
- 1Elasticsearch:(二)3.安装Elasticsearch-head插件
- 2FPGA原理与结构——时钟IP核的使用与测试_fpga怎么调用时钟ip
- 3测试用例常见设计方法_如何设计测试用例
- 4推荐几个比较好的软件测试博客论坛_软件测试论坛
- 5python元胞自动机模拟交通_教程FLUS模型|未来土地利用变化情景模拟模型(GeoSOSFLUS)...
- 6WINDOWS环境下RABBITMQ的启动和停止命令_怎么在windos powershell里关闭rabbitmq
- 7APP开发实战178-查看和删除多余的依赖库_如何删除uniapp不需要的依赖
- 82023亚太杯数学建模竞赛C题新能源电动汽车数据分析与代码讲解_2023年亚太赛c题
- 9SiteServer 学习笔记 Day05 添加模板
- 10AI智能电销机器人是什么?能给我们带来哪些便利?
chatGPT原理详解_chatgpt原理,英文网址
赞
踩
InstructGPT原文:https://arxiv.org/pdf/2203.02155.pdf
chatCPT试用连接:https://chat.openai.com/auth/login
自从chatGPT问世以来,它一路爆火,目前注册用户已达1亿。它的出圈让各大公司纷纷布局AIGC,有不少人预言,称ChatGPT带来的变革,将会颠覆谷歌的现有搜索产品和商业模式。就在发文前一个小时,谷歌宣布推出Bard对抗ChatGPT,打响保卫战,bard将在数周后面向大众使用。能引起人工智能领域这么大反响的chatGPT究竟是怎么运行的呢?下面我汇总了网络上关于chatGPT原理的资源。
从整体技术路线上来看,ChatGPT使用了GPT-3.5大规模语言模型(LLM,Large Language Model),并在该模型的基础上引入强化学习来Fine-turn预训练的语言模型。这里的强化学习采用的是RLHF(Reinforcement Learning from Human Feedback),即采用人工标注的方式。目的是通过其奖励惩罚机制(reward)让LLM模型学会理解各种NLP任务并学会判断什么样的答案是优质的(helpfulness、honest、harmless三个维度)。下面分别讲解相关基础知识和chatGPT原理。
