
- 1做软件测试,就得去大厂!
- 2Rasa中文聊天机器人开发指南(2):NLU篇_rasa中文文档
- 3《基于音频和文本的多模态语音情感识别的TensorFlow实现》的项目(写的很人性化的哦!)_基于tensorflow的语音情绪分析与运用的研究意义
- 4B端界面设计:页面分类设计_页面结构设计,功能划分
- 5介绍一下gpt模型的原理_gpt原理
- 6芒果YOLOv8改进10:特征融合Neck篇:改进特征融合网络 BiFPN 结构,融合更多有效特征_concat_bifpn yolov8
- 7深入解析《企业级数据架构》:HDFS、Yarn、Hive、HBase与Spark的核心应用_数据仓库 hive hdfs
- 8ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices论文学习
- 9mxnet学习笔记(二)——训练器Trainer()函数详解_gluon.trainer
- 10可视化模型:深度学习中的 Grad-CAM 指南_gcn grad-cam
区块链基础知识(下):共识机制 附带图解、超详细教学 看不懂你打死我
赞
踩

苏泽
大家好 这里是苏泽 一个钟爱区块链技术的后端开发者
本篇专栏 ←持续记录本人自学两年走过无数弯路的智能合约学习笔记和经验总结 如果喜欢拜托三连支持~
专栏的前面几篇详细了介绍了区块链的核心基础知识 有兴趣学习的小伙伴可以看看→http://t.csdnimg.cn/CstOy 关于区块链的基本组成、加密原理都用最通俗易懂的方式讲解了 希望能够帮助大家学习
以下是正文
目录
RBFT算法通常包含以下几个阶段:视图切换(View Change)、决策提案(Proposal)、验证和投票(Validation and Voting)、决策达成(Decision)。
当然了还有很多种不同的算法没有天下第一的算法 只有不同场景下相对的最优决策
而在EOS的机制下,节点是定向广播的。21节点的位置是透明的,会选择最短路径来规定广播顺序。如图:
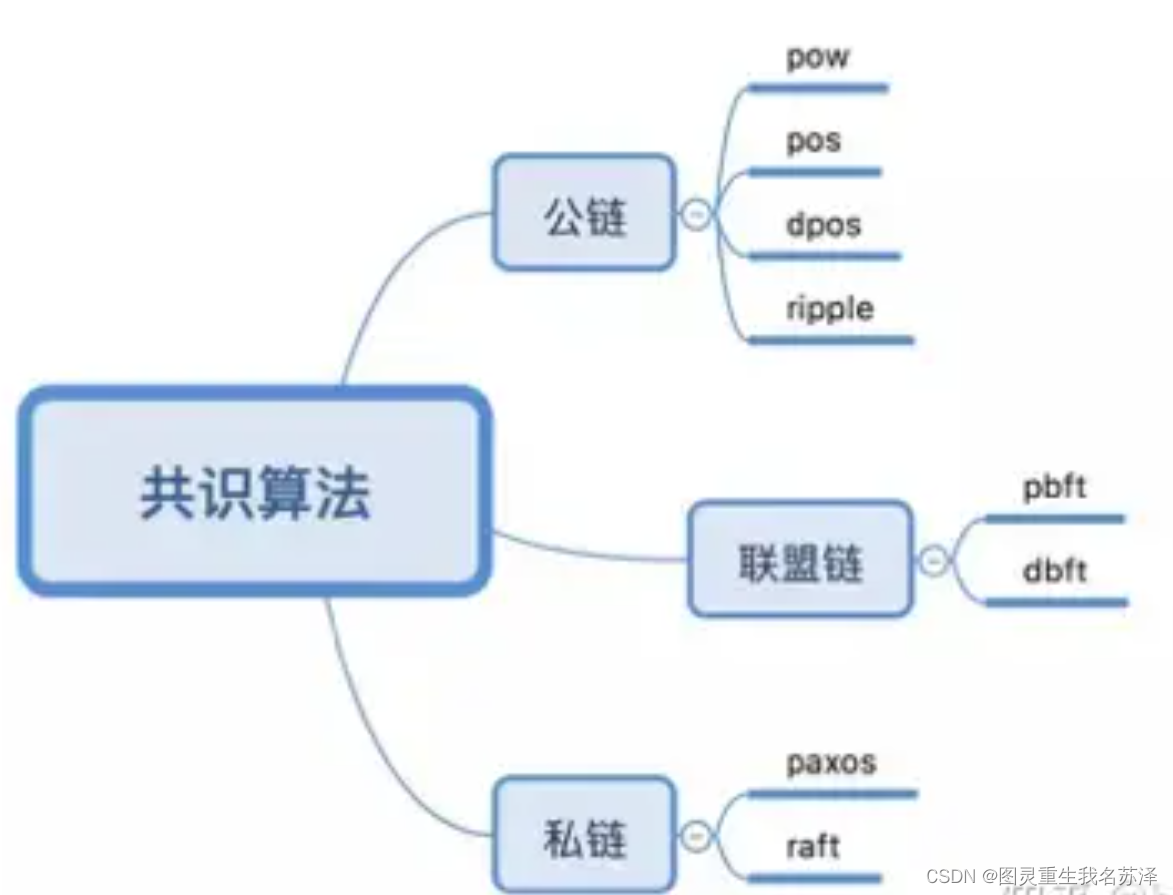
共识机制
共识算法是用于保证分布式系统一致性的机制。这里的一致性可以是交易顺序的一致性、账本一致性、节点状态的一致性等。一般地,我们根据容错类型将共识算法分为两类。
- 拜占庭容错 : 拜占庭容错强调的是能够容忍部分区块链节点由于硬件错误、网络拥塞或断开以及遭到恶意攻击等情况出现的不可预料的行为。BFT系列算法是典型的拜占庭容错算法,比如PBFT、HotStuff等。
- 非拜占庭容错 : 非拜占庭容错通常指能够容忍部分区块链节点出现宕机错误,但不容忍出现不可预料的恶意行为导致的系统故障。常见的CFT共识算法有Paxos、Raft等。
实用拜占庭容错机制理解
我们用一个例子来说明 这个机制
假设有一个拜占庭帝国,帝国中有多位将军和士兵组成的军队,这些将军需要就发起进攻或撤退的决策达成一致,然后将命令传达给士兵执行。然而,有些将军可能是叛徒,他们可能会发送错误的指令或者伪造指令来导致军队混乱。
为了解决这个问题,拜占庭容错机制可以被应用。在这个机制中,将军们通过多轮的消息交流来达成共识。每一轮,将军们会相互发送自己的意见和指令,并收集其他将军们的意见。
在每一轮中,将军们会根据收到的消息进行验证。他们会检查消息的完整性、一致性和发送者的可信度。如果大多数将军发送了相同的指令,那么其他将军将接受这个指令并传达给士兵。如果有少数叛徒将军发送了错误的指令,那么大多数忠诚的将军可以通过多数投票的方式排除这些错误指令,并达成一致的决策。
通过这种方式,拜占庭容错机制可以保证大多数忠诚的将军达成一致的决策,并将正确的指令传达给士兵,即使存在少数叛徒将军的干扰。
大多数平台采用 自适应共识机制 ,支持RBFT、NoxBFT(BFT类)以及RAFT(CFT类)等多种共识算法,以满足不同的业务场景需求。下文将主要介绍RBFT、NoxBFT和RAFT等共识算法。
我们这里讲解其中一种--RBFT
RBFT
