
- 1八数码算法研究(转载)_启发函数事例移动牌
- 2pid巡线算法程序_EV3 双光感比例算法巡线 ——李老师大讲堂第22期 (更新scratch模式)...
- 3hbase的并发控制机制_hbase如何处理并发更新
- 4Android_studio入门之Linearlayout+基本初级语法_androidstudio常用的语句
- 5FluxMQ:新一代国产高性能 MQTT 云原生的 IoT 物联网网关
- 6计算机网络设计校园网实验报告,计算机网络课程设计实验报告---校园网网络构建方案设计和实现...
- 7v-text 和v-html
- 8谈一谈React的setState的执行机制
- 9中文医学大模型“本草”(原名华驼):医学知识增强在中文大型语言模型指令微调上的初步探索...
- 10pytorch练习一MNIST_download_mnist = false if not(os.path.exists('./mn
c++gdal如何在大图像中截取小图像并获取其图像信息_【图像分类】细粒度图像分类...
赞
踩

细粒度图像分类问题是计算机视觉领域一项极具挑战的研究课题,本文介绍了细粒度图像分类算法的发展现状、相关数据集和竞赛,供大家擦考学习。
作者&编辑 | 郭冰洋
1 简介

细粒度图像分类是在区分出基本类别的基础上,进行更精细的子类划分,如区分鸟的种类、车的款式、狗的品种等,目前在工业界和实际生活中有着广泛的业务需求和应用场景。
细粒度图像相较于粗粒度图像具有更加相似的外观和特征,加之采集中存在姿态、视角、光照、遮挡、背景干扰等影响,导致数据呈现类间差异性大、类内差异性小的现象,从而使分类更加具有难度。
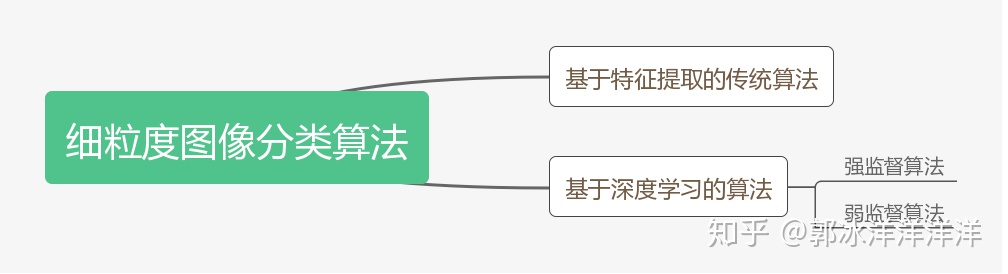
细粒度图像分类研究,从提出到现在已经经历了一段较长时间的发展。面对这一挑战,人们在粗粒度图像分类模型的基础上进行了更加细致的研究和改进,大致可以分为基于特征提取的传统算法和基于深度学习的算法。早期的基于特征提取的算法,由于特征的表述能力有限,分类效果也往往面临很大的局限性。近年来,随着深度学习的兴起,神经网路强大的特征提取能力促进了该领域的快速进步。
2 基于特征提取的传统算法
1、局部特征
早期基于人工特征的细粒度图像分类算法,其研究重点为图像的局部特征,一般先从图像中提取某些局部特征,然后利用相关编码模型进行特征编码。
