
- 1Fragment - (1) - 基本用法_layout fragment使用
- 2MySQL数据库的五个基本操作:查看、创建、修改、删除和选择数据库_定义数据库 1.查看已有的数据库; 2.创建数据库teachsys; 3.选择数据库teachsys
- 3【LeetCode-中等】567. 字符串的排列 - 滑动窗口_unordered_set
occ; int len = s.length(); if( - 4ssm基于Android的自来水收费系统APP(ssm+uinapp+Mysql)_自来水营销管理系统ssm
- 5SpringBoot 全局事务配置_springboot配置事务
- 6DVWA-SQL Injection级别通关详解_dvwa靶机sql通关
- 7【EI征稿】第二届移动互联网、云计算与信息安全国际会议
- 8Android真机调试打印日志的方法_android crush日志 真机调试
- 9A Few Useful Things to Know About Machine Learning 中英文对比和笔记
- 10Android屏幕适配-重点盘点
Yolov5自定义图片训练测试及模型调优(详细过程)_yolov5必须要标注嘛
赞
踩
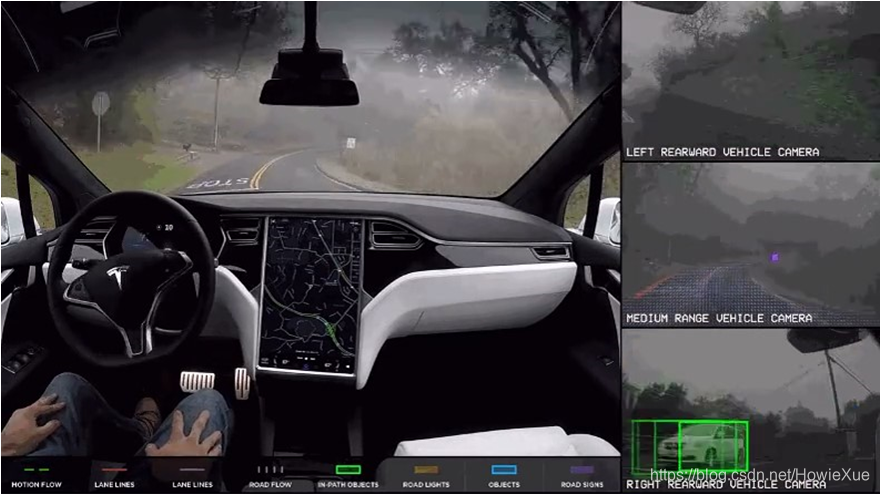
1. 图像数据获取、标注
如果自定义训练自己的数据集,首先需要数据标注,至于数据来源可以是下载现有的开发数据集、拍照、爬虫等等。
如果是拍照、爬虫等获取的数据图片,需要进行数据标注,这个过程可以使用工具来做,但也需要一些手动操作 。。并且图片越多越好,如果样本过少,模型训练和预测都会受到影响,非常容易欠拟合。
这里因为针对自定义数据大多不存在现有数据集,所以我使用了手机拍照方式,获取图片。
图片标注工具有很多,这里我使用的Makesense AI工具对图像添加标签:
makesense.ai是强大且免费使用的 为照片加标签的在线工具
makesense.ai不需要安装,直接用浏览器即可,非常方便:而且能够直接导出Yolo格式,不需要在用工具转换了。。。
