
- 1机器学习新宠:对比学习论文实现大合集,60多篇分门别类,从未如此全面_对比学习最新
- 2语言模型
- 3关于Attention的超详细讲解_attention详解
- 4对于Transformer的Mask机制的再思考--Decoder部分_transformer decoder mask
- 5Python NLP 入门教程_nlp入门教程
- 6java jolt_java – Jolt条件规范
- 7spacy库中文模型的安装_zh_core_web_sm
- 8spring Boot处理返回给前端Long类型精度丢失_springboot long类型到前端精度丢失
- 9python自然语言处理工具包“spaCy”安装教程_spacy python
- 10一日一技:在Python里面如何获取列表的最大n个元素或最小n个元素?
【附教程】2024,人工智能+声音,看这里就够了~16款AI音乐/音频/音效,声音克隆等ai软件与工具大合集~_音频+人工智能
赞
踩
AI音乐音频领域的技术正在迅速发展,为音乐创作和编辑带来了革命性的改变。这些技术通过深度学习和生成式模型,能够理解并模仿音乐的复杂结构和情感,从而创作出高质量的音乐作品。
AI音乐音频技术使得音乐创作变得更加高效和便捷。创作者只需提供简单的指示或参考材料,AI工具就能迅速生成符合要求的音乐,大大节省了创作时间和成本。同时,AI工具还能提供精细的控制功能,允许创作者对生成的音频进行编辑和调整,以满足个性化的需求。
未来,随着技术完善,AI音乐音频技术将为音乐创作和产业发展带来更多创新和突破。
以下工具包含:歌曲,音效,音乐,声音克隆,ai虚拟人等等声音声效的人工智能ai工具,市面上出现过的影视音内容基本都是这16款工具其中一个制作而成,文章包含工具的基础介绍,官方网址以及教程,如果还不能满足,请点击所属工具的相关内容网址,海量相关内容等您吸收~
音频专区:aigc
1. so-vits-svc
So-VITS-SVC是一个基于VITS的开源项目,VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一种结合变分推理(variational inference)、标准化流(normalizing flows)和对抗训练的高表现力语音合成模型。So-VITS-SVC可以快速生成AI歌曲,同时提供本地训练和推理教程,硬件需求为N卡,建议GPU达到GTX 3080显存8G以上。
去年风靡全网的“AI孙燕姿”就是用了这个技术~

其特点包括:
- 实现了音色转换功能,可以将原始声音的音色替换为模型训练好的音色。
- 提供了 Web UI 界面,方便用户进行音频处理和模型推理操作。
- 支持配置文件和模型文件的加载,使得用户可以灵活选择不同模型进行推理。
- 可以应用于生成 AI 音乐、音频处理等领域,具有一定的灵活性和扩展性。
更多相关内容:搜索结果 so-vits-svc-喜好儿网
https://heehel.com/aigc/xingchi-shengyin.html
https://heehel.com/aigc/ai-cover-singer.html
2. GPT-SoVITS
GPT-SoVITS是一款功能强大的AI音色克隆软件,通过简单输入5秒的声音样本,即可享受文字转语音的便利。产品支持跨语言,提供多种辅助工具,且微调模型仅需1分钟训练数据。支持在Windows环境下运行,为用户提供更灵活的使用体验。

GPT-SoVITS具备“零样本语音克隆”和“少样本语音克隆”功能。前者只需输入5秒的语音样本,就能立即体验文本到语音的功能,无需任何训练数据,就能生成与样本相似的语音;后者则是在1分钟的训练数据基础上,对模型进行微调,提高语音的相似性和真实感。只需简单几步,就能创建自己的TTS模型。
总的来说,GPT-SoVITS是一款强大的AI音色克隆软件,它为创作者提供了一个方便的工具,可以快速生成高质量的语音内容。
更多相关内容:搜索结果 GPT-SoVITS-喜好儿网
https://heehel.com/aigc/gpt-sovits-clone-sound.html
3. BERT-VITS2
BERT-VITS2是一种基于BERT和VITS2的语言模型,由华为Noah’s Ark实验室开发。这种模型结合了BERT的预训练和VITS2的微调,可以用于各种自然语言处理任务,如文本分类、命名实体识别、情感分析等。

相比传统的BERT模型,BERT-VITS2在多个任务上都取得了更好的性能表现。它采用了VITS2的微调方法,即在预训练后使用少量的标注数据进行微调,以提高模型在特定任务上的性能。此外,BERT-VITS2还引入了一些新技术,如动态掩码和多任务学习,以进一步提高模型的性能。
更多相关内容:搜索结果 BERT-VITS2-喜好儿网
Bert-vits2 官方地址:GitHub - fishaudio/Bert-VITS2: vits2 backbone with multilingual-bert
Bert-vits2 Fastapi推理页面项目:GitHub - jiangyuxiaoxiao/Bert-VITS2-UI: BertVITS2前端界面
https://heehel.com/aigc/bert-vits2-yenaifa.html
4. SadTalker
SadTalker是一种能够从音频中生成逼真的3D动画人脸的AI人工智能技术。通过StableDiffusion插件功能搭配使用,可以将静态的人像图像和音频合成为会说话的头像视频。除此之外,市面上还有其他一些AI工具,例如D-ID,也可以实现类似的功能,但需要付费使用。SadTalker既可以单独本地安装运行,也可以在Stable-Diffusion-WebUI中运行。
更多相关内容:搜索结果 sadtalker-喜好儿网
SadTalker详细使用流程及如何从官方网站下载安装教程:GitHub - OpenTalker/SadTalker: [CVPR 2023] SadTalker:Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
SadTalker Github 官方网站开源下载地址:GitHub - OpenTalker/SadTalker: [CVPR 2023] SadTalker:Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
https://heehel.com/ai-tutorial/sadtalker-usage-tutorial-one-minute.html
5. HeyGen
HeyGen 是一家推出了 Avatar2.0 的公司,该公司致力于数字创意领域,并引领虚拟分身创作新时代。HeyGen 的特点包括:
1. Avatar2.0 是一款 AI 视频翻译工具,能在手机上生成逼真的虚拟分身,用户只需短短 5 分钟即可完成。
2. HeyGen 提供多语言支持,通过内置的翻译工具,支持创建多语言内容。
3. 口型同步功能:支持口型同步和多语言声音匹配。
4. 免费使用:HeyGen 的服务是免费的,用户可以免费体验他们的创新技术。
5. Avatar2.0 支持 300 多种声音和 50 多种语言,具备准确的卡点能力,音色与用户母语相近,口型也能完美对上。
总的来说,HeyGen 公司通过 Avatar2.0 提供了用户前所未有的数字创作体验,让用户能够以全新的方式表达自己,引领了虚拟分身创作的新时代。
更多相关内容:搜索结果 heygen-喜好儿网
HeyGen官方免费使用网址链接:https://www.heygen.com/
https://heehel.com/aigc/heygen-jiaocheng.html
6. Elevelabs
ElevenLabs是一家专注于AI语音合成技术的初创公司,成立于2022年,该公司专注于开发人工智能语音模型和工具,可以创建不同语言、口音和情感的合成语音。 ElevenLabs主要功能:
AI语音合成:ElevenLabs提供文本转语音工具,支持多种类型的声音、风格和语言生成高质量的口语音频。AI语音合成功能可以将口语内容转换为另一种语言,同时保留原说话者的声音、语言模式、情感和语调。
AI语音克隆:ElevenLabs提供声音克隆工具,无需输入文本便可以快速克隆自己的声音。用户只需录制一段音频样本,AI语音克隆功能就可以快速复制说话者的声音,并生成与原声音高度相似的合成语音。
语音转语音:ElevenLabs的语音生成式AI平台发布了“语音转语音”功能,用户可上传语音并自动转换为不同音色,实现声音的自由切换,为用户带来全新的语音生成体验。
强强组合,以上视频是elevenlabsio给Sora 生成的视频自动配了音,通过原始提示词 + Video Pixel 识别!感觉离人工智能为我们生成的沉浸式世界的未来越来越近了。
Sora是OpenAI开发的一种文本到视频模型,具有强大的视频生成能力。根据OpenAI的介绍,Sora可以生成长达60秒的视频,其中包含了精细复杂的场景、生动的角色表情以及复杂的镜头运动。这一模型甚至可以根据用户的简单提示和静态图像,生成包含多个角色的视频画面,并且能够进行“脑补”和“扩展”现有视频片段。OpenAI将Sora视为一种强大的工具,可以用于内容创意行业。
更多相关内容:搜索结果 elevenlabs-喜好儿网
elevenlabs官方网站地址:AI Voice Generator & Text to Speech | ElevenLabs
https://heehel.com/aigc/how-to-use-elevenlabs.html
7. Suno AI
Suno是一家专门从文本生成AI音频的美国创业公司。他们的音乐生成模型Chirp是一种尖端模型,旨在将文本转换为完全实现的音乐作品,并配有特定风格的元素和歌词。最显着的进步之一是它能够将摇滚、流行、K-pop 等流派以及旋律或快节奏等描述符无缝转换为音乐表达。现在Chirp已经迭代到Chirp v1版本,该版本有以下新功能:

该版本有以下新功能:
- 增强的音频质量
- 选择音乐的风格/流派
- 现在支持50+ 种语言
- 使用[verse]和[chorus]等标签控制歌曲结构
- 更快的生成速度
更多相关内容:搜索结果 suno-喜好儿网
官方网站:Suno AI
https://heehel.com/aigc/suno-ai-usage-demo.html
8. Musicfy AI
Musicfy AI 是一家利用人工智能技术创建音乐的创新网站。通过最新的AI技术,它提供了一系列令人惊叹的功能和工具,帮助音乐创作者在创作过程中发挥更大的创造力。 提供人工智能音乐助手,让音乐创作者能够在创作过程中获得AI的辅助。
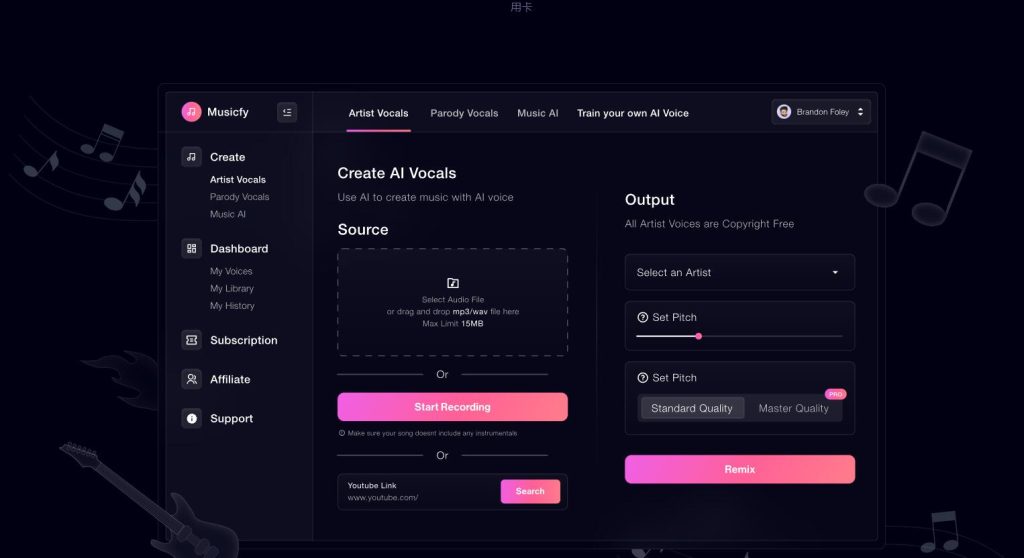
此外,Musicfy AI 还引入了无版权声明,为创作者提供全新的声音资源。而最新奇的使AI仿声作曲功能带来无限乐趣,用户还可以上传自己的声音,创建与自己声音相似的AI音乐模型。自己随口哼的声音或模仿节奏就能重新制作任何歌曲。
用户能够从任何歌曲中分离出特定的音轨,如鼓、人声、贝斯等。此外,AI文字转音乐功能允许用户将文字和情感转化为美妙的歌曲。
更多相关内容:搜索结果 Musicfy-喜好儿网
MusicfyAI官方网站使用地址:
Musicfy AI - AI Voice Song Generator
9. Loudly
Loudly是一个专为现代创作者量身打造的平台。尽管它的整体功能相较于之前介绍的AI音乐生成器Beatoven AI略显简洁,但正所谓“麻雀虽小,五脏俱全”,Loudly同样具备丰富的创作选项。
创作者可以在Loudly上选择音乐流派、节奏、调子、曲目结构以及速度等参数,所有操作都设计得极为简单直观,而且音乐生成速度也相当快。每次操作,平台都会生成3首音乐供用户选择,大大提高了创作的灵活性和效率。

更为出色的是,Loudly还支持文字转音乐功能。用户只需通过文字描述自己的创作意图,即可在生成创作界面上得到反映,从而更容易、更准确地生成符合用户想象的音乐作品。
更多相关内容:搜索结果 loudly-喜好儿网
loudly官方网站地址:
AI music for your creative universe | Loudly
10. Beatoven AI
Beatoven AI是一款专为影视、游戏、自媒体创作者打造的人工智能音乐生成平台,旨在为他们提供便捷的背景音乐创作工具。该平台界面设计简约大方,操作简单易懂,用户只需通过提供文本提示,便能轻松生成高质量的AI音乐。
与suno AI相比,Beatoven AI更侧重于纯音乐的生成。在创作流程上,Beatoven AI全程采用可视化操作,无需编写任何代码。用户只需通过简单的几步操作,如选择曲风、调节节奏情绪、设定时长和速度等,便能快速生成自己专属的AI音乐。值得一提的是,该平台最高能生成15分钟时长的音乐,充分满足用户在不同场景下的需求。

此外,Beatoven AI还配备了一个功能强大的编辑器,提供16种丰富的选项供用户选择。用户可以根据自己的实际需求,配合上传的视频进行在线编辑,如更换乐器、修改内容等,从而打造出更加符合场景氛围的音乐作品。
更多相关内容:搜索结果 beatoven-喜好儿网
beatovenAI官方网站地址:
Beatoven.ai: Royalty Free AI Music Generator.
https://heehel.com/aigc/beatoven-ai.html
11. Stable Audio
Stable Audio是一款功能强大的AI工具,能够从零开始生成音乐,为音乐人和音乐创作人员提供了极大的便利。用户只需通过简单的指示,Stable Audio就能迅速生成高质量的音乐和音效,满足各种创作需求。
Stable Audio的工作原理主要基于先进的生成式AI技术。它运用VAE(变分自编码器)技术,将立体声音频进行高效的数据压缩,形成抗噪、可逆的有损潜在编码。这一创新的设计使得生成和训练过程比直接使用原始音频样本更为高效和精确。

在生成音乐的过程中,Stable Audio还采用了文本编码器。这个编码器能够从用户提供的文本提示中提取关键特征,并将这些特征用于调整扩散模型。扩散模型基于U-Net结构,结合了残差层、自注意层和交叉注意层,用于去噪输入并重新构建出符合用户需求的音频。
无论是用于创建音效、背景音乐,还是创作完全原创的音乐作品,Stable Audio都能发挥出其强大的功能。它以其高效、精准的特点,为音乐创作领域注入了新的活力,让音乐创作变得更加简单、高效。
更多相关内容:搜索结果 Stable Audio-喜好儿网
Stable Audio官网链接:Audio — Stability AI
https://heehel.com/aigc/ai-arranger-stable-audio.html
12. Audiobox
Audiobox 是Meta 的新基础研究模型,用于音频生成。可以使用语音输入和自然语言文本提示生成声音和音效,使得为各种用途创建自定义音频变得容易。它可以用于许多行业,包括广告、媒体、游戏开发和虚拟现实等。对于那些需要自定义声音和音效的项目或产品,Audiobox 提供了一个简单而有创意的解决方案。它还可以用于语音助手、语音提示和电子学习等领域。总的来说,Audiobox 可以在许多行业中提供创造性和实用性的帮助和影响。
更多相关内容:搜索结果 Audiobox-喜好儿网
Audiobox官方网站地址:
https://audiobox.metademolab.com/
13. M2UGen
腾讯与新加坡国立大学共同发布的AI模型M2UGen,具有出色的音乐理解和多模态音乐生成能力。它不仅可以通过文本、图像和视频生成音乐,还能根据用户需求进行乐器和节奏的编辑。M2UGen的出现为AI音乐创作领域提供了强大支持,让普通人也能发挥创造力,创作出多样化的音乐作品。这一创新技术将推动音乐创作领域的发展,为音乐爱好者带来更多可能性。
更多相关内容:搜索结果 m2ugen-喜好儿网
https://heehel.com/aigc/m2ugen.html
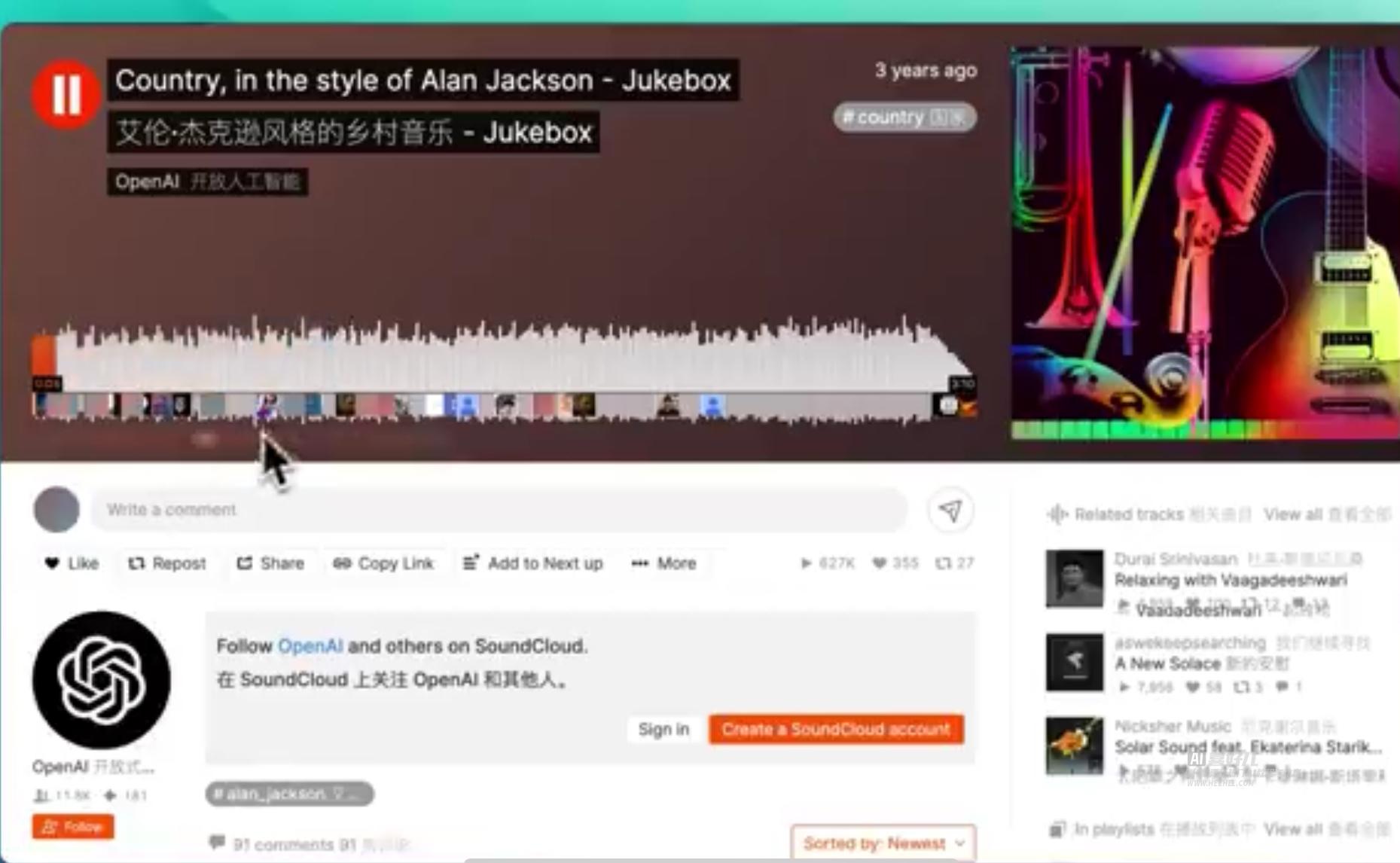
14. Jukebox
原来OpenAI 3年前就开始搞AI音乐生成了
效果甚至比最近发布的sunoAI v3还要好,难道OpenAI 想把这个隐藏大招练成无人能敌的状态才放出来再一次轰动全球?
OpenAI在2019年8月份就推出了他们的一音乐生成模型:Jukebox
Jukebox能够根据提供的歌词、艺术家和流派信息生成多种流派和艺术家风格的完整音乐和人声歌曲。
论文PDF:https://cdn.openai.com/papers/jukebox.pdf
更多相关内容:搜索结果 Jukebox-喜好儿网
https://heehel.com/ai-news/openai-jukebox.html
15. Project Music GenAI Control(Adobe)
Adobe的“Project Music GenAI Control”是一款处于初期阶段的实验性AI音乐工具,允许创作者通过文本提示生成音乐,并提供细粒度的控制来编辑生成的音乐,包括音乐强度调整、重新混音、改变音乐节奏以及生成无缝可重复循环的循环等功能。这个工具有望为音乐创作带来更多可能性和灵感来源。

更多相关内容:搜索结果 Project Music GenAI Control-喜好儿网
16. Image to music V2
Image to Music V2 是一款免费的图生成音乐 AI 工具,用户只需上传一张图片,即可生成相应感觉的音乐。虽然Image to Music V2在功能上与之前介绍的Beatoven相比稍显逊色,但其短小精悍的特点使其非常适合小型有声读物或过场配乐的创作者使用。
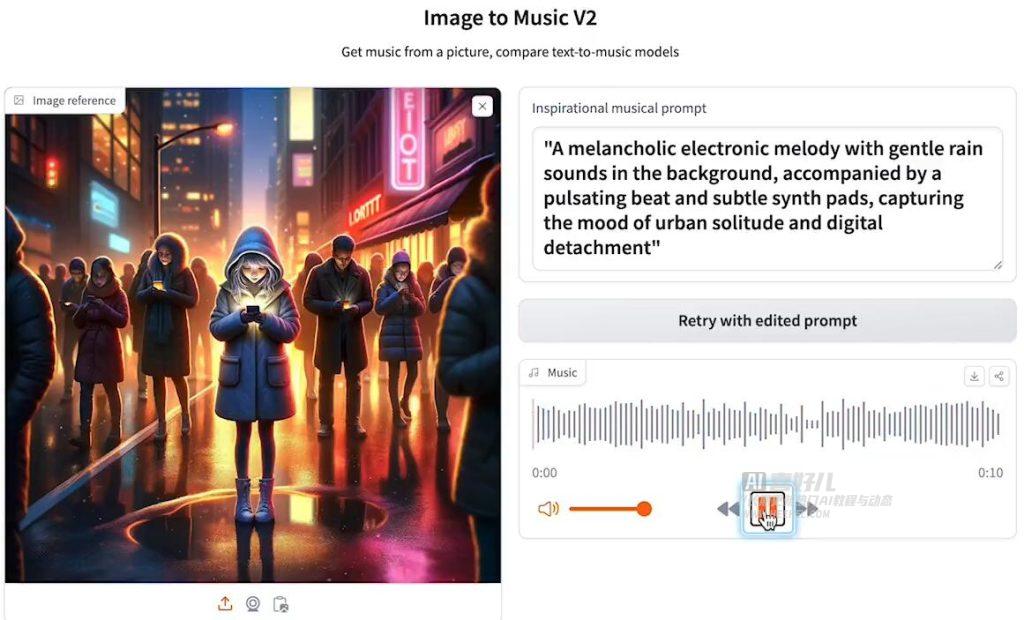
其特点包括:
- 简单易用:只需上传一张图片,即可生成音乐,操作简单方便。
- AI 技术支持:通过 LLM 模型进行代理分析用户上传的图像内容,生成相应的音乐。
- 生成速度快:虽然生成时间不长,但适合作为封面配乐使用。
- 适用范围广:适合小型有声读物或过场配乐创作者使用。
- 在线体验:提供在线体验地址,用户可随时随地使用。
总的来说,Image to Music V2 是一款简单实用的 AI 音乐生成工具,适合需要快速生成音乐的用户使用。
更多相关内容:搜索结果 Image to music V2-喜好儿网
Image to Music在线体验地址:
https://heehel.com/BGM%20tools
https://heehel.com/aigc/image-to-music-v2.html
以上是目前业内呼声较高,以及相对主流的16个AI音频软件或插件,基本可以满足您音频生成的所有需求~
如果想了解更多AI绘画,AI视频,AI文本等软件专题内容,请关注:喜好儿网(https://heehel.com)
https://heehel.com/aigc/ai-vid-topic.html
https://heehel.com/aigc/ai-text-2-image.html

