
- 1如何将平板或手机作为电脑的外接显示器?
- 22022年中国数据库排行榜年终盘点-墨天轮_摩天轮数据库排行榜
- 3Python 量化交易实战_python量化交易软件
- 4人脸检测之是否佩戴口罩检测_检测是否佩戴口罩应用的什么技术
- 5windows环境下在家用笔记本电脑本地部署并微调Gemma全流程记录_gemma windows电脑
- 6蓝桥杯系列1——python组真题_蓝桥杯python真题
- 7Bert MLM_bert 的mlm
- 8计算机视觉 - Attention机制(附代码)_计算机视觉中的attention
- 9微软edge离线下载_edge-tts 离线
- 10用 WebSocket 实现一个简单的客服聊天系统
ArcGis-字段计算器的使用方法与复杂应用--不定期更新建议收藏(计算字段、图形属性获取、关联计算、arcgis计算)_arcgis字段计算器
赞
踩
前言
本文章主要介绍ArcGis中字段计算器的使用方法,(含文本处理、数值处理、组合计算、多要素关联计算等)并结合实际案例,对具体的情况进行分析讲解。
由于Esri在ArcGis Pro中取消了VB脚本解析程序,本文章中实现复杂功能的情况主要使用Python解析程序。其他情形,vb和python都会有介绍。
若有疑问,或希望博主展开的部分,可评论留言。
更新记录:
2024.1.3:新增更新《2.4 图斑的复杂规则编号》(1复杂规则的编号;2整库更新标识码)
2024.2.19:新增《2.2.2 以固定分隔符拆分并提取文本》,原2.2.2章节编号递增;补充2.2.1章节内容;2.2.3中新增在ArcMap中使用正则表达式的注意事项。
文章内用词说明
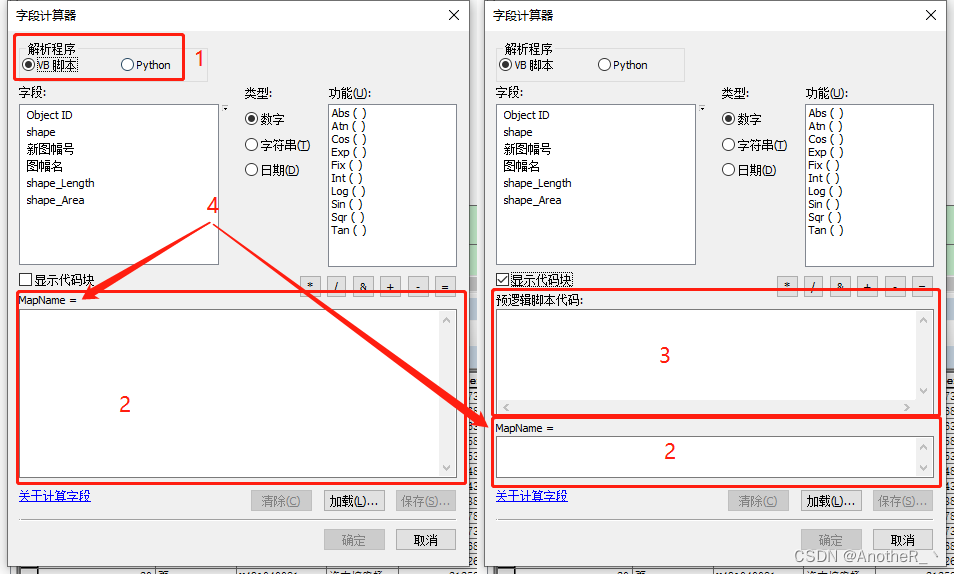
下图,字段计算器页面中:
1:解析程序; 2:表达式; 3:代码块;
4:被计算字段(右键点击并选择“字段计算器”的字段)
目录
1.1.字段计算器中的vb和python解析程序的介绍与区别
2.0.字段计算器中“代码块”的食用方法(仅python,有了解的可跳过)
2.3.从"A"要素中取值,维护"B"要素的字段(A的属性填入B)
2.4.2.案例2:在python环境下进行整库维护标识码(BSM)(非字段计算器)
一、字段计算器的初步应用
1.1.字段计算器中的vb和python解析程序的介绍与区别
vb和python分别对应的是两种不同的编程语言,字段计算器中的vb与Excel的函数大体上是比较类似的,如Excel内mid函数 =MID(A1,2,3) 对应在字段计算器中就为 mid([字段名称],2,3) ,但在python中就大不一样 !字段名称![1:4]。
- 提取 “abcdefg” 内的 “bcd”
-
- EXCEL: =MID(A1,2,3)
- VB: MID([字段名称],2,3)
- python: !字段名称![1:4]
1.1.1.不同解析程序对应的“空”值
VB:
nullPython:
None注:Shapefile 属性表内不允许存在“空”值。留空可在计算时引号内不留空
1.2.字段计算器的基本使用方法
1.2.1.简单值填入
例如:将下图中所有行的文本1字段内填写入“AAA”
计算前 计算后
计算后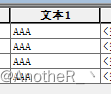
两种不同的解析程序如下:
vb: vb中填写入的文本,必须使用英文的双引号括起来,
"AAA"python: python中的文本单引号,双引号均可
- 'AAA'
- "AAA"
1.2.2.只计算一部分要素
可通过手动选择或按属性选择,选中需要计算的要素,再使用字段计算器即可。
例如:下图,将OBJECTID等于1或等于2的要素,文本test字段中填写入“test”
计算前
计算后
如上图,蓝色高亮选中要素的文本test字段中被填入“test”。表达式就不写了
1.3.处理文本(复杂案例见2.2)
1.3.1.文本的简单组合和提取
纯文本的组合:比较简单,就不上图片了,需要注意的是,在文本组合时vb和python的符号是不一样的。
- vb: [文本1] & [文本2]
- python: !文本1! + !文本2!
数值与文本组合:使用python时需要注意,将数值使用“str()”类型转换为文本类型,再做组合,否则会报错。
- vb: [文本1] & [数值1]
- python: !文本1! + str(!数值1!)
文本提取多为数据样例如下图:

例1:提取“文本1”字段中的前3位
表达式:
- vb: left( [文本1] ,3)
- python: !文本1![:3]
实现后的效果:

例2:提取“文本1”字段中的后3位
- vb: right( [文本1] ,3)
- python: !文本1![-3:]
实现后的效果:
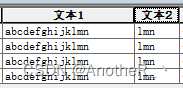
例3:提取“文本1”字段中从第5位开始向后取3位
- vb: mid( [文本1] ,5,3)
- python: !文本1![4:7]
实现后的效果:

1.3.2.python关于字符串提取的逻辑解释
为什么例1与例2中,python表达式内数值都与我们想提取的位数有关,而例3中,貌似与我们需要提取的位数并无关联。
原因在于,python对字符串取值的顺序与我们常规理解的不一致,如下图所示,字符串A-H与其位置对应关系图。绿色为从左至右的取值位,红为从右往左的取值位。
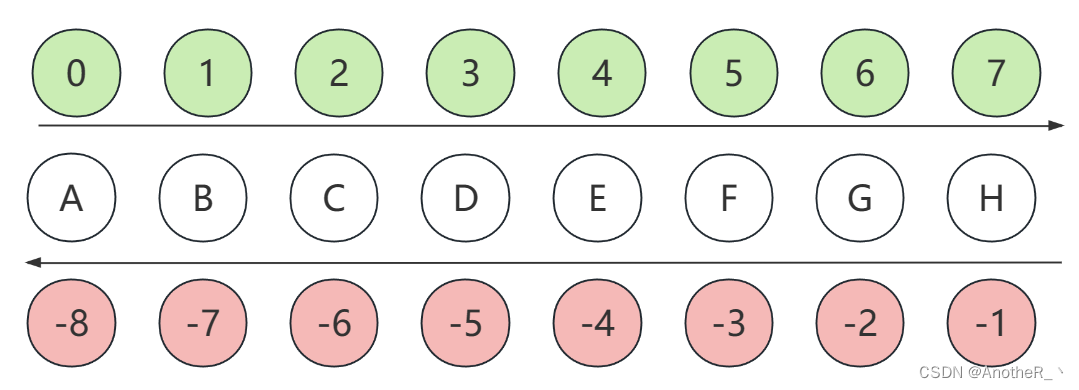
且使用 [起始位:结束位] 取字符时,取出字符串包含起始位,但不包含结束位,且起始位应当位于结束位左侧:
举几个例子:
- # 提取BCD
- # 例1:'ABCDEFGH'[1:4]
- # 例2:'ABCDEFGH'[-7:-4]
- # 例3:'ABCDEFGH'[1:-4]
- # 例3:'ABCDEFGH'[-7:4]
以上所有方式,均可返回字符串“BCD”
其他:
- # 只提取某一位
-
- 例1提取字符D:'ABCDEFGH'[3]
- 例2提取字符G:'ABCDEFGH'[-2]
-
- # 提取至结尾,或提取至开头
-
- 例1提取字符C之前的且不提取C:'ABCDEFGH'[:2]
- 例2提取字符B之后的且提取B:'ABCDEFGH'[1:]
- 例3提取字符F之后的且提取F:'ABCDEFGH'[-3:]
- 例4提取字符E之后的且不提取E:'ABCDEFGH'[-3:]
那么,做个题目吧,有一个不确定长度的字符串,前后都有一个下划线,如何提取下划线之间的内容呢?也就是头尾去掉一个字符(答案写在评论区了,笑)
二、复杂案例解析
(虽然本章节部分代码可直接使用,但仍建议对Python有初步的了解后再查看本节)
2.0.字段计算器中“代码块”的食用方法(仅python,有了解的可跳过)
2.0.1.代码块介绍
如下图,在勾选“显示代码块”后展开的输入框1 为“代码块”,输入框 2 为“表达式”,2 与未勾选时的输入框为相同输入框。图中为一个简单的通过调用自定义函数进行字段计算的简单示意。
代码块中:第一行的def 表示定义了一个函数,函数名称为 aa,且这个函数中 有一个名为b的参数。第二行的 return表示返回值,返回 b + 1的结果。
表达式:表示调用代码块中定义的 aa 函数,并将字段 !mj! 的值作为参数 b ,带入函数进行运算。
举例:如Excel中的 left 函数,它的函数名为“left” 它有两个参数,第一个是被提取的值,第二个是需要取值的位数。他的“代码块”已经在软件中内置好了,不需要我们定义,我们只需要在“表达式(单元格)”中输入他的函数名,并填写入所需要的变量,就可以了。 在字段计算器中,就相当于我们在“代码块”中自定义了一个函数。并在表达式中调用它。