(当然还有别的工具例如labelimg等,但只能导出xml,需要脚本进行xml-txt转换,不过labelimg这类本地Tools数据隐私/安全性更高)
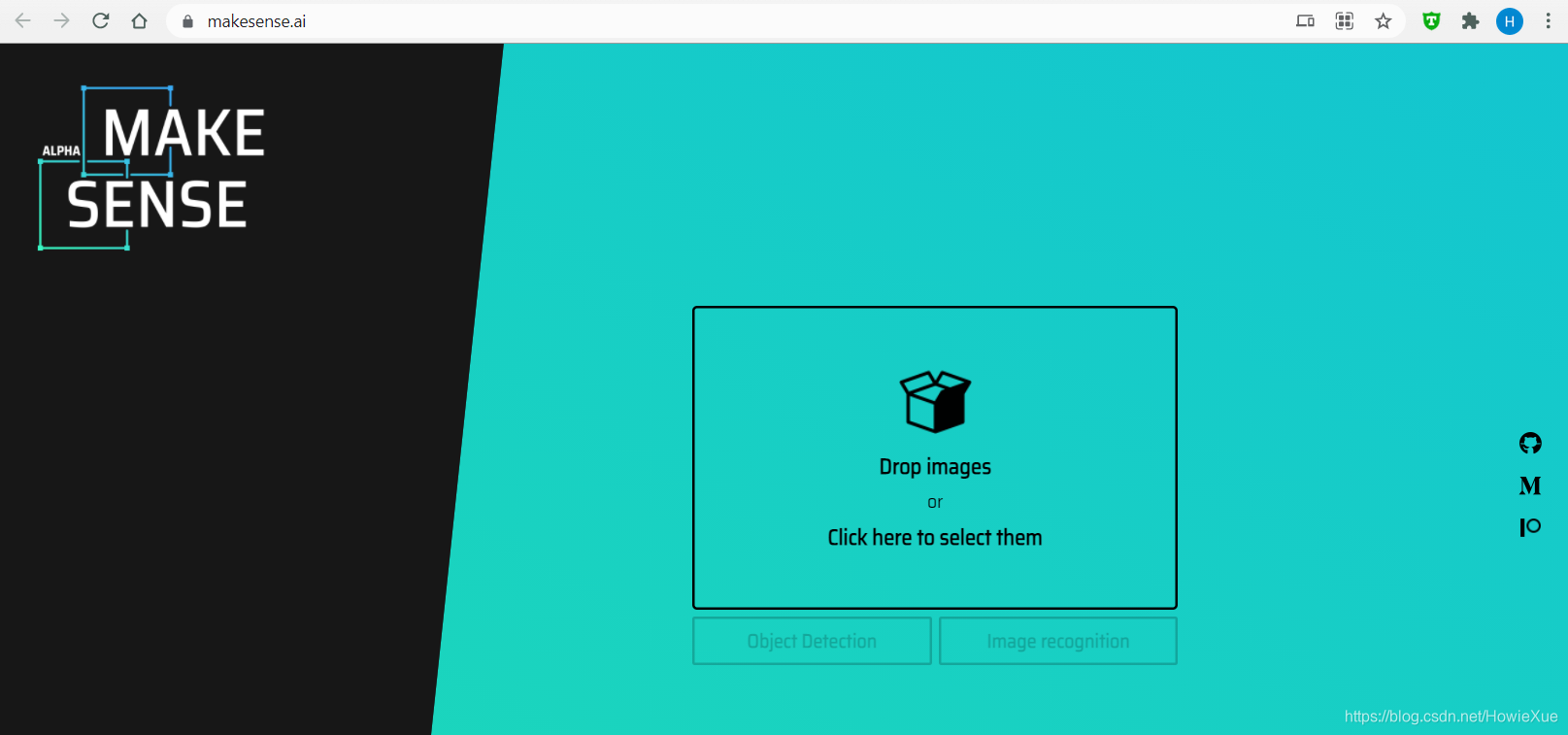
将待标注的图片文件拖拽或点击上传,之后点击Object Detection:
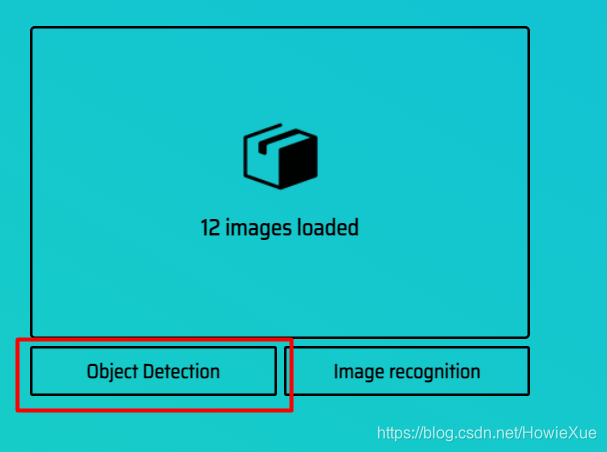
点击ObjectDetection后,系统提示需要我们添加标签,根据需要,添加Lable的名称
(根据待测数据集,有几类就添加几个)
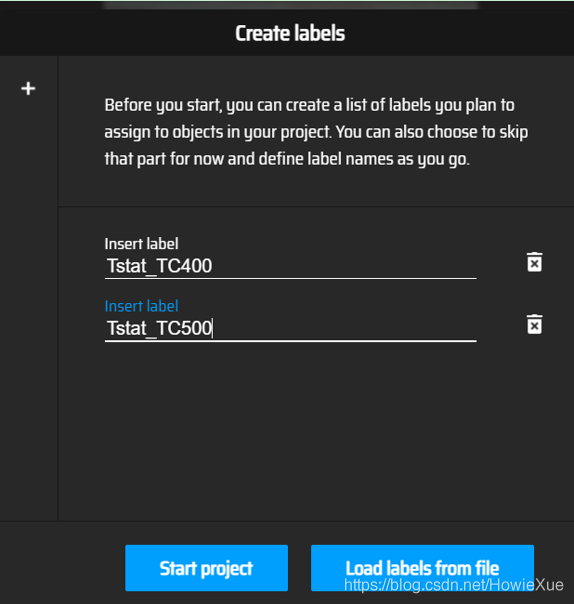
添加完标签名称后,点击start project。
下一步进入工作台,通过Rect画矩形框进行标注:
makesense支持点,线,区域标注
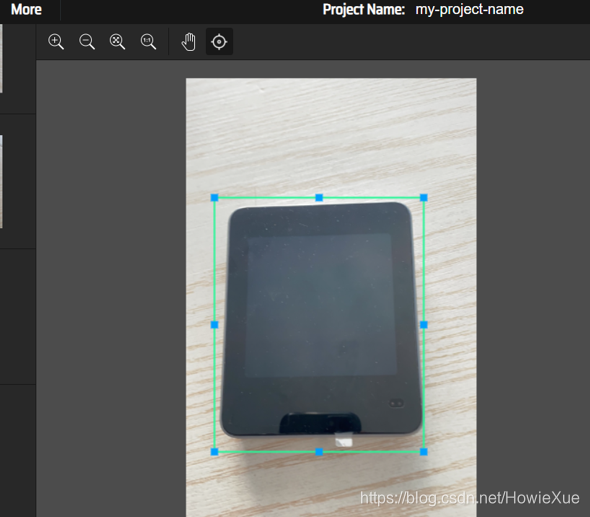
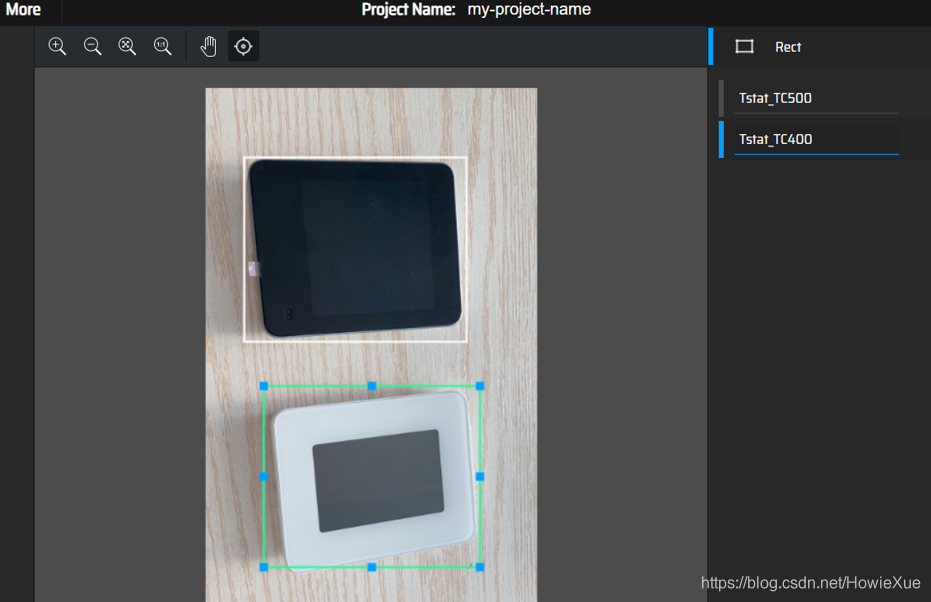
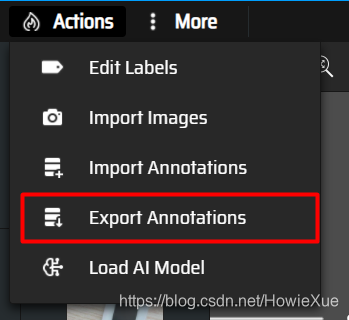
标注完成后,点击Export Annotations导出labels
选择Yolo格式
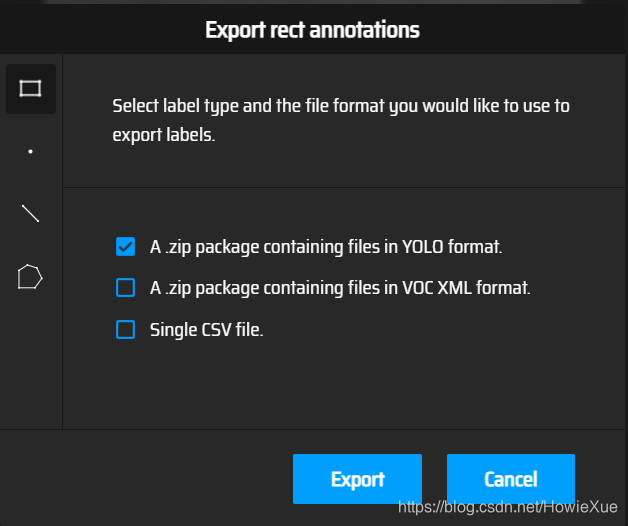
导出的标注 label文件,其实就是类别和区域位置,每一个lable格式分别代表:
- class x_center y_center width height
对应lable文件每行的内容,例如:
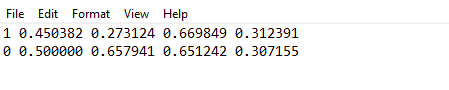
因为我们使用了makesense.ai 可以直接生成yolo格式的label txt,所以之后不需要使用工具进行转换了,直接copy到数据集即可,非常方便。。。否则如果是xml文件格式,还需要脚本进行xml-txt转换。。。
2. 数据集划分及准备
首先划分测试数据集,将自定义测试的图像数据和标签数据集分别 划分为:训练集、验证集、测试集,,比例根据数据量不同,一般可以为 96%:2%:2%
