
- 1el-table的各个属性5.17_el-table属性
- 2Dependency ‘org.springframework.cloud:spring-cloud-starter-config:‘ not found_dependency 'org.springframework.cloud:spring-cloud
- 3Windows的cmd运行编译器(cmd运行c/c++、python等)_windows cmd python
- 42023如果纯做业务测试的话,在测试行业有出路吗?_业务测试是不是最简单的
- 5MAC 安装PHP及环境配置 保姆级别_formula.jws.json: update failed, falling back to c
- 6xcode通过链接ssh 链接git_xcode 配置ssh
- 7fastapi响应数据处理_fastapi中間件修改響應
- 8一篇文章带你入门文件上传漏洞_如何利用文件上传漏洞
- 9c语言中输入一个字符串直到遇到回车为止,C语言程序设计实践第四章.pptx
- 10“BS,“ “PL,“ 和 “CF“ 是财务报告中常用的缩写,它们分别代表财务报表的不同部分_bs pl
写给初学者的YOLO目标检测 概述_tesla t4跑yolo有什么优势
赞
踩
文章目录
- 什么是目标检测
- What is YOLO?
- 为什么YOLO在目标检测领域如此流行?
- YOLO架构
- YOLO目标检测是如何工作的?
- YOLO的应用场景
- YOLO, YOLOv2, YOLO9000, YOLOv3, YOLOv4, YOLOR, YOLOX, YOLOv5, YOLOv6, YOLOv7比较
- 结论
本文主要介绍; YOLO(You Only Look Once) 目标检测的 优势、它在过去几年中的发展情况以及一些现实生活中的应用。
什么是目标检测
目标检测(Object detection)是计算机视觉中使用的一种技术,用于识别和定位图像或视频中的对象。
图像定位是指使用边界框(bounding boxes)来识别一个或多个对象的正确位置的过程,这些边界框对应于围绕对象的矩形形状。
这个过程有时会与图像分类或图像识别混淆,后者旨在将图像或图像中的对象预测为类别或类别之一。
下面的插图对应于上述解释的计算机视觉技术。在图像中检测到的对象是“人”。

在本文中,将首先了解目标检测的优势,然后介绍最先进的目标检测算法YOLO。
在第二部分中,我们将更加关注YOLO算法及其工作原理。之后,我们将提供一些使用YOLO的实际应用。
最后一节将解释YOLO从2015年到2020年的演变,然后总结下一步的步骤。
What is YOLO?
You Only Look Once (YOLO) 是一种最先进的实时目标检测算法,由Joseph Redmon、Santosh Divvala、Ross Girshick和Ali Farhadi于2015年在他们著名的研究论文“You Only Look Once: Unified, Real-Time Object Detection”中引入。
YOLO 的核心思想就是把目标检测转变成一个回归问题,而不是分类任务。利用整张图作为网络的输入,仅仅经过单个卷积神经网络 (CNN),得到bounding box(边界框) 的位置及其所属的类别。
为什么YOLO在目标检测领域如此流行?
YOLO之所以领先竞争对手,原因包括:
- 速度快
- 检测精度高
- 良好的泛化能力
- 开源
1. 速度快
YOLO之所以非常快,是因为它不涉及复杂的流程。它可以以每秒45帧的速度处理图像。此外,与其他实时系统相比,YOLO的平均精度(mAP)超过了两倍,使其成为实时处理的绝佳选择。从下面的图表中,我们可以看到YOLO的速度远远超过其他目标检测器,达到了91 FPS。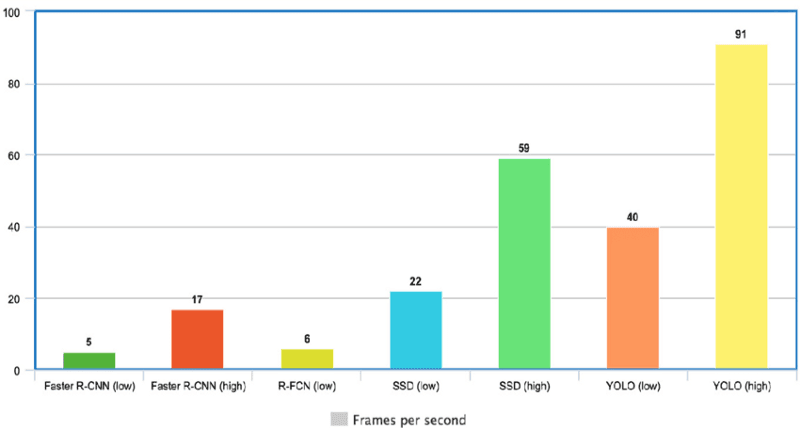
2. 高检测精度
YOLO的准确性远远超过其他最先进的模型,几乎没有背景误差。
3. 更好的泛化性
特别是对于新版本的YOLO,本文稍后会讨论。通过这些改进,YOLO在新领域提供了更好的泛化性能,使其非常适合依赖快速和强大的目标检测应用程序。例如,《使用YOLO深度卷积神经网络自动检测黑色素瘤》的研究表明,YOLOv1版本的平均精度最低,而YOLOv2和YOLOv3版本的平均精度更高。
4. 开源
将YOLO开源使得社区可以不断改进模型。这是YOLO在有限的时间内取得如此多改进的原因之一。
YOLO架构
YOLO架构类似于GoogleNet。如下图所示,它总共有24个卷积层,四个最大池化层和两个全连接层。
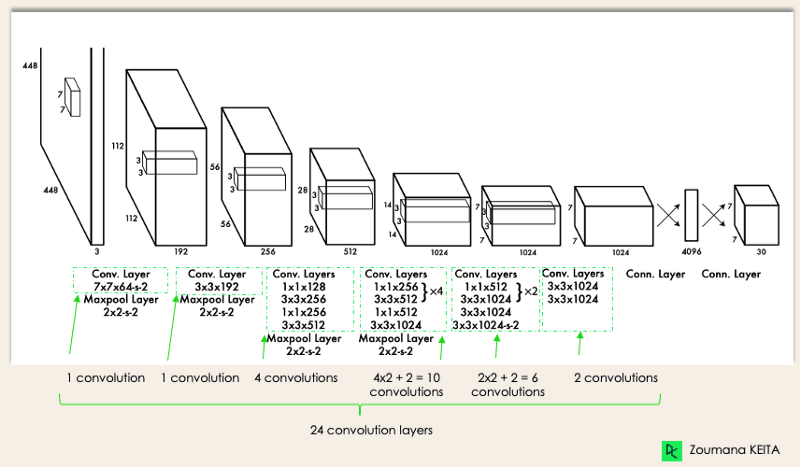
该架构的工作方式如下:
- 将输入图像调整为448x448,然后通过卷积网络处理。
- 首先应用1x1卷积来减少通道数,然后是3x3卷积来生成一个立方体输出。
- 在内部使用的激活函数是ReLU,除了最后一层使用线性激活函数。
- 一些额外的技术,如批量归一化和dropout,分别对模型进行正则化并防止过拟合。
YOLO目标检测是如何工作的?
上一节已经了解了YOLO的架构,让我们简单介绍一下YOLO算法如何使用一个简单的用例来执行目标检测。
想象一下,你构建了一个YOLO应用程序,可以从给定的图像中检测出球员和足球。但是如何向某个人,特别是非专业人士解释这个过程呢?
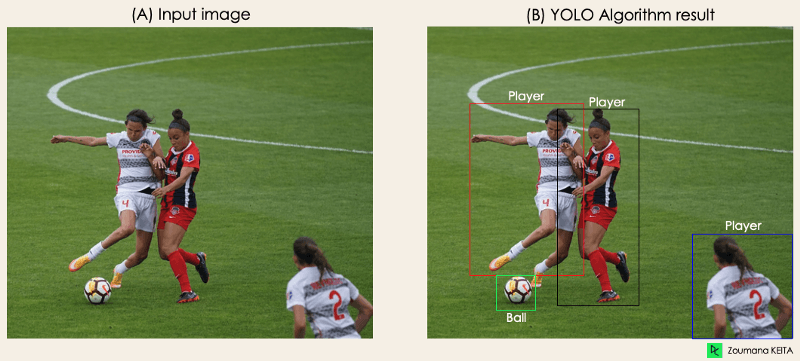
该算法基于以下四种方法进行操作:
- 残差块(Residual blocks)
- 边界框回归(Bounding box regression)
- 交并比 IoU (Intersection over Union)
- 非极大值抑制(Non-Maximum Suppression)
让我们更详细地了解每一种方法。
残差块(Residual blocks)
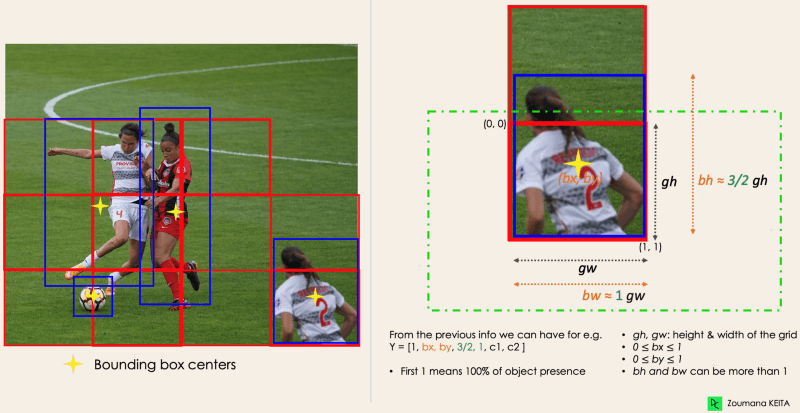
这一步首先将原始图像(A)划分为NxN个具有相等形状的网格单元,其中N在我们的案例中为4,如右侧的图像所示。网格中的每个单元负责定位和预测其覆盖的对象的类别,以及概率(probability)/置信度值(confidence value.)。

边界框回归(Bounding box regression)
下一步是确定与图像中的所有对象相对应的边界框,可以有与给定图像中的对象数量相同的边界框。YOLO使用以下格式的单个回归模块确定这些边界框的属性,其中Y是每个边界框的最终向量表示。
Y = [pc,bx,by,bh,bw,c1,c2]
这在模型的训练阶段尤为重要。
- pc对应于包含对象的网格的概率分数。例如,所有红色网格的概率分数都将大于零。右侧的图像是简化版本,因为每个黄色单元格的概率为零(insignificant)。
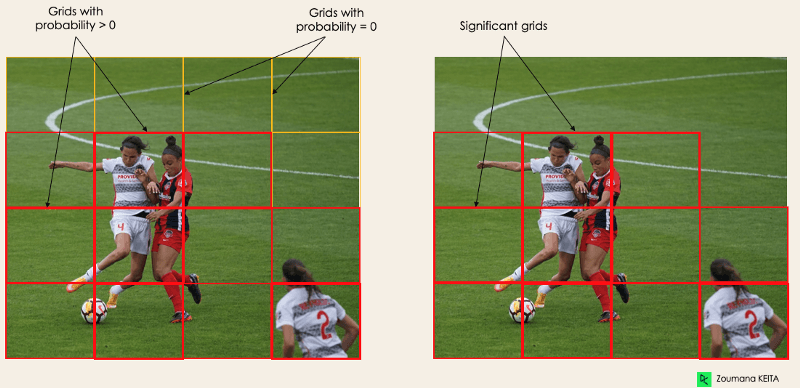
-
bx和by是边界框的中心坐标,相对于包围它的网格单元。
-
bh和bw是边界框的高度和宽度,相对于包围它的网格单元。
-
c1和c2对应于两个类别Player和Ball。你可以根据你的应用需求拥有任意数量的类别。
为了更好地理解,让我们更仔细地观察右下角的球员。
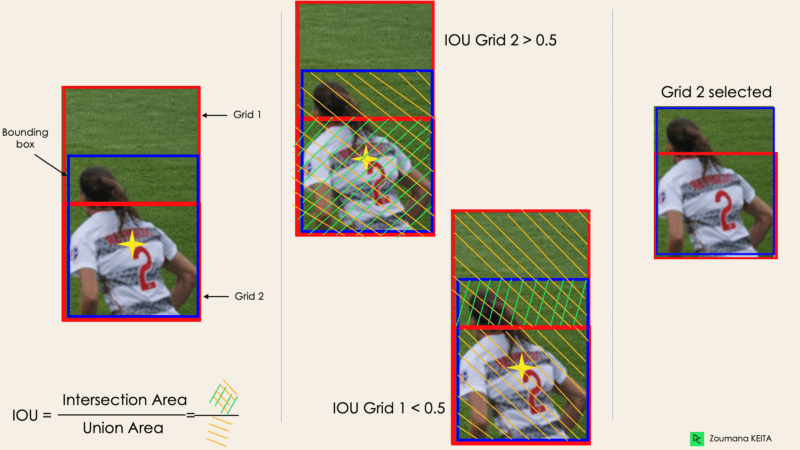
