESTABLISHED状态时,想主动关闭连接,向对方发送了FIN报文,此时该socket进入到FIN_WAIT_1状态。 FIN_WAIT_2状态是当对方回应ACK后,该socket进入到FIN_WAIT_2状态,正常情况下,对方应马上回应ACK报文,所以FIN_WAIT_1状态一般较难见到,而FIN_WAIT_2状态可用netstat看到。
FIN_WAIT_2:主动关闭链接的一方,发出FIN收到ACK以后进入该状态。称之为半连接或半关闭状态。该状态下的socket只能接收数据,不能发。
TIME_WAIT: 表示收到了对方的FIN报文,并发送出了ACK报文,等2MSL后即可回到CLOSED可用状态。如果FIN_WAIT_1状态下,收到对方同时带 FIN标志和ACK标志的报文时,可以直接进入到TIME_WAIT状态,而无须经过FIN_WAIT_2状态。
CLOSE_WAIT: 此种状态表示在等待关闭。当对方关闭一个SOCKET后发送FIN报文给自己,系统会回应一个ACK报文给对方,此时则进入到CLOSE_WAIT状态。接下来呢,察看是否还有数据发送给对方,如果没有可以 close这个SOCKET,发送FIN报文给对方,即关闭连接。所以在CLOSE_WAIT状态下,需要关闭连接。
LAST_ACK: 该状态是被动关闭一方在发送FIN报文后,最后等待对方的ACK报文。当收到ACK报文后,即可以进入到CLOSED可用状态。
tcp第十一种状态:
CLOSING:这种状态较特殊,属于一种较罕见的状态。正常情况下,当你发送FIN报文后,按理来说是应该先收到(或同时收到)对方的ACK报文,再收到对方的FIN报文。但是CLOSING状态表示你发送FIN报文后,并没有收到对方的ACK报文,反而却也收到了对方的FIN报文。什么情况下会出现此种情况呢?如果双方几乎在同时close一个SOCKET的话,那么就出现了双方同时发送FIN报文的情况,也即会出现CLOSING状态,表示双方都正在关闭SOCKET连接。
TCP的2MSL
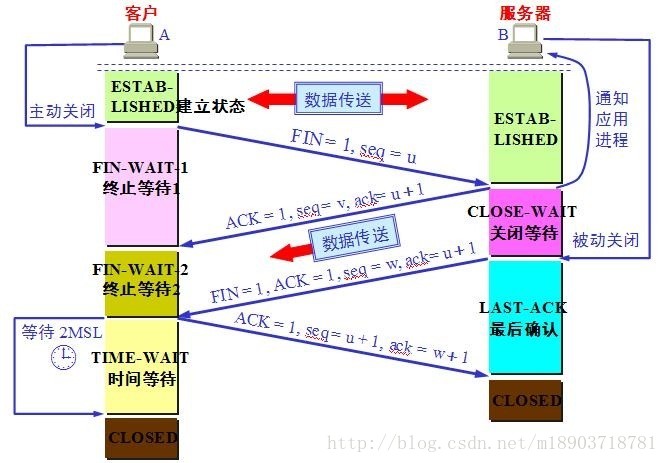
2MSL即两倍的MSL,TCP的TIME_WAIT状态也称为2MSL等待状态,
当TCP的⼀端发起主动关闭,在发出最后⼀个ACK包后,即第3次握 ⼿完成后发送了第四次握⼿的ACK包后就进⼊了TIME_WAIT状态,必须在此状态上停留两倍的MSL时间,等待2MSL时间主要⽬的是怕最后⼀个 ACK包对⽅没收到,那么对⽅在超时后将重发第三次握⼿的FIN包,主动关闭端接到重发的FIN包后可以再发⼀个ACK应答包。
在TIME_WAIT状态 时两端的端⼝不能使⽤,要等到2MSL时间结束才可继续使⽤。当连接处于2MSL等待阶段时任何迟到的报⽂段都将被丢弃。不过在实际应⽤中可以通过设置 SO_REUSEADDR选项达到不必等待2MSL时间结束再使⽤此端⼝。
TCP⻓连接和短连接
短链接

⻓连接

常见的网络攻击
DDOS攻击

注意:简单的理解DDOS攻击就是使用TCP的三次握手协议,编写代码使用多线程或者多进程方式恶意的不发送第三次握手导致服务器listen队列爆满,使正常的客户无法正常连接。
DNS攻击
DNS欺骗就是攻击者冒充域名服务器的一种欺骗行为。 原理:如果可以冒充域名服务器,然后把查询的IP地址设为攻击者的IP地址,这样的话,用户上网就只能看到攻击者的主页,而不是用户想要取得的网站的主页了,这就是DNS欺骗的基本原理。DNS欺骗其实并不是真的"黑掉"了对方的网站,而是冒名顶替、招摇撞骗罢了。
ARP攻击
ARP攻击就是通过伪造IP地址和MAC地址实现ARP欺骗,能够在网络中产生大量的ARP通信量使网络阻塞,攻击者只要持续不断的发出伪造的ARP响应包就能更改目标主机ARP缓存中的IP-MAC条目,造成网络中断或中间人攻击。
ARP攻击主要是存在于局域网网络中,局域网中若有一台计算机感染ARP木马,则感染该ARP木马的系统将会试图通过“ARP欺骗”手段截获所在网络内其它计算机的通信信息,并因此造成网内其它计算机的通信故障。
攻击者向电脑A发送一个伪造的ARP响应,告诉电脑A:电脑B的IP地址192.168.0.2对应的MAC地址是00-aa-00-62-c6-03,电脑A信以为真,将这个对应关系写入自己的ARP缓存表中,以后发送数据时,将本应该发往电脑B的数据发送给了攻击者。同样的,攻击者向电脑B也发送一个伪造的ARP响应,告诉电脑B:电脑A的IP地址192.168.0.1对应的MAC地址是00-aa-00-62-c6-03,电脑B也会将数据发送给攻击者。
