
- 1机器学习(4)--breastcancer随机森林网格搜索
- 2通过 alter system dump logfile语句dump REDO及归档日志信息示例
- 3python中安装mysql包缺少mysql.h的错误原因之一_python 安装pymysql mysql.h: no such file or director
- 4人工智能原理实验3——产生式推理系统_人工智能导论实验:产生式推理系统
- 5区块链的应用:安全威胁与解决策略_区块链中的主要安全问题及解决方案
- 6华为端口安全配置详解_华为端口如何配置端口安全动作模式
- 7使用Transformer模型进行计算机视觉任务的端对端对象检测_transformer的端到端学模型
- 8「雕爷学编程」Arduino动手做(32)——雨滴传感器模块_雨滴传感器代码
- 9UCAS - AI学院 - 知识图谱专项课 - 第8讲 - 课程笔记
- 10ChatGPT 写作进阶指南:发挥ChatGPT在论文撰写中的潜力
AI新工具 小模型也有大智慧Qwen1.5-MoE;大模型动态排行榜;马斯克更新Grok-1.5_qwen小模型
赞
踩
✨ 1: Qwen1.5-MoE
阿里巴巴一款小型 MoE 模型,只有 27 亿个激活参数,但性能与最先进的 7B 模型(如 Mistral 7B 和 Qwen1.5-7B)相匹配。
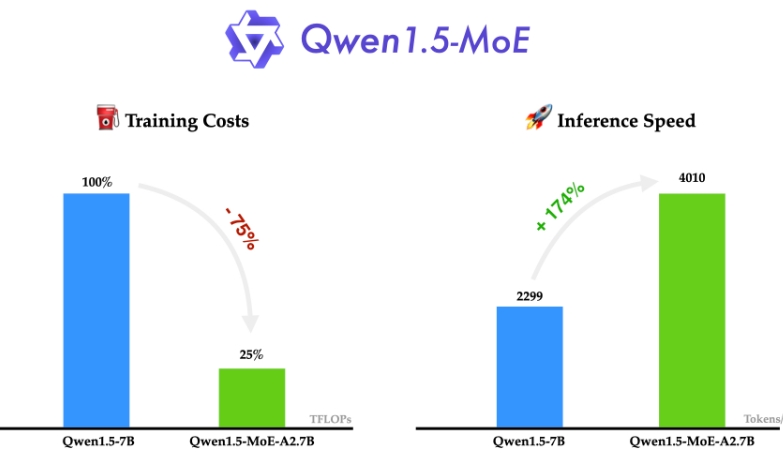
Qwen1.5-MoE是一个使用混合专家模型(Mixture-of-Experts,MoE)架构的尖端人工智能模型。本文简要地用通俗语言解释了Qwen1.5-MoE的功能及其应用场景。
博客: https://qwenlm.github.io/blog/qwen-moe/
HF: https://huggingface.co/Qwen
GitHub:https://github.com/QwenLM/Qwen1.5
地址:https://qwenlm.github.io/blog/qwen-moe/
✨ 2: lmsys
LMSYS Org(由UC伯克利主导)的研究团队正在举行一场前所未有的大语言模型排位赛。

LMSYS Org 是一个开放的研究组织,由加州大学伯克利分校、圣地亚哥分校和卡内基梅隆大学的学生与教师共同创立。该组织致力于通过开发开放数据集、模型、系统和评估工具,让每个人都能访问大型模型。他们的工作涵盖机器学习和系统方面的研究,包括训练大型语言模型并使其广泛可用,同时开发分布式系统来加速模型训练和推理过程。
过去一年,大语言模型在竞技场的排名浮沉:
GPT4 霸榜一整年!刚被opus超过
2023年5月 众多小厂开源选手百花齐放。但后续无力为继纷纷下榜
2023年8月 llama2登场
2023年9月 Claude2登场
2023年12月 GPT1106登场
2024年1月,Mistral登场
2024年3月,Claude3登场
地址:https://lmsys.org/
✨ 3: Grok-1.5
具备更强的推理能力和128,000词元的上下文长度,即将在
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

