- 1前沿AI技术体验:从文字直接产生图片,结果真的震撼! 非常有意思!_在线文字转图片 hugging
- 2Unity Mecanim动画系统 之 动画层(Layers)和 动画遮罩(Avatar Mask)的简单使用_unity avatar mask
- 3YOLOv5进行目标检测的“落地化“应用:安全帽佩戴检测_yolo5检测军装
- 4对象数组 —— 学生信息表_在右侧编辑器中的begin-end之间补充代码,设计 student 类并实现用于管理学生信息
- 5FastDFS服务器的使用_fastdfs其他服务器连接
- 6使用PLC-Recorder快速连接PLC记录数据
- 7ViewPager2+Fragment_viewpager2 fragment
- 8Win10 环境配置 Github SSH Key_github keygen
- 9Elasticsearch中的语义检索_es语义识别
- 10自相矛盾的LLM幻觉:评估、检测、缓解10.30_lmvlm幻觉检测
2. 分布式文件系统 HDFS_分布式文件系统hdfs
赞
踩
2. 分布式文件系统 HDFS
1. 引入HDFS【面试点】
问题一:如果一个文件中有 10 个数值,一行一个,并且都可以用 int 来度量。现在求 10 个数值的和
思路:
- 逐行读取文件的内容
- 把读取到的内容转换成
int类型 - 把转换后的数据进行相加
- 输出最后的一个累加和
问题二:10000 个文件,每个文件 2T,文件里的内容依然是每行一个数值,求这一堆文件的所有数值的和
思路与方案:
- 使用单进程的程序执行,即一行一行读取(串行),可能会计算出结果,但效率很低,且大概率是算不出来
- 将串行改为并行,即分布式运算:
- 第一阶段:先把大的任务切分成小的任务,然后将集群中的每个节点都可以对这些小任务进行计算
- 第二阶段:将之前中间性的结果进行汇总
问题三:问题二中的 10000 个 2T 的文件应该怎么分布才能让这 10000 个任务的执行效率达到最高?
思路:
- 如果集群有 10000 个节点,每个节点都放了一个文件,然后对每个节点上的数据启动计算引擎进行任务的计算,这样效率高
- 计算在 A 节点,存储的数据在 B 节点,这样效率不高;计算和存储在同一个节点效率高。因为数据传输肯定有延迟,从而降低效率
问题四:数据的处理(存储和计算)是这么设计的?
答:存储和计算相互依赖。在涉及存储时必须考虑计算,反之相同
存储:HDFS;计算:MapReduce
HDFS 设计思想:把存入到 HDFS 集群的数据均匀分散的存储到整个集群中
说明:集群的配置是去全局的
案例1: 100G 数据分多少集群节点存储的比较
- 都是 100G 数据,假设 1G 的数据需要 1秒 的运算时间
| 序号 | 集群节点数 | 切分存储块的大小 | 存储方式 | 运算所需时间(秒) |
|---|---|---|---|---|
| 1 | 100 | 1G | 每个节点 1G 数据量 | 1 |
| 2 | 90 | 1G | 10 台存 2G,80 台存 1G | 2 |
| 3 | 90 | 512M | 20 台存 1.5G,70 台存 1G | 1.5 |
- 上述案例得出:切分的块是不是越小越好?但有弊端:小文件很多时,会有问题
案例2: 大文件 access.log 100G 的切分方法
- 第一种切分法:block0 50G + block1 50G
- 第二种切分法:block0 20G + block1 20G + block2 20G + block3 20G + block4 20G
-
对于用户来说,一个文件是完整的存储到 HDFS 进来的,所以用户再去下载该文件时要的是完整的文件整体,要把所有的块合并起来且顺序不能错。块越少拼接越容易
-
上述案例得出:切分的块是不是越大越好?
总结:不大不小最好。不大不小:HDFS 在设计时考虑到不同的应用场景,在每个不同的应用场景中可能需要的块的大小不一样,可以自己配置。
HDFS 块的默认大小为:
- Hadoop2.x 版本以前,默认块的大小:64M
- Hadoop2.x 版本(含)以后,默认块的大小:128M
让大数据能够存储到 HDFS 集群,并考虑计算的效率问题,让文件切分存储,并让这些块均匀分散的存储到整个集群中
HDFS 集群存储的使用场景:
- 数据量特别多
- 前期数据量不大,后期数据量快速增长,可能导致数据量快速增多
HDFS 集群理论上可无限制的增加节点,但有上限:
- HDFS 集群是主从架构,主节点 NameNode
- 加的机器的性能一般(数据安全)
问题五:HDFS 如何保障数据安全?
解决:配置多份
多份数据分布的原则:
- 数据备份的数量由用户指定
- 如果一个文件存储多份,这多份数据完全没必要存储在一个节点上
小问题: 若集群有 3 个存储节点,但用户指定存储 4 份,则 HDFS 上最终有几份数据?3 份
结论:HDFS 集群中的任何一个节点,肯定没有完全相同的两份数据
问题六:HDFS 核心思想:分而治之,冗余备份
- 分散存储: 一个大的文件要存储,必须要借助分布式的存储系统,将大文件进行 分而治之(分治)
- 冗余备份: 整个 HDFS 集群架设在不是特别牢靠的服务器上,所以要保证数据安全。采用 副本 的策略,针对用户上传的整个文件,将该文件切分出来的多个块备份多份
冗余备份的默认值:3 份。备份数量的配置文件路径:
/software/hadoop/etc/hadoop/hdfs-site.xml 更改后重启服务生效
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
知识点1:如果节点机器性能有差异怎么均匀分散?