至此攻击者就控制了电脑A和电脑B之间的流量,他可以选择被动地监测流量,获取密码和其他涉密信息,也可以伪造数据,改变电脑A和电脑B之间的通信内容。
客户端:
1.Python面向对象
创建类
使用class语句来创建一个新类,class之后为类的名称并以冒号结尾,如下实例:
class ClassName: '类的帮助信息' #类文档字符串 class_suite #类体

实例:
class Employee:
'所有员工的基类'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
"创建 Employee 类的第一个对象"
emp1 = Employee("Zara", 2000)
"创建 Employee 类的第二个对象"
emp2 = Employee("Manni", 5000)
emp1.displayEmployee()
emp2.displayEmployee()
print "Total Employee %d" % Employee.empCount
输出结果如下:
Name : Zara ,Salary: 2000 Name : Manni ,Salary: 5000 Total Employee 2
类的私有属性:
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的私有方法: __private_method:两个下划线开头,声明该方法为私有方法,不能在类地外部调用。在类的内部调用 self.__private_methods
class JustCounter:
__secretCount = 0 # 私有变量
publicCount = 0 # 公开变量
def count(self):
self.__secretCount += 1
self.publicCount += 1
print self.__secretCount
counter = JustCounter()
counter.count()
counter.count()
print counter.publicCount
print counter.__secretCount # 报错,实例不能访问私有变量
输出结果如下:
1
2
2
Traceback (most recent call last):
File "test.py", line 17, in <module>
print counter.__secretCount # 报错,实例不能访问私有变量
AttributeError: JustCounter instance has no attribute '__secretCount'
单下划线,双下划线,头尾双下划线说明:
-
__foo__: 定义的是特列方法,类似 __init__() 之类的。
-
_foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于 from module import *
-
__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。
2.正则表达式
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
import re line = "Cats are smarter than dogs"; matchObj = re.match( r'dogs', line, re.M|re.I) if matchObj: print "match --> matchObj.group() : ", matchObj.group() else: print "No match!!" matchObj = re.search( r'dogs', line, re.M|re.I) if matchObj: print "search --> matchObj.group() : ", matchObj.group() else: print "No match!!"