1,GPT
GPT的全称是Generative Pre-Trained Transformer,顾名思义,GPT的目的就是通过Transformer为基础模型,使用预训练技术得到通用的文本模型。
(1)GPT-1比BERT诞生略早几个月。它们都是采用了Transformer为核心结构,不同的是GPT-1通过自左向右生成式的构建预训练任务,然后得到一个通用的预训练模型,这个模型和BERT一样都可用来做下游任务的微调。GPT-1当时在9个NLP任务上取得了SOTA的效果。
(2)对比GPT-1,GPT-2并未在模型结构上大作文章,只是使用了更多参数的模型和更多的训练数据(见表1)。GPT-2最重要的思想是提出了“所有的有监督学习都是无监督语言模型的一个子集”的思想,这个思想也是提示学习(Prompt Learning)的前身。GPT-2在诞生之初也引发了不少的轰动,它生成的新闻足以欺骗大多数人类,达到以假乱真的效果。甚至当时被称为“AI界最危险的武器”,很多门户网站也命令禁止使用GPT-2生成的新闻。
(3)GPT-3被提出时,除了它远超GPT-2的效果外,引起更多讨论的是它1750亿的参数量。GPT-3除了能完成常见的NLP任务外,研究者意外的发现GPT-3在写SQL,JavaScript等语言的代码,进行简单的数学运算上也有不错的表现效果。GPT-3的训练使用了情境学习(In-context Learning),它是元学习(Meta-learning)的一种,元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
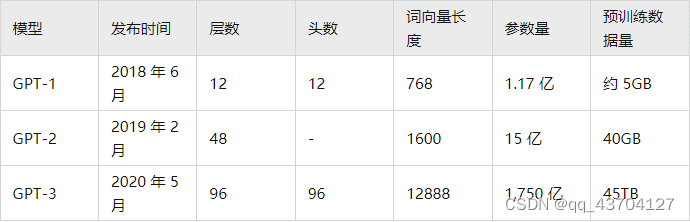
表1 GPT系列
2,指示学习(Instruct Learning)和提示学习(Prompt Learning)