2.0.2.通过字段计算器的代码块进行条件判断
数据来源字段如下图,需求,使用字段计算器进行判断,将面积大于1的标记为“面积大于1”,小于等于1的标记为“面积小于等于1”.
来源: 实现:
实现:

代码块及解释:
- # 定义函数 aa, 参数1个 名为 b
- def aa(b):
- # 条件判断,如果 b 大于 1
- if b > 1:
- # 如果 b 大于 1 返回 面积大于1
- return u'面积大于1'
- # 条件不成立
- else:
- # 返回 面积小于或等于1
- return u'面积小于或等于1'
其实还有一种简写的方法,直接在表达式内输入以下,也可实现单一条件判断:
u'面积大于1' if !mj! > 1 else u'面积小于或等于1'思考:如果不用条件判断的方法,使用其他的工具配合,是否可以实现示例中的效果?
当然,也可以有多条件判断。但如果
2.1.获取图形的属性(面积、长度、XYZ)
在使用arcgis的过程中,你是否有发现在 shp文件 和 要素类的属性表中,总会存在一个名为“Shape”的字段,而且该字段不可以编辑或者删除。
其实这个字段不是如显示的一样,存储的是(点、线、面)的文字,属性表中“Shape”字段储存的是该条属性对应图形的属性信息。并且属性可以通过字段计算进行调用(不可修改)。调用表达式如下(python):
坐标获取:
- # 获取要素重心点坐标(点要素不可使用)
- !shape.trueCentroid.X! # 重心点x
- !shape.trueCentroid.Y! # 重心点y
-
- # 获取坐标(图形外接矩形4角坐标)
- !shape.extent.XMax! # 最大x
- !shape.extent.XMin! # 最小x
- !shape.extent.YMax! # 最大y
- !shape.extent.YMin! # 最小y
-
- # 点要素 x y z 获取
- !shape.X!
- !shape.Y!
- !shape.Z!
面积、周长获取:(再也不用“计算几何”了。笑)
- # 计算面积(单位与要素坐标系一致)
- !shape.area!
-
- # 计算椭球面积
- !shape.geodesicArea!
-
- # 计算周长(长度)
- !shape.length!
杂项:(可以进行简单的质检)
- # 判断要素是否为多部件(布尔值)(可判断空洞)
- !shape.isMultipart!
-
- # 获取要素部件数量(要素内有空洞仍记为1,无法区分空洞)
- !shape.PartCount!
-
-
- # 获取要素的折点数量
- !shape.pointcount!
2.2.文字提取(复杂情况)
2.2.1.提取以特定字符开头或结尾的文本。
案例说明:下图中,省与市的名称长度均不固定(行政区名称均已省或市结尾,不考虑特殊情况),分别提取省、市的名称。