运行结果如下:
No match!! search --> matchObj.group() : dogs 匹配和检索:
Python 的 re 模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
实例
import re phone = "2004-959-559 # 这是一个国外电话号码" # 删除字符串中的 Python注释 num = re.sub(r'#.*$', "", phone) print "电话号码是: ", num # 删除非数字(-)的字符串 num = re.sub(r'\D', "", phone) print "电话号码是 : ", num
以上实例执行结果如下:
电话号码是: 2004-959-559 电话号码是 : 2004959559 下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变
| 模 式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | |
| re{ n,} | 精确匹配n个前面表达式。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | G匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。 但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字及下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
python高级之面向对象高级
本节内容
- 成员修饰符
- 特殊成员
- 类与对象
- 异常处理
- 反射/自省
- 单例模式
1.成员修饰符
python的类中只有私有成员和公有成员两种,不像c++中的类有公有成员(public),私有成员(private)和保护成员(protected).并且python中没有关键字去修饰成员,默认python中所有的成员都是公有成员,但是私有成员是以两个下划线开头的名字标示私有成员,私有成员不允许直接访问,只能通过内部方法去访问,私有成员也不允许被继承。
- class a: # 说明父类的私有成员无法在子类中继承
- def __init__(self):
- self.ge=123
- self.__gene=456
-
- class b(a):
- def __init__(self,name):
- self.name=name
- self.__age=18
- super(b,self).__init__() # 这一行会报错
- def show(self):
- print(self.name)
- print(self.__age)
- print(self.ge)
- print(self.__gene) # 这一行也会报错
- obj=b("xiaoming")
- print(obj.name)
- print(obj.ge)
- # print(obj.__gene) # 这个也会报错
- obj.show()
上面就是类里面的私有成员了。
2.特殊成员
1.__init__
__init__方法可以简单的理解为类的构造方法(实际并不是构造方法,只是在类生成对象之后就会被执行),之前已经在上一篇博客中说明过了。
2.__del__
__del__方法是类中的析构方法,当对象消亡的时候(被解释器的垃圾回收的时候会执行这个方法)这个方法默认是不需要写的,不写的时候,默认是不做任何操作的。因为你不知道对象是在什么时候被垃圾回收掉,所以,除非你确实要在这里面做某些操作,不然不要自定义这个方法。
3.__call__
__call__方法在类的对象被执行的时候(obj()或者 类()())会执行。
4.__int__
__int__方法,在对象被int()包裹的时候会被执行,例如int(obj)如果obj对象没有、__int__方法,那么就会报错。在这个方法中返回的值被传递到int类型中进行转换。
5.__str__
__str__方法和int方法一样,当对象被str(obj)包裹的时候,如果对象中没有这个方法将会报错,如果有这个方法,str()将接收这个方法返回的值在转换成字符串。
6.__add__
__add__方法在两个对象相加的时候,调用第一个对象的__add__方法,将第二个对象传递进来,至于怎么处理以及返回值,那是程序员自定义的,就如下面的例子:
- class abc:
- def __init__(self,age):
- self.age=age
- def __add__(self,obj):
- return self.age+obj.age
- a1=abc(18)
- a2=abc(20)
- print(a1+a2)
- #执行结果:38
7.__dict__
__dict__方法在类里面有,在对象里面也有,这个方法是以字典的形式列出类或对象中的所有成员。就像下面的例子:
- class abc:
- def __init__(self,age):
- self.age=age
- def __add__(self,obj):
- return self.age+obj.age
- a1=abc(18)
- print(abc.__dict__)
- print(a1.__dict__)
- #执行结果:
- {'__add__': <function abc.__add__ at 0x0000020666C9E2F0>, '__module__': '__main__', '__weakref__': <attribute '__weakref__' of 'abc' objects>, '__init__': <function abc.__init__ at 0x0000020666C9E268>, '__doc__': None, '__dict__': <attribute '__dict__' of 'abc' objects>}
- {'age': 18}
8.__getitem__ __setitem__ __delitem__
__getitem__方法匹配 对象[索引] 这种方式,__setitem__匹配 对象[索引]=value 这种方式,__delitem__匹配 del 对象[索引] 这种方式,例子如下:
- class Foo:
- def __init__(self,name,age):
- self.name=name
- self.age=age
- def __getitem__(self, item): # 匹配:对象[item]这种形式
- return item+10
- def __setitem__(self, key, value): # 匹配:对象[key]=value这种形式
- print(key,value)
- def __delitem__(self, key): # 匹配:del 对象[key]这种形式
- print(key)
-
- li=Foo("alex",18)
- print(li[10])
- li[10]=100
- del li[10]
- 执行结果:
- 20
- 10 100
- 10
9.__getslice__ __setslice__ __delslice__
这三种方式在python2.7中还存在,用来对对象进行切片的,但是在python3之后,将这些特殊方法给去掉了,统一使用上面的方式对对象进行切片,因此在使用__getitem__ __setitem__ 这两个方法之前要先判断传递进参数的类型是不是slice对象。例子如下:
- class Foo:
- def __init__(self,name,age):
- self.name=name
- self.age=age
- self.li=[1,2,3,4,5,6,7]
- def __getitem__(self, item): # 匹配:对象[item]这种形式
- if isinstance(item,slice): # 如果是slice对象,返回切片后的结果
- return self.li[item] # 返回切片结果
- elif isinstance(item,int): # 如果是整形,说明是索引
- return item+10
- def __setitem__(self, key, value): # 匹配:对象[key]=value这种形式
- print(key,value)
- def __delitem__(self, key): # 匹配:del 对象[key]这种形式
- print(key)
- def __getslice__(self,index1,index2):
- print(index1,index2)
-
- li=Foo("alex",18)
- print(li[3:5])
- #执行结果:
- [4, 5]
10. __iter__
类的对象如果想要变成一个可迭代对象,那么对象中必须要有__iter__方法,并且这个方法返回的是一个迭代器。
for 循环的对象如果是一个可迭代的对象,那么会先执行对象中的__iter__方法,获取到迭代器,然后再执行迭代器中的__next__方法获取数据。如果for循环的是一个迭代器,那么直接执行迭代器中的__next__方法。
- class Foo:
- def __init__(self,name,age):
- self.name=name
- self.age=age
- def __iter__(self):
- return iter([1,2,3,4,5]) # 返回的是一个迭代器
- li=Foo("alex",18)
-
- # 1.如果类中有__iter__方法,他的对象就是可迭代对象
- # 2.对象.__iter()的返回值是一个迭代器
- # 3.for循环的如果是迭代器,直接执行.next方法
- # 4.for循环的如果是可迭代对象,先执行对象.__iter(),获取迭代器再执行next
-
- for i in li:
- print(i)
- #执行结果:
- 1
- 2
- 3
- 4
- 5
11.isinstance和issubclass
之前讲过isinstance可以判断一个变量是否是某一种数据类型,其实,isinstance不只可以判断数据类型,也可以判断对象是否是这个类的对象或者是这个类的子类的对象,代码如下:
- class Foo:
- def __init__(self,name,age):
- self.name=name
- self.age=age
- class Son(Foo):
- pass
- obj=Son("xiaoming",18)
- print(isinstance(obj,Foo))
- 执行结果:True
issubclass用来判断一个类是否是某个类的子类,返回的是一个bool类型数据,代码如下:
- class Foo:
- def __init__(self,name,age):
- self.name=name
- self.age=age
- class Son(Foo):
- pass
- obj=Son("xiaoming",18)
- print(issubclass(Son,Foo))
- 执行结果:True
3.类与对象
__new__和__metaclass__
在python中,一切皆对象,我们定义的类其实。。。也是一个对象,那么,类本身是谁的对象呢?在python2.2之前(或者叫经典类中),所有的类,都是class的对象,但是在新式类中,为了将类型(int,str,float等)和类统一,所以,所有的类都是type类型的对象。当然,这个规则可以被修改,在类中有一个属性 __metaclass__ 可以指定当前类该由哪个类进行实例化。而创建对象过程中,其实构造器不是__init__方法,而是__new__方法,这个方法会返回一个对象,这才是对象的构造器。下面是一个解释类实例化对象内部实现过程的代码段:
- class Mytype(type):
- def __init__(self, what, bases=None, dict=None):
- super(Mytype,self).__init__(what, bases, dict)
- def __call__(self, *args, **kwargs):
- obj=self.__new__(self)
- self.__init__(obj, *args, **kwargs)
- return obj
- class Foo:
- __metaclass__=Mytype
- def __init__(self,name,age):
- self.name=name
- self.age=age
- def __new__(cls, *args, **kwargs):
- return object.__new__(cls)
- obj=Foo("xiaoming",18)
- print(obj.name,obj.age)
- 执行结果:xiaoming 18
4.异常处理
python中使用try except finally组合来实现异常扑捉,不像java中是使用try catch finally......其中,except中的Exception是所有异常的父类,下面是一个异常处理的示例:
-
- try:
- int("aaa") #可能出现异常的代码
- except IndexError as e: # 捕捉索引异常的子异常,注意,这里的as e在老版本的py中可以写成,e但是新版本中用as e,",e"未来可能会淘汰
- print("IndexError:",e)
- except ValueError as e: # 捕捉value错误的子异常
- print("ValueError:",e)
- except Exception as e: # 如果上面两个异常没有捕获到,那么使用Exception捕获,Exception能够捕获所有的异常
- print("Exception:",e)
- else: # 如果没有异常发生,执行else中的代码块
- print("true")
- finally: # 不管是否发生异常,在最后都会执行finally中的代码,假如try里面的代码正常执行,先执行else中的代码,再执行finally中的代码
- print("finally")
- 执行结果:
- ValueError: invalid literal for int() with base 10: 'aaa'
- finally
那么既然Exception是所有异常的父类,我们可以自已定义Exception的子类,实现自定义异常处理,下面就是实现例子:
- class OldBoyError(Exception): # 自定义错误类型
- def __init__(self,message):
- self.message=message
- def __str__(self): # 打印异常的时候会调用对象里面的__str__方法返回一个字符串
- return self.message
- try:
- raise OldBoyError("我错了...") # raise是主动抛出异常,可以调用自定义的异常抛出异常
- except OldBoyError as e:
- print(e)
- 执行结果:我错了...
