
- 1行业模板|DataEase制造行业大屏模板推荐
- 2数字人系统OEM流程:部署AI数字人系统源码需要注意哪些?
- 3微信小程序真实项目开发实战视频教程_微信小程序全栈开发实战 百度网盘
- 4手机支付流程图模板分享 怎么画手机支付流程图操作教程分享
- 5Huggingface Transformers(1)-Hugging Face官方课程_hugging face transformers
- 6Hadoop HA集群的搭建_nameservice
67108864 指定ha - 7Diffusion model之DDPM
- 8OpenAI开源"weak-to-strong"方法代码框架!我们带你一探究竟
- 9新版 Redis 不再“开源”,对使用者都有哪些影响?_redis 不再开源
- 10人工智能基础与线性回归模型_ai 和回归模型
朱晔的互联网架构实践心得S2E3:品味Kubernetes的设计理念
赞
踩
Kubernetes(k8s)是一款开源的优秀的容器编排调度系统,其本身也是一款分布式应用程序。虽然本系列文章讨论的是互联网架构,但是k8s的一些设计理念非常值得深思和借鉴,本人并非运维专家,本文尝试从自己看到的一些k8s的架构理念结合自己的理解来分析 k8s在稳定性、简单、可扩展性三个方面做的一些架构设计的考量。
稳定性:考虑的是系统本身足够稳定,用户使用系统做的一些动作能够稳定落地,系统本身容错性足够强可以应对网络问题,系统本身有足够的高可用等等。
简单:考虑的是系统本身的设计足够简单,组件之间没有太多耦合,组件职责单一等等。
可扩展性:考虑的是系统的各个模块有层次,模块对内对外一视同仁,外部可以轻易实现扩展模块插入到系统(插件),模块实现统一的接口便于替换切换具体实现等等。 下面,针对这三方面我们都会来看一些k8s设计的例子,在看k8s是怎么做的同时我们可以自己思考一下,如果我们需要研发的一款产品就是类似于k8s这样的需要高可靠的资源状态管理协调系统,我们会怎么来设计呢?
1、稳定:声明式应用程序管理
我们知道,k8s定义了许多资源(比如Pod、Service、Deployment、ReplicaSet、StatefulSet、Job、CronJob等),在管理资源的时候我们使用声明式的配置(JSON、YAML等)来对资源进行增删改查操作。我们提供的这些配置就是描述我们希望这些资源最终达成的一个目标状态,叫做Spec,k8s会对观察资源得到资源的状态,叫做Status,当Spec!=Status的时候,k8s的各种控制管理程序就会起作用,进行各种操作使得资源最终可以达到我们期望的Spec。这种声明式的管理方式和命令式管理方式相比,虽然没有后者这么直接,但是容错性会很强,后面一节会进一步详细提到这点。而且,这种管理方式非常的简洁,只要用户提供合适的Spec定义即可,并不需要对外暴露几十个几百个不同的API来实现对资源的各个方面做改变。当然,我们也可以灵活的对一些重要的动作单独开辟管理API(比如扩容,比如修改镜像),这些API底层做的操作就是修改Spec,底层是统一的。
