
- 1安装Anaconda在d盘,那么新建环境(比如:tensorflow环境)就默认在d盘中的Anaconda的envs中/同理,安装python的依赖包,也会默认安装在ANACONDA的目录下_anoconda安装在d盘 之 安装tensorflow
- 2CAN上的E2E vs SecOC区别_secoc和e2e
- 3手把手教你解决 Git 冲突——微软 GitHub 课程_github 上启动学习实验室
- 4HarmonyOS Next 实现登录注册页面(ARKTS) 并使用Springboot作为后端提供接口_arkts能写后端吗
- 5python 情绪分析_python snownlp情感分析简易demo(分享)
- 6基于Java备考自习室预约管理系统-开题报告参考
- 7小程序图片上传功能_小程序post方式上传图片
- 8如何快速构建自己的AI客服 将GPT接入淘宝,抖店,拼多多,美团等电商平台 实现当前最强的客服机器人_轻简客服
- 9深入理解sed中的-n选项和-p选项的用法_sed -n
- 10HTML颜色编码和名称_html 红色
【机器学习300问】46、什么是ROC曲线?
赞
踩
一、二分类器的常用评估指标有哪些?
二分类器是机器学习领域中最常见的也是应用最广泛的分类器。评价二分类器的指标也很多,下面列出几个我之前重点写文章介绍过的指标。
(1)准确率(Accuracy)
定义为分类正确的样本数占总样本数的比例,在类别分布均匀的情况下,准确率是一个直观有效的评估指标,但在类别不平衡数据集上可能不能很好地反映分类器性能。
(2)精确率(Precision)
定义为被预测是正类的样本中实际为正类的比例,对于那些错判代价高的场景特别重要,例如医疗诊断中,高精确率意味着模型预测为阳性的结果中有很高比例确实是真实的病例。
(3)召回率(Recall)
定义为实际是正类的样本中被正确预测为正类的比例,在某些情况下,如罕见事件检测或安全预警系统中,高召回率至关重要,因为它反映了模型能否找出所有的正类实例。
(4)F1分数(F1 Score)
定义为精确率和召回率的调和平均数,用来同时考虑两者的表现。F1值在精确率和召回率之间取得平衡,通常用于综合评估分类器的效果。
如果友友们想细致了解上述指标,可以看看我的这篇文章:
【机器学习300问】25、常见的模型评估指标有哪些?![]() http://t.csdnimg.cn/g0aM0
http://t.csdnimg.cn/g0aM0
二、什么是ROC曲线?
ROC曲线(Receiver Operating Characteristic Curve)是一种直观且强大的可视化工具,用于评估和比较二分类模型(二分类器),在不同阈值条件下的表现好坏。他的中文直译是“受试者工作特征曲线”。
(1)先得知道几个概念
为了让概念生动活泼,我在这里全部用医院检测癌症的二分类任务说明。
| 名词 | 解释 |
| 阳性 | 当医学检测或测试预测出一个人患有癌症时,这个结果被称为阳性。阳性通常指标签为“是”的正分类结果。 |
| 阴性 | 如果检测或测试结果表明一个人没患癌症,那么结果是阴性。阴性通常指标签为“否”的负分类结果。 |
| 真阳性 | 当测试结果预测为阳性,并且这个预测是正确的(即该人确实患有癌症),则这样的结果称为真阳性。 |
| 假阳性 | 当测试结果预测为阳性,但这个预测是错误的(即该人实际上没有患癌症),则这个结果称为假阳性。 |
| 真阳性率 | 真阳性率,也称为召回率或灵敏度。是真阳性的数量除以实际全部阳性的数量(真阳性加上假阴性) |
| 假阳性率 | 假阳性率,也称特异度。是假阳性的数量除以实际全部阴性的数量(假阳性加上真阴性) |
(2)ROC曲线的定义
在ROC曲线图上,我们将假阳性率放在X轴上,真阳性率
放在Y轴上。每种可能的阈值对应图上一个点,连接这些点形成的曲线就是ROC曲线。
如上图所示理想的模型会有一条靠近左上角的曲线,因为这意味着在保持很低的误报率的同时,有着很高的正确发现率。图中虚线表示分类能力如同随机分类,分类器的ROC曲线越往左上角靠就越说明这个分类器效果好。
(3)举例说明
现在用我最喜欢的举例说明为大家介绍什么是ROC曲线。
假设有一家医院,现在需要诊断病人。有10位疑似癌症患者,其中有3位很不幸确实得了癌症(P=3),另外7位不是癌症患者(N=7)。医院对这10个疑似癌症患者做了诊断,诊断出了3位癌症患者,其中有2位确实是真患者(TP=2)。那么真阳性率是
。对于7位非癌症患者来说,有一位很不幸被误诊为癌症患者(FP=1),那么假阳性率是
。对于这个医院(二分类器)来说这组分类结果就对应了ROC曲线上的一个点
。
三、ROC曲线对比这些个常用指标有什么优势?
ROC曲线相对于其他一些常用的二分类评估指标,有以下优势。
(1)不依赖阈值
ROC曲线展示了分类器在所有可能阈值下的真阳性率(TPR,Sensitivity)和假阳性率(FPR,1-Specificity)的关系,因此,它允许我们观察模型在不同决策阈值下的性能而不受单一阈值影响,有助于我们在实际应用中根据业务需求选择合适的阈值。
(2)可以处理类别不平衡问题
ROC曲线的一个显著优点是对类别不平衡的数据集更稳健。即使正负样本比例变化,ROC曲线形状本身不会改变,因此可以帮助我们在不同样本分布下公平地比较不同模型的性能。
(3)直观全面且易于比较
ROC曲线提供了一个可视化工具,可以直观地比较不同分类器在区分正负样本上的整体能力。方便在同一坐标系下比较多个分类器的性能,只需查看它们各自的曲线位置及AUC值即可判断哪一个分类器性能更好。(关于AUC后续我还会单独出一篇文章来讲讲)
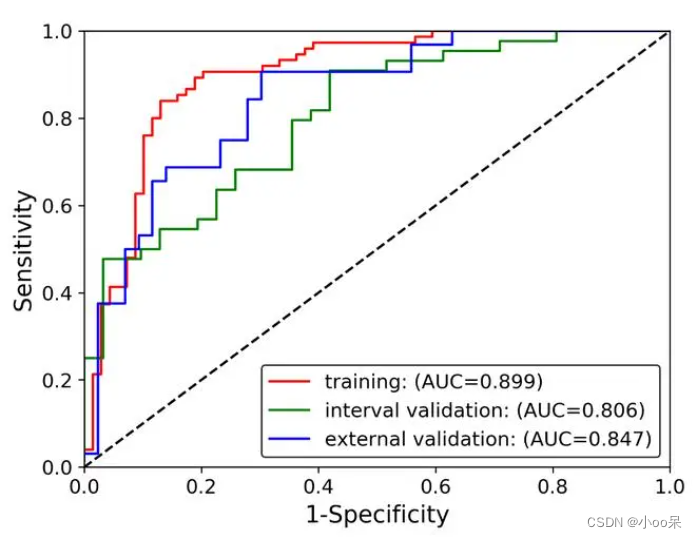
图中可以直观的看出,红色的模型(二分类器)分类效果最好!