异常处理里面还有一个断言,一般用在判断执行环境上面,只要断言后面的条件不满足,那么就抛出异常,并且后面的代码不执行了。
- print(123)
- assert 1==2 # 断言,故意抛出异常,做环境监测用,环境监测不通过,报错并结束程序
- print("456")
- 执行结果:
- assert 1==2 # 断言,故意抛出异常,做环境监测用,环境监测不通过,报错并结束程序
- 123
- AssertionError
5.反射/自省
python中的反射/自省的实现,是通过hasattr、getattr、setattr、delattr四个内置函数实现的,其实这四个内置函数不只可以用在类和对象中,也可以用在模块等其他地方,只是在类和对象中用的很多,所以单独提出来进行解释。
- hasattr(key)返回的是一个bool值,判断某个成员或者属性在不在类或者对象中
- getattr(key,default=xxx)获取类或者对象的成员或属性,如果不存在,则会抛出AttributeError异常,如果定义了default那么当没有属性的时候会返回默认值。
- setattr(key,value)假如有这个属性,那么更新这个属性,如果没有就添加这个属性并赋值value
- delattr(key)删除某个属性
注意,上面的key都是字符串,而不是变量,也就是说可以通过字符串处理类中的成员或者对象中的属性。下面是一个例子代码:
- class Foo:
- def __init__(self,name,age):
- self.name=name
- self.age=age
- def show(self):
- return self.name,self.age
- obj=Foo("xiaoming",18)
- print(getattr(obj,"name"))
- setattr(obj,"k1","v1")
- print(obj.k1)
- print(hasattr(obj,"k1"))
- delattr(obj,"k1")
- show_fun=getattr(obj,"show")
- print(show_fun())
- 执行结果:
- xiaoming
- v1
- True
- ('xiaoming', 18)
反射/自省能够直接访问以及修改运行中的类和对象的成员和属性,这是一个很强大的功能,并且并不像java中效率很低,所以用的很多。
下面是一个反射/自省用在模块级别的例子:
- import s2
- operation=input("请输入URL:")
- if operation in s2.__dict__:
- getattr(s2,operation)()
- else:
- print("404")
-
- #模块s2中的代码:
- def f1():
- print("首页")
- def f2():
- print("新闻")
- def f3():
- print("精选")
- 执行结果:
- 请输入URL:f1
- 首页
6.单例模式
这里介绍一个设计模式,设计模式在程序员写了两三年代码的时候,到一定境界了,才会考虑到设计模式对于程序带来的好处,从而使用各种设计模式,这里只是简单的介绍一个简单的设计模式:单例模式。在面向对象中的单例模式就是一个类只有一个对象,所有的操作都通过这个对象来完成,这就是面向对象中的单例模式,下面是实现代码:
-
- class Foo: # 单例模式
- __v=None
- @classmethod
- def ge_instance(cls):
- if cls.__v:
- return cls.__v
- else:
- cls.__v=Foo()
- return cls.__v
- obj1=Foo.ge_instance()
- print(obj1)
- obj2=Foo.ge_instance()
- print(obj2)
- obj3=Foo.ge_instance()
- print(obj3)
- 执行结果:
- <__main__.Foo object at 0x000001D2ABA01860>
- <__main__.Foo object at 0x000001D2ABA01860>
- <__main__.Foo object at 0x000001D2ABA01860>
可以看到,三个对象的内存地址都是一样的,其实,这三个变量中存储的都是同一个对象的内存地址,这样有什么好处呢?能够节省资源,就比如在数据库连接池的时候就可以使用单例模式,只创建一个类的对象供其他程序调用,还有在web服务中接收请求也可以使用单例模式来实现,节省资源。

