
热门标签
热门文章
- 1thinkphp日志泄漏漏洞_Thinkphp5 远程代码执行漏洞事件分析报告
- 2数据要素时代,企业数据如何安全合规流通?
- 3【深度学习】Transformer长大了,它的兄弟姐妹们呢?(含Transformers超细节知识点)...
- 4下载AOSP源码编译、调试、刷机_aosp_arm64-exp-u1b1.230908.003-10811961-24d7d0fa
- 5最强Node js 后端框架学习看这一篇文章就够_使用node写后台 框架
- 6Laravel 6 - 第十五章 验证器
- 7IDEA上配置Maven环境
- 8python 文本分类卡方检验_中文文本分类:你需要了解的10项关键内容
- 9程序员年龄大了,真的会失业吗?那么以后该怎么办_游戏开发年龄大了怎么办
- 10详解UART通信协议以及FPGA实现
当前位置: article > 正文
从头开始训练 BERT 的终极指南:分词器 从文本到令牌:BERT 令牌化分步指南_中文bert分词器
作者:从前慢现在也慢 | 2024-04-16 07:51:30
赞
踩
中文bert分词器
您是否知道标记文本的方式可以成就或破坏您的语言模型?您是否曾经想过用一种罕见的语言或专门的领域来标记文档?将文本分割成标记,这不是一件苦差事;它是将语言转化为可操作的情报的门户。这个故事将教你关于标记化所需了解的一切,不仅适用于 BERT,也适用于任何法学硕士。
