
- 1如何使用 pyinstaller 将 python3 文件打包成可以执行的 exe 程序_pyinstaller - f - ntest _ exetest . py ",
- 2基于Python爬虫广东广州水酒店宾馆数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 32018年人工智能之自动驾驶研究报告_navlab-5
- 4NLP实战:基于Pytorch的文本分类入门实战_build_vocab_from_iterator
- 5最近学习的一点感想(关于 Flask、Django、SpringBoot)_flask和springboot哪个难
- 6NLP(六十六)使用HuggingFace中的Trainer进行BERT模型微调
- 7AWS-EKS 给其他IAM赋予集群管理权限
- 8用chatglm实现code interpreter_self.model = automodel.from_pretrained(model_path
- 9每次看到她写的代码,我都感到自己无比平庸_justine tunney
- 10GPT-4强到离谱,OpenAI首席科学家:开源并不明智,我们错了!
山东大学软件学院2022-2023第二学期自然语言处理期末考试回忆版_自然语言处理期末考试试题
赞
踩
山东大学软件学院2022-2023第二学期自然语言处理期末考试回忆版
前言
1、考试时间:2023/6/13 14:00 – 16:00
2、考试科目:自然语言处理(老师:SunYuQing)
3、考题语言:中文
4、考试形式:闭卷
5、题型:概念、算法、拓展
6、考后感悟: 平时作业题里有一部分是原题,还是要看看的。…………………然后。。。…………其他的……………………尽力吧。……算法………公式………真的很难背啊。。。。(还有CSDN上人工智能专业的NLP考试回忆大多是青岛校区的,参考意义不大。(怨种就是我了,看了很长时间。))
7、这里放个复习笔记吧, 仅供参考。
NLP期末复习
访问密码 hard
一、(15’)
描述Skip-gram模型训练过程,写出详细公式。
答:


二、(25’)
文本序列标注问题是什么?从模型假设和计算方式说明CRF 和HMM的不同。写出HMM的前向算法和后向算法的步骤,写出计算公式,并说明其中符号的意义。
答:
1、文本序列标注问题,即给定一个输入序列,使用模型对这个序列的每一个位置标注一个相应的标签,是一个序列到序列的过程。
2、不同:
模型假设:HMM有严格的独立性假设条件;而CRF没有,因而可以容纳任意的上下文信息,特征设计灵活。
计算方式:HMM求解过程可能是局部最优,CRF可以全局最优。
3、


三、(20’)
请写出分词任务的评价指标公式,给出正确情况和错误情况的详细说明。
写出基于最大概率的词典匹配算法。
答:
1、评价指标公式:


2、正确情况及错误情况说明:
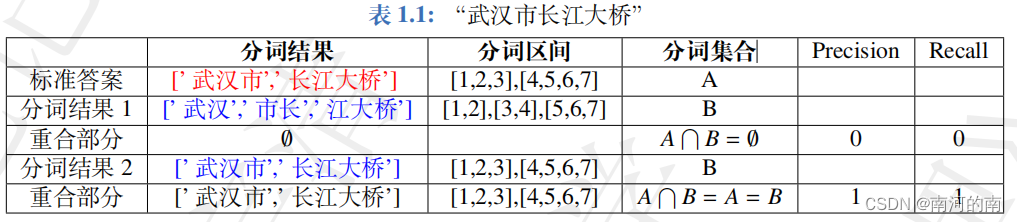
针对上述例子“武汉市长江大桥”的分词结果 1,精准率和召回率均为 0,因为没有重合部分。对于分词结果 2 来说,算法预测样本中与真实标注一致,精准率和召回率均为 1。
3、基于最大概率的词典匹配算法:
步骤 1:基于前缀词典算法,实现高效的词图扫描,找出句子中所有可能成词情况,生成有向无环图 (DAG)。
步骤 2:采用动态规划查找最大概率路径, 即找出基于词频的最大切分组合。


四、(15’)
写出词法分析CYK算法的过程。
答:

五、(10’)
说明机器翻译中评价指标 METEOR 及 BERTScore 的计算公式 ,并说明其中符号的意义。
答:
1、METEOR:
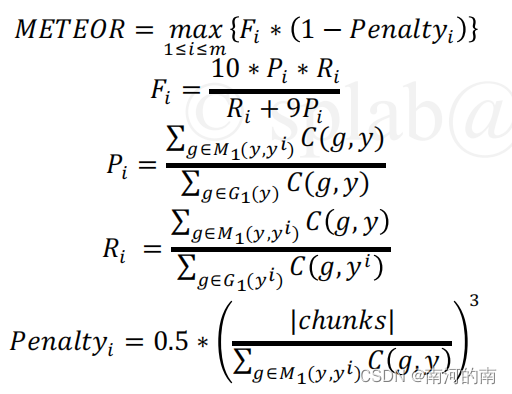
chunk表示匹配的元组块集合;Penalt yi是惩罚项; Pi是精准率;Ri是召回率;C(g,yi) )表示元组g在参考⽂本yi 中的出现次数
2、BERTScore

六、(15’)
什么是语言模型?说明主流语言模型的训练方式,并说明缺点。
答:
1、语言模型是建模“预测一个语言样本/实例的能力”,也可以视为一个计算文本概率的系统。
2、chatgpt语言模型使用基于Transformer的结构,训练过程可以在不同的时间步并行化,加快训练过程。
3、缺点:模型可能缺乏对特定行业的深入了解,导致在某些任务上的表现不佳。同时,伦理和道德问题,如生成虚假信息和歧视性内容,也是需要关注的问题。
结尾
复习建议:平时作业题最好看看,可能会有几道原题。其他的……就尽力吧……考了很多 算法、公式 还有公式中每个符号的意义。
注:以上题目答案均个人见解,欢迎探讨。
点 个 赞 呗 ~
点 个 赞 呗 ~
点 个 赞 呗 ~