在之前第一季的系列文章S1E2中,我分享过任务表的设计,其实这里的声明式对象管理就是类似这样的思想,我们在数据库中保存的是我们要的结果,然后由不同的任务Job来进行处理最终实现这样的结果(同时也会保存组件当前的状态到数据库),即使任务执行失败也无妨,后续的任务会继续重试,这种方式是可靠性最高的。
2、稳定:边缘触发 vs 水平触发
K8s使用的是声明式的管理方式,也就是水平触发。另一种做法是叫做命令式的管理,也就是边缘触发。比如我们在做支付系统,用户充值100元,提现100元然后又充值100元,对于命令式管理就是三条命令。如果提现请求丢失了,用户账户的余额就出错了,这肯定是不能接受的,命令式管理或边缘触发一定需要配合补偿。而声明式的管理就是告诉系统,用户在进行了三次操作后的余额分别是100、0和100,最终就是100,即使提现请求丢失了,最终用户的余额就是100。
来看下下图的例子,在网络良好的情况下,边缘触发没任何问题。我们进行了开、关、开三次操作,最后的状态是0。
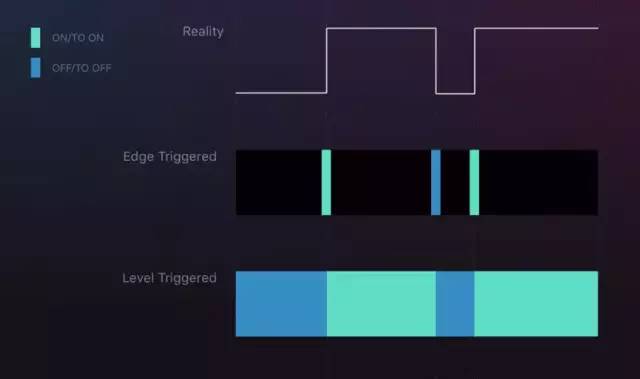
在网络出现问题的时候,丢失了关这个操作,对于边缘触发,最终停留在了2这个错误的状态。对于水平触发没有这个问题,虽然当中有一段时间网络不好,状态错误停留在了1,但是网络恢复后我们马上可以感知到当前的状态应该是0,状态又能回到0,最终状态也能回到正确的1。试想一下,如果我们对我们的Pod进行扩容缩容,如果每次告知k8s应该增加或减少多少个Pod(的这种命令式方式),最终很可能因为网络问题,Pod的状态不是我们期望的。更好的做法是告诉k8s我们希望的状态,不管现在网络是否有问题,某个管理组件是否有问题,pod是否有问题,最终我们期望k8s帮我们调整到我们期望的状态,宁可慢也不要错。
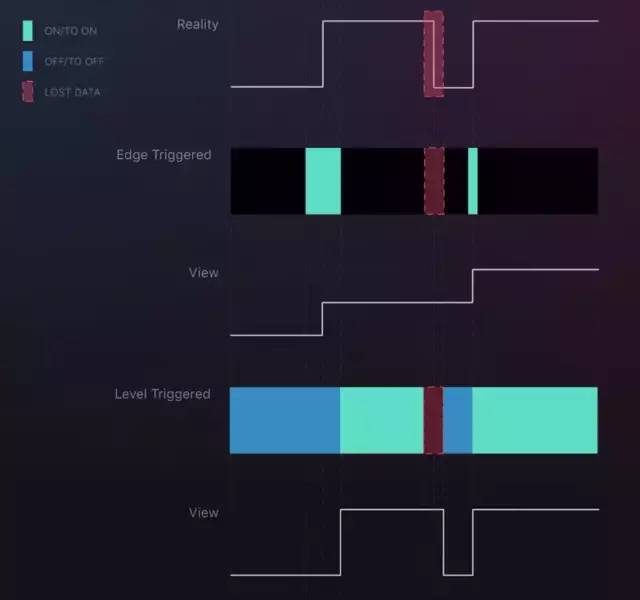
(图来自这里)
3、稳定:高可用设计
我们知道etcd是基于Raft协议的分布式键值数据库/协调系统,本身推荐使用3、5、7这样奇数节点构成集群实现高可用。对于Master节点,我们可以在每一个节点都部署一个etcd,这样节点上的API Server可以和本地的etcd直接通讯,而API Server因为是轻(无)状态的,所以可以在之前使用负载均衡器做代理,不管是Node节点也好还是客户端也好都可以由负载均衡分发请求到合适的API Server上。对于类似于Job的Controller Manager以及Scheduler,显然不适合多个节点同时运行,所以它们都会采用抢占方式选举Leader,只有Leader能承担工作任务,Follower都处于待机状态。整体结构如下图所示:
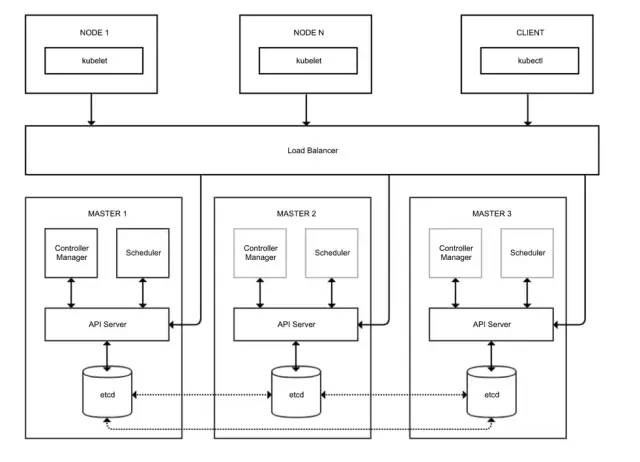
