
- 1Spring AI 指南_spring-ai
- 2【开山篇】自然语言处理(PyTorch版)_pytorch自然语言处理
- 3理解BERT模型理论_bert是什么时候提出来的模型
- 4中间件的分类_操作系统数据库中间件归位哪一类
- 5使用ApacheZeppelin进行自然语言处理:入门指南
- 6发挥ChatGPT潜力:高效撰写学术论文技巧
- 7拦截请求的三种方式 Filter、Interceptor、Aspect_请求拦截怎么做
- 8Drag Gan,AI绘画又有了重大突破_darggan
- 9Transformers Pipeline: NLP任务的全面指南_transformer的pipeline
- 10Python数据分析实战:使用Pandas进行数据分析_pandas数据分析实战 (超详细)
Python数据处理(二)-txt文件指定数据提取处理_python txt导出指定区域数据
赞
踩
系列文章:
0、基本常用功能及其操作(本文操持更新)
1,20Gtxt文件提取并分类整理输出作图
2,数据的归类并处理(本文)
3,txt文件指定数据提取并可视化作图
4,上万行log数据提取并作图进阶版
5、上万行数据提取并分类进阶版
6、.......... (待定)
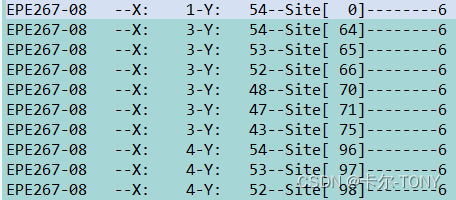
一,数据格式及需求
有一个几十M的TXT文件,每一行都蕴含坐标轴,X,Y以及对应的数据,时间啊,电压电流等等,X坐标轴从0--107,Y坐标轴也是0---107,X,Y为一组,相同的X,Y的组数据放一起。最终放入excel表格,XY坐标,后面就说各个XY组的数据依次排列在行的后面。
二,分布实现需求
这个需求比较复杂,因为手动复制是很费时费力的,而且通过不好操作,所以需要分步骤实现我们的需求。
1,把X坐标相同的全部提取单独的文件中,X从0---107,所以我们会有107个文件
2,在各个文件里面,再去对Y进行分类排序,将Y相同的放一起
3,最后就简单了,107个文件,每个文件XY都按照预期放好了,
那么我们只需要提取我们需要的数据,X,Y坐标,以及每一组的我们需要的值即可,然后放入excel文件
三,需求的各个步骤的实现
1,X的分类,这个很简单,只要把不同的X放入对应的TXT即可
- def X_select(wafer_XY_input_txt,wafer_XY_output_folder):
- wafer_XY_output_txt = wafer_XY_output_folder + '/xvalue_'
- # 读取原始文本文件
- with open(wafer_XY_input_txt, "r") as file:
- lines = file.readlines()
- # 提取并存储符合条件的行
- for line in lines:
- match = re.search(r'--X:\s+(\d+)-', line)
- if match:
- x_value = int(match.group(1))
- if 1 <= x_value <= 107:
- file_name = wafer_XY_output_txt + str(x_value) + '.txt'
- with open(file_name, 'a') as file:
- file.write(line)
注释:(1)只读方式打开需要处理的文件并存入缓存数据结构
(2)循环读取并操作每一行
(3)结合正则表达式,识别X的坐标为多少(我用是两个特定符号之间来缩小判断的数,当然可以有其他方法,空格也算分隔符,逗号在CSV中也算是一种分隔符)
(4)从字符型转换为int类型并作数据,X坐标多少就写入对应的TXT文件

2,python进行0--107个txt文件的数据整理
X已经分好类了,但是里面的Y坐标还是杂乱无章的并不是相同的Y都在一起,所以需要整理。
- def Y_sort(wafer_XY_output_folder, X_START , X_END , XY_value_num):
- # ----2-----------整理Y值,相同放一起,Y从小到大
- import re
- from collections import defaultdict
- # 函数用于处理和重写单个文件
- def process_and_rewrite_file(filename):
- with open(filename, 'r') as file:
- lines = file.readlines()
-
- # 使用字典来存储相同数值的行,键为数值,值为行列表
- grouped_lines = defaultdict(list)
-
- # 读取并分组所有行
- for line in lines:
- match = re.search(r"Y: (.*?)--S", line)
- if match:
- value = match.group(1).strip()
- grouped_lines[value].append(line)
-
- # 写入新的整理过的数据到文件
- with open(filename, 'w') as file:
- for value in sorted(grouped_lines.keys(), key=float): # 假设数值可以转化为浮点型并进行排序
- # 限制写入每个数值的前--12/18/7---个元素
- for line in grouped_lines[value][:XY_value_num]:
- file.write(line)
-
- # 处理 xvalue_1.txt 到 xvalue_107.txt 文件 /1_2TD
- for i in range(X_START, X_END):
- process_and_rewrite_file(wafer_XY_output_folder + f"/xvalue_{i}.txt")

注释:
(1)打开文件存入缓存数据结构(这个在超大文件时不可用,详情见文章一),并定义字典
(2)正则表达式,提取Y值并作判断,每个Y坐标作为一个键,将这一行作为值存入字典
(3)最后打开原文件并写入字典数据覆盖
(4)最后实现从0---107个文件的顺序执行
3,数据处理并导出
前面数据都归类整理好了,最后就是指定数据处理了,
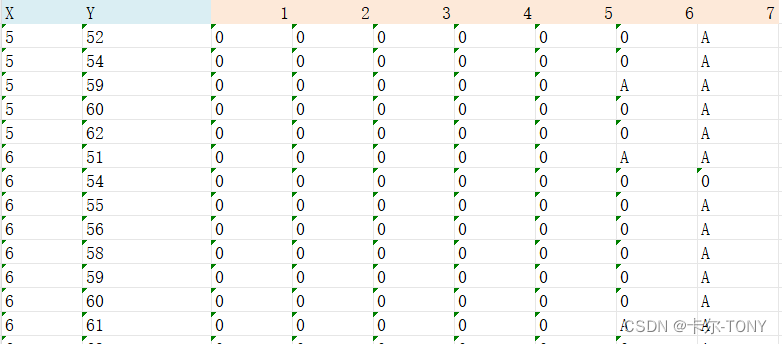
我们需要X,Y坐标以及XY相同组的数据写到一起,比如X,Y相同的组有12个,18个,4个,等等都可以,需要提前看一下源文件(这个算是小的不太完美的地方),然后定义每一组有都少个数据
同时X也未必只有0--107或者小于,或者大于,这个留了接口,可自动调整
(1)打开文件,提取数据到缓存数据结构
(2)处理每一组数据,提取第一行X,Y坐标,以及每一组的我们需要的值,电流,电压,时间等等
(3)提取的数据存入单元格内容的列表,并存入excel文件
(4)当然,数据可以作图或者,其他操作都可以,看情况
- def XY_output_excel(wafer_XY_output_folder,wafer_XY_output_excel,X_START,X_END,XY_value_num):
- # # ----4----------最终成品,写到Excel文件中,并且X,Y分开写
- import re
- from openpyxl import Workbook
- # 创建Excel工作簿
- wb = Workbook()
- ws = wb.active
- # Excel文件名
- excel_file_name = wafer_XY_output_excel
- # 遍历所有文件
- for i in range(X_START, X_END):
- filename = wafer_XY_output_folder + f"/xvalue_{i}.txt"
- try:
- with open(filename, 'r') as file:
- lines = file.readlines()
-
- # 按组处理数据,每12行一组
- for j in range(0, len(lines), XY_value_num):
- group_lines = lines[j:j + XY_value_num]
-
- # 确保数据完整
- if len(group_lines) < XY_value_num:
- continue
-
- # 提取X和Y的值
- x_match = re.search(r'X: (.*?)-Y', group_lines[0])
- y_match = re.search(r'Y: (.*?)--S', group_lines[0])
-
- # 如果匹配成功
- if x_match and y_match:
- x_value = x_match.group(1).strip()
- y_value = y_match.group(1).strip()
-
- # 准备单元格内容列表
- row_data = [x_value, y_value]
-
- # 从每一行提取'--------'之后的数据
- for line in group_lines:
- value_match = re.search(r'--------(.*)', line)
- if value_match:
- value = value_match.group(1).strip()
- row_data.append(value)
- # 将键和值写入工作表的一行
- ws.append(row_data)
- except FileNotFoundError:
- print(f"File {filename} not found. Skipping.")
- # 保存Excel文件
- wb.save(filename=excel_file_name)