RBFT(Redundant Byzantine Fault Tolerance)是一种拜占庭容错算法,它通过增加冗余节点来提高系统的容错性能。在RBFT算法中,系统中的节点被分为两类:主节点(Primary)和备份节点(Backup)。主节点负责提出决策并向其他节点传达,备份节点则用于容错,以确保即使主节点出现错误或恶意行为,系统仍能正常运行。
回到之前的拜占庭帝国的例子,我们可以应用RBFT算法来改进共识过程。假设有5位将军,其中一位将军被选为主将军,其他4位将军作为备份将军。
在每一轮的共识过程中,主将军会提出进攻或撤退的决策,并将其发送给其他4位备份将军。备份将军会验证主将军的决策,并与其他备份将军进行比较。如果大多数备份将军收到并验证了相同的决策,那么他们会接受该决策并将其传达给士兵。
然而,如果主将军是叛徒或出现错误,发出了错误的决策,备份将军可以通过相互比较和多数投票的方式排除错误的决策,并达成一致的决策。只有当大多数备份将军达成一致时,正确的决策才会被传达给士兵。
通过增加备份将军,RBFT算法提供了冗余的节点来容忍主节点的错误或恶意行为。即使主节点是叛徒或出现错误,只要大多数备份节点是诚实的,系统仍然能够达成共识并保持正常运行。
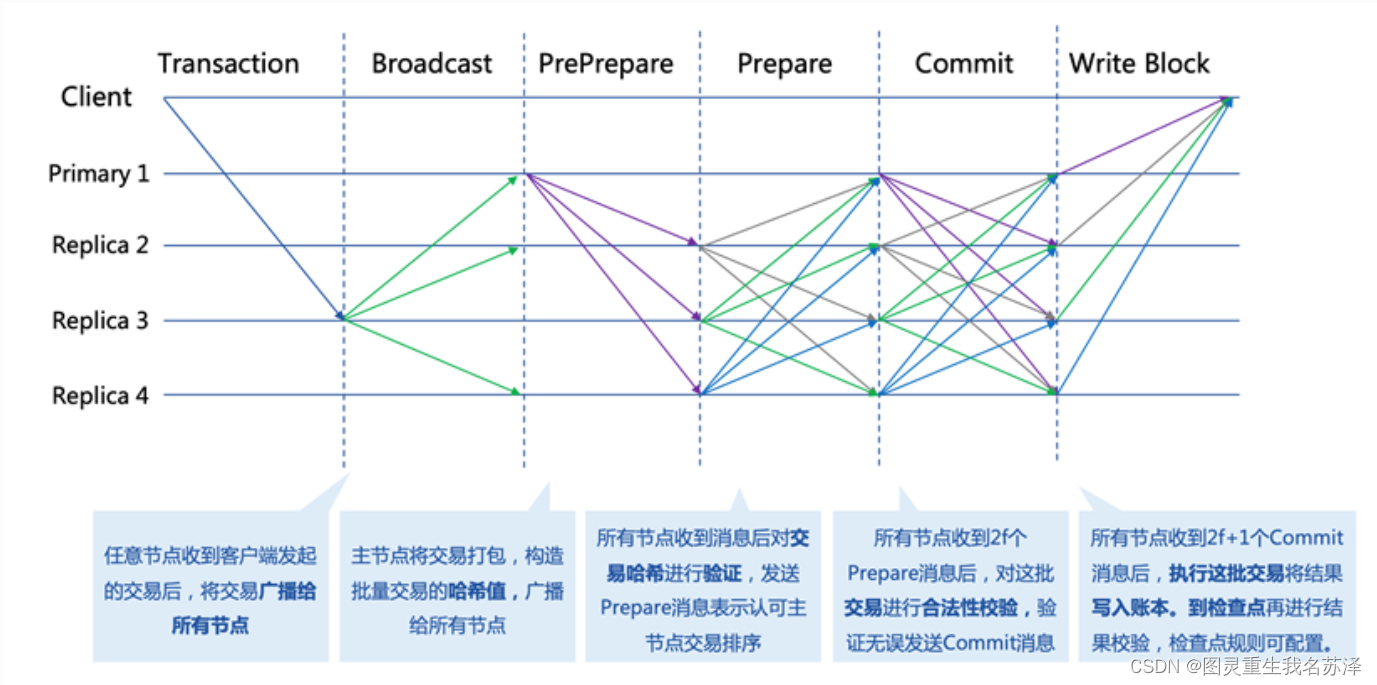
RBFT算法通常包含以下几个阶段:视图切换(View Change)、决策提案(Proposal)、验证和投票(Validation and Voting)、决策达成(Decision)。
- 视图切换(View Change):在RBFT算法中,主节点可能会出现错误或恶意行为。为了应对这种情况,备份节点可以通过视图切换机制选择新的主节点。在每个视图中,节点可以根据事先约定的规则来选择新的主节点。这个阶段的目标是确保主节点的正确性和可靠性。
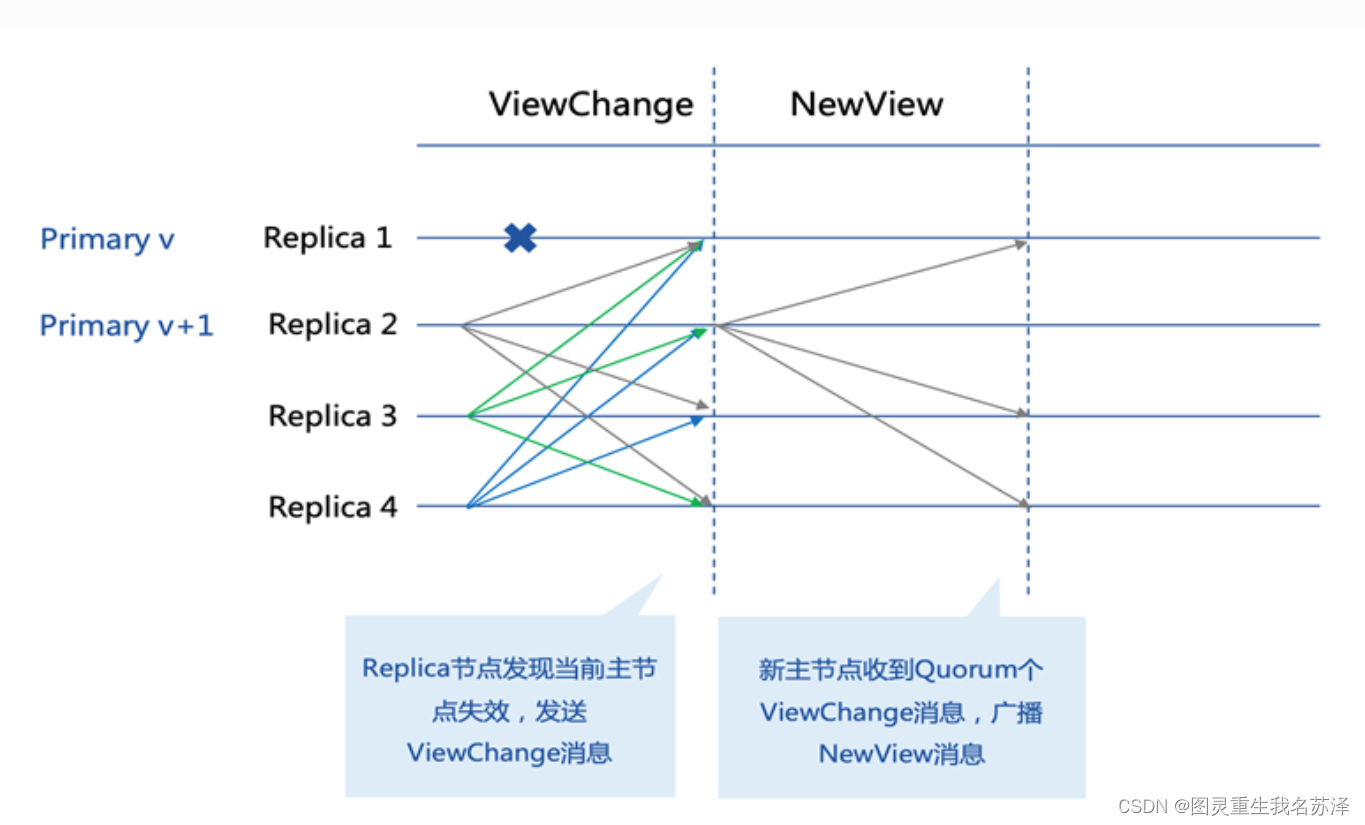
沿用之前的例子,假设主将军在某个轮次中发送了错误的决策或者出现了故障。备份将军可以触发视图切换,并通过约定的规则来选择新的主将军。
- 决策提案(Proposal):在RBFT算法中,主节点负责提出决策。主节点会根据一定的规则和条件提出进攻或撤退的决策,并将其发送给其他节点。