由于局部特征选择过程繁琐,表述能力有限,其自身也存在一定缺陷,即忽略了不同局部特征之间的关联以及与全局特征之间的位置空间关系,因此并没有取得令人满意的结果。
2、视觉词包
为了进一步提升分类精度,相关人员在局部特征的基础上又进一步提出视觉词包(BOVW)的概念。通过统计图像的整体信息,将量化后的图像作为视觉单词,通过视觉单词分布来描述图像内容。
词包模型与一系列特征提取算法进行融合,虽然取得了一定的进展,但距离实际应用要求还有很远的距离。同时,构建词包的过程非常复杂,需要额外的处理工作。
3、特征定位
局部特征和视觉词包都没有构建与全局特征之间的关联,只在图像的部分区域进行语义挖掘,因此人们提出对特征进行定位,如利用关键点的位置信息发现最具价值的图像信息。
通过位置信息的辅助,分类精度也得到了一定的提高,但是位置信息的获取需要高精度的算法来完成,同时还需要精细的人工标注,其成本更大。
3 基于深度学习的算法
随着深度学习的兴起,从神经网络中自动获得的特征,比人工特征具有更强大的描述能力,在一定程度上极大地促进了细粒度图像分类算法的发展。
根据监督方式的不同,该类算法可以分为强监督和弱监督两种类别。
1、强监督细粒度图像分类
强监督利用bounding box和key point等额外的人工标注信息,获取目标的位置、大小等,有利于提升局部和全局之间的关联,从而提高分类精度。
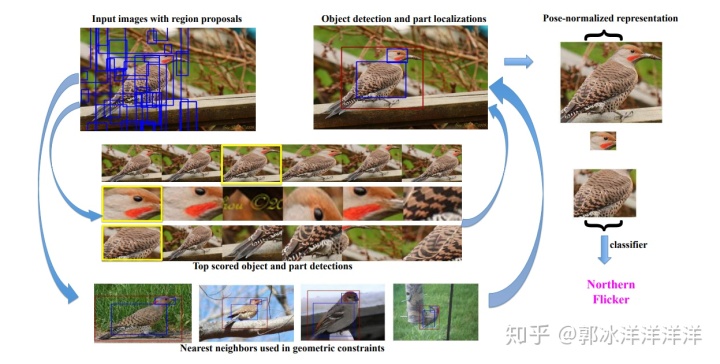
Part-based R-CNN基于R-CNN算法完成了局部区域的检测,利用约束条件对R-CNN提取到的区域信息进行修正之后提取卷积特征,并将不同区域的特征进行连接,构成最后的特征表示,然后通过SVM分类器进行分类训练,该算法在CUB-200数据集上取得了73.9%的精度。
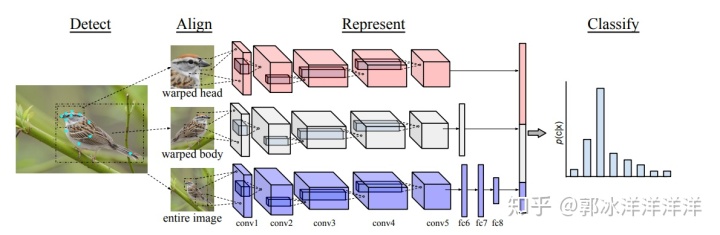
Pose-normalized CNN首先对每一张图片进行局域位置的检测,然后将检测框内的图像进行裁剪,从而提取不同层次、不同位置的图像,再对提取到的图像块进行姿态对齐送入CNN,将得到的特征拼接后利用SVM分类器进行分类,该算法在CUB-200数据集上取得了75.7%的精度。
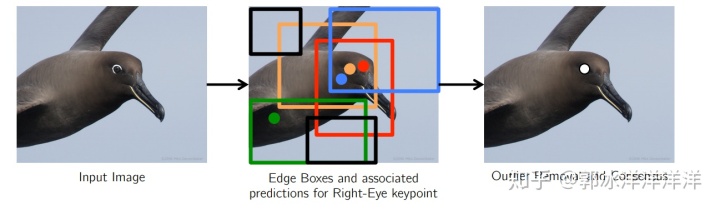
Multi-proposal Net则通过Edge Box Crop方法获取图像块,并引入关键点及视觉特征的输出层,进一步强化了局部特征与全部信息直接的位置关联,该算法在CUB-200数据集上取得了80.3%的精度。
2、弱监督细粒度图像分类
弱监督即仅利用图像的类别标注信息,不使用额外的标注。该方法又可以总结为图像过滤和双线性网络两类。
(1)图像过滤
图像过滤的思想和强监督中利用bounding box的方法类似,只不过仅借助于图像的类别信息过滤图片中与物体无关的模块,其中比较有代表性的即Two Attention Level算法。
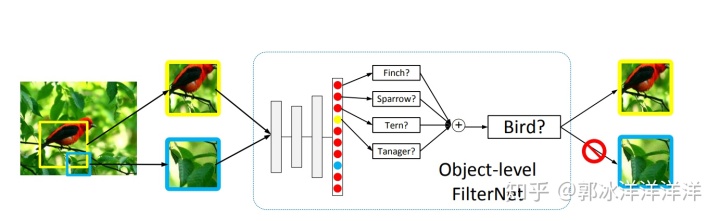
Two Attention Level利用物体级和局部级的信息,通过Search Selective算法过滤掉无关背景,然后将过滤掉的背景送入CNN网络进行训练,得到物体级别的分类结果,随后通过聚类算法将不同位置的特征继续区分,并将不同区域的特征拼接后送入SVM分类器进行训练,该算法在CUB-200数据集上取得了75.7%的精度。
在此方法的灵感上,后续诸多算法开始研究如何更好、更有效地对图像无关背景完成过滤,从而获取到更有效的目标特征信息。
(2)双线性网络
人在认知物体和事物时,往往需要完成对其特征的理解以及类别名称的记忆,为了使神经网络具有更强大的学习能力,B-CNN创新性的提出了一个全新的概念。
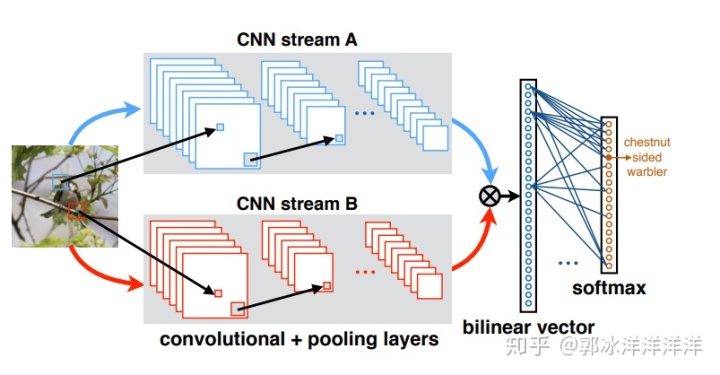
B-CNN根据大脑工作时同认知类别和关注显著特征的方式,构建了两个线性网络,协调完成局部特征提取和分类的任务,该算法在CUB-200数据集上取得了84.1%的精度,不过该方法在合并阶段会产生较高的维度,使得整个计算开销非常大。
后续的双线性网络将改进方向放在了设计更好的双线性汇合过程以及精简双线性汇合,以减少计算开销,同时提升分类精度。
介绍完主要的思想方法,现将近年来基于深度学习的相关算法在CUB-200数据集上所取得的成绩进行罗列,供大家查阅。
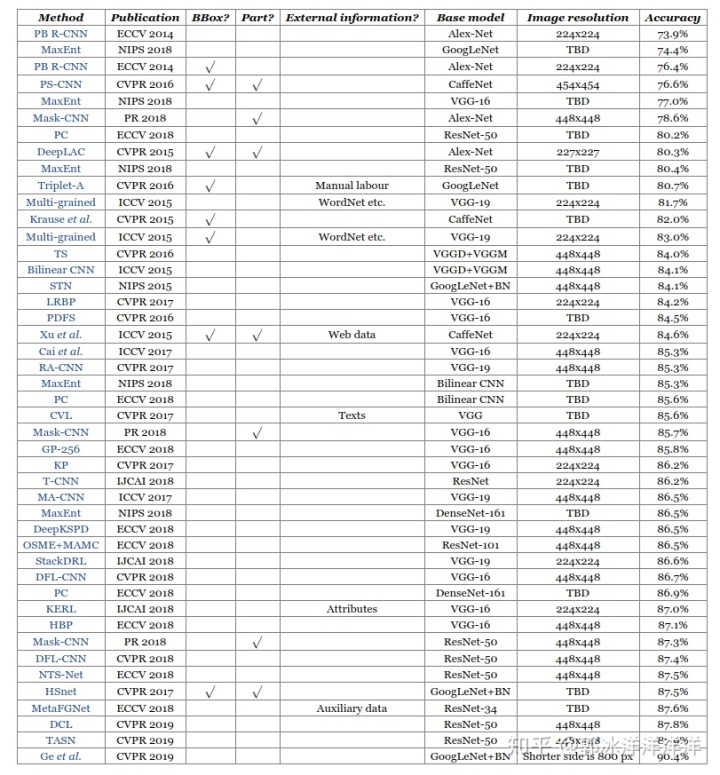
通过准确度排行列表我们可以看到,想要实现真正的应用,细粒度图像分类还有很长的一段路要走。
4 数据集
相对于粗粒度图像分类任务的数据集,细粒度图像数据获取难度要更大一些,其搭建往往需要更加专业的相关知识。近年来,越来越多的细粒度数据集出现,这也侧面反应了这一领域的发展势头和实际需求。
1、CUB-200
CUB-200是细粒度图像分类领域最经典,也是最常用的一个数据库,共包含200种不同类别、11788张鸟类图像数据。同时,该数据库提供了丰富的人工标注数据,每张图像包含15个局部区域位置、312个二值属性、1个标注框 以及语义分割图像。
2、Stanford Dogs
作为Stanford数据库的系列之一,该数据库提供了120种不同种类的狗的图像数据,共有20 580张图,只提供标注框这一个人工标注数据。
3、Stanford Cars
在对狗的不同类别进行构建后,Stanford团队又对车辆进行了详细的汇总和收集,提供196类不同品牌不同年份不同车型的车辆图像数据,一共包含有16185张图像,只提供标注框信息。
4、Oxford Flowers
Oxford团队构建的花朵数据库共包含102种类别,每个类别包含了40到258张图像数据,共有8189张图像。该数据库只提供语义分割图像 , 不包含其他额外标注信息。
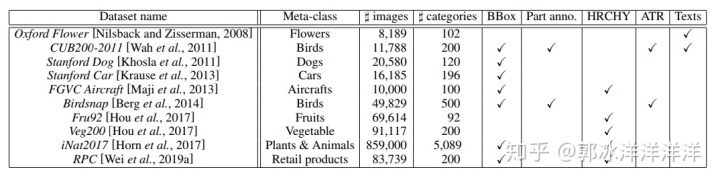
除了上述四个数据集,相关数据集还有很多,如下表所示,在此不再一一进行细述。
5 竞赛
随着人们对细粒度图像分类的越来越重视,相关赛事也在如火如荼的开展当中。

2011 年,谷歌开始赞助举办第一届FGVC Workshop,之后每两年举办一次,到 2017 年已经举办了四届。由于近年来计算机视觉的快速发展,FGVC 活动影响力也越来越大,自2018年开始由两年一次改为了一年一次。
FGVC竞赛侧重于子类别的详细划分,每届赛事都包含了多个主题,涵盖了动物种类、零售产品、艺术品属性、木薯叶病、腊叶标本的野牡丹科物种、来自生命科学图片的动物物种、蝴蝶和蛾物种、菜肴烹饪以及博物馆艺术品等多个事物的细粒度属性。
除了FGVC以外,Kaggle也举办了许多以家具、动物为主题的细粒度图像分类竞赛。
竞赛的举办在一定程度上促进了数据集的扩充,同时发掘了更多、更有效的细粒度分类算法,为该领域的进一步发展做出了重大贡献。
6 总结
作为计算机视觉领域一项极具挑战的研究课题,细粒度图像分类的发展远远没有达到粗粒度图像分类的精度,在深度学习日渐繁荣的今天,如何更有效地解决这一问题,也是图像分类领域的一大突破重点。