数据节点机器性能差异不是特别多,若某一台机器的性能比较差,可设置该机器少存一些数据。设置:
hadoop fs -setrep [-R] [-w] <numPeplicas> <path>
- 1
知识点2:block 块的大小设置多少?
默认 128M,实际生产最多 256M。若不懂就按照默认的,大部分都是按默认的
知识点3:HDFS 集群节点很多会导致什么情况
元数据信息 fsimage 很多,加载到内存中的时间越来越长
DataNode 节点多,节点保存的数据块的个数也多
知识点4:跨网络肯定有数据延迟和丢失问题
知识点5:HDFS 不适合存储小文件
原因:存储一亿个小文件,大小仅仅 1T,但要消耗 20G 左右的内存
- 文件存储在硬盘上,存储文件元信息(比如文件的创建者、文件的创建日期和文件的大小等)的区域叫 iNode(中文译名为 “索引节点” ),iNode 是有限的。当有成千上万个小文件存储于服务器的文件系统中时,最先消耗完的肯定不是磁盘的空间,而是 iNode,这会导致大量空闲磁盘的空间无法使用。小文件带来的问题归根结底是由于其小且数量巨大
解决方案:对小文件进行合并,或对小文件提前做处理
- 将一定数量的小文件合并为一个个的大文件,并且只存储合并后的大文件,那存储系统中的文件数量就会大大减少,通过一定方式再从合并后的大文件中分离出小文件,按需获取想要的数据即可
知识点:文件存储在硬盘上,硬盘的最小存储单位叫做 “扇区”(sector)。每个扇区存储512字节(相当于0.5KB)。操作系统读取硬盘时,不会一个个扇区的读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个 “块”(block)。这种由多个扇区组成的 “块”,是文件存储的最小单位。“块” 的大小,最常见的是 4KB,即连续 8 个 sector 组成一个 block。文件数据都存储在 “块” 中,那么很显然,我们还必须找到一个地方存储文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种存储文件元信息的区域就叫做 iNode。
2. HDFS 概述
HDFS 是大数据存储的基础,几乎所有的大数据分布式存储需求都会使用到。
1. HDFS 设计思路
HDFS 被设计成使用低廉的服务器进行海量数据的存储,如何做到?分散存储
- 大文件被切割成小文件,使用分而治之的思想对同一个文件进行管理
- 每个切分后的块都进行冗余备份,高可用不丢失
2. HDFS 架构
主从架构。下边三个节点的架构是最基础的,高可用会有 StandbyNameNode,用于防止 NameNode 宕机。
- NameNode 主节点:掌管文件系统的目录树,处理客户端的请求,保存元数据信息
- DataNode 从节点:存储实际数据,处理真正的读写
- SecondaryNameNode(单机/伪分布式/分布式):分担 NameNode 的压力,协助合并元数据信息

3. HDFS 优缺点
优点:
- 可构建在廉价机器上,通过多个副本来提高可靠性,文件切分多个块进行存储
- 高容错性。数据可自动保存多个副本,副本丢失后可自动恢复
- 适合批处理。移动计算比移动数据更方便
- 流式文件访问。一次写入,多次读取。可以保证数据一致性
缺点:(不适合以下操作)
- 要求高的数据访问。比如毫秒级
- 小文件存储。寻道时间超过读取时间
- 并发写入,文件随机修改。一个文件只能有一个写,仅支持追加写入
3. HDFS 操作
1. HDFS 的 Shell 操作【重点】
| 命令 | 功能 | 举例 |
|---|---|---|
| hadoop fs hdfs dfs | 两种方式操作 hdfs 文件的命令前缀 | |
| -help | 输出这个命令参数手册 | hadoop fs -help |
| -ls | 显示目录信息 | hadoop fs -ls hdfs://ip:9000/hadoop fs -ls / |
| -put | 本地文件上传至 hdfs | 把当前目录下的 a.txt 上传到 hdfs:hadoop fs -put a.txt /hdfsPath |
| -get | 从 hdfs 下载文件到本地 | hadoop fs -get /a.txt localPath |
| -cp | 从 hdfs 的一个路径拷贝到另一个路径 | 把 /a.txt 拷贝到 /aa 下,并更名为 a2.txthadoop fs -cp /a.txt /aa/a2.txt |
| -mv | 在 hdfs 目录中移动文件 | hadoop fs -mv /a.txt /aa |
| -mkdir | 创建文件夹 | hadoop fs -mkdir /b |
| -rm | 删除文件或文件夹 | hadoop fs -rm -r /aa/bb |
| -rmdir | 删除空目录 | hadoop fs -rmdir /aa/bb |
| -moveFromLocal | 从本地剪切到 hdfs | hadoop fs -moveFromLocal /home/a.txt /aa/bb |
| -moveToLocal | 从 hdfs 剪切到本地 | hadoop fs -moveToLocal /aa/bb/a.txt /home |
| -copyFromLocal | 从本地文件系统中拷贝文件到 hdfs | hadoop fs -copyFromLocal ./a.txt /aa |
| -copyToLocal | 从 hdfs 拷贝到本地 | hadoop fs -copyToLocal /a.txt . |
| -appendToFile | 追加一个文件到已经存在的文件末尾 | hadoop fs -appendToFile ./a.txt /a.txt |
| -cat | 显示文件内容 | hadoop fs -cat /aa/a.txt |
| -tail | 显示一个文件的末尾 | hadoop fs -tail /aa/a.txt |
| -text | 以字符形式打印一个文件的内容 | hadoop fs -text /aa/a.txt |
| -chmod | 与 Linux 文件系统的用法一样,对文件设置权限 | hadoop fs -chmod 666 /aa/a.txt |
| -df | 统计文件夹的大小信息 | hadoop fs -df -sh /aa/* |
| -count | 统计一个指定目录下的文件节点数量 | hadoop fs -count /aa |
| -setrep | 设置 hdfs 中文本的副本数量 | hadoop fs -setrep 3 /aa/a.txt |
| hdfs dfsadmin -report | 查看 hdfs 集群工作状态 | Live datanodes (2)说明有两台是正常运行的数据节点 |
2. HDFS 的 API 操作
HDFS 的 API 操作所需的 maven 依赖导入 pom.xml 文件的 <artifactId>module_name</artifactId> 和 </project> 之间,并等待下载完成
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.7.4</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.1</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> <!-- <verbal>true</verbal>--> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <minimizeJar>true</minimizeJar> </configuration> </execution> </executions> </plugin> </plugins> </build> <properties> <maven.compiler.source>16</maven.compiler.source> <maven.compiler.target>16</maven.compiler.target> </properties>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
1. 访问数据
1. 获取 FileSystem
