- 1鸿蒙开发过程中(DevEco Studio)使用远程真机连接端口异常的解决办法_hdc: hdc_server_port must be set to a positive num
- 2IOS面试题编程机制 31-35
- 3AI作画的业界天花板被我找到了,AIGC模型揭秘 | 昆仑万维_singularity openapl
- 4分享63个微信小程序源代码总有一个是你想要的_微信小程序开源源代码
- 5Java LinkedList类和Vector类_mybug鞋
- 6HarmonyOS中利用overflow属性实现横向滚动失效的解决方法_横向滚动条失效
- 7vue+element实现树状表格的增删改查;使用el-table树形数据与懒加载实现树状表格增删改查_vue3树形表格添加数据
- 8遇见这些APP,我觉得世界都变得温柔了_devcheck csdn
- 9Python圣诞树_python圣诞树代码源码
- 10【DBeaver】建立连接报驱动问题can‘t load driver class ‘org.postgresql.Driver_dbeaver连接pg数据库缺少驱动
基础GAN实例(pytorch代码实现)
赞
踩
目录
导入库
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- import torch.optim as optim #优化
- import numpy as np
- import matplotlib.pyplot as plt #绘图
- import torchvision #加载图片
- from torchvision import transforms #图片变换
数据准备
- #对数据做归一化(-1,1)
- transform=transforms.Compose([
- #将shanpe为(H,W,C)的数组或img转为shape为(C,H,W)的tensor
- transforms.ToTensor(), #转为张量并归一化到【0,1】;数据只是范围变了,并没有改变分布
- transforms.Normalize(0.5,0.5)#数据归一化处理,将数据整理到[-1,1]之间;可让数据呈正态分布
- ])
transforms.Compose(): 将多个预处理依次累加在一起, 每次执行transform都会依次执行其中包含的多个预处理程序
transforms.ToTensor():在做数据归一化之前必须要把PIL Image转成Tensor
transforms.Normalize([0.5], [0.5]):归一化,这里的两个0.5分别表示对张量进行归一化的 全局平均值和方差,因为图像是灰色的只有一个通道,所以分别指定一了一个值,如果有多个通道,需要有多个数字,如3个通道,就应该是Normalize([m1, m2, m3], [n1, n2, n3])
- #下载数据到指定的文件夹
- train_ds = torchvision.datasets.MNIST('data',
- train=True,
- transform=transform,
- download=True)
root :需要下载至地址的根目录位置
train:如果是True, 下载训练集 trainin.pt; 如果是False,下载测试集 test.pt; 默认是True¶
transform:一系列作用在PIL图片上的转换操作,返回一个转换后的版本
download:是否下载到 root指定的位置,如果指定的root位置已经存在该数据集,则不再下载
datalodar=torch.utils.data.DataLoader(train_ds,batch_size=64,shuffle=True)PyTorch中数据读取的一个重要接口是 torch.utils.data.DataLoader。
该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch_size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入。
torch.utils.data.DataLoader(onject)的可用参数如下:
dataset(Dataset): 数据读取接口,该输出是torch.utils.data.Dataset类的对象(或者继承自该类的自定义类的对象)。
batch_size (int, optional): 批训练数据量的大小,根据具体情况设置即可。一般为2的N次方(默认:1)
shuffle (bool, optional):是否打乱数据,一般在训练数据中会采用。(默认:False
定义生成器
输出是长度为100的噪声(正态分布随机数)
输出为(1,28,28)的图片
linear 1:100---256
linear 2: 256--512
linear 3:512--784(28*28)
reshape: 784---(1,28,28)
- class Generator(nn.Module):
- def __init__(self):
- super(Generator,self).__init__()
- self.main=nn.Sequential(
- nn.Linear(100,256),
- nn.ReLU(),
- nn.Linear(256,512),
- nn.ReLU(),
- nn.Linear(512,784),
- nn.Tanh()#对于生成器,最后一个激活函数是tanh,值域:-1到1
- )
- #定义前向传播
- def forward(self,x): #x表示长度为100的noise输入
- img = self.main(x)
- img=img.view(-1,28,28)#转换成图片的形式
- return img

定义判别器
输入为为(1,28,28)的图片,输出为二分类的概率值,输出使用sigmoid的激活0-1
BCEloss计算交叉熵损失
在判别器中一般推荐使用nn.LeakyReLU
- class Discriminator(nn.Module):
- def __init__(self):
- super(Discriminator,self).__init__()
- self.main = nn.Sequential(
- nn.Linear(784,512),
- nn.LeakyReLU(),
- nn.Linear(512,256),
- nn.LeakyReLU(),
- nn.Linear(256,1),
- nn.Sigmoid()
- )
- def forward(self,x):
- x =x.view(-1,784) #展平
- x =self.main(x)
- return x
初始化模型,优化器及损失计算函数
- #设备的配置
- device='cuda' if torch.cuda.is_available() else 'cpu'
- #初始化生成器和判别器把他们放到相应的设备上
- gen = Generator().to(device)
- dis = Discriminator().to(device)
- #训练器的优化器
- d_optim = torch.optim.Adam(dis.parameters(),lr=0.0001)
- #训练生成器的优化器
- g_optim = torch.optim.Adam(dis.parameters(),lr=0.0001)
- #交叉熵损失函数
- loss_fn = torch.nn.BCELoss()
绘图函数
- def gen_img_plot(model,test_input):
- prediction = np.squeeze(model(test_input).detach().cpu().numpy())
- fig = plt.figure(figsize=(4,4))
- for i in range(16):
- plt.subplot(4,4,i+1)
- plt.imshow((prediction[i]+1)/2)
- plt.axis('off')
- plt.show()
test_input = torch.randn(16,100 ,device=device) #16个长度为100的随机数GAN的训练
- D_loss = []
- G_loss = []
- #训练循环
- for epoch in range(20):
- #初始化损失值
- d_epoch_loss = 0
- g_epoch_loss = 0
- count = len(dataloader) #返回批次数
- #对数据集进行迭代
- for step,(img,_) in enumerate(dataloader):
- img =img.to(device) #把数据放到设备上
- size = img.size(0) #img的第一位是size,获取批次的大小
- random_noise = torch.randn(size,100,device=device)
-
- #判别器训练(真实图片的损失和生成图片的损失),损失的构建和优化
- d_optim.zero_grad()#梯度归零
- #判别器对于真实图片产生的损失
- real_output = dis(img) #判别器输入真实的图片,real_output对真实图片的预测结果
- d_real_loss = loss_fn(real_output,
- torch.ones_like(real_output)
- )
- d_real_loss.backward()#计算梯度
-
- #在生成器上去计算生成器的损失,优化目标是判别器上的参数
- gen_img = gen(random_noise) #得到生成的图片
- #因为优化目标是判别器,所以对生成器上的优化目标进行截断
- fake_output = dis(gen_img.detach()) #判别器输入生成的图片,fake_output对生成图片的预测;detach会截断梯度,梯度就不会再传递到gen模型中了
- #判别器在生成图像上产生的损失
- d_fake_loss = loss_fn(fake_output,
- torch.zeros_like(fake_output)
- )
- d_fake_loss.backward()
- #判别器损失
- d_loss = d_real_loss + d_fake_loss
- #判别器优化
- d_optim.step()
-
-
- #生成器上损失的构建和优化
- g_optim.zero_grad() #先将生成器上的梯度置零
- fake_output = dis(gen_img)
- g_loss = loss_fn(fake_output,
- torch.ones_like(fake_output)
- ) #生成器损失
- g_loss.backward()
- g_optim.step()
- #累计每一个批次的loss
- with torch.no_grad():
- d_epoch_loss +=d_loss
- g_epoch_loss +=g_loss
- #求平均损失
- with torch.no_grad():
- d_epoch_loss /=count
- g_epoch_loss /=count
- D_loss.append(d_epoch_loss)
- G_loss.append(g_epoch_loss)
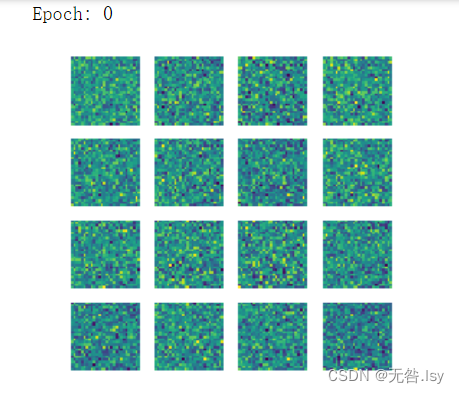
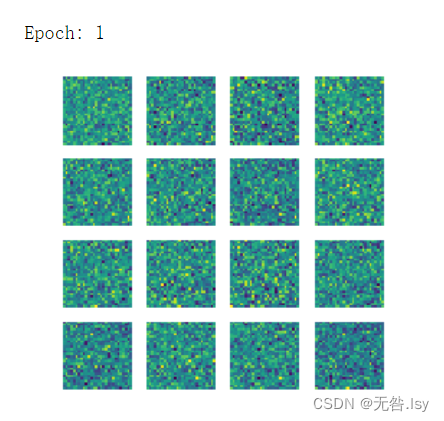
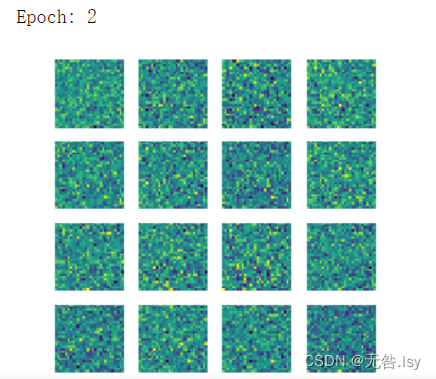
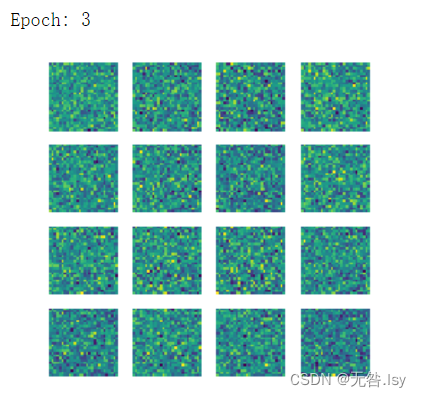
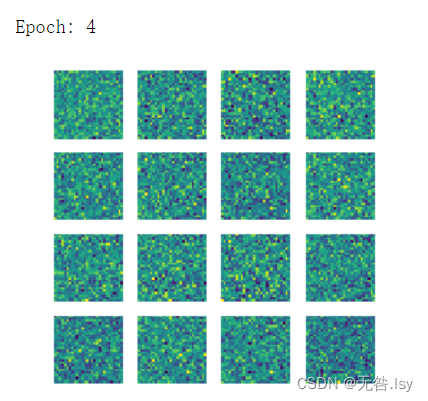
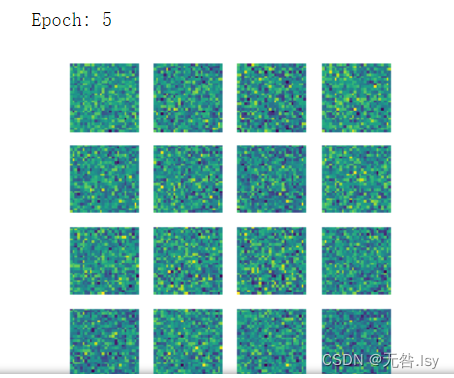
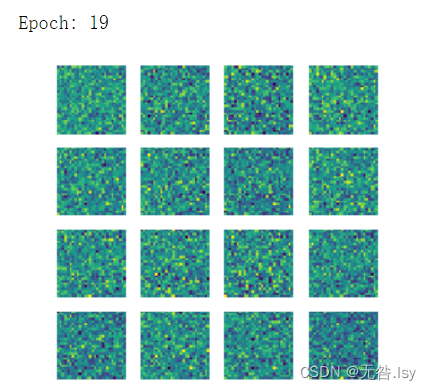
- print('Epoch:',epoch)
- gen_img_plot(gen,test_input)
运行结果
一共有20张,因篇幅有限,这里先展示前六张和最后一张