案例分析:调查机构(DCJG)字段内填写的文字结构为某省某市,可以通过(index)找到“省”字所在位置,向前与向后提取文字。
python表达式:
- # 提取省的名称:
- !DCJG![:!DCJG!.index(u"省") + 1]
-
- # 提取市的名称:
- !DCJG![!DCJG!.index(u"省") + 1:]
-
解释:
@ 在 "省" 前面加 u 的原因:因为argis储存字符串是以 utf-8 的格式进行存储,且arcmap 的python版本为 2.7,在使用方法或函数处理汉字时,需要在前面加一个 u 表示字符串为utf-8编码
arcgis pro 不需要加
@ !DCJG!.index(u"省") 会返回“省”这个字符,在字段 !DCJG! 中的位置。
@ 通过 !DCJG![位置 : ] 或 !DCJG![ : 位置] 的方式提取前后的文本
那么,问题来了,为什么需要“位置+1”呢?提取省和提取市的“位置+1”原因是否一样?(1.3中有讲到)
结合1.3与本小节内容,是否可以提取规则为“xxxx起始xxxxx终止xxxx”的文本中,“起”到“止”之间的文本呢?
2.2.2.以固定“分隔符”拆分并提取文本
案例说明:下图中,“坐标”字段储存了点位的坐标信息,x,y,z坐标之间通过分号“;”进行分隔。需求:分别提取其中的x,y,z坐标,并将其存放于单独的字段中,且储存坐标的字段的类型需为双精度。

案例分析:本案例中需要提取的内容,由统一的字符分隔,可以使用 split 将字符串以特定的分隔符拆分为列表(list),并分别取用。split使用效果如下:
- '562873.938;3539624.743;331.461'.split(';')
- # 输出结果为:['562873.938', '3539624.743', '331.461']
提取x坐标的python表达式:
- float(!坐标!.split(';')[0])
- # 因为存储在列表中的坐标,仍然为字符串,所以需要用float将其转换为双精度数值
那么,问题来了,提取y,z坐标的表达式应该修改哪个部分呢。(*^_^*)
拓展:如果字段中分隔符的数量并不一致,如某些行中缺少,Z坐标。在使用以上方法获取Z坐标时会报错,导致整个计算工作无法执行。此时可以使用try,在程序异常时可继续执行,并返回0。
python表达式:
aa( !坐标! )代码块:
- def aa(a):
- try:
- return float(a.split(';')[2])
- except:
- return 0
2.2.3.使用正则表达式处理符合规则的字符
案例说明:数据来源字段如下图,要求提取其中的数值,并将其填入双精度字段。

案例分析:因为此类情况比较复杂,面积数值是不固定的,且数值前、后的字符数量也不固定,本文介绍的其他方法无法解决此情况。此类情况可采用正则表达式来对字符进行提取。
由于在python中使用正则表达式,需要引入 re 模块,所以得使用 代码块来配合实现。

