
- 1React Hooks全面解读与高效开发实践
- 2Java项目实战案例 - 搭建微服务自动构建环境(gitee + docker + jenkins + maven)_ecs docker maven gitee jenkins ssh
- 3Spring Security进行登录认证和授权_spring security认证和授权流程
- 4在一个Python文件中执行另外一个Python文件,并获取输出到控制台的结果_在一个python文件中执行另一个python文件并获取其返回的变量
- 5Asp .Net Core 系列:集成 Refit 和 RestEase 声明式 HTTP 客户端库
- 6华为配置通过流策略实现流量统计
- 7令人笑喷的56个代码注释,最后几个老衲实在憋不住了。。。_drunk, fix later
- 8【Flutter】插件包选择 ( 查看文档是否全面 | 查看插件包的更新版本次数 | 查看使用示例 | 查看 GitHub 项目的 Star Fork Issues )_flutter 查看插件历史版本
- 9【自然语言处理】基于句子嵌入的文本摘要算法实现_grucell生成句子嵌入
- 10Oracle12c的容器数据库和热插拔数据库_oracle容器数据库
python批量爬取某站视频_python下载b站视频
赞
踩
前言:
本项目是批量下载B站如下图示例的视频:

(家里的小孩想看动画片,就下载到U盘上在电视上给他们放。。。)
一、所用到的库函数以及具体作用
在这个项目中,涉及到的模块有以下几个:
1.shutil: Python 标准库中的一个模块,用于文件操作,包括复制、移动、删除文件等。在这个项目中,主要用于创建文件夹和删除空文件夹。
2.re: Python 标准库中的正则表达式模块,用于对字符串进行模式匹配和查找。在这个项目中,主要用于从 HTML 文本中提取视频标题和音视频链接。
3.json: Python 标准库中的 JSON 编解码模块,用于处理 JSON 格式的数据。在这个项目中,主要用于解析从 Bilibili 获取的视频信息。
4.os: Python 标准库中的操作系统接口模块,提供了许多与操作系统交互的函数。在这个项目中,主要用于创建文件夹、检查文件是否存在、删除文件等操作。
5.ffmpeg: ffmpeg 是一个开源的音视频处理工具,可以用于处理、转换音视频文件。在这个项目中,使用了 ffmpeg 来合并下载的音频和视频文件。
6.requests: 第三方库,用于发送 HTTP 请求。在这个项目中,用于获取 Bilibili 视频的页面源代码和视频、音频文件。
7.multiprocessing.pool.ThreadPool: Python 标准库中的多线程池模块,用于并发执行任务。在这个项目中,用于并发下载多个视频文件,加快下载速度。
其中,shutil, re, json, os和multiprocessing.pool是 Python 的标准库,通常无需额外安装。而ffmpeg, requests是第三方库函数,可以通过下面命令进行安装:
pip install ffmpeg-python
pip install requsets
导入需要的包:
import json
import os
import re
import shutil
from multiprocessing.pool import ThreadPool
import ffmpeg
import requests
- 1
- 2
- 3
- 4
- 5
- 6
- 7
二、具体实现步骤:
1、在全局上,我定义了一个变量: index_num 作为我要下载的集数(也就是我这个视频有多少集啦)。需要注意的是,根据B站的反爬机制,爬取B站视频的时候记得在请求头上添加上Referer作为防盗链,否则会出现403错误。
下面是我在全局定义的一些变量:
# 视频总集数
index_num = 10
headers = {
'Referer': 'https://search.bilibili.com/all',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}
# 文件保存路径
fileSavePath = 'E:\\Software\\Python\\Code\\爬虫\\哆啦A梦\\'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.在复制url的时候,最好是复制第二集的。下面就是我需要爬取视频的第二集url链接。
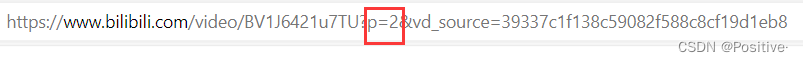
将=后面的数字2改成{i}就可以访问到每一集视频的链接了。
在这里,我定义了一个getResponse()方法用来获取url的响应结果。B站上的视频是将视频和音频分开的。在这个方法里,可以获取到每一集的视频和音频的下载链接,同时也获取到视频的标题,方便后面保存。
这里的重点在于找到音视频的下载接口,而B站的音视频链接就放在“playinfo”中。我们可以在通过浏览器的页面源代码查找playinfo关键词进行查看。这里我就通过正则表达式匹配到了playinfo的相关内容,再将其转化为字典后进行匹配音视频链接。
具体代码如下:
def getResponse(i): url = f"https://www.bilibili.com/video/BV1zN4y1v7Vv?p={i}&vd_source=39337c1f138c59082f588c8cf19d1eb8" res = requests.get(url, headers=headers) # 获取视频标题 videoTitle = re.findall('<title data-vue-meta="true">(.*?)_哔哩哔哩_bilibili</title>', res.text)[0].split('&')[0] # 获取视频音频数据 play_info = re.findall('<script>window.__playinfo__=(.*?)</script>', res.text)[0] json_data = json.loads(play_info) # 将获得的play_info转化为python对象(字典),方便后面操作 # pprint.pprint(json_data) # 以更规范的格式查看字典json_data audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0] video_url = json_data['data']['dash']['video'][0]['baseUrl'] # 封装数据 videoInfo = { 'i': i, 'title': videoTitle, 'audio_url': audio_url, 'video_url': video_url } return videoInfo

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3.接下来就是下载视频和音频了,这里没有什么好说的。我定义了一个download()方法来进行下载保存。方便后面管理,我又在本目录下新建了一个文件夹用来保存下载的音视频片段。(具体的步骤将在主函数中实现)
def download(i): videoInfo = getResponse(i) # print(videoInfo) # 下载视频 try: # 保存视频和音频 video = requests.get(videoInfo['video_url'], headers=headers).content audio = requests.get(videoInfo['audio_url'], headers=headers).content with open(fileSavePath + '视频片段\\' + videoInfo['title'] + '_video.mp4', mode='wb') as f: f.write(video) with open(fileSavePath + '视频片段\\' + videoInfo['title'] + '_audio.mp3', mode='wb') as f: f.write(audio) except Exception as e: print("发生异常:", videoInfo['title']) print("异常信息:", e) combine(videoInfo)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
4.在每个视频下载完成后会由combine()方法将视频和音频进行合并。当音视频合并成功后,会将其删除掉。
最开始我采用的是第三方工具ffmpeg工具,但是这个需要通过python调用终端命令,不能通过多线程运行,后面被我改成了使用python的第三方库函数:ffmpeg-python合并音视频。
def combine(videoInfo): if os.path.exists(f'{fileSavePath}视频片段\\{videoInfo["title"]}_video.mp4') and os.path.exists( f'{fileSavePath}视频片段\\{videoInfo["title"]}_audio.mp3'): video_path = f"{fileSavePath}视频片段\\{videoInfo['title']}_video.mp4" # 视频文件路径 audio_path = f"{fileSavePath}视频片段\\{videoInfo['title']}_audio.mp3" # 音频文件路径 output_path = fileSavePath + f"{videoInfo['title']}.mp4" # 输出文件路径 try: input_video = ffmpeg.input(video_path) input_audio = ffmpeg.input(audio_path) # 使用 concat 过滤器将视频流和音频流合并 command = ffmpeg.output(input_video.video, input_audio.audio, output_path, vcodec='copy', acodec='aac') # 运行 ffmpeg 命令 ffmpeg.run(command, capture_stderr=True) print(f"{videoInfo['title']}。。。下载成功") os.remove(video_path) os.remove(audio_path) except: print(f"{videoInfo['title']}。。。合并失败")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
5.最后就是主函数了,因为是批量下载视频,我选择采用多线程的方式进行下载。除此之外,为了便于管理,我在本文件路径下新建了一个“视频片段”文件夹保存临时下载的音视频片段,当音视频全部合并成功后,文件夹被清空又会将这个文件夹删除。
def main(): # 创建保存文件目录 try: os.makedirs(fileSavePath) except: pass # 创建文件夹用来保存已下载的音视频片段 try: os.makedirs(fileSavePath + '视频片段') except: pass # 采用多线程下载 pool = ThreadPool(processes=5) segments = range(1, index_num + 1) pool.map(download, segments) pool.close() pool.join() # 删除空文件夹 if len(os.listdir(fileSavePath + '视频片段')) == 0: shutil.rmtree(fileSavePath + '视频片段')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
以下是我的全部代码:
import json import os import re import shutil from multiprocessing.pool import ThreadPool import ffmpeg import requests # 视频总集数 index_num = 10 headers = { 'Referer': 'https://search.bilibili.com/all', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36' } # 文件保存路径 fileSavePath = 'E:\\Software\\Python\\Code\\爬虫\\哆啦A梦\\' # 获取url响应体 def getResponse(i): url = f"https://www.bilibili.com/video/BV1zN4y1v7Vv?p={i}&vd_source=39337c1f138c59082f588c8cf19d1eb8" res = requests.get(url, headers=headers) # 获取视频标题 videoTitle = re.findall('<title data-vue-meta="true">(.*?)_哔哩哔哩_bilibili</title>', res.text)[0] # 获取视频音频数据 play_info = re.findall('<script>window.__playinfo__=(.*?)</script>', res.text)[0] json_data = json.loads(play_info) # 将获得的play_info转化为python对象(字典),方便后面操作 # pprint.pprint(json_data) # 以更规范的格式查看字典json_data audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0] video_url = json_data['data']['dash']['video'][0]['baseUrl'] # 封装数据 videoInfo = { 'i': i, 'title': videoTitle, 'audio_url': audio_url, 'video_url': video_url } return videoInfo def download(i): videoInfo = getResponse(i) # print(videoInfo) # 下载视频 try: # 保存视频和音频 video = requests.get(videoInfo['video_url'], headers=headers).content audio = requests.get(videoInfo['audio_url'], headers=headers).content with open(fileSavePath + '视频片段\\' + videoInfo['title'] + '_video.mp4', mode='wb') as f: f.write(video) with open(fileSavePath + '视频片段\\' + videoInfo['title'] + '_audio.mp3', mode='wb') as f: f.write(audio) except Exception as e: print("发生异常:", videoInfo['title']) print("异常信息:", e) combine(videoInfo) # 合并视频和音频文件 def combine(videoInfo): if os.path.exists(f'{fileSavePath}视频片段\\{videoInfo["title"]}_video.mp4') and os.path.exists( f'{fileSavePath}视频片段\\{videoInfo["title"]}_audio.mp3'): video_path = f"{fileSavePath}视频片段\\{videoInfo['title']}_video.mp4" # 视频文件路径 audio_path = f"{fileSavePath}视频片段\\{videoInfo['title']}_audio.mp3" # 音频文件路径 output_path = fileSavePath + f"{videoInfo['title']}.mp4" # 输出文件路径 try: input_video = ffmpeg.input(video_path) input_audio = ffmpeg.input(audio_path) # 使用 concat 过滤器将视频流和音频流合并 command = ffmpeg.output(input_video.video, input_audio.audio, output_path, vcodec='copy', acodec='aac') # 运行 ffmpeg 命令 ffmpeg.run(command, capture_stderr=True) print(f"{videoInfo['title']}。。。下载成功") os.remove(video_path) os.remove(audio_path) except: print(f"{videoInfo['title']}。。。合并失败") def main(): # 创建保存文件目录 try: os.makedirs(fileSavePath) except: pass # 创建文件夹用来保存已下载的音视频片段 try: os.makedirs(fileSavePath) os.makedirs(fileSavePath + '视频片段') except: pass # 采用多线程下载 pool = ThreadPool(processes=5) segments = range(1, index_num + 1) pool.map(download, segments) pool.close() pool.join() # 删除空文件夹 if len(os.listdir(fileSavePath + '视频片段')) == 0: shutil.rmtree(fileSavePath + '视频片段') if __name__ == '__main__': main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
以上就是批量爬取视频的代码,基本上每个地方都有注释,相信有爬虫基础的小伙伴都能看懂。我相信有厉害的小伙伴会有更好的方法,希望不要吝啬可以给我分享一下。拜拜~~
(第一次写博客,写得不好请勿见怪。谢谢!)