// FileSystem.get() import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import java.io.IOException; public class hdfs01GetFileSystem { public static void main(String[] args) throws IOException { // 1. 创建Configuration对象 Configuration conf = new Configuration(); // 2. 设置文件系统类型 // 第二个参数是访问域名,做过域名解析可设置成 hdfs://hadoop0:8020 conf.set("fs.defaultFS", "hdfs://hadoop0:8020"); // 3. 获取指定文件系统 FileSystem fileSystem = FileSystem.get(conf); // 4. 打印输出 System.out.println(fileSystem); }}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 执行上述代码返回下图所示结果即成功:

2. 文件的遍历
// FileSystem.listFiles() + for循环 import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; public class traverseFile { public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException { // 1. 获取FileSystem,默认端口8020 FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop0:8020"), new Configuration(), "root"); // 2. 调用 listFile()方法 获取根目录下所有的文件信息 RemoteIterator<LocatedFileStatus> iterator = fileSystem.listFiles(new Path("/"), true); // 3. 遍历迭代器 while (iterator.hasNext()) { LocatedFileStatus fileStatus = iterator.next(); // 获取文件的绝对路径:hdfs://172.16.15.100/xxx System.out.println(fileStatus.getPath() + "===" + fileStatus.getPath().getName()); // 文件的block信息 BlockLocation[] blockLocations = fileStatus.getBlockLocations(); for (BlockLocation blockLocation : blockLocations) { String[] hosts = blockLocation.getHosts(); for (String host : hosts) { System.out.println("主机为:" + host); }} System.out.println("block数量为:" + blockLocations.length); }}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 输出结果:
hdfs://hadoop0:8020/0320/data.txt===data.txt
主机为hadoop1
主机为hadoop2
block数量为:1
hdfs://hadoop0:8020/0320/merge.txt===merge.txt
主机为hadoop2
主机为hadoop1
block数量为:1
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3. 创建文件夹
// FileSystem.mkdirs() import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; public class hdfs03CreateFolder { public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException { // 1. 获取FileSystem FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop0:8020"), new Configuration(), "root"); // 2. 创建文件夹 fileSystem.mkdirs(new Path("/0320")); // 3. 关闭FileSystem fileSystem.close(); }}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 执行结果:

4. 文件的上传
// FileSystem.copyFromLocalFile() import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; public class hdfs04FileUpload { public static void main(String[] args) throws InterruptedException, IOException, URISyntaxException { hdfs04FileUpload fileUpload = new hdfs04FileUpload(); fileUpload.FileUpload(); } /* 定义上传文件的方法 */ public void FileUpload() throws URISyntaxException, IOException, InterruptedException { // 1. 获取文件系统 FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop0:8020"), new Configuration(), "root"); // 2. 上传文件 fileSystem.copyFromLocalFile(new Path("/Users/jason93/Desktop/BigData/file/data.txt"), new Path("/0320")); // 3. 关闭FileSystem fileSystem.close(); }}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 执行结果:

5. 文件的下载
// IOUtils.copy() import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.FileOutputStream; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; public class hdfs05FileDownload { public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException { // 1. 获取FileSystem FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop0:8020"), new Configuration(), "root"); // 2. 获取hdfs的输入流 FSDataInputStream inputStream = fileSystem.open(new Path("/0320/data.txt")); // 3. 获取本地文件的输出流 FileOutputStream outputStream = new FileOutputStream("/Users/jason93/Desktop/BigData/file/hdfs/dataDown.txt"); // 4. 文件的拷贝 IOUtils.copy(inputStream, outputStream); // 5. 关闭流 IOUtils.closeQuietly(inputStream); IOUtils.closeQuietly(outputStream); fileSystem.close(); }}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 运行结果:(其文件内容与 data.txt 一样)

2. 合并小文件
1. 合并小文件上传
- 首先准备几个小文件