交并比 IoU (Intersection over Union)
通常情况下,一张图像中的单个物体可能有多个网格框作为预测结果,但并非所有网格框都是相关的。IOU(介于0和1之间的值)的目标是舍弃这些无关的网格框,只保留相关的网格框。其逻辑如下:
-
用户定义其IOU选择阈值,例如0.5。
-
然后,YOLO计算每个网格单元的IOU,即交集面积除以并集面积。
-
最后,它忽略IOU ≤ 阈值的网格单元的预测结果,并考虑IOU>阈值的网格单元。
下面是将网格选择过程应用于左下角物体的示例。我们可以观察到,该物体最初有两个网格框候选,最终只选择了“Grid 2”。
非极大值抑制(Non-Maximum Suppression)
设置IOU的阈值并不总是足够的,因为一个物体可能有多个框与阈值的IOU值相同,如果保留所有这些框,可能会包含噪声。这就是我们可以使用NMS来仅保留具有最高检测概率分数的框的原因。
YOLO的应用场景
YOLO目标检测在我们日常生活中有不同的应用。在这一部分中,我们将涵盖以下领域的一些应用:医疗保健、农业、安全监控和自动驾驶汽车。
1- 应用于工业领域
目标检测已经被引入到许多实际的工业领域,如医疗保健和农业。让我们通过具体的例子来了解每一个领域。
医疗
在医疗领域,特别是在手术中,由于患者之间的生物多样性,实时定位器官可能具有挑战性。Kidney Recognition in CT使用YOLOv3来帮助在计算机断层扫描(CT)中定位二维和三维肾脏。
农业
人工智能和机器人在现代农业中扮演着重要角色。收割机器人是基于视觉的机器人,用于代替手工采摘水果和蔬菜。在这个领域中最好的模型之一使用了YOLO。在《基于修改后的YOLOv3框架的番茄检测》中,作者描述了他们如何使用YOLO来识别不同类型的水果和蔬菜,以实现高效收获。

安全监控
在安全监控领域,虽然物体检测技术被广泛应用,但这并不是唯一的应用。在 COVID-19 疫情期间,YOLOv3 被用来估计人们之间的社交距离违规情况。你可以从《基于深度学习的 COVID-19 社交距离监测框架》进一步了解这个话题。
YOLO, YOLOv2, YOLO9000, YOLOv3, YOLOv4, YOLOR, YOLOX, YOLOv5, YOLOv6, YOLOv7比较