仿照Yolov5原生格式,我们新建一个datasets目录,并创建images,labels两个子目录,分别存放待训练的图像以及标注后的label数据:
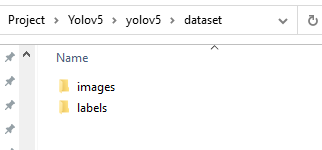
并分别创建数据集目录 train/val/test,
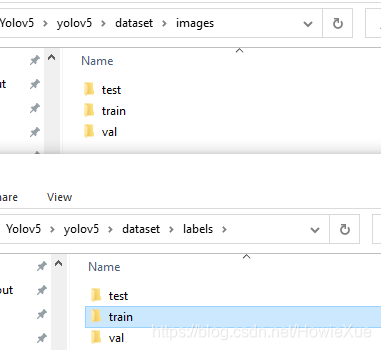
将相应测试数据集分别放入相应文件夹中(文件名要一一对应),如下图:
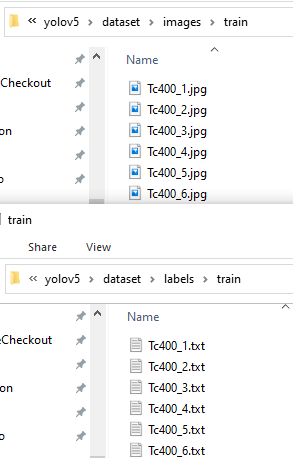
到这一步训练所需数据集划分及准备 就完成了,
3. 配置训练参数,准备训练:
和Yolov3/Yolov4中的.cfg配置文件不同,Yolov5参数配置文件都是以.yaml的格式
3.1 修改data/训练配置xxx.yaml文件:
下面需要修改Yolov5的训练配置参数,既自定义制作自己使用的训练.yaml配置文件:
为了方便修改,我们可以copy一份原有的data/coco128.yaml, 重命名一下,并修改其中的参数为自定义训练的参数:
先看下coco128.yaml,可以看到原有coco训练集的类别数量是80个,标签(模型能识别的类别名)分别是下面的name
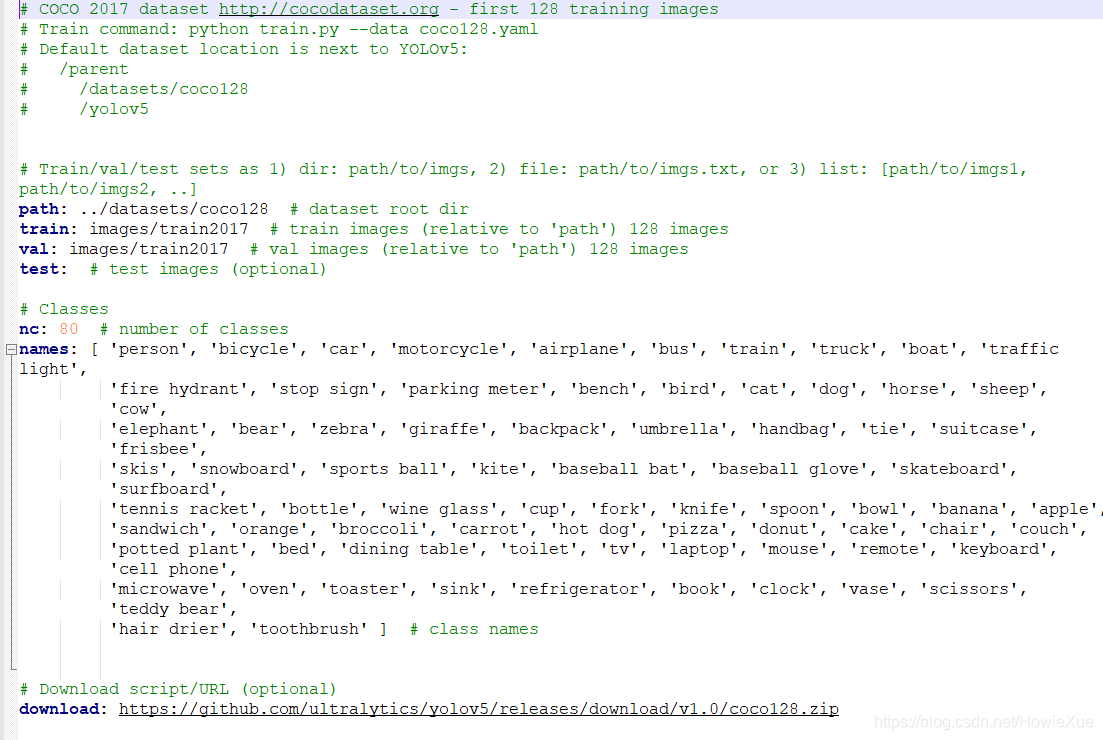
根据具体需要修改,我这里测试所用的修改为:
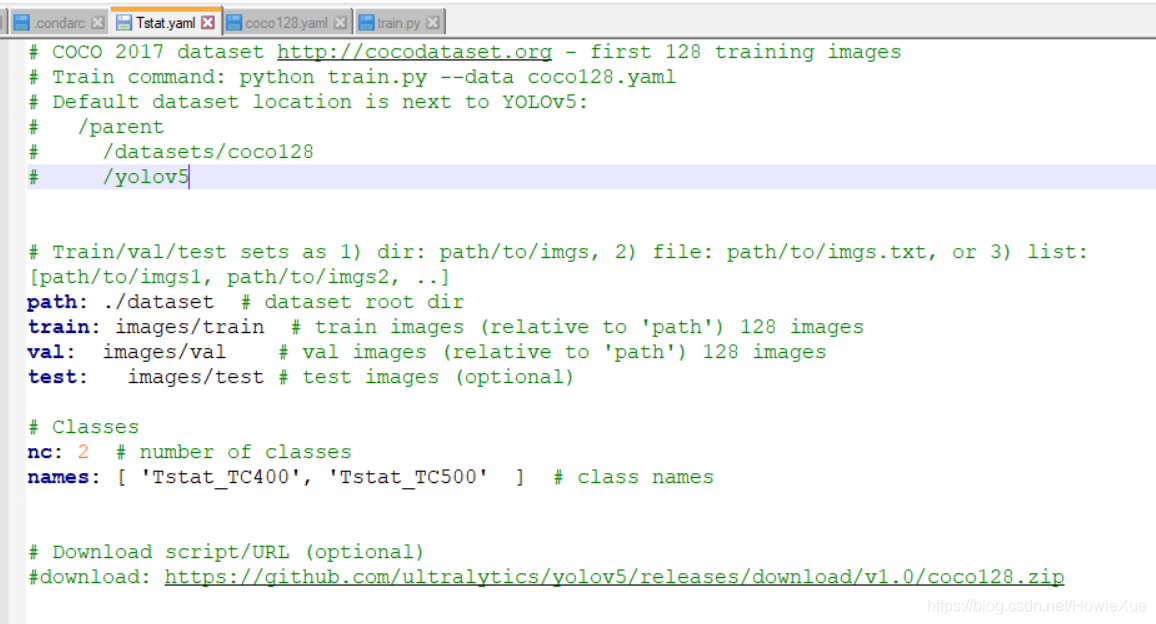
- 修改path/train/val/test的目录路径为自定义数据集路径
- 将nc(number of classes)改为 2
- 修改Names为自己数据的类别名
- 注释掉Download
train.py在训练过程中,会将路径中的images替换为 labels来寻找labels数据
修改后的yaml:
3.2 修改models模型配置xxx.yaml文件
进入models/目录,可以看到有四个模型配置的yaml文件:
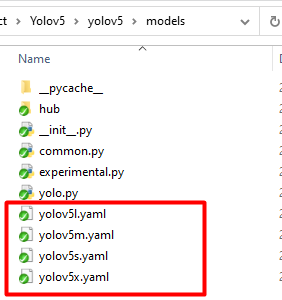
根据需要选择其中的模型yaml进行修改,这里为了精度,以模型网络参数量最多的yolov5x为例,打开yolov5x.yaml:
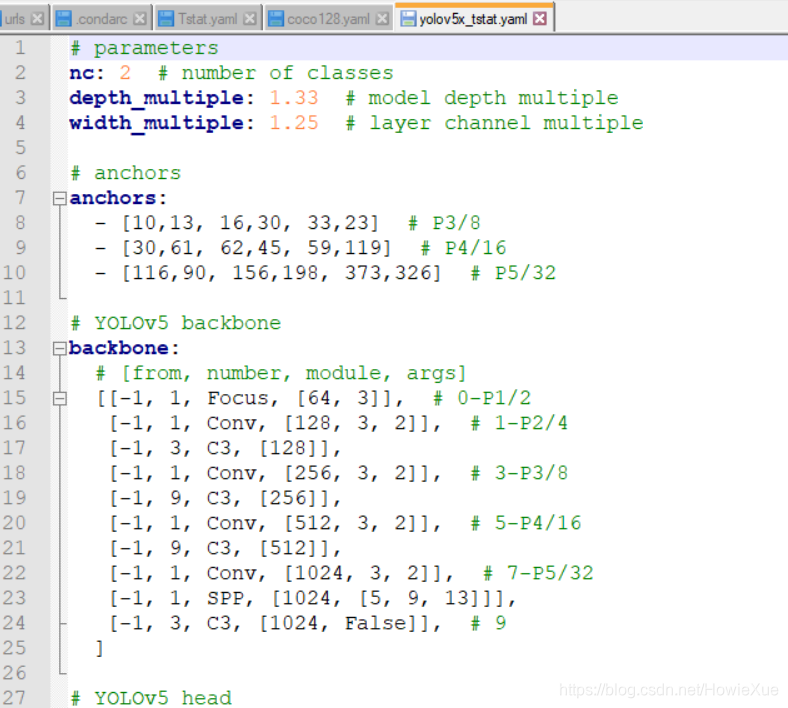
Model的yaml文件中都是模型网络相关配置参数,例如nc下面的depth_multiple是指网络的深度,width_multiple是网络的宽度, anchors是锚标(标出物体的方框),backbone既骨干网络
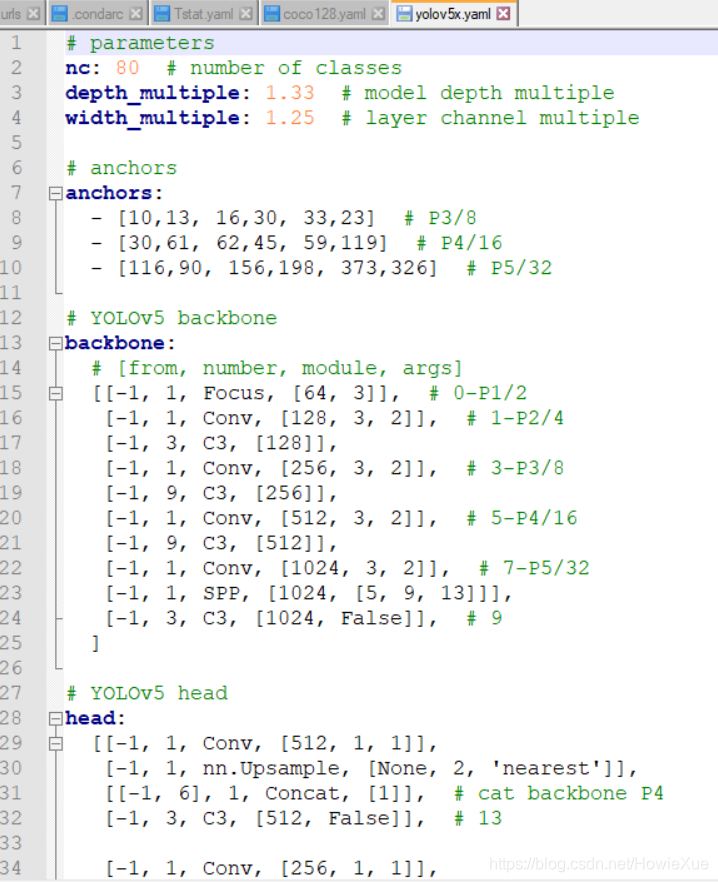
yolov5x.yaml里面就是yolov5x 模型训练的具体参数了,这里和上面一样对应也做修改
建议还是copy出一份新的yaml,进行修改:
- nc 修改为2,
- 针对Anchors ,如果自己提前聚类过,可以同步把计算后anchors修改下,如果没有可以不修改
因为Yolov5默认已经能够 自动判断是否需要重新进行聚类anchors的功能(使用K-means),所以这里我没有操作
4. 开始训练
在修改完两个yaml配置文件后,就可以开始训练了:
python train.py --cfg models/yolov5m_tstat.yaml --data data/Tstat.yaml --weights yolov5m.pt --epoch 150 --batch-size 32
- 1
开始训练:
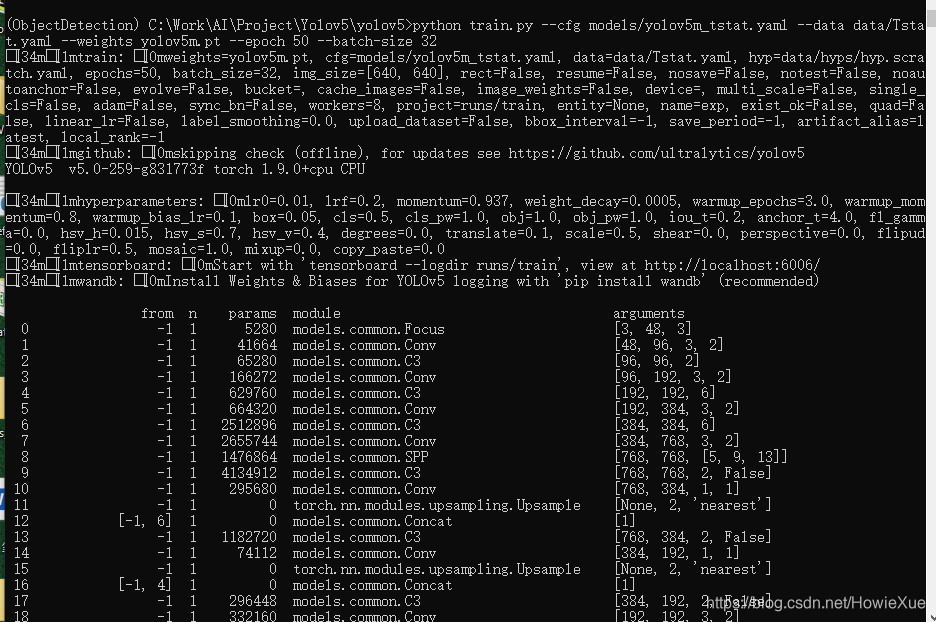
然后就是漫长的traning过程,等待训练完成。。。
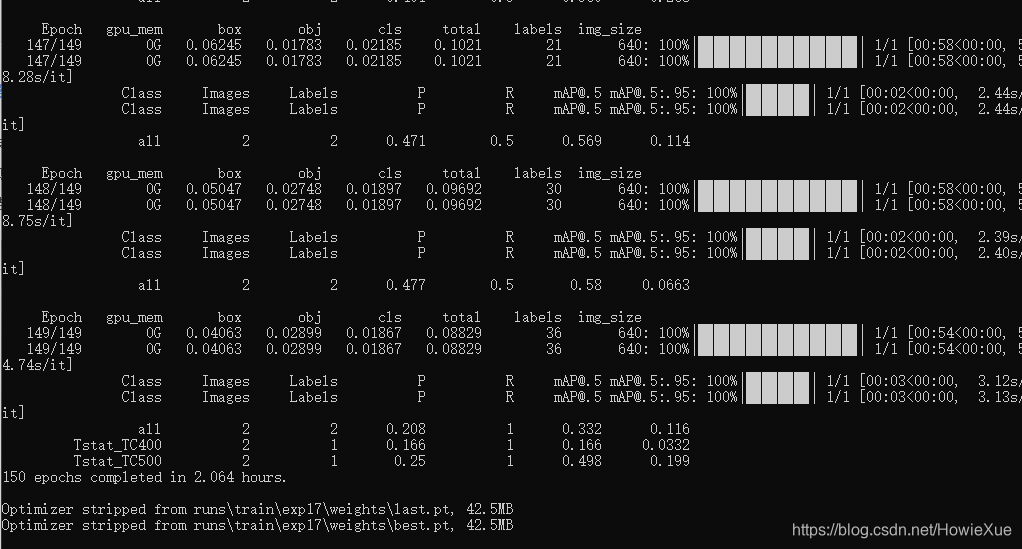
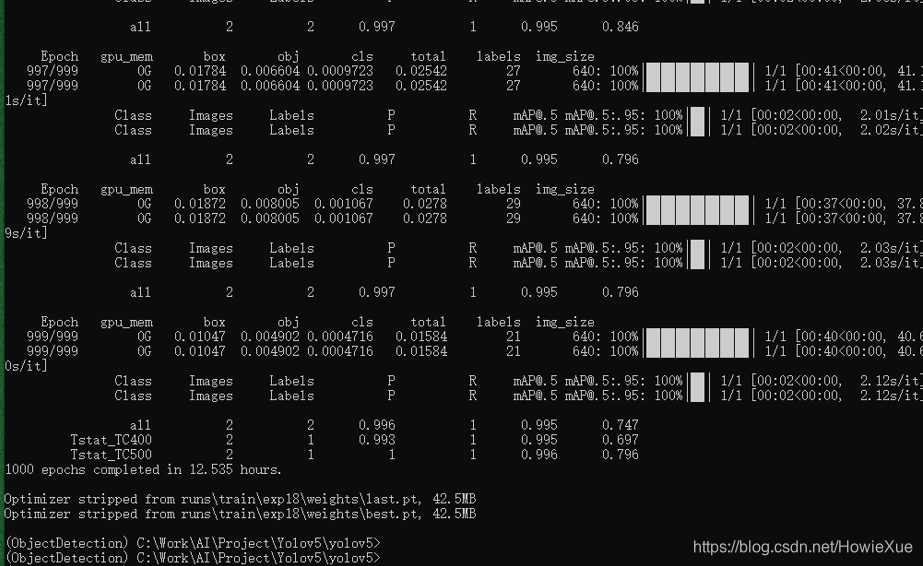
训练完后,通过最后log可以看到训练好的模型的权重保存在了runs/train/exp17/weights/last.pt和best.pt
其中还包括了PR Curve 曲线、Confusion matric (混淆矩阵)、results.png/txt 等训练过程数据
train.py相关参数解析:
- weights:权重文件路径,如果是’'则重头训练参数,如果不为空则做迁移学习,权重文件的模型需与cfg参数中的模型对应
- epochs:指的就是训练过程中整个数据集将被迭代多少次
- batch-size:每次梯度更新的批量数,指一次看完多少张图片才进行权重更新
- config-thres: 模型目标检测的置信度阈值
- cfg:存储模型结构的配置文件
- data:存储训练、测试数据的文件
- img-size:输入图片的宽高
- rect:进行矩形训练
- resume:恢复最近保存的模型开始训练
- nosave:仅保存最终checkpoint
- notest:仅测试最后的epoch
- evolve:进化超参数
- cache-images:缓存图像以加快训练速度
- name: 重命名results.txt to results_name.txt
- device:cuda device, i.e. 0 or 0,1,2,3 or cpu
- adam:使用adam优化
- multi-scale:多尺度训练,img-size +/- 50%
- single-cls:单类别的训练集
5. 测试训练后的模型:
同样使用detect.py,weights使用新训练后的best.pt,测试图片可以拍一个新照片,或者找一个之前没有用到的图片
python detect.py --weights runs/train/exp16/weights/best.pt --source data/test/Tc400_137.jpg
- 1
(图片的置信度0.9是在模型调优后才达到的)


train_batch0.jpg:可以看到模型在训练过程,模型分别使用0和1代表两个不同的label/class,

Yolov5官网的预训练模型在训练中使用的coco数据集,也是通过0-80数字来分别代表不同的label/class
例如官方文档提供的train_batch0.jpg示例图片 ,对应了预训练模型训练时的batch 0:

测试实时摄像头识别如下,识别的区分度还是有的~

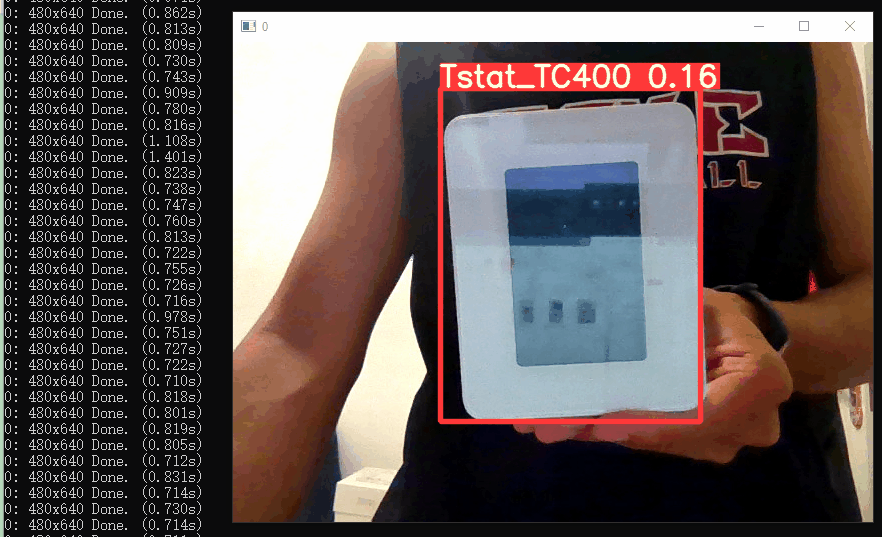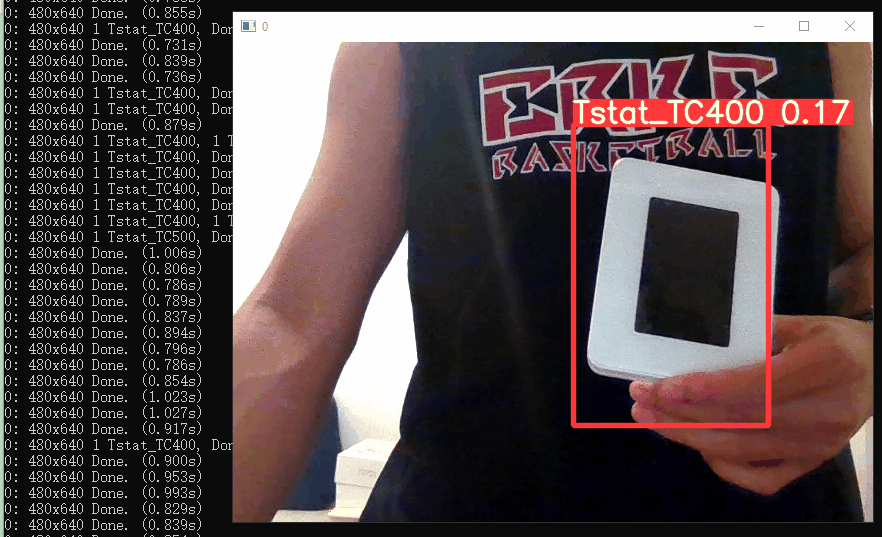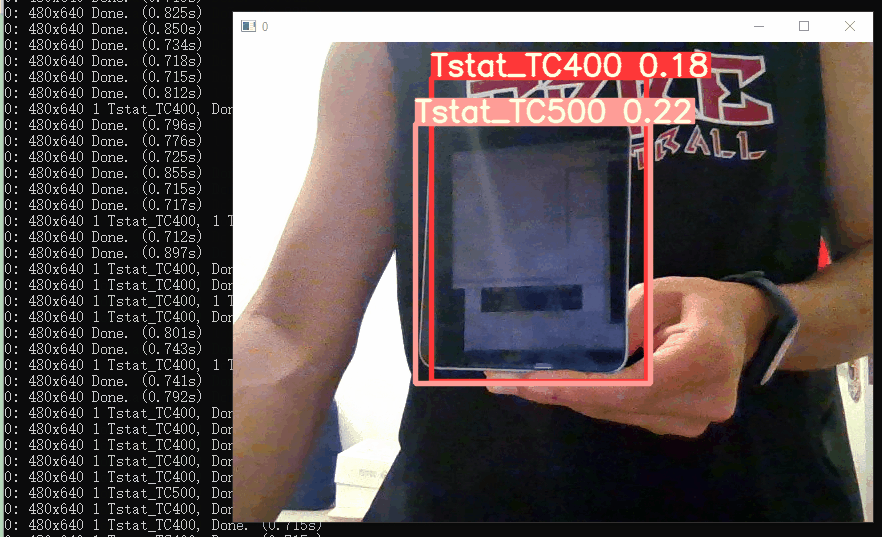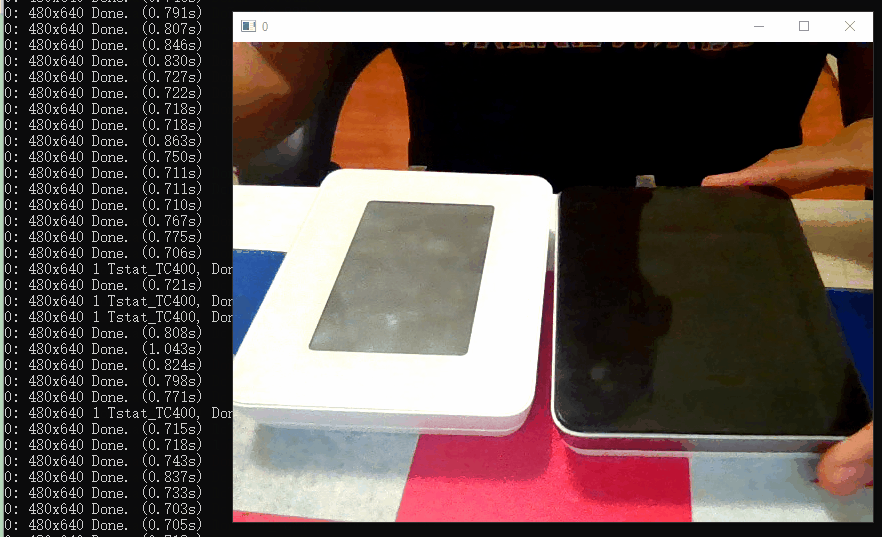
6. 模型的参数调优
细心的小伙伴们可以发现上面目标检测识别的置信度比较低(在实时摄像头检测的置信度都低于0.2)。。
良好的模型一般置信度要在0.6以上,识别率要达到90%以上。
因此这次训练出来的模型识别效果很差,不能使用,这是因为上面训练过程没有进行模型的调优。
接下来需要进行YOLOv5模型参数的调优,才能提高识别率及置信度。。。(或提高样本数据量然后重新训练)
train.py会默认使用的源码自带的模型超参数 (HyperParameter),这些参数针对Githu上的源码在训练时的数据集(如coco数据集)或许最优,但不一定在我们自定义的数据中是有效的。
实际上,Github上的预训练模型在识别率等方面也有一定缺陷,不能直接应用在实际工程中,在大多数应用中都需要重新调整,并基于相应数据集训练适用于自己项目的模型。。。
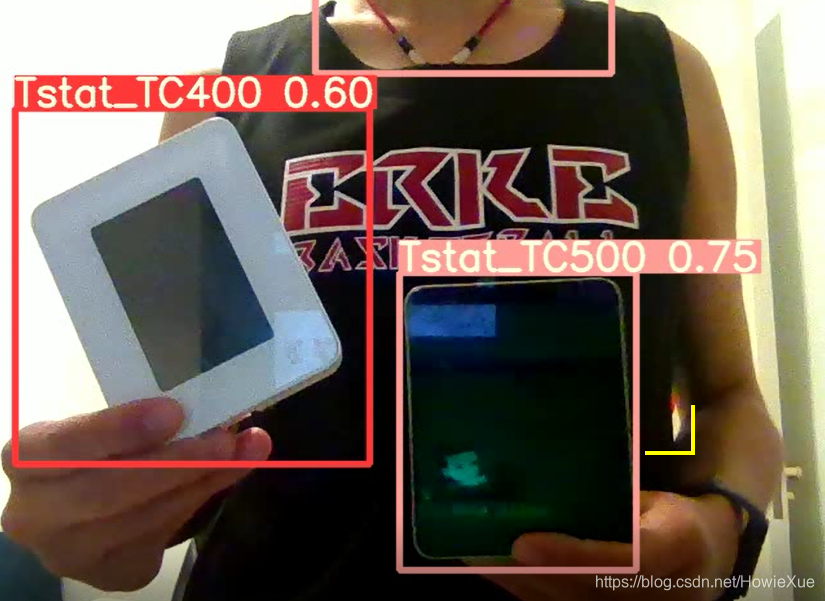
在经过模型hyp参数调优后,置信度显著得到提升,最终测试 ,实时摄像头检测的置信度能达到0.6以上,纯img检测图像更是能达到0.9:
参数调优过程一般要反复多次进行微调<->训练<->测试,最终得出符合需求/较优的HyperPara,应用在项目中
先上图:
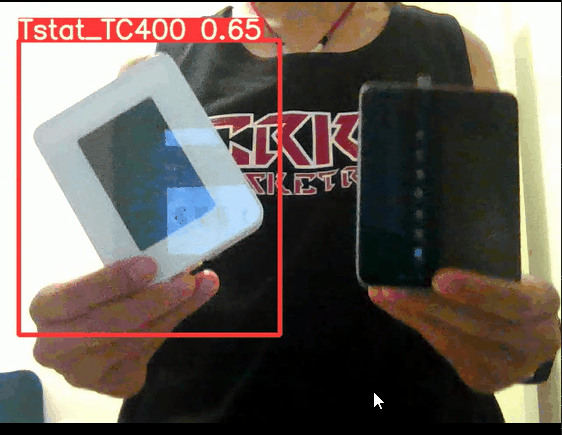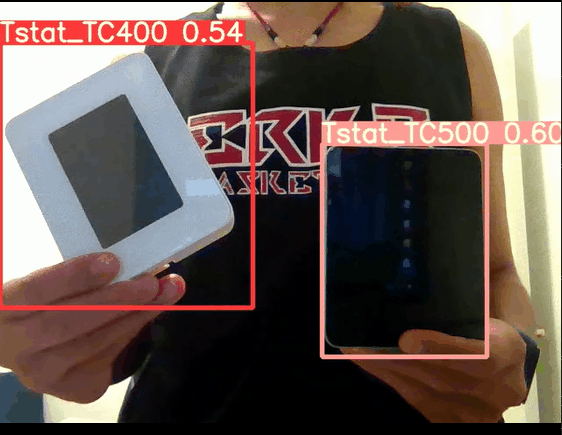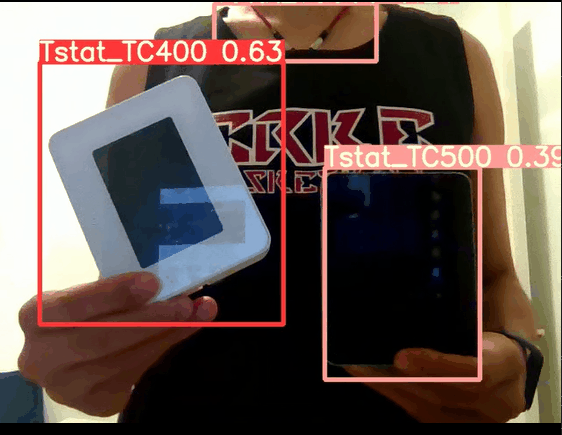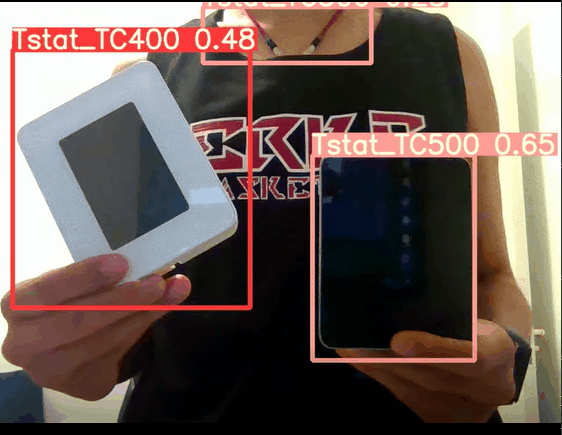
调整超参数在data/hyps/hyp.finetune.yaml:
这里最终主要是调整了lr0(学习率)为0.0030,同时修改了epoch、batch-size
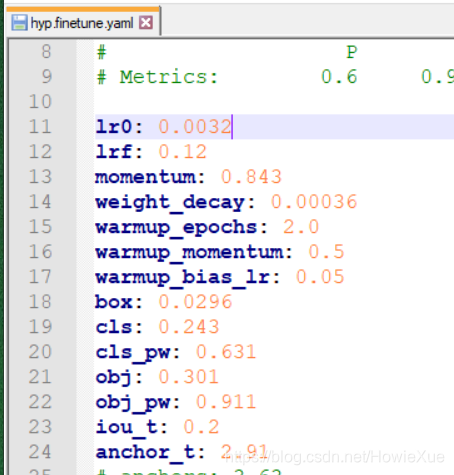
部分hyp超参数意义:
- lr0: 0.0032 #学习率
- lrf: 0.12 # 余弦退火超参数 (CosineAnnealing)
- momentum: 0.843 # 学习率动量
- weight_decay: 0.00036 # 权重衰减系数
- warmup_epochs: 2.0 #预热学习epoch
- warmup_momentum: 0.5 #预热学习率动量
- warmup_bias_lr: 0.05 #预热学习率
- box: 0.0296 # giou损失的系数
- cls: 0.243 # 分类损失的系数
- cls_pw: 0.631 #分类BCELoss中正样本的权重
- obj: 0.301 # 有无物体损失的系数
- obj_pw: 0.911 # 有无物体BCELoss中正样本的权重
- iou_t: 0.2 # 标签与anchors的iou阈值iou training threshold
并且增大epoch到1000,batch-size增大到64,重新使用train.py训练,训练时间也增加了不少(这次用了12小时)
python train.py --cfg models/yolov5m_tstat.yaml --data data/Tstat.yaml --weights yolov5m.pt --epoch 1000 --batch-size 64
- 1
当然还要考虑一点,针对视频图像识别中,移动的物体识别率本身就比静止图像差,同时运动检测越剧烈,偏差越大。。。
例如把设备放到桌面上 这样的识别率及置信度都会更稳定一些:

同时还要考虑到,我在这里的测试过程,是手工拍照的数据量比较小,也可能会导致模型欠拟合,造成模型识别效果不良。
实际图像数据量,每个类别最好大于1500张,并且做一些图像增强、变换等数据预处理技术。 增加模型的鲁棒性,防止过拟合。
针对模型调优的技巧,可参考官网的Tips:https://docs.ultralytics.com/tutorials/training-tips-best-results/
在进行模型测试时,无论是加载模型的速度还是对测试图片的推理速度,都能明显感觉到Yolov5速度更快,尤其是加载模型的速度,因为同样的数据集训练出来的模型Yolov5更加轻量级,模型大小减小为Yolov3的将近四分之一。
至此Yolov5自定义数据训练及测试 /模型调优 都已完成。。。
附Yolov5的网络模型结构图(图片来自知乎江大白)
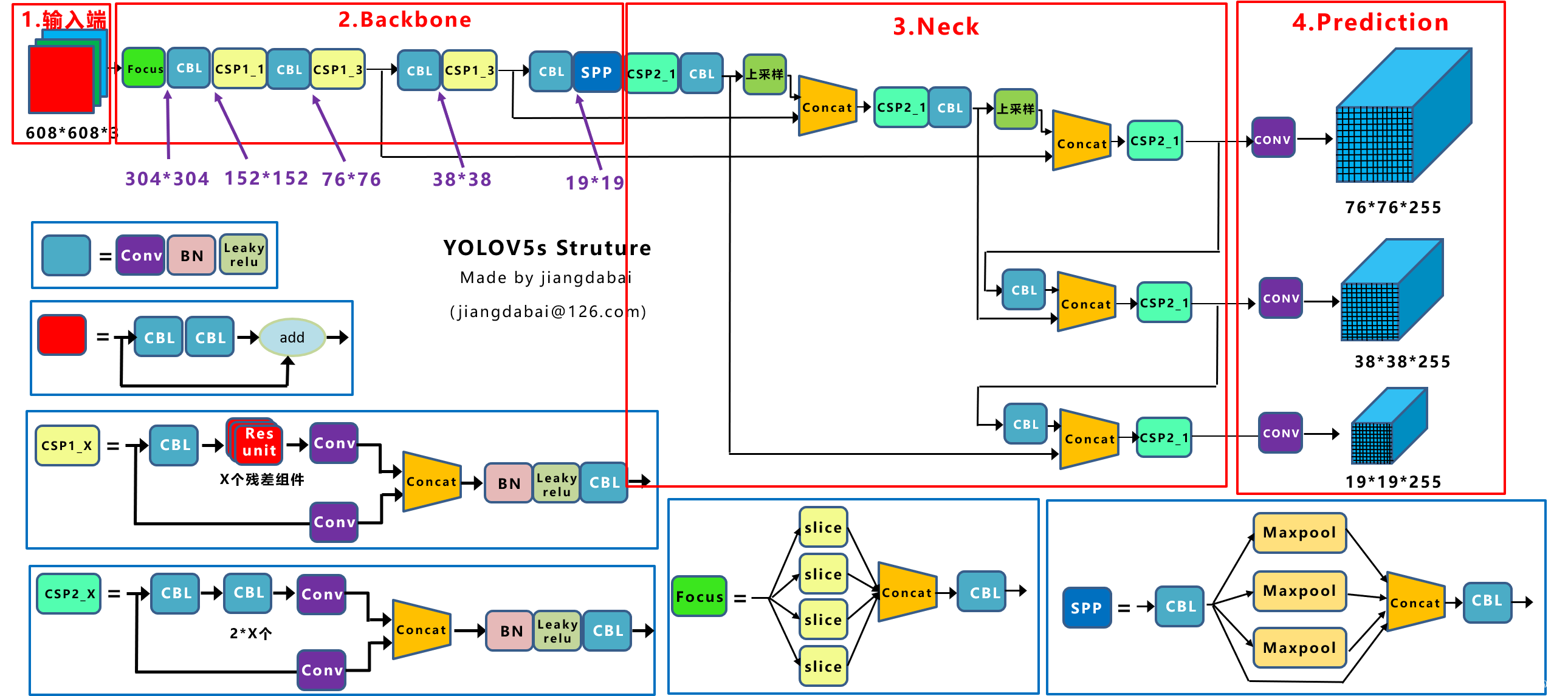
下面将继续开始对Yolov5的源码和骨干网络进行深入探讨。。。

博主热门文章推荐:
一篇读懂系列:
LoRa Mesh系列:
网络安全系列:
- ATECC508A芯片开发笔记(一):初识加密芯片
- SHA/HMAC/AES-CBC/CTR 算法执行效率及RAM消耗 测试结果
- 常见加密/签名/哈希算法性能比较 (多平台 AES/DES, DH, ECDSA, RSA等)
- AES加解密效率测试(纯软件AES128/256)–以嵌入式Cortex-M0与M3 平台为例
嵌入式开发系列:
- 嵌入式学习中较好的练手项目和课题整理(附代码资料、学习视频和嵌入式学习规划)
- IAR调试使用技巧汇总:数据断点、CallStack、设置堆栈、查看栈使用和栈深度、Memory、Set Next Statement等
- Linux内核编译配置(Menuconfig)、制作文件系统 详细步骤
- Android底层调用C代码(JNI实现)
- 树莓派到手第一步:上电启动、安装中文字体、虚拟键盘、开启SSH等
- Android/Linux设备有线&无线 双网共存(同时上内、外网)
AI / 机器学习系列:
- AI: 机器学习必须懂的几个术语:Lable、Feature、Model…
- AI:卷积神经网络CNN 解决过拟合的方法 (Overcome Overfitting)
- AI: 什么是机器学习的数据清洗(Data Cleaning)
- AI: 机器学习的模型是如何训练的?(在试错中学习)
- 数据可视化:TensorboardX安装及使用(安装测试+实例演示)