在我的上一篇文章中,我们讨论了BERT,探讨了它的理论基础和训练机制,并讨论了如何对其进行微调并创建问答系统。现在,当我们进一步探讨这一开创性模型的复杂性时,是时候关注一下无名英雄之一了:标记化。
我得到它; 标记化似乎是您和令人兴奋的模型训练过程之间的最后一个无聊的障碍。相信我,我以前也是这么想的。但我在这里告诉你,代币化不仅仅是一种“必要的罪恶”——它本身就是一种艺术形式。
在这个故事中,我们将检查标记化管道的每个部分。有些步骤是微不足道的(如标准化和预处理),而其他步骤(如建模部分)则使每个标记生成器独一无二。
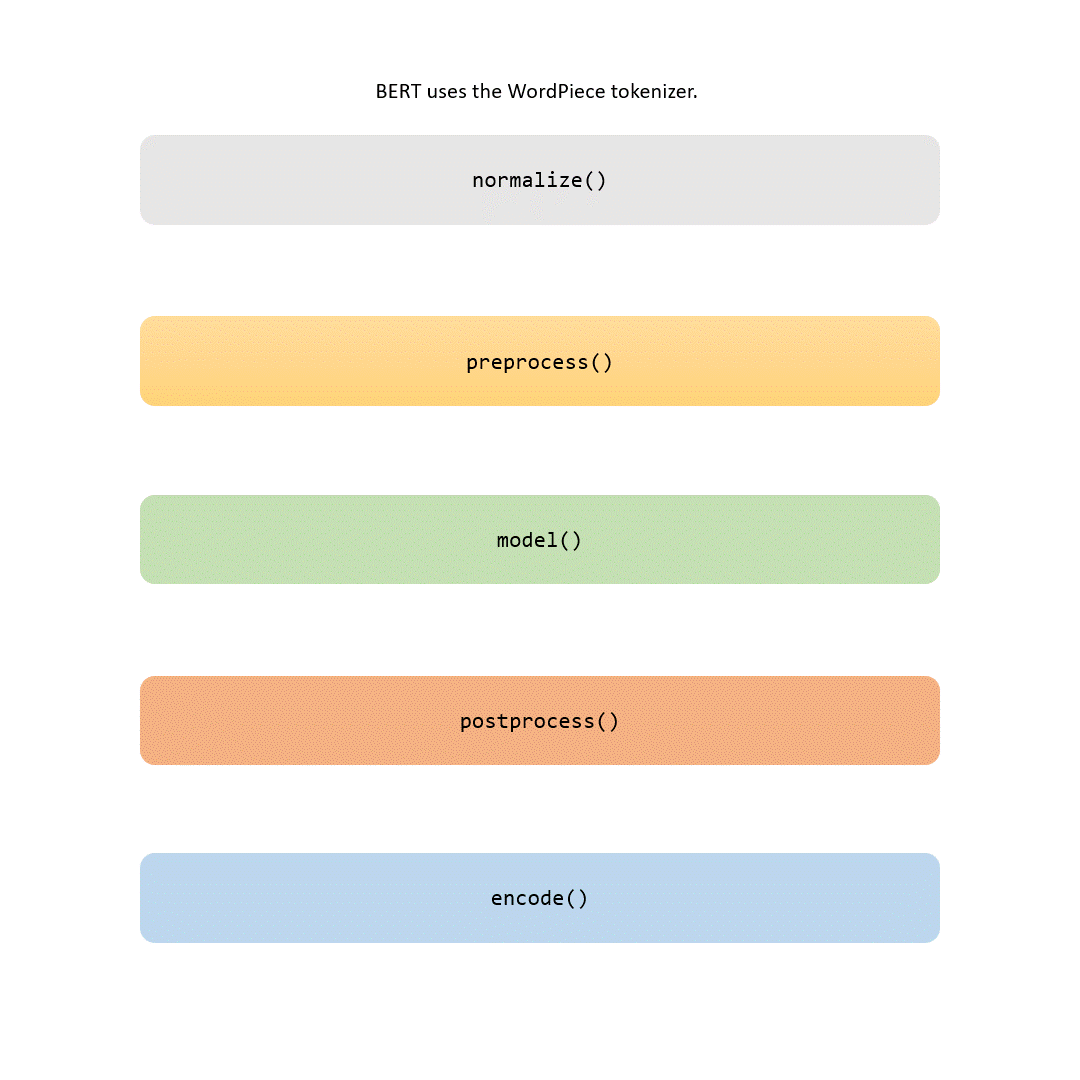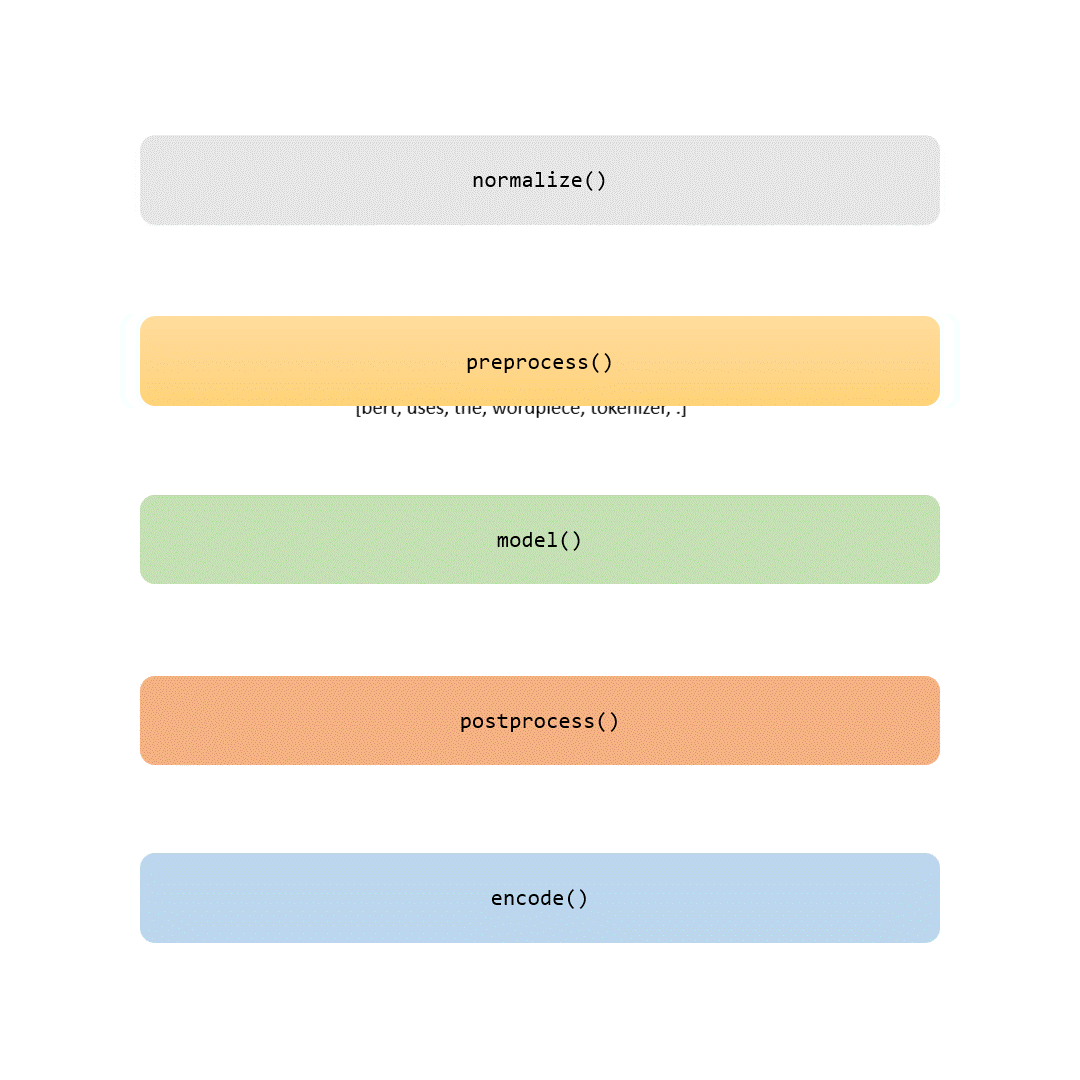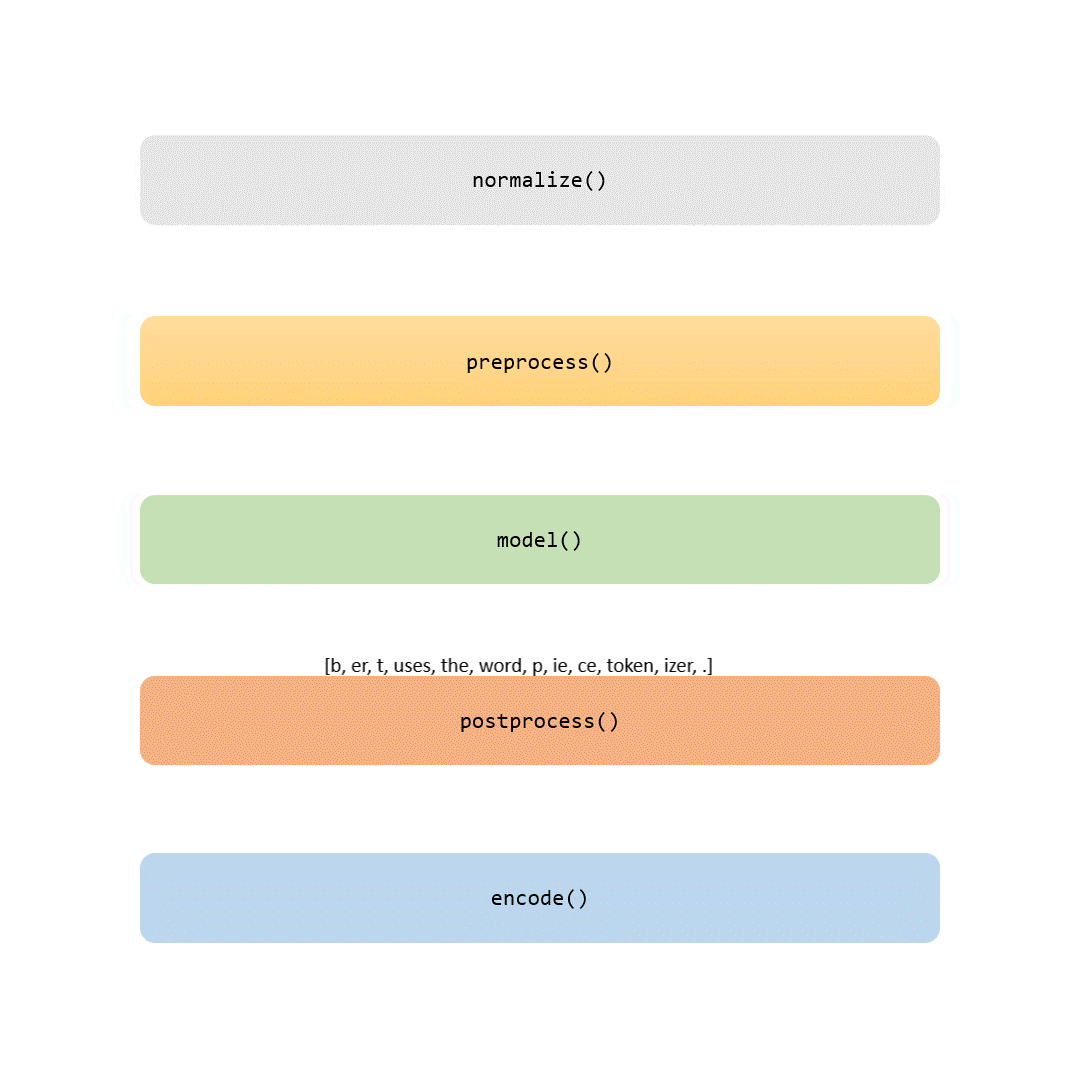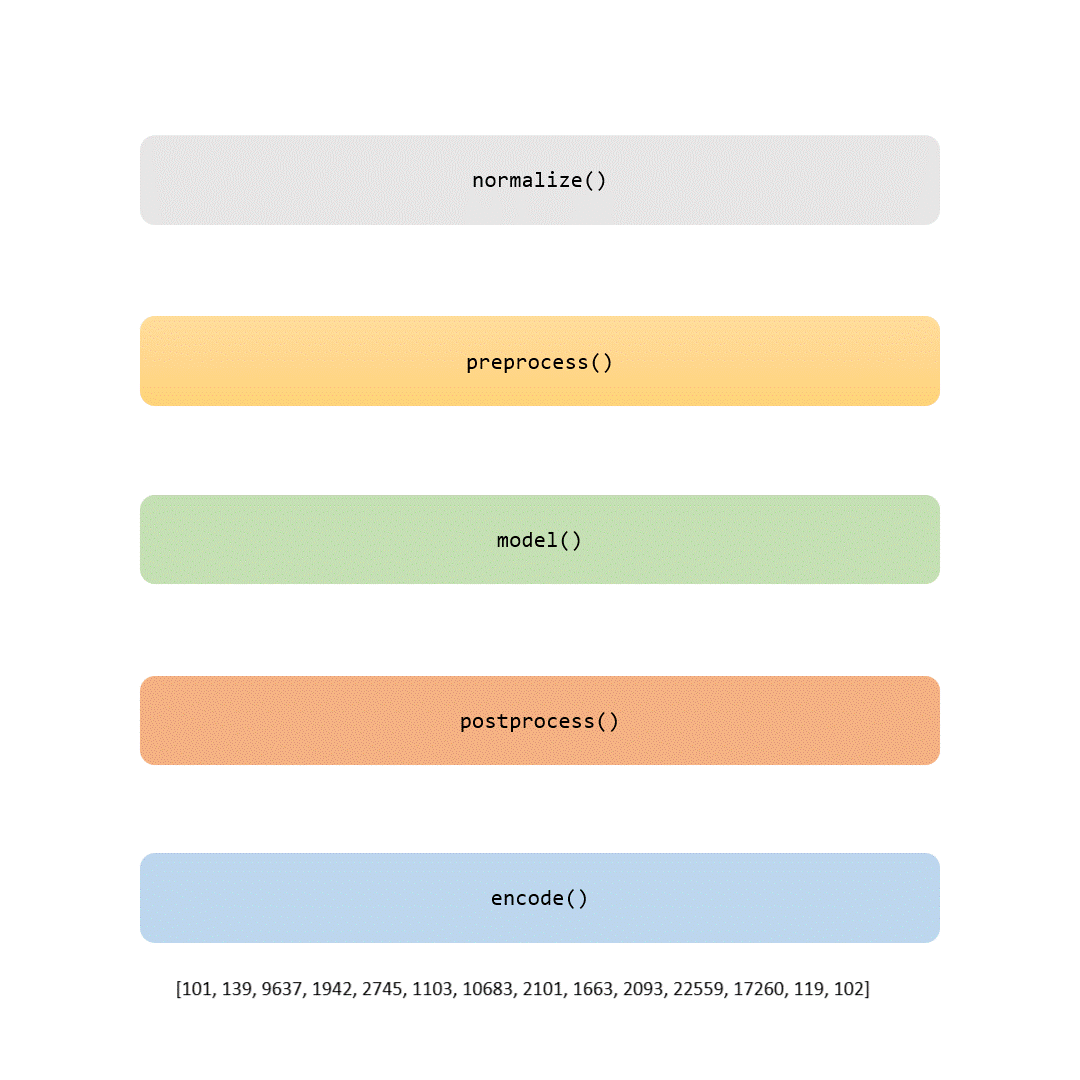
当您读完本文时,您不仅会了解 BERT 分词器的详细信息,而且还能够根据自己的数据对其进行训练。如果您喜欢冒险,您甚至可以使用工具在从头开始训练您自己的 BERT 模型时自定义这一关键步骤。
将文本分割成标记,这不是一件苦差事;它是将语言转化为可操作的情报的门户。
那么,为什么代币化如此重要?从本质上讲,标记化是一个翻译器;它接收人类语言并将其翻译成机器可以理解的语言:数字。但有一个问题:在这个翻译过程中,分词器必须保持关键的平衡,找到意义和计算
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/433091
推荐阅读
相关标签