自从2015年YOLO首次发布以来,它已经通过不同版本不断发展。在本节中,我们将了解每个版本之间的区别。
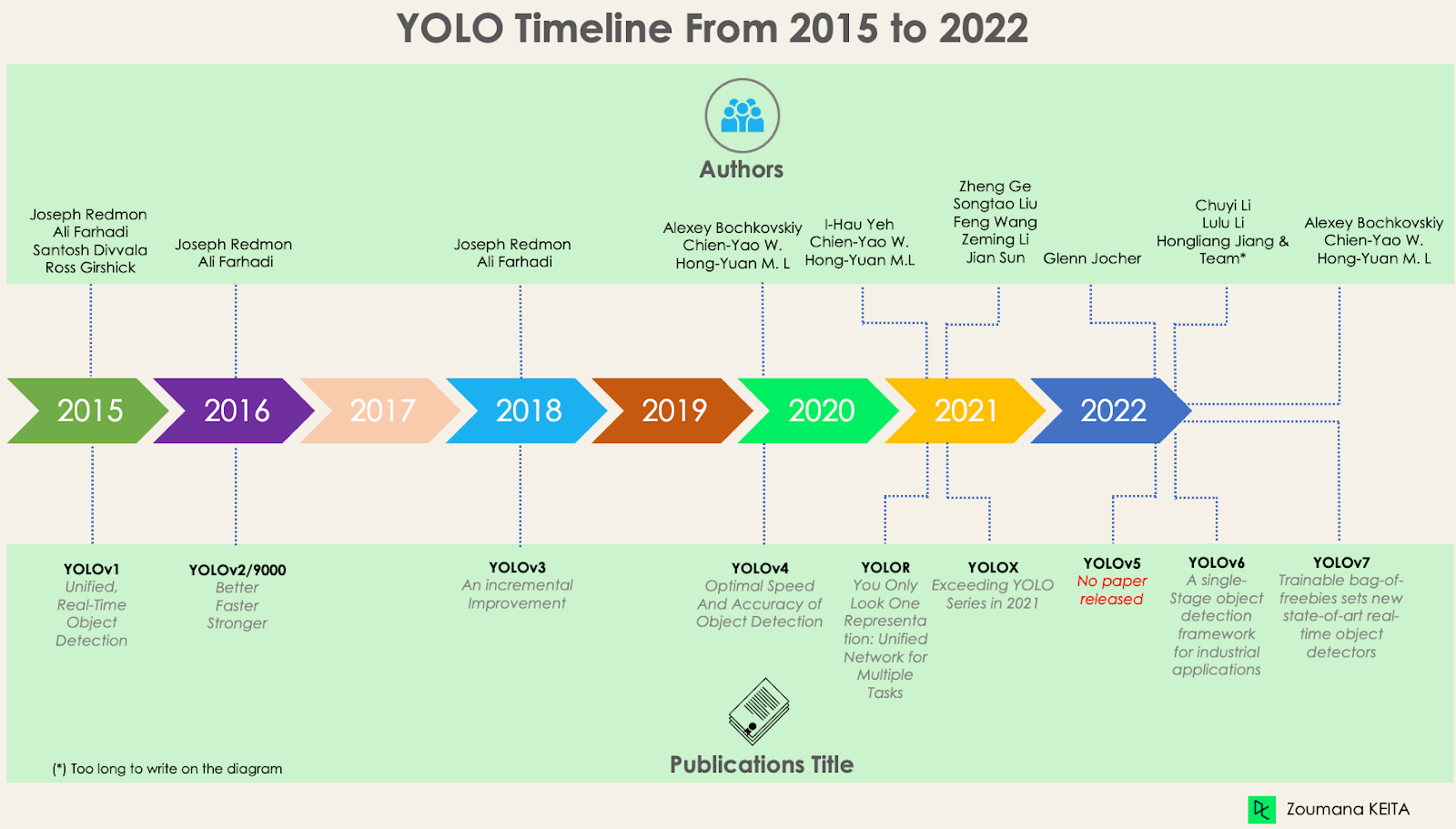
YOLO/YOLOv1,起点
YOLO的第一个版本由于快速高效地识别物体的能力而成为目标检测的改变者。
然而,像许多其他解决方案一样,YOLO的第一个版本也有其自身的局限性:
- 它难以检测图像组中的较小图像,例如体育场中的一组人。这是因为YOLO架构中的每个网格都设计用于单个对象检测。
- 然后,YOLO无法成功检测新的或不寻常的形状。
- 最后,用于近似检测性能的损失函数对小型和大型边界框的误差进行相同处理,从而创建错误的定位。
YOLOv2或YOLO9000
YOLOv2是在2016年创建的,旨在使YOLO模型更好、更快、更强。
改进包括但不限于使用Darknet-19作为新的架构、批量归一化、更高的输入分辨率、具有锚点的卷积层、维度聚类和细粒度特征。
1-批量归一化,添加批量归一化层将性能提高
1- 批量归一化(批标准化)
添加批量归一化层可以提高2%的mAP性能。这种批量归一化包括正则化效果,防止过拟合。
2- 更高的输入分辨率
YOLOv2直接使用更高分辨率的448×448输入,而不是224×224,这使得模型调整其滤波器以在更高分辨率的图像上表现更好。在ImageNet数据上训练10个时期后,这种方法将准确性提高了4%的mAP。
3- 使用锚框的卷积层
YOLOv2简化了问题,用锚框替换完全连接层,而不是像YOLOv1那样预测物体边界框的精确坐标。这种方法略微降低了准确性,但将模型召回率提高了7%,为改进提供了更大的空间。
4- 维度聚类
上述提到的锚框是由YOLOv2使用k = 5的k-means维度聚类自动发现的,而不是手动选择。这种新颖的方法在模型的召回率和精度之间提供了良好的折衷。
为了更好地理解k-means维度聚类,请查看我们的Python中使用scikit-learn的K-Means聚类和R中的K-Means聚类教程。它们深入探讨了使用Python和R进行k-means聚类的概念。
5- 细粒度特征
YOLOv2预测生成13x13的特征图,这对于大型物体检测当然足够了。但是,对于更细的物体检测,可以通过将26×26×512特征图转换为13×13×2048特征图并与原始特征串联来修改架构。这种方法将模型性能提高了1%。
YOLOv3 - 渐进式改进
在YOLOv2的基础上进行了渐进式改进,创建了YOLOv3。
主要的变化包括一个新的网络架构:Darknet-53。这是一个106层的神经网络,具有上采样网络和残差块。与YOLOv2的骨干网络Darknet-19相比,它更大、更快、更准确。这种新的架构在许多方面都有益处:
1- 更好的边界框预测
YOLOv3使用逻辑回归模型为每个边界框预测物体得分。
2- 更准确的类别预测
与YOLOv2中使用的softmax不同,引入了独立的逻辑分类器来准确预测边界框的类别。这在面对具有重叠标签的更复杂领域时非常有用(例如,人→足球运动员)。使用softmax会限制每个框只有一个类别,这并不总是正确的。
3- 在不同尺度上更准确的预测
YOLOv3对每个位置在输入图像中进行三次不同尺度的预测,以帮助从前一层进行上采样。这种策略允许获得细粒度和更有意义的语义信息,以获得更高质量的输出图像。
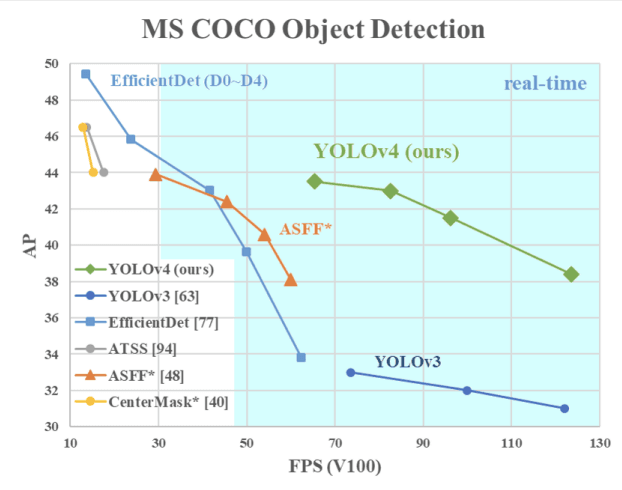
YOLOv4 - 目标检测的最佳速度和准确性
与所有先前版本和其他最先进的目标检测器相比,这个版本的YOLO具有最佳的目标检测速度和准确性。
下面的图像显示,与YOLOv3相比,YOLOv4的速度提高了10%,与FPS相比提高了12%。
YOLOv4是专门为生产系统设计的,并针对并行计算进行了优化。
YOLOv4架构的主干是CSPDarknet53,这是一个包含29个卷积层的网络,具有3 x 3滤波器和大约2760万个参数。
与YOLOv3相比,该架构增加了以下信息以实现更好的物体检测:
- 空间金字塔池化(SPP)块显着增加了感受野,分离了最相关的上下文特征,并不影响网络速度。
- YOLOv4使用PANet而不是YOLOv3中使用的特征金字塔网络(FPN)来进行来自不同检测级别的参数聚合。
- 数据增强使用拼贴技术,将四个训练图像组合在一起,并采用自适应对抗性训练方法。
- 使用遗传算法执行最佳超参数选择。
感受野: 卷积神经网络每一层输出的特征图(feature map)上的像素点映射回输入图像上的区域大小。通俗点的解释是,特征图上一点,相对于原图的大小,也是卷积神经网络特征所能看到输入图像的区域
YOLOR — You Only Look One Representation
YOLOR是一个多任务统一网络,它基于显式和隐式知识方法的组合统一网络。
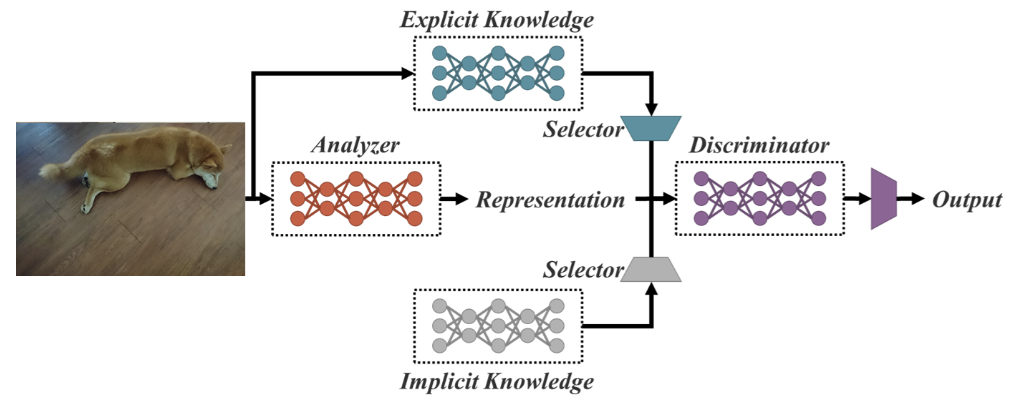
显性知识和隐性知识
显性知识是指正常或有意识的学习。而隐性学习则是指通过经验在潜意识中进行的学习。
将这两种技术结合起来,YOLOR能够基于三个过程创建更强大的架构:(1)特征对齐,(2)目标检测的预测对齐,以及(3)多任务学习的规范表示。
1- 预测对齐
这种方法在每个特征金字塔网络(FPN)的特征图中引入了隐式表示,可以将精度提高约0.5%。
2- 目标检测的预测细化
通过向网络的输出层添加隐式表示,可以对模型预测进行细化。
3- 多任务学习的规范表示
执行多任务训练需要在所有任务共享的损失函数上执行联合优化。这个过程可能会降低模型的整体性能,而在模型训练期间集成规范表示可以缓解这个问题。
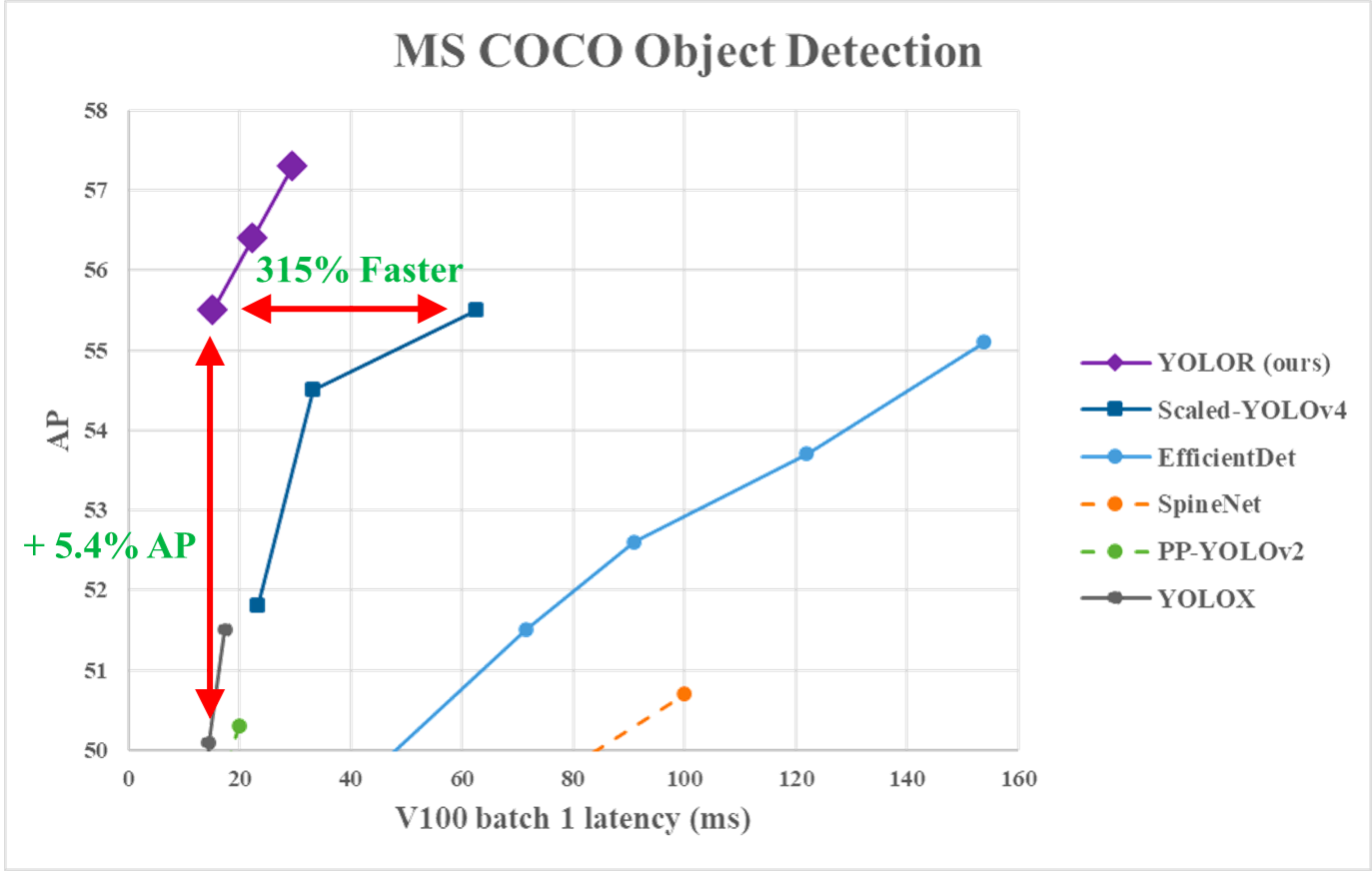
从下面的图表中,我们可以看到YOLOR在MS COCO数据上实现了与其他模型相比的最先进的推理速度。
YOLOX - 2021年超越YOLO系列
本文使用YOLOv3的修改版作为基线,并以Darknet-53作为其骨干网络。
《YOLOX: Exceeding YOLO Series in 2021》一文中,YOLOX提供了以下四个关键特性,以创建比旧版本更好的模型。
1- 高效分离的头部
在之前的YOLO版本中使用的联合头部被证明会降低模型的性能。YOLOX使用了分离的头部,可以将分类和定位任务分开,从而提高了模型的性能。
2- 强大的数据增强
将Mosaic和MixUp集成到数据增强方法中,显著提高了YOLOX的性能。
3- 无锚点系统
基于锚点的算法在内部执行聚类,这会增加推理时间。在YOLOX中去除了锚点机制,减少了每个图像的预测数量,并显著提高了推理时间。
4- SimOTA标签分配
作者引入了SimOTA,一种更强大的标签分配策略,而不是使用交并比(IoU)方法。SimOTA不仅减少了训练时间,还避免了额外的超参数问题,从而实现了最先进的结果。此外,它将检测mAP提高了3%。
YOLOv5
相较于其他版本,YOLOv5没有发表研究论文,是第一个在Pytorch中实现而非Darknet的YOLO版本。
由Glenn Jocher于2020年6月发布,YOLOv5与YOLOv4类似,使用CSPDarknet53作为其架构的主干。发布包括五种不同的模型大小:YOLOv5s(最小)、YOLOv5m、YOLOv5l和YOLOv5x(最大)。
YOLOv5架构中的一个主要改进是集成了Focus层,由单个层表示,通过替换YOLOv3的前三层来创建。该集成减少了层数和参数数量,并且在不对mAP产生重大影响的情况下增加了前向和后向速度。
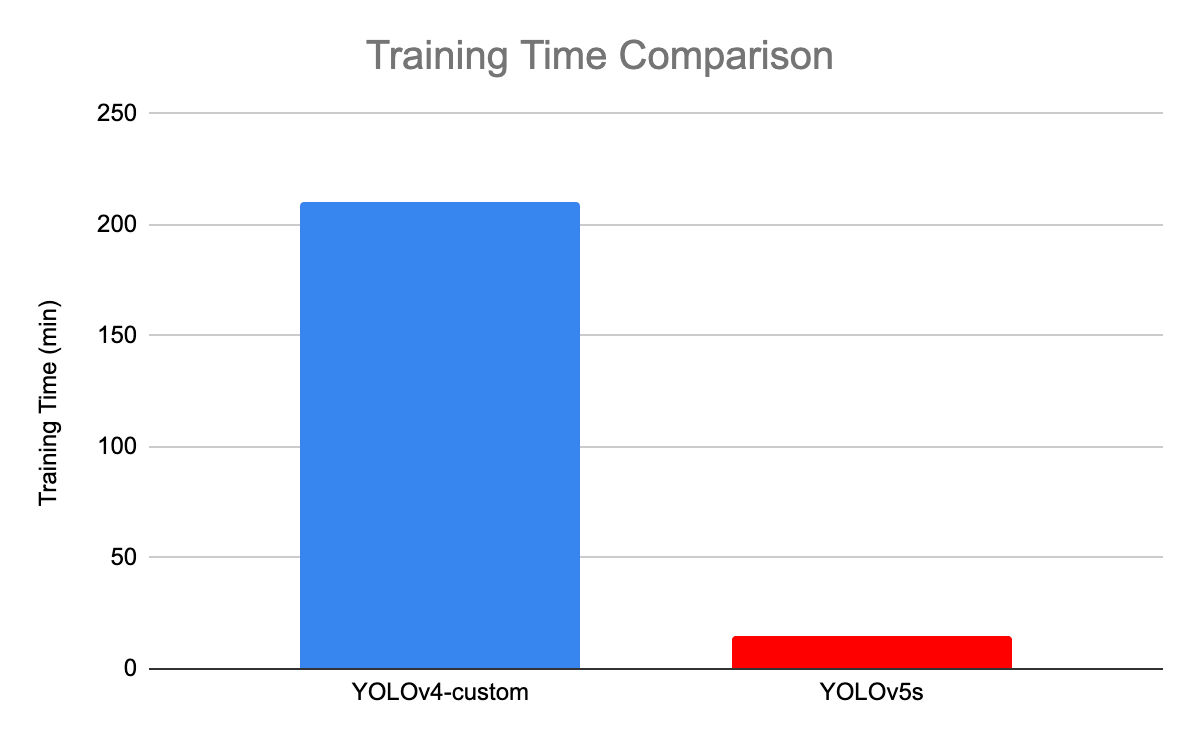
以下插图比较了YOLOv4和YOLOv5s之间的训练时间。
YOLOv6 - 一种面向工业应用的单阶段物体检测框架
由中国电商公司美团推出的 YOLOv6 (MT-YOLOv6) 框架专门针对工业应用进行了硬件友好的高效设计和高性能的优化。
该框架是用 Pytorch 编写的,虽然不是官方 YOLO 的一部分,但其主干受到了原始单阶段 YOLO 架构的启发而被命名为 YOLOv6。
相对于先前的 YOLOv5,YOLOv6 在硬件友好的主干和颈部设计、高效的解耦头部和更有效的训练策略方面引入了三项重大改进。
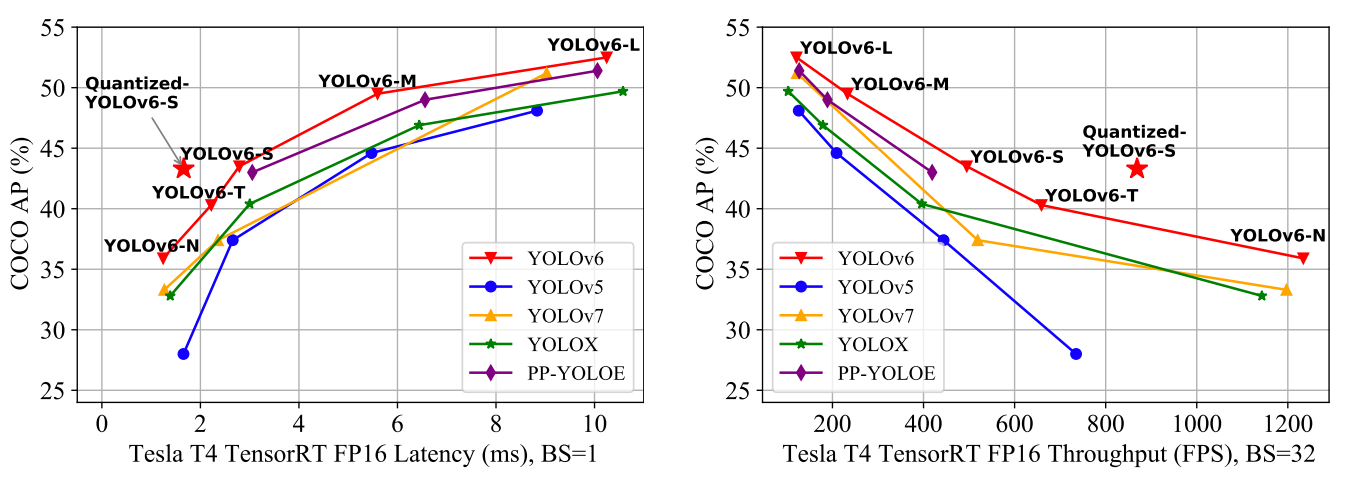
如下所示,YOLOv6 在 COCO 数据集上的准确性和速度方面相对于先前的 YOLO 版本都有了显著提高。
-
YOLOv6-N在NVIDIA Tesla T4 GPU上的吞吐量为1234 FPS,达到了35.9%的AP。
-
YOLOv6-S在869 FPS的速度下,达到了43.3%的AP,创造了新的最优结果。
-
YOLOv6-M和YOLOv6-L在相同的推理速度下分别达到了更好的准确性表现,分别为49.5%和52.3%。
YOLOv7 - 可训练的免费工具包为实时目标检测器设定了新的技术水平