在我们的例子中,新选出的主将军会提出进攻或撤退的决策,并将其发送给其他备份将军
- 验证和投票(Validation and Voting):备份节点在收到主节点的决策提案后,会对其进行验证。节点会检查决策的合法性和正确性,并与其他节点进行比较。如果大多数节点对决策达成一致,它们将投票支持该决策。
在例子中,备份将军会验证主将军的决策,并与其他备份将军进行比较。如果大多数备份将军验证了相同的决策,它们会投票支持该决策。
- 决策达成(Decision):当大多数节点投票支持同一决策时,系统会达成共识并执行该决策。正确的决策将被传达给士兵,以便他们执行相应的行动。
在例子中,当大多数备份将军达成一致,并投票支持同一个决策时,该决策将被传达给士兵,以便他们执行进攻或撤退的行动。
通过这些阶段的组合,RBFT算法能够容忍主节点的错误或恶意行为,并通过多数投票的方式达成共识。这种机制提高了系统的容错性和安全性
当然了还有很多种不同的算法没有天下第一的算法 只有不同场景下相对的最优决策
常用的共识机制有PoW(Proof of Work)工作量证明,PoS(Proof of Stake)权益证明,DPoS(Delegated Proof of Stake委任权益证明,DBFT(Delegated Byzantine Fault Tolerance)等。
EOS
采用了委任权益证明,选出一些代表性的节点来进行投票,这种方式目的是优化社区投票的效率和结果,但带来了一些中心化的风险。
在研究EOS之前 我们先说说DPOS
假设将军的例子中,我们有三个节点分别代表将军A、将军B和将军C。现在我们将这个例子应用于上述提到的情况。
假设A是第一个出块的将军,然后是B,最后是C。现在,将军B决定进行分叉。在轮到将军B出块时,他不再承认将军C和将军A的块,而是自己单独出块。在这种情况下,B分叉出去的链每9秒才能出一个块,而C和A每6秒出一个块。在DPOS机制下,即使分叉,B仍然需要等待A和C都出块后才能继续出块。
因此,分叉出块的速度永远追不上原来链的速度,因为共识机制只承认最长的链。这意味着少数节点分叉的情况下,分叉的节点无法超过由其他节点认可的链的增长速度。
如果有三分之二的节点决定分叉,原理也是一样的。最后一个诚实的少数节点决定了最快、最长的链。分叉的节点无法追上由其他节点认可的链的增长速度。
在DPOS共识机制中,确定最长的链是通过"最后不可逆块"的概念实现的。最后不可逆块是指无法修改的最后一个区块。根据DPOS规定,当三分之二的节点确认一个区块时,它就成为不可逆块。如果最新出块的三分之二节点确认一个区块,那么它就是最后不可逆块。
通过最后不可逆块,可以确认这条链是否是由三分之二的节点签名的最长链。
总结来说,DPOS机制可以有效地防范拜占庭作恶,具有强大的拜占庭容错性。本例只列举了几种主要的作恶情况,而DPOS机制可以预防许多其他作恶情况,这里没有一一列举。
此外,交易作为权益证明(TaPOS)是指交易作为验证前一个块的数据的证明。当块数增加时,这条链很难被替代,因为修改一个块会导致所有的TaPOS值不匹配。
在EOS的DPOS机制中,通过定向广播来提高出块速度和性能。在比特股和STEEM等系统中,广播是随机的,谁先收到块就可以接力生成新的块。然而,EOS采用了定向广播,使得块的传播更加高效。这种机制使得EOS可以达到更快的出块速度(例如500毫秒)。
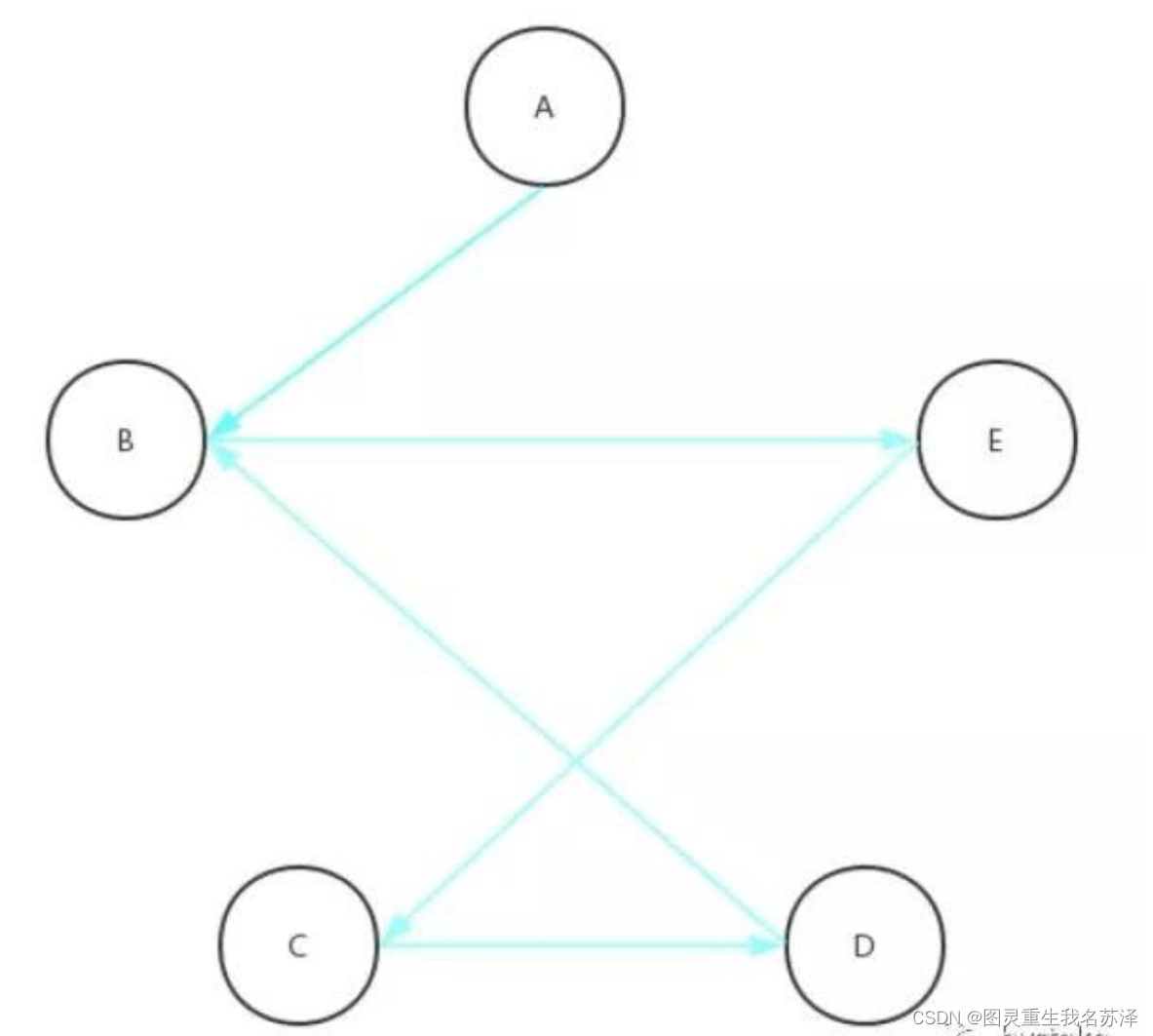
在上文提到,比特股的出块速度是3s,而EOS可以达到500ms。EOS能提高出块速度是因为定向广播。
因为是随机广播,所以会诞生很多同步一轮的区块路径不是最短路径。
而在EOS的机制下,节点是定向广播的。21节点的位置是透明的,会选择最短路径来规定广播顺序。如图:

DBFT
DBFT共识机制则是通过对节点分配不同的角色来达成共识,这样可以很大程度降低开销和避免分叉,但是也有核心角色作恶的风险。
NEO 在 PBFT(Practical Byzantine Fault Tolerance, 实用拜占庭容错)算法的基础上,提出了 dBFT(delegated Byzantine Fault Tolerance, 委托拜占庭容错)共识算法。算法根据区块链实时投票情况,决定下一轮参与共识的节点,有效降低了算法耗时,从而提高了出块速度,同时降低了交易确认周期。
共识术语
| 名称 | 定义 |
|---|---|
| 共识节点 | 具有发起新块提案和对提案投票权限的节点 |
| 普通节点 | 具有转账、交易权限和全网账本,但不能发起区块提案与投票 |
| 议长 | 负责向其他节点广播新块提案 |
| 议员 | 参与共识出块的账户,负责对新块提案进行投票 |
| 候选人 | 被提名有权参与共识节点竞选的账户 |
| 共识节点 | 从候选人中被选出的,参与共识的账户 |
| 视图 | 一轮共识从开始到结束所使用的数据集。视图编号 v,从 0 开始,本轮共识失败时 v 逐渐递增,直到新的提案通过后重置 |
共识消息
dBFT 2.0 算法包含 6 种共识消息:
| 名称 | 描述 |
|---|---|
| Prepare Request | 发起新一轮共识的信息 |
| Prepare Response | 用来通知其他节点已获取构建区块的全部交易信息 |
| Commit | 通知其他节点已获取了足够多的 Prepare Response |
| Change View Request | 尝试改变视图的信息 |
| Recovery Request | 同步共识状态的请求 |
| Recovery Message | 对 Recovery Request 的响应信息 |
共识流程
三阶段共识流程

我们可以使用刚才的将军的例子来解释这四个步骤。
假设我们有三个将军A、B和C,他们正在进行一轮共识。
-
议长发起共识,广播 Prepare Request(准备请求):
- 在这个步骤中,将军A被选为议长,并发出一个准备请求,表示他准备开始共识过程。
- 将军A广播这个准备请求给其他两个将军B和C。
-
接收到 Prepare Request 后,议员广播 Prepare Response(准备响应):
- 将军B和将军C接收到将军A的准备请求后,他们分别广播自己的准备响应。
- 这些准备响应表示将军B和将军C同意参与共识过程。
-
接收到足够多的 Prepare Response 后,共识节点广播 Commit(提交):
- 一旦将军A收到足够多的准备响应(例如收到了B和C的准备响应),他就会广播提交消息。
- 这个提交消息表示将军A确认共识已经达成,并准备继续下一步。
-
接收到足够多的 Commit 后,共识节点产生新块并广播:
- 一旦将军A收到足够多的提交消息(例如收到了B和C的提交消息),他们就开始生成新的区块。
- 生成的新区块包含了达成共识后的数据,并由将军A广播给其他节点,以便它们更新他们的链。
大致分为这么几步:
初始化本地共识信息,重置共识上下文:
- 这个步骤类似于将军们初始化并准备开始新一轮战斗。他们确定了将谁担任议长,并设置了超时时间。
各共识节点超时前监听网络,收集交易信息:
- 这个步骤类似于将军们在超时时间之前,收集关于战局和敌方动向的情报信息。
发起共识:
- 在这个步骤中,议长根据共识策略从内存池中选择交易,并将它们打包为准备请求(Prepare Request),然后广播出去,这相当于将军们发起了新一轮的战斗。
广播 Prepare Response:
- 在这个步骤中,议员们收到议长的准备请求后,进行验证并将准备响应(Prepare Response)广播出去,这相当于将军们对议长的命令作出回应。
收集 Prepare Response & 广播 Commit:
- 在这个步骤中,议长和接收到准备请求的议员们收集到足够多的准备响应后,进行验证并广播提交消息(Commit),这相当于将军们收集到足够多的回应后决定执行战斗计划。
收集 Commit 信息 & 出块:
- 在这个步骤中,已经收集到准备请求中交易信息的共识节点收集到足够多的提交消息后,进行验证并生成新的区块,然后广播出去,这相当于将军们根据战斗计划执行行动并取得胜利。
回到第 1 步,开始下一轮共识:
- 在这个步骤中,共识过程完成后,开始准备新一轮的共识,这相当于将军们完成一轮战斗后准备进入下一轮。
这样 我们就能对这个算法有一个初步的认知 但是实际的使用还要看具体的业务场景来判别