代码块与代码说明:
- # 引入 re 模块
- import re
- # 定义函数,名为 aa , 变量为 in_str
- def aa(in_str):
- # 使用正则表达式 按规则进行提取
- mj_str = re.search(r'\d*\.\d*', in_str).group()
- # 由于被计算字段类型为双精度,所以将正则表达式提取的str类型的面积 转为 float 类型
- mj_float = float(mj_str)
- # 返回面积
- return mj_float
正则表达式太深奥,再这里仅作介绍,如有需要可自行查询。
注意:在arcmap中使用正则匹配中文时,因为python版本为2.7,字符串的默认编码格式为ASCII编码,需使用compile编译正则表达式,否则无法正常使用。compile示例:
- # coding=utf-8
- import re
- def ss(text):
- cp = re.compile(u'[\u4e00-\u9fa5]+')
- va = re.findall(cp, text)
- result = ''.join(va) if va else ''
- return result
2.3.从"A"要素中取值,维护"B"要素的字段(A的属性填入B)
(代码可直接使用,且比较通用,但仍建议会一点点python再观看本节)
如下如,现有 要素A 和 表B ,通过计算 表B 的 MJ 字段,汇总 要素A的地类名称等于 表B 中DL 字段的 图斑面积之和。
其实这个目标,可以使用工具实现(那么,需要使用哪些工具呢?笑),本小节仅对字段计算实现的另一种方式进行探讨。
要素A: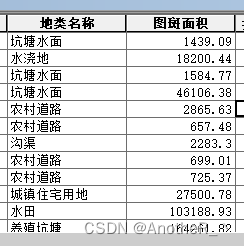 表B:
表B: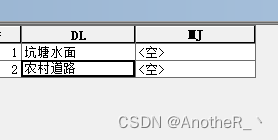
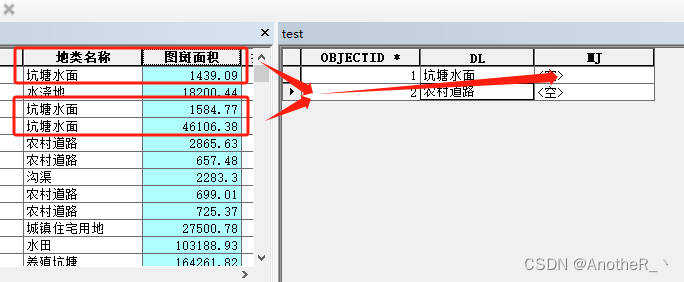
实现方式:通过使用arcpy游标遍历 要素A,汇总面积,并将结果通过 global 在自定义函数内调用。维护 表B 的 MJ 字段。
表达式:
aa(!DL!)代码块:
- # 引入 arcpy 模块
- import arcpy
- # 定义 要素A 的路径(自定义部分)
- fc_A = u'C:\\ArcGIS\\Default.gdb\\A'
- # 定义储存面积的字典
- mj_dict = {}
-
- # 查询游标 遍历 要素A
- cursor = arcpy.SearchCursor(fc_A)
- for row in cursor:
- dlmc = row.getValue('DLMC') # 获取地类名称(分组字段-自定义部分)
- tbmj = row.getValue('TBMJ') # 获取面积(汇总字段-自定义部分)
-
- if dlmc not in mj_dict.keys(): # 字典维护
- mj_dict[dlmc] = 0
- mj_dict[dlmc] += tbmj # 字典维护
-
- # 自定义函数, 变量 a 用于储存 表2 中的 "DL"字段值
- def aa(a):
- global mj_dict # 引入全局变量
- if a in mj_dict.keys():
- return mj_dict[a] # 维护值
- else:
- return 0 # 如果不存在,返回 0

使用arcgis工具实现的话,可以先用“汇总统计数据”按地类名称分组汇总面积。然后再将结果与表B,通过匹配“地类名称和DL”字段进行“连接字段”。
2.4.图斑的复杂规则编号
2.4.1.案例1:重复值顺序编号,不重复情况特殊处理
要求:如下表中,填写“单元支号”字段,为“单元号”进行同值顺序编号。
若“单元号”存在重复,则从“001”开始,为相同值进行顺序编号; 若“单元号”的值不存在重复,则“单元支号”填入“000”。
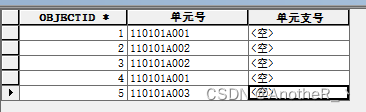
实现思路:此要求其实与常规的“同值顺序编号”基本类似①,仅多出一步对不重复的值进行单独赋值“000”②。
①首先,我们可以编写一个简单的重复值编号函数。
表达式:
aa(!单元号!)代码块:
- # 定义一个用于计数的字典
- count_dir = {}
- def aa(dyh):
- # 将字典引入函数
- global count_dir
- # 如果字典中不存在该单元号(键),则添加该键并将其值设为0
- if dyh not in count_dir.keys():
- count_dir[dyh] = 0
- # 计数
- count_dir[dyh] += 1
- # 返回文本类型的编号,并补0至3位
- return str(count_dir[dyh]).zfill(3)
运行结果:如下图,实现了对“单元号”相同的图斑进行了顺序编号。

但未实现题目中“单元号不存在重复时,填写000”的要求。如最后一行“单元号” 110101A003 仅存在一个,但“单元支号”为001。
②下一步开始实现对不重复的情况处理:
表达式:与上一步相同
代码块:(在上一步的基础上进行新增和修改)
- # ------新增部分(开始)-------
- # 导入 arcpy 包
- import arcpy
- # 填写被计算要素的路径
- fc_path = u'D:\\测试\\test.gdb\\TB' # 填写规则见下文中说明
- # 使用arcpy中SearchCursor查询游标 获取所有单元号 并建立列表(list)
- dyh_list = [row.getValue(u"单元号") for row in arcpy.SearchCursor(fc_path)]
- # ------新增部分(结束)-------
-
- # 定义一个用于计数的字典
- count_dir = {}
- def aa(dyh):
- # 将字典引入函数
- global count_dir, dyh_list # (新增引入存放所有单元号的列表)
- # 如果字典中不存在该单元号(键),则添加该键并将其值设为0
- if dyh not in count_dir.keys():
- count_dir[dyh] = 0
- # 计数
- count_dir[dyh] += 1
-
- # 原 return 语句
- # return str(count_dir[dyh]).zfill(3)
-
- # ------新增部分(调整return规则)-------
- # 判断 如果 单元号 在 列表 中只出现过一次(不重复的情况)
- if dyh_list.count(dyh) == 1:
- # 则填入“000”
- return "000"
- else:
- # 与原 return 语句一致
- return str(count_dir[dyh]).zfill(3)
运行结果:此时最后一行 “单元号”为110101A003 的 “单元支号”就被编为“000”了。

关于上方代码块内路径的说明:
若你使用的时ArcMap 10.X ,对应的python版本是2.7。若在路径中存在中文,则必须添加 “u”(表示使用unicode编码),且路径中的分隔符需用“\\”双斜杠。
若使用的是arcgis pro 任意版本,无需对中文进行特殊处理,仅在字符串前加“r”(表示不进行转义)即可(无需双斜杠)。
- # ------示例-------
- # arcmap 10.x
- # 路径中存在中文的情况(字符串前加 u ;双斜杠分隔)
- fc_path = u'D:\\测试\\test.gdb\\TB'
- # 不存在中文的情况(调用部分函数可能出现错误,若出现可按存在中文的情况下调整)
- fc_path = r'D:\test\test.gdb\TB'
-
- # arcgis pro
- fc_path = r'D:\test\test.gdb\TB' # 任意情况
2.4.2.案例2:在python环境下进行整库维护标识码(BSM)(非字段计算器)
如本小节标题,为个数据库的标识码字段进行编号,所有要素之间编号不重复。
代码如下:(注,此处只遍历了所有要素类,并未获取表)此代码会替换掉原始“编号字段”内的所有内容,请注意备份数据。
- # 导入 arcpy os包
- import arcpy, os
- # 待编号的数据库路径
- data_path = u'D:\\测试\\xxx.gdb' # 填写规则见上一节
- initial = 0 # 编号的初始值
- fd_name = "BSM" # 需要编号的字段名
- # 定义工作空间
- arcpy.env.workspace = data_path
-
- # 获取所有的要素数据集
- datasets = arcpy.ListDatasets(feature_type='feature')
- datasets = [''] + datasets if datasets is not None else []
-
- # 遍历要素数据集
- for ds in datasets:
- # 遍历要素数据集中的所有要素类
- for fc in arcpy.ListFeatureClasses(feature_dataset=ds):
- # 拼接得到要素的路径
- fc_path = os.path.join(arcpy.env.workspace, ds, fc)
-
- # 判断要素类中是否存在 标识码 字段
- if fd_name in arcpy.ListFields(fc_path):
-
- # 使用 UpdateCursor 更新游标 遍历 要素类的所有行
- cursor = arcpy.UpdateCursor(fc_path)
- for row in cursor:
- # 修改值 可使用 “str(initial).zfill(数值)” 在编号前补零 但字段类型必须为 文本
- row.setValue(fd_name, initial)
- # 更新
- cursor.updateRow(row)
- # 编号 +1
- initial += 1
可复制入arcmap的python窗口下运行:(位置如下图)
运行时建议,无论是否修改,先将代码复制入文本文档,再复制入python窗口内运行。(运行需按两下回车键“enter”)
其他:
1.不同类型的数据在使用字段计算器时的注意事项
部分数据类型无法实现,在计算字段时,值字段内包含被计算字段(有点绕)。示例如下:
@数据情况:有两个字段,一个是类型,一个是编号。
@目的:只使用1次字段计算器,将类型和编号字段的拼接值填写入编号字段。
计算前 计算后
计算后 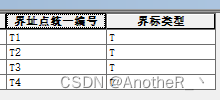
Python:
!类型! + !编号!@此时,计算字段既要从编号字段提取值,又要向编号字段内填写值。
若使用pythohn解析程序计算时需要用到这种方法,请注意mdb(个人地理数据库)内所有类型的要素或表格,均无法使用此方法。VB解析程序无此情况。