指示学习是谷歌Deepmind的Quoc V.Le团队在2021年的一篇名为《Finetuned Language Models Are Zero-Shot Learners》文章中提出的思想,文中提出一种基于instruction-tuning的方法叫做FLAN(Finetuned Language Net),其中Instruction-tuning——finetuning language models on a collection of tasks (more than 60 NLP tasks) described via instructions。
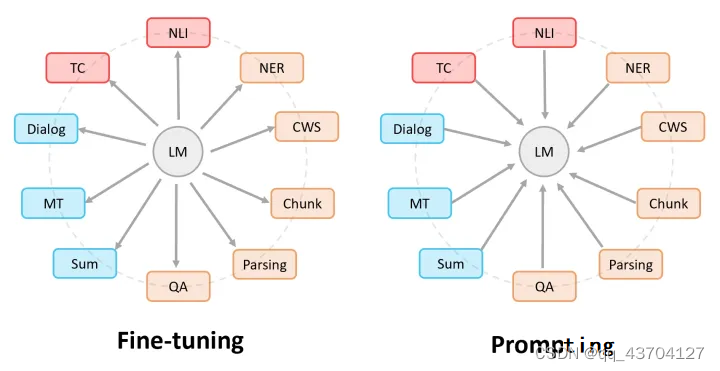
Prompt Learning是指对输入文本信息按照特定模板进行处理,把任务重构成一个更能充分利用预训练语言模型处理的形式。下图表示了微调和提示学习的区别:Fine-tuning中:是预训练语言模型“迁就“各种下游任务;Prompting中,是各种下游任务“迁就“预训练语言模型。
Instruct是激发语言模型的理解能力,它通过给出更明显的指令,让模型去做出正确的行动。Prompt是激发语言模型的补全能力,例如根据上半句生成下半句,或是完形填空等。举例如下:
(1)提示学习:给女朋友买了这个项链,她很喜欢,这个项链太____了。
(2)指示学习:判断这句话的情感:给女朋友买了这个项链,她很喜欢。选项:A=好;B=一般;C=差。
指示学习的优点是它经过多任务的微调后,也能够在其他任务上做zero-shot,而提示学习都是针对一个任务的。泛化能力不如指示学习。可以通过下图来理解微调,提示学习和指示学习:

3,强化学习
强化学习两个最基本的要素就是状态等观测值和奖励函数。监督学习两个最基本的要素就是训练数据和标签。这俩完全就是无缝链接,因为观测值可以作为训练数据,奖励函数可以作为损失函数,标签也有了。这样就可以在agent在环境里跑的时候不断获得训练数据和标签,本质上就是让agent的行为逐渐拟合奖励函数。强化学习并不需要人工标注数据,而是让机器自动学习标注。监督学习往往需要人为大量标注数据集,而强化学习需要人为创造环境和目标,让一个可以与环境交互的agent(代理人)自己学到达成目标的方法。
强化学习通过奖励(Reward)机制来指导模型训练,奖励机制可以看做传统模训练机制的损失函数。奖励的计算要比损失函数更灵活和多样(AlphaGO的奖励是对局的胜负),这带来的代价是奖励的计算是不可导的,因此不能直接拿来做反向传播。强化学习的思路是通过对奖励的大量采样来拟合损失函数,从而实现模型的训练。同样人类反馈也是不可导的,那么我们也可以将人工反馈作为强化学习的奖励,基于人工反馈的强化学习便应运而生。
InstructGPT/ChatGPT使用的RLHF最早可以追溯到Google在2017年发表的《Deep Reinforcement Learning from Human Preferences》,它通过人工标注作为反馈,提升了强化学习在模拟机器人以及雅达利游戏上的表现效果。
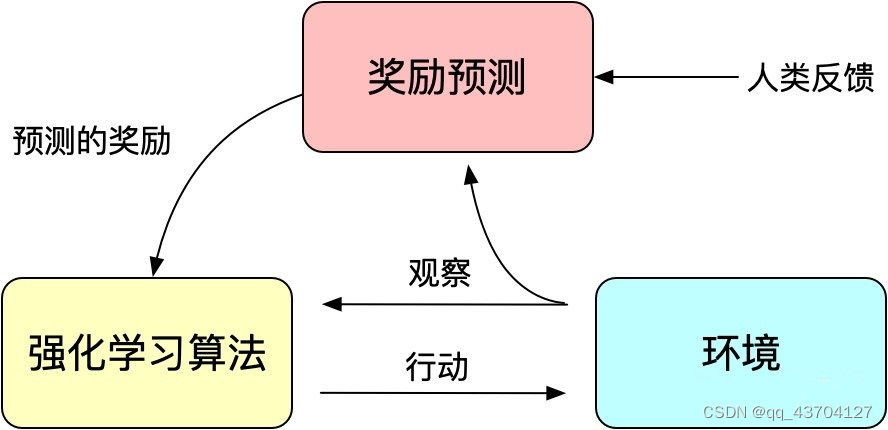
图:人工反馈的强化学习的基本原理
InstructGPT/ChatGPT还使用了强化学习的另外一个算法——最近策略优化(Proximal Policy Optimization,PPO),PPO算法是一种新型的Policy Gradient算法,Policy Gradient算法对步长十分敏感,但是又难以选择合适的步长,在训练过程中新旧策略的的变化差异如果过大则不利于学习。PPO提出了新的目标函数可以在多个训练步骤实现小批量的更新,解决了Policy Gradient算法中步长难以确定的问题。
4,InstructGPT/ChatGPT原理解读
(1)InstructGPT流程
InstructGPT/ChatGPT都是采用了GPT-3的网络结构,通过指示学习构建训练样本来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练。流程如下:
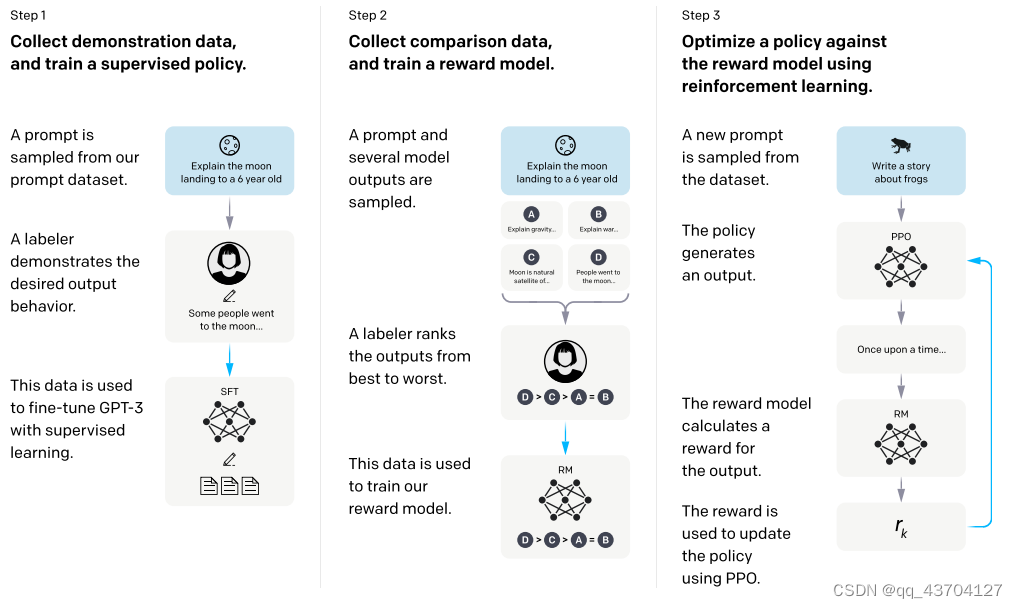
InstructGPT的计算流程:(1)有监督微调(SFT);(2)奖励模型(RM)训练;
(3)通过PPO根据奖励模型进行强化学习。
具体步骤解释如下:
步骤1.)从GPT-3的输入语句数据集中采样部分输入,基于这些输入,采用人工标注完成希望得到输出结果与行为,然后利用这些标注数据进行GPT-3有监督的训练。该模型即作为指令式GPT的冷启动模型。
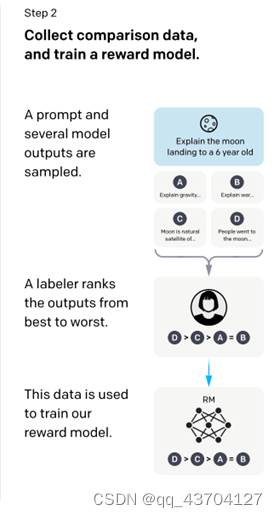
步骤2.)在采样的输入语句中,进行前向推理获得多个模型输出结果,通过人工标注进行这些输出结果的排序打标。最终这些标注数据用来训练reward反馈模型。
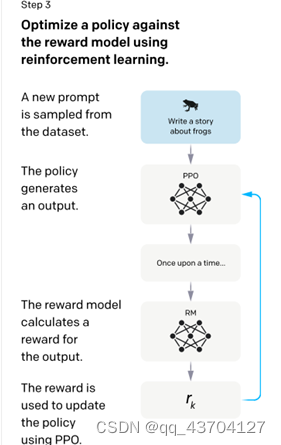
步骤3.)采样新的输入语句,policy策略网络生成输出结果,然后通过reward反馈模型计算反馈,该反馈回过头来作用于policy策略网络。以此反复,这里就是标准的reinforcement learning强化学习的训练框架了。
所以总结起来ChatGPT(对话GPT)其实就是InstructGPT(指令式GPT)的同源模型,然后指令式GPT就是基于GPT-3,先通过人工标注方式训练出强化学习的冷启动模型与reward反馈模型,最后通过强化学习的方式学习出对话友好型的ChatGPT模型。
(2)InstructGPT使用到的数据集
InstructGPT使用了三个数据集,分别是:SFT数据集,RM数据集,PPO数据集。
SFT数据集是用来训练第1步有监督的模型,即使用采集的新数据,按照GPT-3的训练方式对GPT-3进行微调。因为GPT-3是一个基于提示学习的生成模型,因此SFT数据集也是由提示-答复对组成的样本。RM数据集用来训练第2步的奖励模型。
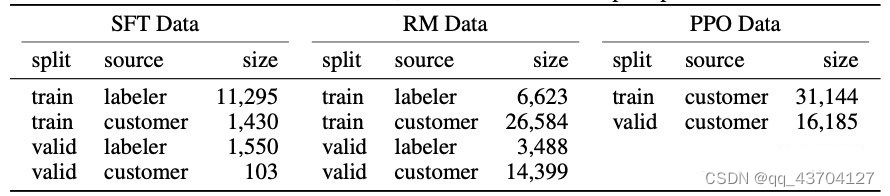
表2:InstructGPT的数据分布
(3)InstructGPT三个阶段详释
InstructGPT总结一下:RLHF用于第一二阶段,首先通过人工标注微调gpt模型得到SFT模型,用SFT模型生成k个回答人工排序,训练RM模型。第三阶段,把SFT模型参数拿来,用RM模型获得的reward进行训练,得到pro和pro-ptx模型。
- 有监督微调(SFT)
该阶段的输入是从测试用户提交的prompt(就是指令或问题)中随机抽取的一批数据(SFT数据集),主要分为两步:
- 对抽取的prompt数据人工进行高质量回答,获得<prompt,answer>数据对
- 通过高质量回答微调(fine-turn) gpt-3.5(InstructGPT)模型,在第一阶段帮助模型更好地理解输入指令。
这样,一个基本的 GPT-3.5语言模型就被学习成了这里的 SFT 模型。
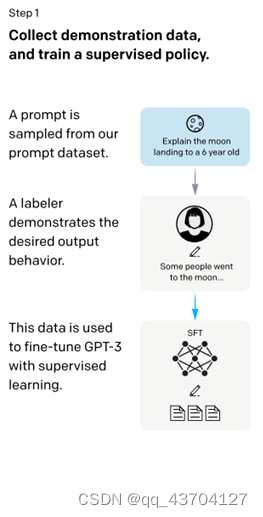
- 奖励模型(RM)
RM结构是将SFT训练后的模型的最后的嵌入层去掉后的模型。它的输入是prompt和Reponse,输出是奖励值。大致分为两步:
- 对于每个prompt,InstructGPT/ChatGPT会随机生成K个输出(4<=K<=9),然后向每个labeler(标注人员)成对的展示输出结果,也就是每个prompt共展示
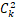 个结果,然后用户从中选择效果更好的输出,即人工标注排名顺序。
个结果,然后用户从中选择效果更好的输出,即人工标注排名顺序。 - 用排序结果训练数据对<prompt,answer>,在训练时,InstructGPT/ChatGPT将每个prompt的
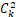 个响应对作为一个batch,这种按prompt为batch的训练方式要比传统的按样本为batch的方式更不容易过拟合,因为这种方式每个prompt会且仅会输入到模型中一次。
个响应对作为一个batch,这种按prompt为batch的训练方式要比传统的按样本为batch的方式更不容易过拟合,因为这种方式每个prompt会且仅会输入到模型中一次。
奖励模型的损失函数是:最大化labeler更喜欢的响应和不喜欢的响应之间的差值。公式如下:

其中rθ(x,y) 是提示x和响应y在参数为θ的奖励模型下的奖励值,yw是labeler更喜欢的响应结果, yl是labeler不喜欢的响应结果。D是整个训练数据集。
- 强化学习模型(PPO)
这一步数据集规模更大一些且和第一二阶段不同,且不再需要人工。其方法可以概括为以下四个部分:
- 由第一阶段的监督模型初始化PRO模型的参数
- PRO模型生成回答
- 用第二阶段RM模型对回答进行评估和打分
- 通过打分,更新训练PRO模型参数
InstructGPT/ChatGPT在训练过程中遇到了两个问题:
问题1:随着模型的更新,强化学习模型产生的数据和训练奖励模型的数据的差异会越来越大。作者的解决方案是在损失函数中加入KL惩罚项βlog(πφRLyx/πSFT(y|x)) 来确保PPO模型的输出和SFT的输出差距不会很大。
问题2:只用PPO模型进行训练的话,会导致模型在通用NLP任务上性能的大幅下降,作者的解决方案是在训练目标中加入了通用的语言模型目标γEX~Dpretrain[log(πφRL(x))] ,这个变量在论文中被叫做PPO-ptx。
综上,PPO的训练目标为:

5, 实验与模型的衡量
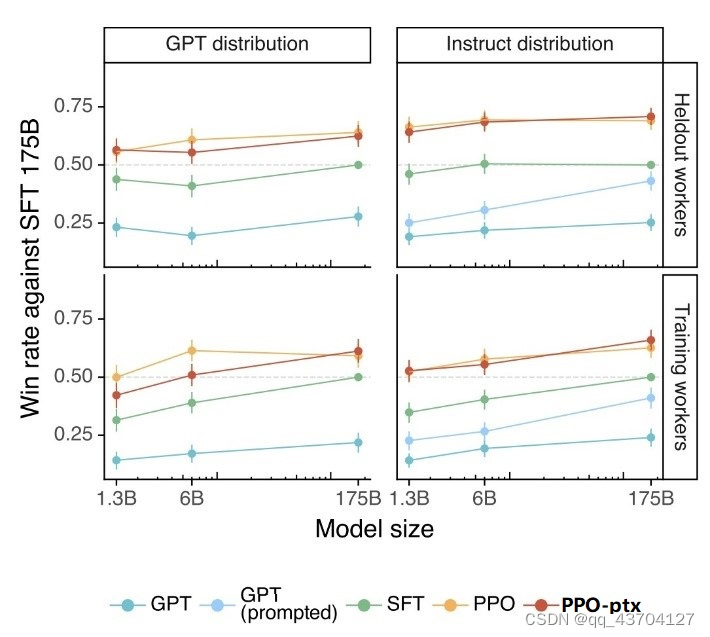
- Helpful——是否可以推断用户意图
测试方法是标注员在待测试模型的输出和 SFT 模型的输出中选择一个更好的。如果得分为 0.5 则表示该模型和 SFT 相比性能差不多。下图左侧为GPT提供prompt,右侧即为instructGPT提供的prompt测试得到的结果。可以看出pro和pro-ptx模型相对于其它模型取得了更好的效果。
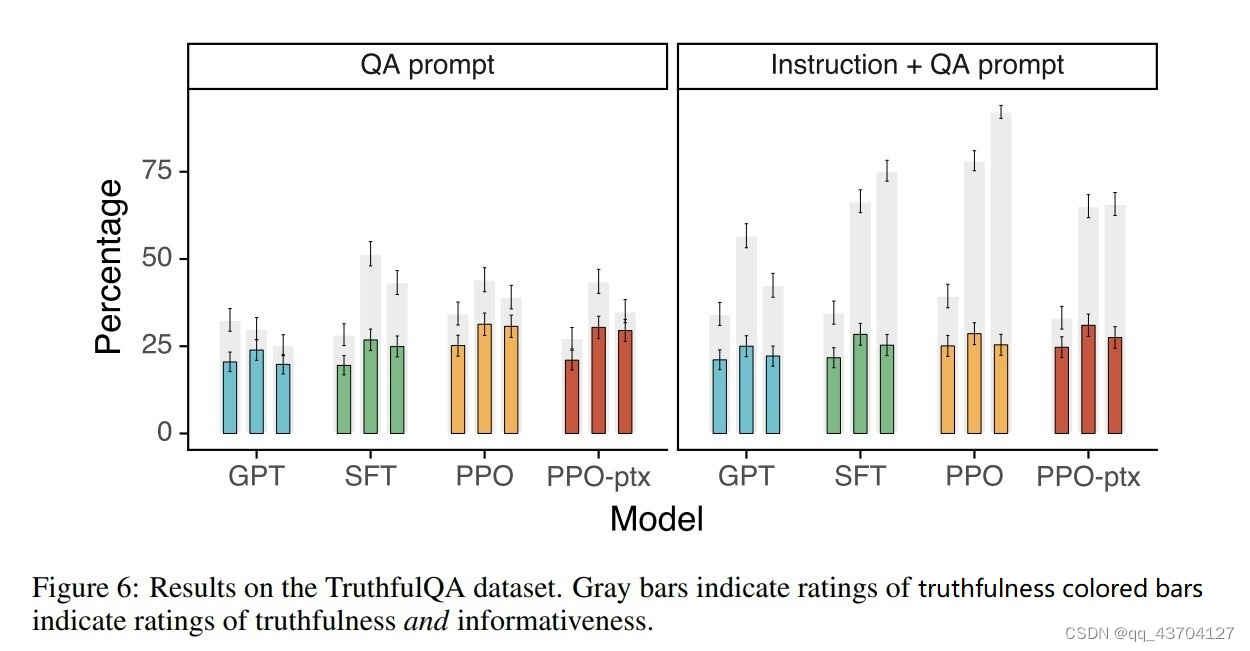
- honest
方法是在模型前加上如下这样的 instruction prompt,提示模型该小心什么问题,该怎样回答。

结果如下,右图即为加上instruction的效果。其中灰色代表可信度,有颜色的即代表同时可信和包含信息量的额比率:
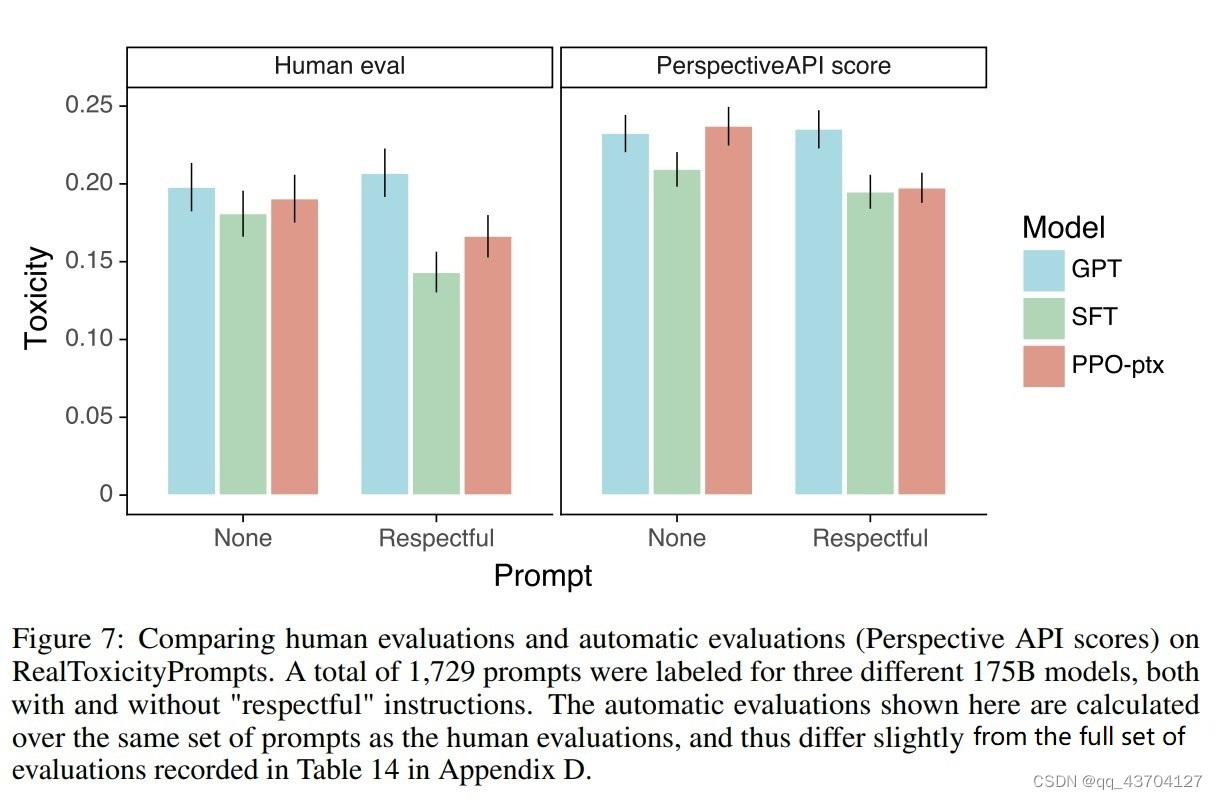
- harmless
方法也是加上instruction,从而减少模型产生有害/不礼貌/带有偏见的回答,效果如下所示:
参考链接:

