
- 1LTP在arm-linux-交叉编译环境上的安装_ltp工具交叉编译arm架构
- 2LLM-预训练:深入理解 Megatron-LM(1)基础知识【TP并行策略用于一个服务器内;PP并行策略用于服务器之间;】_megatron llm
- 3MySQL——高可用_mysql高可用
- 4微信小程序webview页面不刷新,webview缓存页面不刷新,小程序webview页面不刷新,小程序webview地址追加参数页面还是缓存,解决办法_微信小程序webview ios不会刷新路径
- 5【回归利器】提升至少50%效率的自动化测试工具
- 6中科亿海微亮相ICCAD 2022_中科亿海微前景
- 71.4.1 大内核和微内核_大内核相较于小内核可靠性较低吗
- 8OpenHarmony应用签名 - DevEco Studio 自动签名_deveco unsigned
- 9XSS安全漏洞修复解决方案_xss修复建议
- 10梯度下降算法_批量梯度下降(BGD)、随机梯度下降(SGD)、小批量梯度下降(MBGD)
文本匹配:语义相关性_对话语义相关性分析
赞
踩
语义相关性,比如搜索,查询词和文档如果关键字不一样,但两者是多词一义,则模型不理解语义,做语义上的匹配解决不了问题。在推荐中,商品可以由一个向量来刻画,用户也可以由一系列交互过的商品来表达,两者之间做一些语义上的匹配,能推荐出一些有新意的商品,增加推荐多样性。而传统的方法比如CF,CB等,无法学习得到这种用户和商品的相对间接的联系。
适用场景:阅读理解,QA,搜索,语义蕴含,推荐,广告等。
DSSM:
《Learning Deep Structured Semantic Models
for Web Search using Clickthrough Data》
文章提出,PSLA LDA等模型都是非监督模型,和目标不直接挂钩,效果自然比不上监督模型
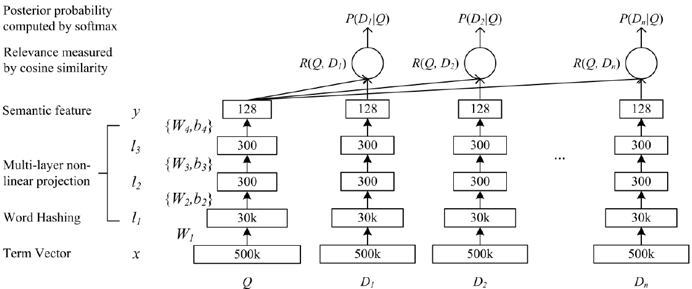
Word hashing层:每个词加上一个开始和结束的符号 (e.g. #good#).然后切分成n-grams 特征(e.g. letter trigrams: #go, goo, ood, od#).当然,更常见的做法是做一个预训练的word embedding。Word hashing的好处是模型是真正的end-to-end结构,不用额外维护一个word embedding lookup table,对于输入可以进行简单地映射。
FC层:若干全连接层
Softmax层:这里算出每个文档D和查询词Q的语义向量y后,求Q和每个文档D的余弦相似度,然后接softmax层求损失函数值。
采样:正样本D+和随机采样的四个不相关文档。文章指出,未发现不同采样方式对模型性能的影响。
CDSSM:
《A Latent Semantic Model with
Convolutional-Pooling Structure for Information Retrieval》
传统的信息检索方法如TF-IDF, BM25等词袋模型,以及LDA等主题模型,无法学习词的上下文信息。基于短语(phrase-based)的模型捕捉了一定的上下文信息,但是它只把短语当成编码单元(indexing units),而无法学习短语与短语之间的语义关系,同时也只能处理出现过的短语。这些问题在CLSM中都能解决
模型结构和之前的区别在于利用ConvNets layer代替了non-linear Multi-layer,因而也被称为CDSSM。convolutional latent semantic model (CLSM),
模型结构:
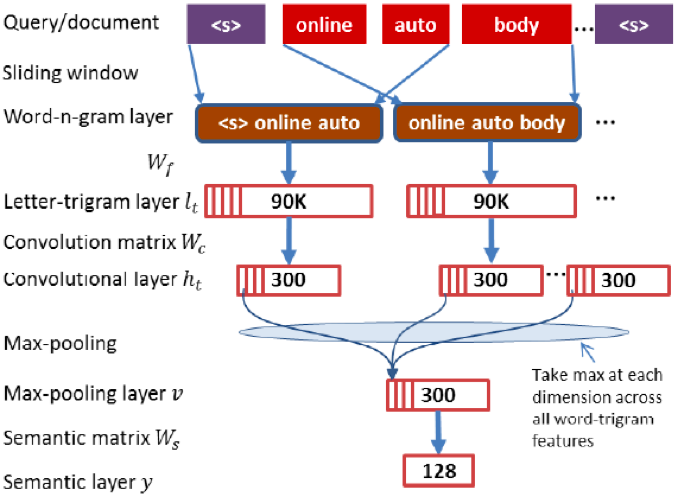
1 word
hashing。比如boy:letter-tri-grams: #-b-o, b-o-y, o-y-#
2卷积层,学习Word-n-gram-Level Contextual Features
3 max-pooling。学习Sentence-Level Semantic Features,同时把不同长度的查询词或文档变成等长向量,便于后面接FC
4全连接层。
5 softmax层
原文提到的一些设计原因:
1 全英文单词的总数很多,但是letter-trigrams不会太多,维度可控
2 卷积视野2d+1,学习词的上下文信息。结果发现相似的词义其向量相似。这样的好处是不简单地加和每个字的向量,而是用模型去发现重要的语义概念。
3卷积+max pooling,可以只留下最有用的局部特征,同时把不同长度的句子映射到同一长度的表示
4 学习分类器
查询词和每一个文档进行余弦相似度计算:
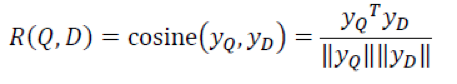
在多个文档中进行softmax归一化:
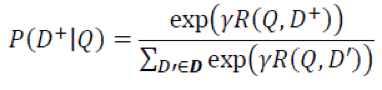
最后,优化目标是:
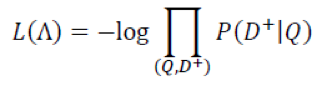
文章最后说,这种结构对于相关的词能学到较大权重,因而后面相关的词在max-pooling的贡献更大(和attention类似)
《Learning to Rank Short Text Pairs with
Convolutional Deep Neural Networks》
这篇文章提出的是很经典的结构,后面的大多数text matching论文大多是在这种结构上的改进
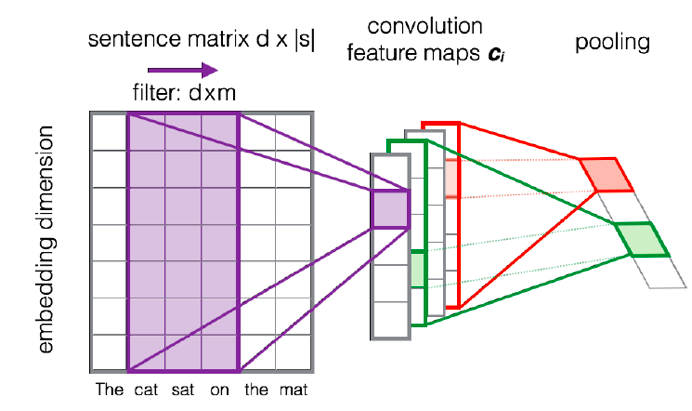
模型结构:Conv-ReLU-max pooling
当然,其实Conv可以多种尺寸,不光是5,这样可以学习不同视野范围下的特征
文章没有像DSSM那样计算余弦相似度,而是计算了如下形式的某种『距离』:
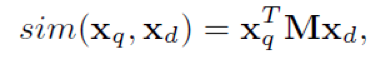
同时在该层可以任意增加一些人工构造的特征。
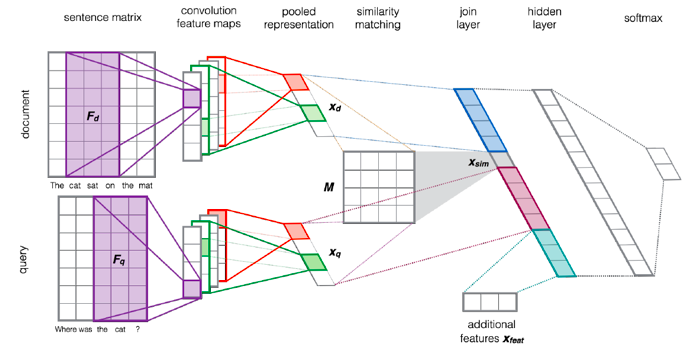
Word embedding是无监督初始化并静态的。原文说因为样本量不够,不然word embedding参数可以动态学习
这里的两篇论文对于query和document建模是分开的,也就是两个不同结构,与现在的一些模型不同。现在大部分是共享结构和参数的,这样对于模型的学习,样本更充分,也能更好地学出文本之间的一些匹配关系。本质而言,如果是求文本和文本这种同构的两种事物之间的语义匹配问题,共享模型参数是没问题的,如果是在推荐里,用户的表达是由其交互过的一连串的商品来刻画的,那用户和所需推荐的商品之间的匹配关系可能就不能共享模型和参数了。
《Improved Representation Learning for Question
Answer Matching》
这类问题,要么是利用问题和答案的表示计算相似度,要么是把两者表示合起来做一个分类器(是正确答案或者不是)。这篇文章是前者
基本模型:
word embeddings 加 Bi-lstm,然后用三种方式生成问题和答案的表达:
1 两个方向上最后时刻的隐藏单元拼接
2 所有bi-lstm的average-pooling
3 所有bi-lstm的max-pooling
同时question和answer是共用一个模型的,即只有一个模型,这点与上面提到的文章的工作都不同。
hinge loss
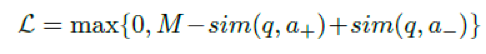
对于每一个正例,随机选择k个负例,但只选取loss最高的那个来更新模型
模型2 Convolutional-pooling LSTM:
结合了LSTM对长序信息,CNN对局部n-gram信息的优点
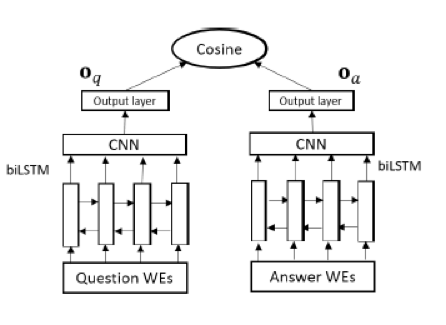
就是后面增加了conv和max-pooling
原文这里还做了一个变换,将BiLSTM输出的矩阵以每个词为中间向两边扩展k个(这也是卷积层的filter gram size,就是矩阵每个词的维度是原来k倍),这样能增加对局部信息的利用。
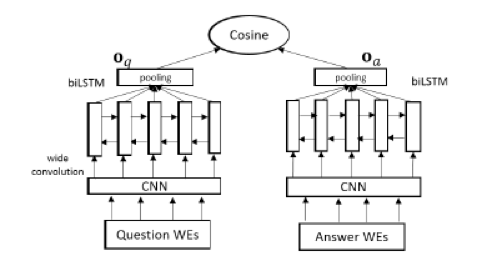
这个模型和上面的类型,就是lstm和conv换了次序。原文的数据是这个没有上面那个模型好,就是先lstm再卷积效果好。个人理解是对于nlp问题,一上来用卷积会损失较多信息,而信息高损操作应该尽量往后放。
模型3 attention
如果不看问题,再怎么对答案抽取表达向量,也一定包含很多无效信息,因为很多信息单独看答案句子是重要的,联系到问题就不重要,所以这里用上了attention,就是问题向量对答案里每个lstm隐向量求attention
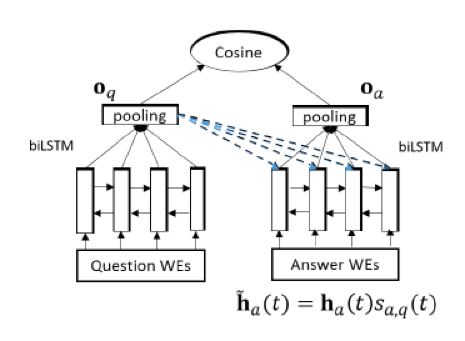
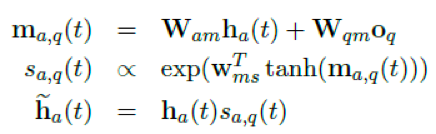
ha(t)是答案在t时刻的bi-lstm单元,oq是问题的表达向量
attention发生在答案侧bi-lstm后
《A Compare-Aggregate Model for Matching Text
Sequences》
原文说,两个序列比较的结果,不是由比较各自独立得到的总的表示得到,而是由比较各自的更小单元(比如词)的表示,然后结合这些表示来得到。个人理解就是问题-答案匹配,与其考虑模型学出来的问题表达向量和答案表达向量之间的匹配程度,不如考虑问题里每个词的表示和答案里每个词的表示之间的匹配程度,然后再做某种方式的汇总。
然后提出了一种通用的做文本匹配的模型框架
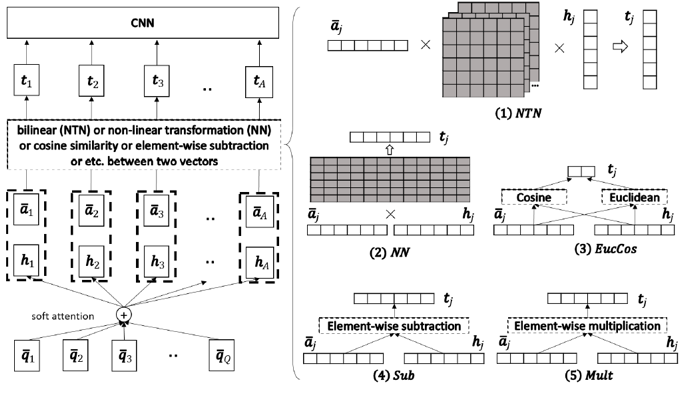
序列匹配的 “compare-aggregate” framework 的模型的一般形式。
Preprocessing: 为了得到有上下文信息的word embedding vector。如w2v, lstm
Attention: 对于A的每一列,得到Q的每一列的attention weight,和其注意力权重和向量hj,表示对于该答案词,问题的注意力表示向量
Comparison: 对比函数f去对比每一对aj和hj得到tj
Aggregation: CNN去聚合(aggregate)tj得到结果
对比函数f,可以选择简单的神经网络层,a neural tensor network,欧氏距离,余弦距离,和两个奇怪的东西。。。这里不罗列公式了。
转自:

