
- 1微信小程序自定义弹窗组件
- 2python简易使用rabbitmq_python 是否可以像springboot一样使用rabbitmq
- 3轻快好用的Docker版云桌面(不到300M、运行快、省流量).md_docker 云桌面
- 4python库--pipreqs_python pipreqs ./
- 5word2vec实现训练自己的词向量及其参数详解_word2vec参数设置
- 6遥感数据集+YOLOV5_yolov5_obb
- 7chatgpt赋能python:爬取电影数据的Python代码_爬取chatgpt的回答
- 8最新SparkAI创作系统ChatGPT程序源码+详细图文搭建教程/支持GPT-4/支持AI绘画/Prompt应用_gpt4 prompt 绘画
- 9分类预测 | MATLAB实现基于Isomap降维算法与改进蜜獾算法IHBA的Adaboost-SVM集成多输入分类预测_matlab isomap
- 10中文译英文 模型_helsinki-nlp 中英文互译
大力出奇迹,揭秘昇腾CANN的AI超能力_compute architecture for neural networks
赞
踩
摘要:CANN(Compute Architecture for Neural Networks)异构计算架构,是以提升用户开发效率和释放昇腾AI处理器极致算力为目标,专门面向AI场景的异构计算架构。
1、引言
从2016年,战胜世界顶级棋手,强势将了人类一军的AlphaGo,
到2020年,会写小说、编剧本、敲代码,科科满分样样全能的GPT-3,
再到2021年,最接近人类中文理解能力,泛化力超群的盘古大模型…
近几年的人工智能领域,像开了挂一样,不断刷新人类认知,颠覆人类想象…
和人类掌握某项技能一样,训练一个足够聪明的AI算法模型往往需要成千上万的数据量。以GPT-3为例,其参数量已经达到1750亿、样本大小有45TB之多,单次训练时间以月为单位,算力诉求已是挡在AI赛道上的绊脚石!
同时,随着人工智能应用日益成熟,文本、图片、音频、视频等非结构化数据的处理需求呈指数级增长,数据处理过程从通用计算逐步向异构计算过度。
华为推出的昇腾AI基础软硬件平台。其中,昇腾AI处理器+ 异构计算架构CANN,带着与生俱来的超强算力和异构计算能力,软硬件强强联合,正逐渐成为促成AI产业快速落地的催化剂。
CANN(Compute Architecture for Neural Networks)异构计算架构,是以提升用户开发效率和释放昇腾AI处理器极致算力为目标,专门面向AI场景的异构计算架构。对上支持主流前端框架,向下对用户屏蔽系列化芯片的硬件差异,以全场景、低门槛、高性能的优势,满足用户全方位的人工智能诉求。
2、主流前端框架兼容,快速搞定算法移植
目前人工智能领域内,AI算法模型搭建方面的技艺已经是炉火纯青,市面上用于AI模型搭建的深度学习框架,除了华为开源的MindSpore,还有Google的TensorFlow、Facebook的PyTorch、Caffe等。
CANN通过Plugin适配层,能轻松承接基于不同框架开发的AI模型,将不同框架定义的模型转换成标准化的Ascend IR(Intermediate Representation)表达的图格式,屏蔽框架差异。
这样,开发者只需要非常少的改动,即可快速搞定算法移植,体验昇腾AI处理器的澎湃算力,大大减少了切换平台的代价,就说它香不香?
3、简单易用的开发接口,让小白也能玩转AI
依靠人工智能实现智能化转型,几乎成为了各行各业的必修课,CANN秉承极简开发的理念,提供了一套简单易用的AscendCL(Ascend Computing Language)编程接口,为开发者屏蔽底层处理器的差异,你只需要掌握一套API,就可以全面应用于昇腾全系列AI处理器。
同时,能够满足开发者能够在未来CANN版本升级的情况下,依然可以做到后向全面兼容,且运行效率不打折扣!
简单的AI应用开发接口
人工智能寄托着人类对未来美好生活的憧憬,当我们每天面对“这是什么垃圾,要扔在哪个桶里”的灵魂拷问的时候,一个AI垃圾分类桶应用,就能把你从水深火热中解救出来。
AscendCL提供了一套用于开发深度神经网络推理应用的C语言API库,兼具运行时资源管理、模型加载与执行、图像预处理等能力,能够让开发者轻松解锁图片分类、目标识别等各类AI应用。并且可以做到即支持通过主流开源框架调用AscendCL库,也支持直接调用CANN开放的AscendCL编程接口。
下面教你5步搞定AI垃圾分类应用:

- 运行管理资源申请:用于初始化系统内部资源。
- 加载模型文件并构建输出内存:将开源模型转换成CANN支持的om模型,并加载到内存;获取模型基本信息,构建模型输出内存,为后续模型推理做准备。
- 数据预处理:对读入的图像数据进行预处理,然后构建模型的输入数据。
- 模型推理:根据构建好的模型输入数据进行模型推理。
- 解析推理结果:根据模型输出,解析模型的推理结果。
灵活的算子开发接口
当你的AI模型中有CANN尚未支持的算子,或者想要修改已有算子以提升计算性能时,可以利用CANN开放的自定义算子开发接口,随心所欲地开发你想要的算子。
面向不同水平的AI开发者,CANN提供高效(TBE-DSL)和专业(TBE-TIK)两种算子开发模式,可灵活满足不同层次水平的开发者。
其中,TBE-DSL的入门难度较低,它可以自动实现数据的切分和调度,开发者只需关注算子本身的计算逻辑,无需了解硬件细节,即可开发出高性能算子。
TBE-TIK相对难一些,不像TBE-DSL只是在高层抽象编程,而是提供指令级编程和调优能力,开发者需要手工完成类指令级调用,这样能充分挖掘硬件能力,实现更加高效和复杂的算子。
便捷的IR构图接口
另外,开发者还可以通过标准化的Ascend IR(Intermediate Representation)接口,抛开深度学习框架本身,直接调用CANN中的算子库,构建出可以在昇腾AI处理器上执行的高性能模型。
4、1200+高性能算子库,筑起澎湃算力源泉
基于深度学习框架构建的模型,其实是由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称Op),它对应着特定的计算逻辑。
算子在硬件上的加速计算构成了加速神经网络的基础和核心。目前CANN提供了1200+种深度优化的、硬件亲和的算子,正是如此丰富的高性能算子,筑起了澎湃的算力源泉,让你的神经网络「瞬时」加速。
- NN(Neural Network)算子库:CANN覆盖了包括TensorFlow、Pytorch、MindSpore、ONNX框架在内的,常用深度学习算法的计算类型,在CANN所有的算子中占有最大比重,用户只需要关注算法细节的实现,大部分情况下不需要自己开发和调试算子。
- BLAS(Basic Linear Algebra Subprograms)算子库:BLAS为基础线性代数程序集,是进行向量和矩阵等基本线性代数操作的数值库,CANN支持通用的矩阵乘和基础的Max、Min、Sum、乘加等运算。
- DVPP(Digital Video Pre-Processor)算子库:提供高性能的视频编解码、图片编解码、图像裁剪缩放等预处理能力。
- AIPP(AI Pre-Processing)算子库:主要实现改变图像尺寸、色域转换(转换图像格式)、减均值/乘系数(图像归一化),并与模型推理过程融合,以满足推理输入要求。
- HCCL(Huawei Collective Communication Library)算子库:主要提供单机多卡以及多机多卡间的Broadcast,allreduce,reducescatter,allgather等集合通信功能,在分布式训练中提供高效的数据传输能力。
5、高性能图编译器,赋予神经网络超能力
人间最苦是等待,等红绿灯,等寒暑假,等外卖,等那个对的人…
人工智能领域也是一样,随着神经网络结构的快速演进,单纯利用手工优化来解决AI模型性能问题越来越容易出现瓶颈,CANN的图编译器像是一个魔法师,将具有较高抽象度的计算图,根据昇腾AI处理器的硬件结构特点,进行编译优化,从而能够高效执行。
魔法师到底有哪些「神操作」呢?
自动算子融合:基于算子、子图、SCOPE等多维度进行自动融合,有效减少计算节点,大幅减少计算时间。
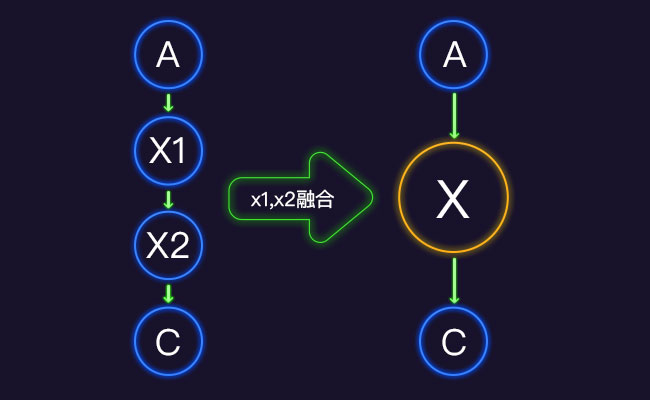
Buffer融合:针对神经网络计算大数据吞吐,memory bound问题,通过减少数据搬运次数、提升昇腾AI处理器内缓存利用率,提升计算效率。
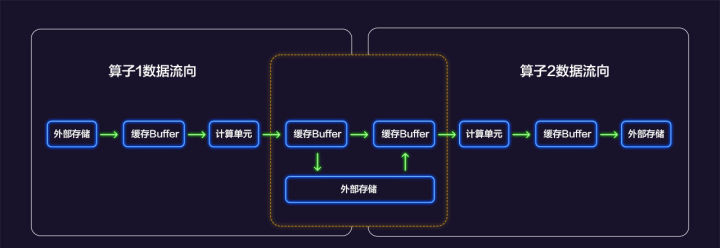
我们对Buffer融合前后做一比对:
融合前,算子1在昇腾AI处理器上计算完后,将数据从昇腾AI处理器内的缓存buffer搬运到外部存储,算子2从外部存储获取数据作为输入,搬入缓存buffer进行计算。融合后,算子1计算完成后,数据保留在缓存buffer,算子2从缓存buffer直接获取数据进行算子2的计算,有效减少数据搬运次数,提升了计算性能。
全图下沉:昇腾AI处理器,集成了丰富的计算设备资源,比如AICore/AICPU/DVPP/AIPP等,正是得益于昇腾AI处理器上丰富的土壤,使得CANN不仅可以将计算部分下沉到昇腾AI处理器加速,还可以将控制流、DVPP、通信部分一并下沉执行。尤其在训练场景,这种把逻辑复杂计算图的全部闭环在AI处理器内执行的能力,能有效减少和Host CPU的交互时间,提升计算性能。
异构调度能力:当计算图中含有多类型的计算任务时,CANN充分利用昇腾AI处理器丰富的异构计算资源,在满足图中依赖关系的前提下,将计算任务分配给不同的计算资源,实现并行计算,提升各计算单元的资源利用率,最终提升计算任务的整体效率。

6、自动混合精度,有效达到收益平衡
顾名思义,自动混合精度是一种自动将半精度和单精度混合使用,从而加速模型执行的技术,在大规模模型训练场景下有着不可或缺的地位。
单精度(Float Precision32,FP32)是计算机常用的一种数据类型,半精度(Float Precision16,FP16)则是一种相对较新的浮点类型,在计算机中使用 2 字节(16 位)存储,适用于精度要求不高的场景。
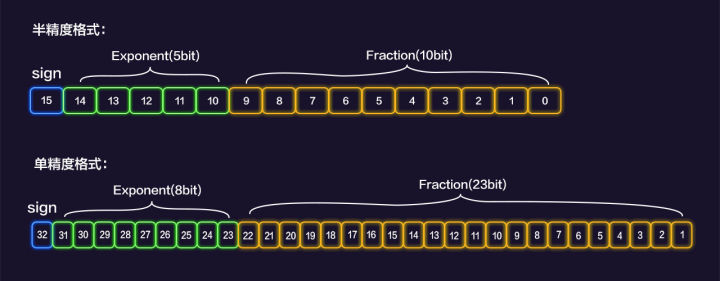
显而易见,使用FP16类型肯定会带来计算精度上的损失,但对于深度学习训练而言,并不是所有计算都要求很高的精度。因此,可以将计算图中对精度不敏感的算子使用FP16类型加速计算,可有效减少内存使用,达到性能和精度平衡。
7、E级集群,开启AI超算时代
随着主流深度学习模型所能够解决的问题日趋复杂,模型本身的复杂度也开始增大,人工智能领域需要更强大的算力,来满足未来网络的训练需求。
基于昇腾AI基础软硬件的“鹏城云脑II”,打破了当今业内百P级FLOPS(每秒十亿亿次计算)的算力天花板,让E级FLOPS(每秒百亿亿次计算)算力场景迈上了历史舞台。
它集成了数千颗昇腾AI处理器,总算力达到 256-1024 PFLOPS,也就是每秒25.6-102.4亿亿次浮点运算。
如何高效调度上千颗昇腾AI处理器,是大规模集群网络面临的难题。
CANN集成了HCCL(Huawei Collective Communication Library,华为集合通信库),为昇腾AI处理器多机多卡训练提供了数据并行/模型并行的高性能集合通信方案:
- server内高速HCCS Mesh互联和server间无阻塞RDMA组网的两级拓扑组网,配合拓扑自适应通信算法,能充分利用链路带宽,并将server间的数据传输量并行均分至各个独立的网络平面,大大提升超大规模集群下模型训练线性度。
- 集成高速通信引擎和专用硬件调度引擎,大幅降低通信调度开销,实现通信任务和计算任务统一和谐调度,精准控制系统抖动。
如果把“鹏城云脑II”比作一个大型交响乐团,那么CANN就是一名优秀的指挥家,携手昇腾AI处理器,开启了AI超算时代新篇章。
8、写在最后
CANN在2018年发布伊始便不断尝试突破,带给开发者极简体验,释放AI硬件的极致性能,成为了支撑CANN在人工智能领域行走的双腿。
相信它会矢志不渝地在AI这条赛道上,携手想要改变世界的人,一起改变世界,共筑未来!
2021年年底,CANN也要迎来崭新的、更加强大的5.0版本,它到底会带来哪些惊喜呢?让我们拭目以待吧!