# /Users/jason93/Desktop/BigData/file/hdfs/merge/
# data1.txt
hello,world
# data2.txt
hello,hadoop
# data3.txt
hello,hdfs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 代码:
// IOUtils.copy() import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; public class hdfs06MergeFileUpload { public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException { // 1. 获取FileSystem FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop0:8020"), new Configuration(), "root"); // 2. 获取hdfs大文件的输出流 FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("/0320/hdfs/merge.txt")); // 3. 获取一个本地文件系统 LocalFileSystem localFileSystem = FileSystem.getLocal(new Configuration()); // 4. 获取本地文件夹下所有文件的详情 FileStatus[] fileStatuses = localFileSystem.listStatus(new Path("/Users/jason93/Desktop/BigData/file/hdfs/merge")); // 5. 遍历每个文件,获取每个文件的输入流 for (FileStatus fileStatus : fileStatuses) { FSDataInputStream fsDataInputStream = localFileSystem.open(fileStatus.getPath()); // 6. 将小文件的内容复制到大文件 IOUtils.copy(fsDataInputStream, fsDataOutputStream); IOUtils.closeQuietly(fsDataInputStream); } // 7. 关闭流 IOUtils.closeQuietly(fsDataOutputStream); localFileSystem.close(); fileSystem.close(); }}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 运行后看结果

2. 合并小文件下载
方式一:通过命令行方式
-
将 hdfs 的
/0320/hdfs/下的三个文件合并下载到本地
-
说明:若本地该文件不存在则创建写入,若存在则覆盖文件的原内容
# 合并指定目录下的所有文件
hadoop fs -getmerge /0320/hdfs/* /home/data/hdfs/mergeDown.txt
# 合并目录下的指定文件也可以(相对路径)
hadoop fs -getmerge /0320/hdfs/data1.txt /0320/hdfs/data3.txt mergeDown13.txt
# 查看结果:
[root@hadoop0 hdfs]# ls
mergeDown13.txt mergeDown.txt merge.txt
[root@hadoop0 hdfs]# cat mergeDown.txt
hello,world
hello,hadoop
hello,hdfs
[root@hadoop0 hdfs]# cat mergeDown13.txt
hello,world
hello,hdfs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
方式二:通过 Java API方式
// IOUtils.copy() import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; public class hdfs07MergeFileDownload { public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException { // 1. 获取FileSystem FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop0:8020"), new Configuration(), "root"); // 2. 获取一个本地文件系统 LocalFileSystem localFileSystem = FileSystem.getLocal(new Configuration()); // 3. 获取本地大文件的输出流 FSDataOutputStream outputStream = localFileSystem.create(new Path("/Users/jason93/Desktop/BigData/file/hdfs/mergeDown.txt"), true); // 4. 获取hdfs下的所有小文件 RemoteIterator<LocatedFileStatus> listFiles = fileSystem.listFiles(new Path("/0320/hdfs"), true); // 5. 遍历 while (listFiles.hasNext()) { LocatedFileStatus locatedFileStatus = listFiles.next(); FSDataInputStream inputStream = fileSystem.open(locatedFileStatus.getPath()); // 6. 将小文件复制到大文件中 IOUtils.copy(inputStream, outputStream); IOUtils.closeQuietly(inputStream); } // 7. 关闭流 IOUtils.closeQuietly(outputStream); localFileSystem.close(); fileSystem.close(); }}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 运行结果:

4. HDFS 原理
1. HDFS 的启动流程【重要】
- 先启动 NameNode 进程
- 加载 NameNode 文件夹中存储的磁盘的元数据信息(fsimage + edits_inprogress)
- NameNode 在启动完毕后,会在 NameNode 节点启动一个服务,该服务会等待所有 DataNode 上线后汇报块信息
- DataNode 一旦上线,就会通过心跳机制把自身所持有的所有块信息汇报给 NameNode
- 只有 NameNode 等到了所有的 DataNode 的上线以及把所有的块信息都汇报完毕后,最后 NameNode 才能得知:当前集群中所有文件的所有块的副本的分布。这样才代表 NameNode 正常启动
2. DataNode 页面信息介绍

信息说明:
- Node:地址和端口
- Last Contact:最近通讯时间(正常是 0/1/2 的间隔,若不正常则为最后一次的通讯时间)
- Admin State:管理员状态
- Capacity:HDFS 容量
- Used:已使用容量
- Non DFS Used:非 HDFS 使用容量
- Remaining:剩余容量
- Blocks:块容量
- Block pool used:块使用占比
- Failed Volumes:失败卷的个数,确定当前数据节点停止服务允许卷出错的服务,0 代表任何卷出错都停止服务
- Version:版本
3. HDFS 的读写剖析
1. HDFS 读数据流程

- 客户端把要读取的文件路径发送给 NameNode
- NameNode 获取文件的元信息(主要信息是 block 块的存放位置)返回给客户端
- NameNode 根据 block 块所在节点与客户端的距离判断返回哪个节点,哪个节点离客户端最近就返回哪个
- 客户端根据返回的信息找到相应 DataNode,然后逐个获取文件的 block,并在客户端本地进行数据追加合并,从而获得整个文件
异常情况: HDFS 在读取文件时,如果其中一个块突然坏掉了怎么办?
- 客户端在 DataNode 上读取完后,会对读取到的数据进行 checksum 验证(该验证就是将读取到数据和 HDFS 块的元数据进行校验),如果校验过程中发现了错误,则说明该 DataNode 读取的数据不完整,可能这个 DataNode 坏掉了,这时客户端会跟 NameNode 通讯,告诉它存在异常的 DataNode,而客户端可以从拥有该 block 备份的其他 DataNode 上重新读取文件
- 当 DataNode 确认数据异常后,将会启动异步删除,并同时告诉 NameNode 更新元数据信息,若没有其余副本,则需通过 SecondaryNameNode 进行数据恢复
2. HDFS 写数据流程

具体步骤:
-
Client 发送写数据请求
-
NameNode 响应请求,然后做一系列校验,如果能上传该数据则返回该文件的所有切块应该被存放在哪些 DataNode 上的 DataNode 列表
block-001: hadoop2 hadoop3 block-002: hadoop3 hadoop4- 1
- 2
-
Client 拿到 DataNode 列表后,开始传数据
-
首先传第一个block-001,DataNode 列表就是 hadoop2 和 hadoop3,Client 就把 block-001 传到 hadoop2 和 hadoop3 上
-
以此类推,用传第一个数据块的方式传其他的数据
-
当所有的数据块都传完后,Client 会给 NameNode 返回一个状态信息,表示数据已全部写入成功,或者失败
-
NameNode 接收到 Client 返回的状态信息来判断当次写入数据的请求是否成功,若成功则更新元数据信息
异常情况:
场景一:HDFS 在上传文件时,若其中一个 DataNode 突然挂掉了怎么办?
- 客户端上传文件时与 DataNode 建立 pipeline 管道,管道正向是客户端向 DataNode 发送的数据包,管道反向是 DataNode 向客户端发送 ACK 确认,也就是正确接收到数据包后发送一个已确认接收到的应答
- 当 DataNode 突然挂掉了,客户端接收不到该 DataNode 发送的 ACK 确认,此时不会立刻终止写入(如果立刻终止,易用性和可用性都太不友好),客户端会通知 NameNode,NameNode 检查该块的副本与规定的不符,会通知其他 DataNode 去复制副本,并将挂掉的 DataNode 作下线处理,不再让它参与文件上传与下载,该过程称为 pipeline recovery
场景二:HDFS 向 DataNode 写入数据失败怎么办?(上传 100MB 的文件,上传到 50MB,突然断了,或 block 由于网络等原因异常了,HDFS 会怎么处理?)
- Pipeline 数据流管道会被关闭,ACK 队列中的 packets 会被添加到数据队列的前面以确保数据包不丢失
- 在已正常存储 block 块的 DataNode 的 blockID 版本会更新(升级),这样发生故障的 DataNode 节点上的 block 数据会在节点恢复正常后被删除,失效节点也会从 Pipeline 中删除
- 剩下的数据会被写入到 Pipeline 数据流管道中的其他节点上
5. HDFS 三大机制(核心设计)
HDFS 三大核心机制:心跳机制、安全模式、副本存放策略
1. HDFS 心跳机制【重要】
Hadoop 是 Master/Slave 架构,Master 中有 NameNode 和 ResourceManager,Slave 中有 DataNode 和 NodeManager。
【心跳机制】:DataNode 每隔一段时间(默认 3 秒)就会跟 NameNode 取得一次联系,从而证明自己还活着,让 NameNode 能够识别到当前集群中有多少存活的节点。
- 详细点:Master 启动时会启动一个 IPC(Inter-Process Communication,进程间通信)server 服务,等待 Slave 连接;Slave 启动时会主动连接 Master 的 IPC server 服务,并且每隔 3 秒连接一次 Master,这个每隔一段时间去连接一次的机制称为心跳。Slave 通过心跳给 Master 汇报自己的信息,Master 也通过心跳给 Slave 下达命令。NameNode 通过心跳得知 DataNode 的状态,ResourceManager 通过心跳得知 NodeManager 的状态。如果 Master 长时间都没收到 Slave 的心跳,就认为该 Slave 挂掉了。
NameNode 判断 DataNode 是否宕机需要一个标准:超时
timeout(超时时长) = 10 * 心跳时长(3秒) + 2 * 检测心跳是否正常工作的间隔(5分钟)
- 即 10 * 3 + 2 * 5 * 60 = 630 秒
超时时间可在 hdfs-site.xml 文件中配置 dfs.heartbeat.interval 参数,或使用 Zookeeper 做一个监控,有节点宕机可迅速感知。
心跳机制分两个方面:
- 命令:NameNode 给 DataNode 发
- 汇报:DataNode 给 NameNode 发
心跳机制作用:
- 让 NameNode 能够识别当前各个 DataNode 的状态
- DataNode 向 NameNode 传送 心跳数据包
心跳数据包:
- 该节点自身状态:磁盘使用量、block 块的数量、block 块的状态
- 该 DataNode 节点保存的所有 block 块的信息
- block 块的信息在 Linux 系统的文件位置:

2. HDFS 安全模式【重要】
在正常的启动范围内,HDFS 集群会进入安全模式,无法对外提供服务。安全模式下,客户端不能对任何数据进行操作,只能查看元数据信息。
1. 进入安全模式
进入安全模式的场景:
- 大概率是因为集群出现问题时进入安全模式
- 当 HDFS 集群中部分 DataNode 节点宕机后,HDFS 启动服务做恢复
- 当丢失数据的比例超过
0.1%时会进入安全模式- 丢失率 可手动配置
- 默认是:
dfs.safemode.threshold.pct=0.999f - 新版本的配置是:
dfs.namenode.safemode.threshold-pct=0.999f
- 默认是:
- 丢失率 可手动配置
若要强制对外提供服务,可使用HDFS命令操作:
hdfs dfsadmin -safemode leave # 退出安全模式
hdfs dfsadmin -safemode enter # 进入安全模式
hdfs dfsadmin -safemode get # 获取安全模式状态
hdfs dfsadmin -safemode wait # 等待
- 1
- 2
- 3
- 4
2. 退出安全模式
hdfs dfsadmin -safemode leave
- 1
说明:
- 找到集群的问题进行修复(比如修复宕机的 DataNode),修复好了会自动退出安全模式
- 手动强行退出安全模式,并没有真正解决数据丢失的问题
3. 副本存放策略
决定一个数据块的那几个副本(默认是 3)到底该存储到哪些服务器上
原则:
- 任意一个节点上不可能存储两个一样的副本块
- 如果一个数据块要保存完整的 3 个副本块,则至少有 3 个节点
副本存放策略:

策略:
- 第一个副本块选取和客户端相同的节点
- 第二个副本块选取跟第一个副本块存储节点相邻的机架(Rack)上面的任意一个节点
- 第三个副本块存放在和第二个副本块所在机架不同的节点上
策略是一个参考,不是硬性标准。所以实际选取存储空间大、不忙的节点
**方法:**将每个文件的数据分块存储,每一个数据块又保存多个副本,这些数据块副本分布在不同的机器节点上
作用:数据分块存储和副本存放,是保证可靠性和高性能的关键
6. HDFS 三大组件
重点:组件的职责、元数据
1. NameNode 主节点
1. 职责
- 维护元数据(查询、修改)
- 响应客户端的读写数据请求
- 配置副本存放策略
- 管理集群数据库负载均衡问题
2. 元数据
如何管理元数据? 使用 WAL(Write-Ahead Logging)预写日志系统
WAL:数据库中一种高效的日志算法,对于非内存数据库而言,磁盘 I/O 操作是数据库效率的一大瓶颈。在相同的数据量下,采用 WAL 日志的数据库系统在事务提交时,磁盘写操作只有传统的回滚日志的一半左右,大大提高了数据库磁盘 I/O 操作的效率,从而提高了数据库的性能。
说明:MySQL 实现了 WAL,所有的事务操作都会记录日志,若某张表的数据丢失后,可根据该日志拿到对应数据,对表进行恢复
元数据信息的位置:${HADOOP_HOME}/data/namenode/current/ 。示例如下:

相关说明:
(1)edits_inprogress_000… 文件:它是时刻操作的文件,按一定时间或一定大小(不同版本有差异)分割为若干 edits_000… 文件
- edits 和 fsimage 的关系:操作性文件 edits_00…-000… 合并起来为镜像文件 fsimage_00… 。比如 fsimage_000…0013725,表示 edits_000…0013725 及之前所有的 edits_000xxx 文件合并后的文件;fsimage_000…0013727 表示 edits_000…0013727 及之前所有的 edits_000xxx 文件合并后的文件。至于什么时候合并,有个 Checkpoint 检查点。后一个 fsimage 包含前一个 fsimage 和更新的 edits 文件,生成两个 fsimage 是起到 备份 的作用。若合并 edits_000…0013727 时失败,则在 hdfs 冷启动时加载 fsimage_000…0013726、edits_000…0013727 和 edits_inprogress_000… 三个文件即可;当然若合并 edits_000…0013727 成功了,则只加载 fsimage_000…0013727 和 edits_inprogress_000… 两个文件即可