我们可以想一下其它一些分布式系统的高可用方案,以及我们自己设计的系统的高可用方案,无非就是这三种大模式:
无状态多节点 + 负载均衡
有状态的主节点 + 从(或备份)节点
对称同步的有状态多节点
4、简单:基于list-watch的发布订阅
通过前面的介绍我们大概知道了k8s的一个设计原则是etcd会处于API Server之后,集群内的各种组件是无法直接和数据库对话的,不仅仅因为把数据库直接暴露给各组件会特别混乱,更重要的是谁都可以直接读写etcd会非常不安全,需要统一经过API Server做身份认证和鉴权等安全控制(后面我们会提到API Server的插件链)。
对于k8s集群内的各种资源,k8s的控制管理器和调度器需要感知到各种资源的状态变化(比如创建),然后根据变化事件履行自己的管理职责。考虑到解耦,显然这里有MQ的需求,各种管理组件可以监听各种资源的状态变化事件,不需要相互感知到对方的存在,自己做自己的事情即可。如果k8s还依赖一些消息中间件实现这个功能,那么整体的复杂度会上升,而且还需要对消息中间件进行一些安全方面的定制。
K8s给出的实现方式是仍然使用API Server来充当简单的消息总线的角色,所有的组件通过watch机制建立HTTP长链接来随时获悉自己感兴趣的资源的变化事件,完成自己的功能后还是调用API Server来写入我们组件新的Spec,这份Spec会被其它管理程序感知到并且进行处理。Watch的机制是推的机制,可以实时对变化进行处理,但是我们知道考虑到网络等各种因素,事件可能丢失,组件可能重启,这个时候我们需要推拉结合进行补偿,因此API Server还提供了List接口,用于在watch出现错误的时候或是组件重启的时候同步一次最新状态。通过推拉结合的list-watch机制满足了时效性需求和可靠性需求。
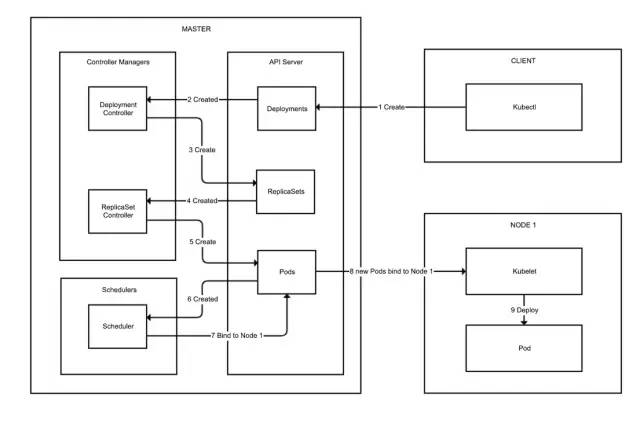
我们来看一下这个图,这个图展示了客户端创建一个Deployment后k8s大概的工作过程:
组件初始化阶段:
Deployment Controller订阅Deployment创建事件
ReplicaSet Controller订阅ReplicaSet创建事件
Scheduler订阅未绑定Node的Pod创建事件
所有Kubelet订阅自己节点的Node和Pod绑定事件
集群资源变更操作:
客户端调用API Server创建Deployment Spec
Deployment Controller收到消息需要处理新的Deployment
Deployment Controller调用API Server创建ReplicaSet
ReplicaSet Controller收到消息需要处理新的ReplicaSet
ReplicaSet Controller调用API Server创建Pod
Scheduler收到消息,需要处理的新的Pod
Scheduler经过处理后决定把这个Pod绑定到Node1,调用API Server写入绑定
Node1上的Kubelet收到事消息需要处理Pod的部署
Node1上的Kubelet根据Pod的Spec进行Pod部署
可以看到基于list-watch的API Server实现了简单可靠的消息总线的功能,基于资源消息的事件链,解耦了各组件之间的耦合,配合之前提到的基于声明式的对象管理又确保了管理稳定性。从层次上来说,master的组件都是控制面的组件,用来控制管理集群的状态,node的组件是执行面的组件,kubelet是一个无脑执行者的角色,它们的交流桥梁是API Server的各种事件,kubelet是无法感知到控制器的存在的。
5、简单:API Sever收敛资源管理入口
如下图所示,API Server实现了基于插件+过滤器链的方式(比如我们熟知的Spring MVC的拦截器链)来实现资源管理操作的前置校验(身份认证、授权、准入等等)。
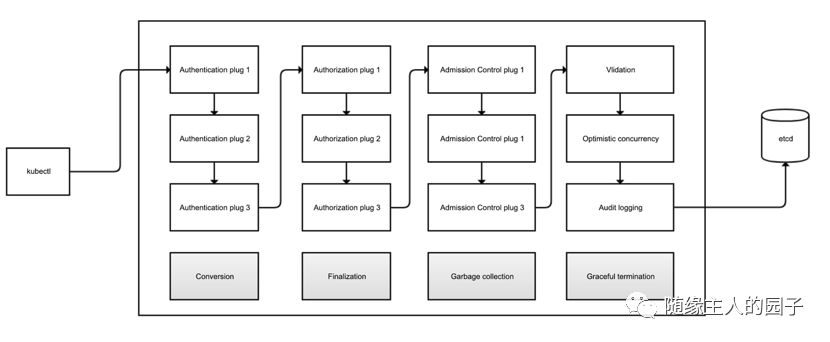
整个流程会有哪些环节呢:
身份认证,根据各种插件确定来者是谁
授权,根据各种插件确定用户是否有资格可以操作请求的资源
默认值和转换,资源默认值设置,客户端到etcd版本号转换
管理控制,根据各种插件执行资源的验证或修改操作,先修改后验证
验证,根据各种验证规则验证每一个字段有效性
幂等和并发控制,使用乐观并发方式(版本号方式)验证资源尚未被并发修改
审计,记录所有资源变更日志
如果是删除资源,还会有额外的一些环节:
优雅关闭
终接器钩子,可以配置一些终接器,在这个时候回调
垃圾回收,级联删除没有引用根的资源
对于复杂的流程式的操作,采用职责链+处理链+插件的方式来实现是很常见的做法。你可能会说这个API Server的设计总体上就不简单,怎么有这么多环节,其实这才是最简单的做法,每一个环节都有独立的插件来运作(插件可以独立更新升级,也可以根据需求动态插拔配置),每一个插件只是做自己应该做的事情,如果没有这样的设计,恐怕会出现1万行代码的一个大方法。
6、简单:Scheduler的设计
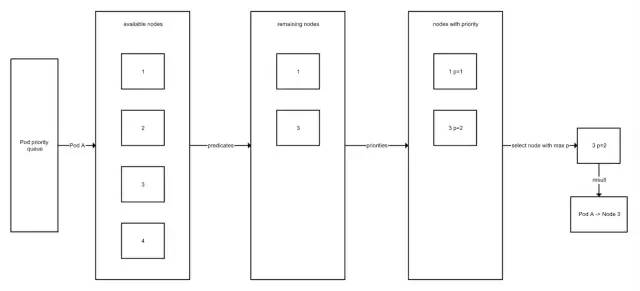
如图所示,类似于API Server的链式设计,Scheduler在做Pod调度算法的时候也采用了链式设计:
待调度的Pod本身有一个优先级的概念,优先级高的先调度
先找出所有的可用节点
使用predicate(过滤器)筛选节点
使用priority(排序器)对节点进行排序
选择最大优先级的节点调度给Pod
常见的predicate算法有:
端口冲突监测
资源是否满足
亲和性考量
……
常见的priority算法有:
网络拓扑临近
平衡资源使用
资源较多节点优先
已使用的节点优先
已缓存镜像节点优先
……
比如我们在做类似路由系统这种业务系统的时候可以借鉴这种设计模式。简单一词在于每一个小组件简单,它们可以组合起来构成复杂的规则系统,这种设计比把所有逻辑堆在一起简单的多。
7、扩展:分层架构
K8s的设计理念是类似Linux的分层架构:
核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析等)
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)
接口层:kubectl 命令行工具、客户端 SDK 以及集群联邦
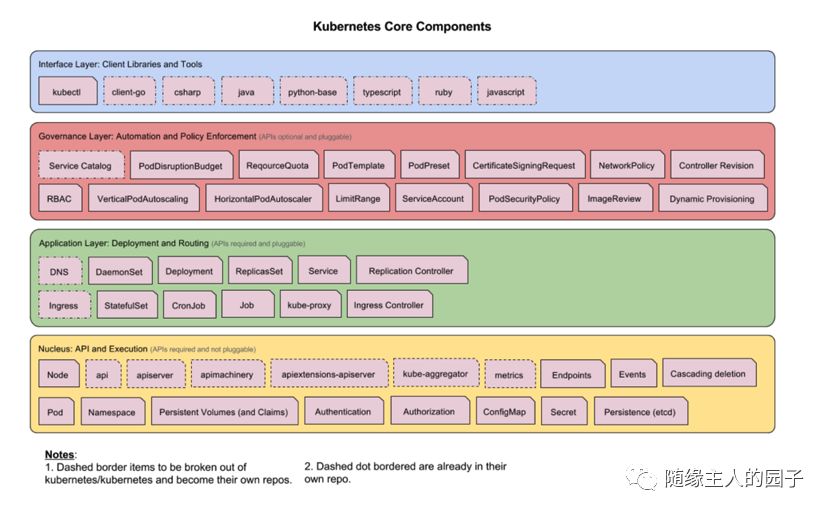
之前介绍的一些组件大多数位于核心层和应用层。在更上层的管理层和接口层,我们往往会做更多的一些二次开发。在之前的文章中我也介绍过,对于复杂的微服务互联网系统,我们也应该把微服务进行分层,从下到上分为基础服务、业务服务、聚合业务服务等,每一层的服务聚合下层实现一些业务逻辑,不但可以做到服务重用,而且上层多变的业务服务的变动可以不影响下层基础设施的搭建。
8、扩展:接口化和插件
除了k8s大量内部组件的实现使用了插件的架构,k8s在整体设计上就把核心和外部的一些资源和服务抽象为了统一的接口,可以插件方式插入具体的实现,如下图所示:
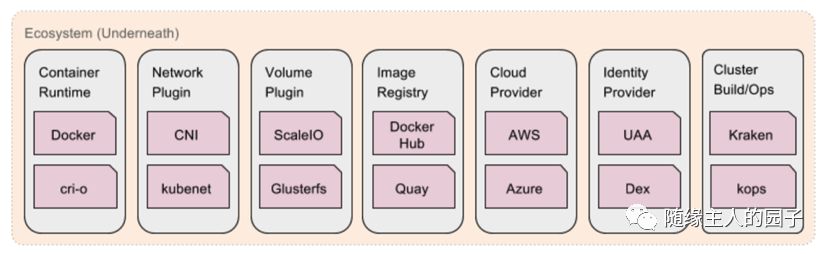
容器方面,容器运行时插件(Container Runtime Interface,简称 CRI)是 k8s v1.5 引入的容器运行时接口,它将 Kubelet 与容器运行时解耦,将原来完全面向 Pod 级别的内部接口拆分成面向 Sandbox 和 Container 的 gRPC 接口,并将镜像管理和容器管理分离到不同的服务。
网络方面,k8s支持两种插件:
kubenet:这是一个基于 CNI bridge 的网络插件(在 bridge 插件的基础上扩展了 port mapping 和 traffic shaping ),是目前推荐的默认插件
CNI:CNI 网络插件,Container Network Interface (CNI) 最早是由CoreOS发起的容器网络规范,是Kubernetes网络插件的基础。
存储方面,Container Storage Interface (CSI) 是从 k8s v1.9 引入的容器存储接口,用于扩展 Kubernetes 的存储生态。实际上,CSI 是整个容器生态的标准存储接口,同样适用于 Mesos、Cloud Foundry 等其他的容器集群调度系统 我们看下下面这个图,k8s使用CRI插件来管理容器,为容器配置网络的时候又走了CNI插件:
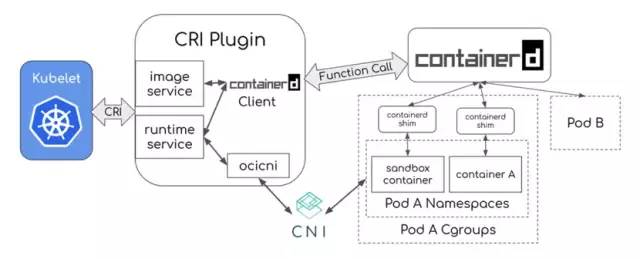
CNI、CSI、CRI我们比较熟悉了,其它更多的抽象接口这里就不描述了,k8s就像一个大主板,主板上有各种内存、CPU、IO、网络方面的接口,具体的实现k8s本身并不关心,用户和社区甚至可以根据的需要实现自己的插件。 我觉得这点是最了不起的最困难的,很多时候我们在设计一个系统的时候一开始是无法定义出抽象接口的,因为我们不知道将来会面对什么样的实现,只有到实现越来越多后我们才能抽象出接口才能制定标准。
9、扩展:PV & PVC & StorageClass
K8s在存储方面的解耦设计特别值得一提。如下图所示,我们来看一下k8s在存储这块的解耦设计:
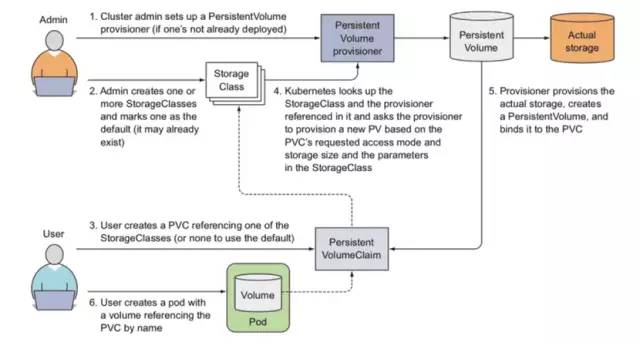
(图引自Kubernetes in Action一书)
我们要做的事情很明确,Pod需要绑定存储资源:
首先,我们肯定需要有卷这种抽象,来抽象出存储方式。但是,如果每次都让k8s的使用者(不管是运维还是开发)在部署Pod的时候设置需要的卷显然耦合太强了(比如NFS卷,每次都要设置地址,用于无需也无法关注到底层的这些细节)。卷V描述的是底层存储能力。
于是,k8s抽象出持久卷PV和和持久卷声明PVC的概念,管理员可以先设置配置PV映射到卷,用户只需要创建PVC来关联PV,然后在创建Pod的时候引用PVC即可,PVC并不关注卷的一些具体细节,只关注容量需求和操作权限。PV这层抽象描述的是运维能提供出来的全局卷的资源,PVC这层描述的是用户希望为Pod申请的存储资源请求。
但是总是需要运维先创建PV还是不方便,k8s还提供了StorageClass这层抽象,通过把PVC关联到指定的(或默认的)StorageClass来动态创建PV。
K8s中除了存储抽象的V、PV、PVC、SC,还有其它的一些组件也有类似层次的抽象以及动态绑定的理念。
我们在使用OO语言进行编程的时候,很自然知道我们需要先定义类,然后再实例化类来创建对象,如果类特别复杂(有不同的实现)的话,我们可能会使用工厂模式(或反射,外层传入目标类型名称)来创建对象。可以和k8s存储抽象比较一下,是不是这个意思,这其实就是一种解耦的方式,在架构设计中,甚至表结构设计中,我们完全可以引入类和实例的概念。比如工作流系统的工作流可以认为是一个类模板,每一次发起的工作流就是这个工作流的实例。
总结
好了,本文大概窥探了一下k8s的架构,不知道你是否感受到了k8s的精良设计,对内考虑了高可用以及高可靠,对外考虑到了高可扩展性。几乎任何操作都允许失败,最终实现一致的状态,几乎任何组件都允许扩展和替换,让用户实现自己的定制需求。
如果你的业务系统也是一套复杂的资源协调系统(k8s抽象的是运维相关的资源,我们的业务系统可以抽象的是其它资源),那么k8s的设计理念有相当多的点可以借鉴。举一个例子,我们在做一套很复杂的流程引擎,我们就可以考虑:
流程的执行者抽象出接口,插件方式插入系统
流程涉及到的资源我们可以先梳理清楚列出来
流程的管理可以把期望结果声明式方式存储到数据库
流程的管控组件可以都对着统一的API服务读写&订阅变化
流程的管控组件本身可以采用插件链、职责链方式执行
流程的入口可以由统一的网关收口做认证和鉴权等
……