YOLOv7于2022年7月发布,文章名为“训练免费工具包为实时目标检测器设定了新的技术水平”。这个版本在目标检测领域取得了重大进展,其在准确性和速度方面均超过了以前的所有模型。
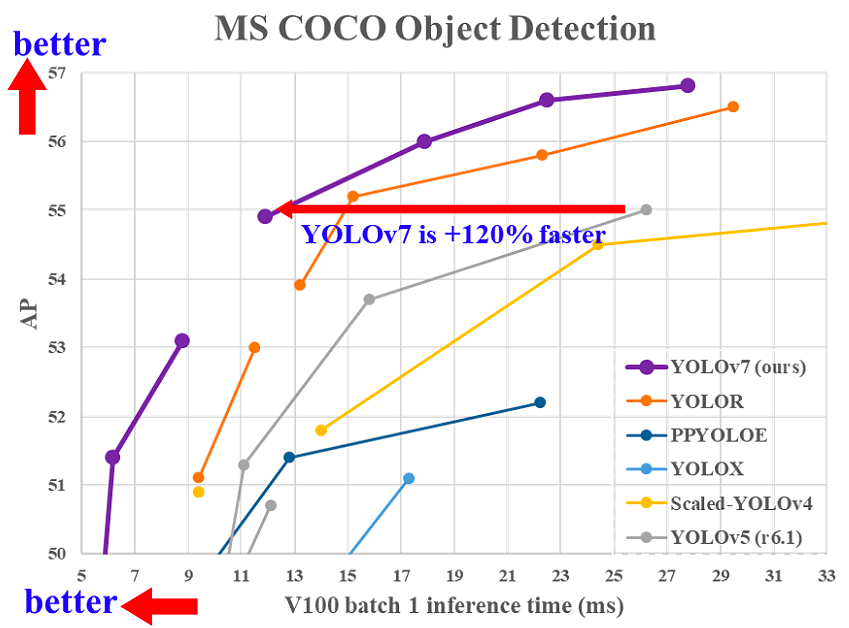
YOLOv7在其(1)架构和(2)可训练免费工具包层面上进行了重大改变:
1- 架构层面
YOLOv7通过集成扩展高效层聚合网络(E-ELAN)来改进其架构,从而使模型学习更多样化的特征,以便更好地进行学习。
此外,YOLOv7通过连接其派生模型的架构,如YOLOv4、Scaled YOLOv4和YOLO-R,来扩展其架构,从而使模型满足不同推理速度的需求。
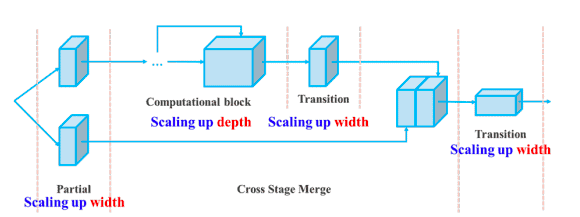
2- 可训练的免费工具包
“免费工具包”一词指的是提高模型准确性而不增加训练成本的方法,这就是为什么YOLOv7不仅提高了推理速度,还提高了检测准确性的原因。
YOLOv8 是一种尖端的、最先进的 (SOTA) 模型,它建立在以前成功的 YOLO 版本的基础上,并引入了新功能和改进以进一步提高性能和灵活性。
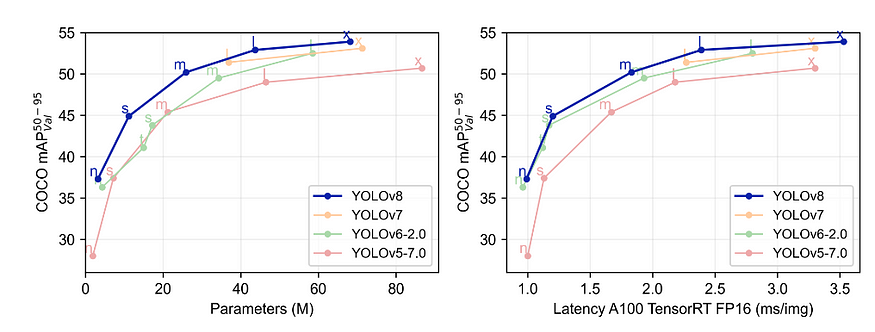
与其他 YOLO 的比较 [来源:Ultralytics ]
它使用无锚检测和新的卷积层来使预测更加准确。
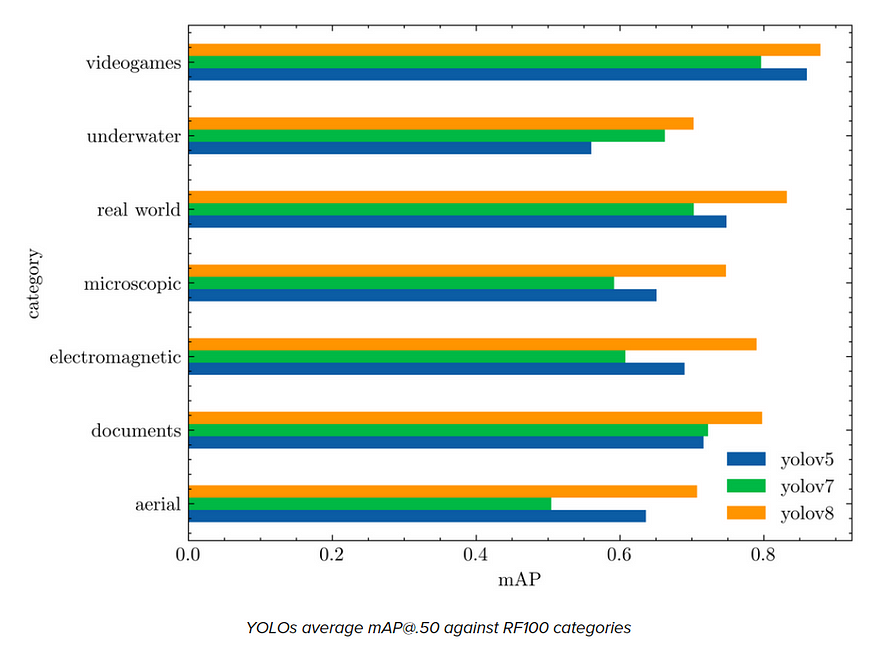
V8 不同版本对比【来源:Roboflow】
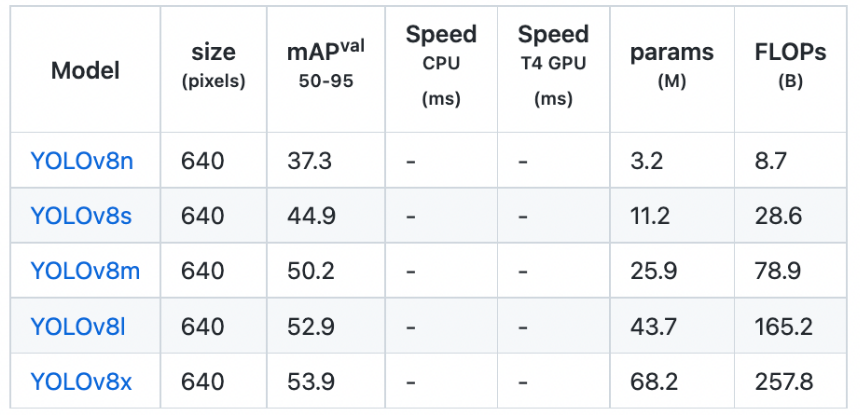
结果:
YOLO 8 在 RF100 上得到的结果比其他版本有所改进。
YOLOv8
YOLOv8是一种尖端的、最先进的 (SOTA) 模型,它建立在以前成功的 YOLO 版本的基础上,并引入了新功能和改进以进一步提高性能和灵活性。
它使用无锚检测和新的卷积层来使预测更加准确。
结果:
YOLO 8 在 RF100 上得到的结果比其他版本有所改进。
结论
本文介绍了YOLO与其他最先进的目标检测算法相比的优势,以及其从2015年到2020年的演变,并突出了其优点。
考虑到YOLO的快速发展,毫无疑问它将在很长一段时间内保持目标检测领域的领导地位。
下一步将是将YOLO算法应用于实际案例。