- 通过生成一个可查看的 xml 文件查看 edits 和 fsimage 文件信息:
# edits 文件:
hdfs oev -i edits_0000000000000013664-0000000000000013665 -o edits.xml
cat edits.xml
# fsimage 文件:
hdfs oiv -i fsimage_0000000000000013725 -p XML -o fsimage.xml
cat fsimage.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(2)seen_txid:存放 edits_inprogress_00… 日志最新的 id(存放 transactionId 的文件),比如 edits_inprogress_00xxx0013728,则 (3)seen_txid 为13728。format 之后是 0
(4)VERSION:存放 HDFS 集群的版本信息
(5)fsimage_000xxx.md5:校验性文件
NameNode 元数据存储机制:
- 内存 中的元数据信息:metadata,内存中一份完整的元数据信息(目录树结构 + 文件块映射 + 数据库和 DataNode 的映射)
- 目录树结构:文件地址的目录信息
- 文件块映射:文件切分成哪些块
- 磁盘 中的元数据镜像:fsimage 快照 + edits 编辑日志 + edits_inprogress(实时操作变化日志),在 NameNode 的工作目录中
- 用于衔接内存 metadata 和持久化元数据镜像 fsimage 之间的操作日志(edits 文件)
- 当客户端对 HDFS 中的文件进行新增或修改时,操作记录首先被写入 edits 日志文件中,当客户端操作成功后,相应的元数据会更新到内存 metadata 中
元数据合并的好处【面试点】
- 大大缩小操作日志的大小
- 合并后的镜像磁盘文件可以被快速加载到内存中去。可以不用加载所有的操作性文件,只加载 fsimage 和 edits_inprogress 两个文件,有利于加快程序的冷启动
元数据的 Checkpoint: 每隔一段时间,会有 SecondaryNameNode 将 NameNode 上积累的所有 edits 和一个最新的 fsimage 下载到本地,并加载到内存中进行 merge(合并),该过程称为 Checkpoint。
2. DataNode 从节点
1. 职责
- 维护 NameNode 分配给它的 block 块(存储管理用户的文件块数据)
- 通过心跳机制汇报自身所有的块信息给 NameNode
- 真正的提供读写数据
数据块的两个参数: 块的大小、副本的个数
data 数据的存放目录:
${HADOOP_HOME}/data/datanode/current/BP-1365453085-172.16.15.103-1646548673937/current/finalized/subdir0/
- 1
2. DataNode 上下线
例1:一个集群有 500 个节点,现增加 10 个节点。HDFS 如何表现?
- 新增加的 DataNode 启动后,会按照配置文件寻找 HDFS 集群的 NameNode 进行汇报
- 新上线的 DataNode 没有任何数据块的信息,只有自身的状态信息
- 原来的 DataNode 和新加的 DataNode 之间存在数据倾斜的问题
解决数据倾斜的方法:负载均衡
- 负载均衡类型:服务器之间的负载均衡、磁盘之间的负载均衡
- 说明:启动负载均衡需要手工启动一个 start-balance 的进程
- 负载均衡举例:比如一个节点 4 个磁盘,每个盘 2T,该节点存储了 1T 的数据,若该 1T 的数据都在第一个磁盘上,就意味着其他 3 个磁盘没用到,这时最好做负载均衡:每个磁盘 256G
例2:一个集群 500 个节点,现减少 10 个节点,这 10 个节点上的数据块信息丢失。HDFS 如何表现?
- HDFS 集群会利用自身的恢复机制恢复到原来副本块的个数
知识点:
- 下线节点,在被动情况下,某个块的所有副本所在节点都宕机了,怎么处理?
- 若之前做过
异地灾备,可以从异地机房做数据恢复 - 若之前没做过异地灾备,那数据就丢失了
- 若之前做过
- 假设一个节点异常,数据被负载到其他节点上了,后来该节点又恢复了,那数据会重新分配吗?
- 某个数据所在的节点异常,在一个时间间隔(630秒)之内数据不会进行恢复;超过该时间后,若原来是 3 个数据块副本,现在是 2 个,则启动恢复模式恢复成 3 个数据块副本。原节点恢复过来后,会在一个时间间隔后向 NameNode 汇报,NameNode 检测到该数据块副本已经正常了,则恢复过来的节点就不起作用 了
3. SecondaryNameNode
**职责:**分担 NameNode 合并元数据信息(镜像文件和操作日志)的压力
**注意:**SecondaryNameNode 不要和 NameNode 配置在一个节点上
说明:
- SecondaryNameNode 并不是 NameNode 的热备份,所以当 NameNode 挂掉后不能代替 NameNode 工作,对外提供服务
- SecondaryNameNode 只在单机模式、伪分布模式和分布式模式中使用,在高可用、联邦集群中由 StandbyNameNode 取代,所以 SecondaryNameNode 与 StandbyNameNode 是互斥的关系,二者存且仅存一个
- SecondaryNameNode 只能帮助 NameNode 恢复部分数据,因为当 SecondaryNameNode 接收到 NameNode 的编辑日志 edits 和镜像文件 fsimage 之后,NameNode 之中的操作还会记录到它本身的编辑日志(edits)中,不会同步到 SecondaryNameNode,所以,SecondaryNameNode 只有 checkpoint 之前的数据,只能恢复部分的数据,如果 NameNode 将 checkpoint 之后的数据丢失则无法恢复
工作机制:
- SecondaryNameNode 向 NameNode 发出请求,看 NameNode 是否需要进行 checkpoint 活动
- NameNode 返回自己是否需要 checkpoint 活动的结果,若需要则继续,若不需要就没有后续了
- SecondaryNameNode 在接收到 NameNode 需要进行 checkpoint 的请求后,会向 NameNode 发起 checkpoint 请求
- NameNode 接收到请求后,对编辑日志(edits)进行回滚,然后将编辑日志(edits)和镜像文件(fsimage)拷贝到 SecondaryNameNode 中
- SecondaryNameNode 将 NameNode 拷贝过来的 fsimage 和 edits 加载到内存中进行合并,生成新的 fsimage.chkpoint
- SecondaryNameNode 将 fsimage.chkpoint 拷贝到 NameNode 中
- NameNode 将 fsimage.chkpoint 重新命名为 fsimage
7. HDFS 的高可用和联邦【重点】
1. 高可用(HA)
集群要对外提供服务,首先要保证 NameNode 正常,不能宕机。因为企业一般都 7*24 小时不间断提供服务。保证 NameNode 实时提供服务而不宕机的机制:HA(High Available)高可用
SPOF(Single Point Of Failure)单点故障,是主从架构存在的通性问题
单点故障具体解决方案:做备份

为防止 Active 的 NameNode 宕机,在旁边准备一台 Standby 节点。假设 Active 的 NameNode 节点是 Hadoop0,Standby 的 NameNode 节点是 Hadoop4,若 Hadoop0 宕机了,Hadoop4 会代替它运行。
HDFS 高可用功能,用配置过 Active/Standby 两个 NameNode 实现在集群中对 NameNode 的热备份来解决 NameNode 机器宕机或软硬件升级导致集群无法使用的问题。
元数据信息在 NameNode 节点 Hadoop0 中,当它宕机后,Hadoop4 要迅速取代 Hadoop0,也就意味着 Hadoop4 和 Hadoop0 要存储一模一样的元数据信息,即 Hadoop4 是 Hadoop0 的一个热备份。【重要】
不管 Active 节点做了什么操作,Standby 节点都要 时刻保持同步。
保持同步的方法:创建 JournalNode 集群,NameNode(Active)写入该集群,NameNode(Standby)从该集群中读取。JournalNode 集群的各个节点跟 Zoopeeper 集群类似,每个节点都有可能成为主节点,因此不存在单点故障。至于区分 Active 和 Standby,由 Zookeeper 集群的文件目录树决定。该目录树是一个 LOCK,两个 NameNode 谁先抢到谁就是 Active。
为了保险起见,设置多个 Standby 是否可以?可以,但有条件,也不建议特别多,个位数。
- 条件:Hadoop2.x 版本中不行,一个 Active 只能对应一个 Standby;Hadoop3.x 版本中可以
多主多从:主节点是一个小集群,从节点也是一个集群(比如 Kudu)
2. 联邦(Federation)
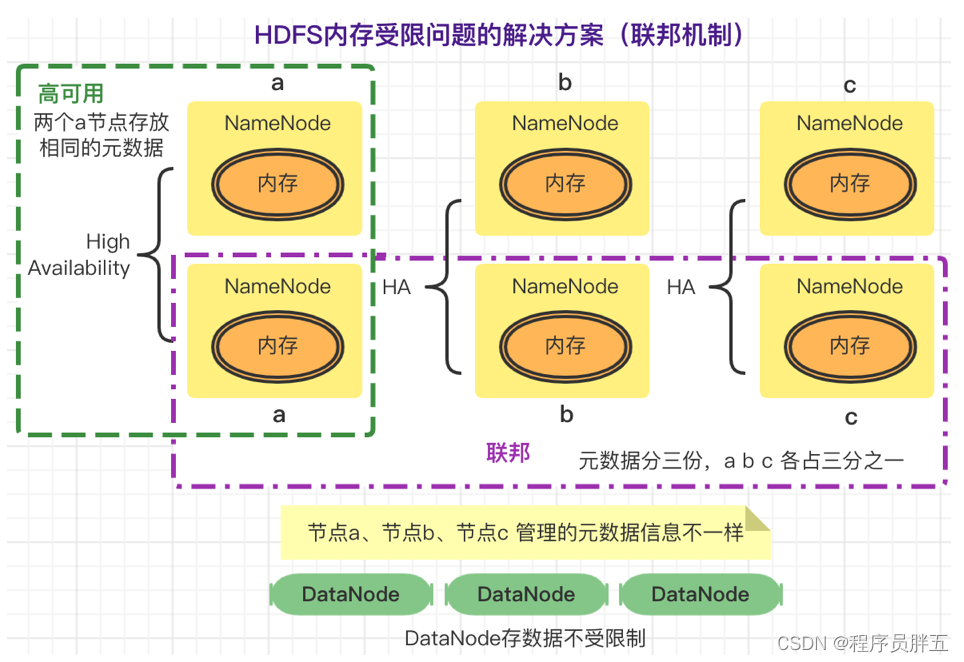
元数据信息加载到内存中,有可能内存放不下,导致 内存受限。解决内存受限问题:联邦
HDFS Federation:指 HDFS 集群可同时存在多个 NameNode,包含多组 HA,每组 HA 中各 NameNode 存储相同元数据,元数据分多份,均分到各组 HA 的 NameNode中。
这种设计可解决单 NameNode 存在的以下问题:
- HDFS 集群扩展性
- 性能更高效
- 良好的隔离性
HDFS Federation方案: