
- 1超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了_爬虫python入门
- 2【Doris】Doris 最佳实践-Compaction调优(3)_doris中如何查看哪个表的版本有堆积?
- 3⑩② 【MySQL索引】详解MySQL`索引`:结构、分类、性能分析、设计及使用规则。_mysql 索引名带`
- 4CentOS 7.6 防火墙打开、关闭,端口开启、关闭_centos7.6开放端口命令
- 5李宏毅-2023春机器学习 ML2023 SPRING-学习笔记:2/24 正确认识chatGPT_李宏毅2023gpt
- 6yaw(pan)/pitch(tilt)/roll计算_yaw pitch roll计算
- 7Vivado PLL锁相环 IP核的使用
- 8雪花id如何保证连续且不重复
- 9解决ssh:connect to host github.com port 22: Connection timed out与kex_exchange_identification_cloning into 'gonganzichan'... ssh: connect to hos
- 10循环队列的初始化,入队,出队,求队长,取队头元素_循环队列初始化
【AI理论学习】理解词向量、CBOW与Skip-Gram模型_cbow和skip-gram
赞
踩
理解词向量、CBOW与Skip-Gram
由于计算机不能直接对各种字符进行运算,为此需要将词的表示进行一些转换。因此,在自然语言处理中,通常需要对输入的语料进行一些预处理:
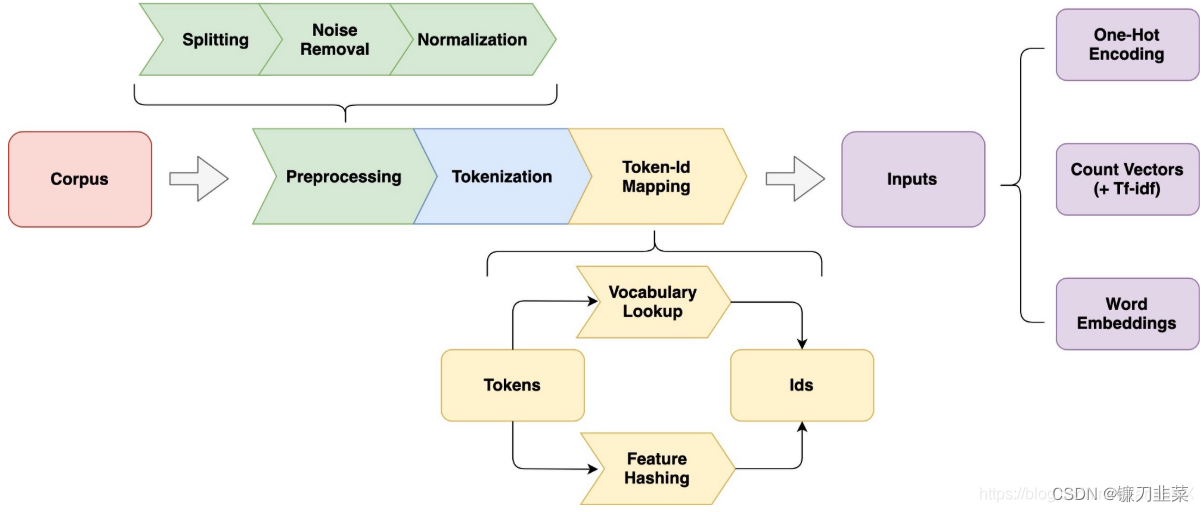
其中,如何对词汇进行表示是很关键的问题,糟糕的表示方法容易导致所谓的 “Garbage in, garbage out”。
词向量基础知识
对词汇的表示,常见的有One-hot represention 和 Distributed Representation 两种形式。
One-hot表示
One-hot represention 将词汇用二进制向量表示,这个向量表示的词汇,仅仅在词汇表中的索引位置处为1,其他地方都为0。例子如下图所示:

这样的方式表示词汇虽然简单,但是也有如下缺点:
- 单词的上下文丢失了。
- 没有考虑频率信息。
- 词汇量大的情况下,向量维度高且稀疏,占用内存。
Distributed表示
Distributed Representation 也可以理解为Word Embedding,具体形式为:

注意到,使用Word Embedding得到的向量维度远小于词汇表的个数。如果将上面的向量在空间中表示,可以得到:

上图告诉我们,通过词向量之间的距离可以度量他们之间的关系,意思相近的词在空间中的距离比较近。出现这种现象的原因是最后得到的词向量在训练过程中学习到了词的上下文。
那么,Distributed Representation 要如何得到?
- 使用神经网络语言模型可以得到;
- 使用word2vec。
word2vec基础知识
word2vec是google在2013年推出的一个NLP工具,它的特点是将所有的词向量化,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。在正式讲解 word2vec 前,还需要对一些基本概念有所了解。
CBOW和Skip-gram
CBOW模型(Continuous Bag-of-Words Model)和Skip-gram模型(Continuous Skip-gram Model)。如下图所示:
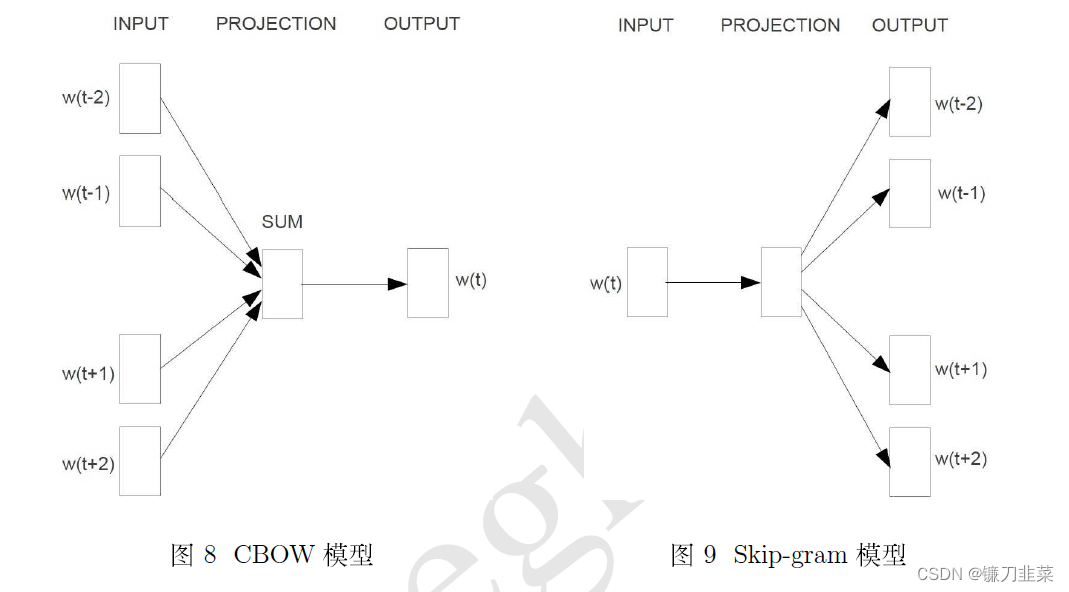
由图可见,两个模型都包含三层:输入层、投影层和输出层。前者是在已知当前词
w
t
w_t
wt的上下文
w
t
−
2
,
w
t
−
1
,
w
t
+
1
,
w
t
+
2
w_{t-2},w_{t-1},w_{t+1},w_{t+2}
wt−2,wt−1,wt+1,wt+2的前提下预测当前词
w
t
w_t
wt(CBOW模型);而Skip-gram模型则恰恰相反,是在已知当前词
w
t
w_t
wt的前提下,预测其上下文
w
t
−
2
,
w
t
−
1
,
w
t
+
1
,
w
t
+
2
w_{t-2},w_{t-1},w_{t+1},w_{t+2}
wt−2,wt−1,wt+1,wt+2。
霍夫曼树
一般情况下,词汇表中词汇的数量是非常多的,如果用传统的DNN+Softmax的方式来训练词向量,计算量太大了。于是,word2vec 使用的数据结构是用霍夫曼树来代替隐藏层和输出层的神经元。霍夫曼树的叶子节点起到输出层神经元的作用,叶子节点的个数即为词汇表的小大, 而内部节点则起到隐藏层神经元的作用。这里首先需要了解下霍夫曼树。
从实际的例子出发,看看如何构造霍夫曼树:
假设有(a,b,c,d,e,f)共6个词汇,词汇的权值用词频表示:
w
a
=
16
,
w
b
=
4
,
w
c
=
8
,
w
d
=
6
,
w
e
=
20
,
w
f
=
3
w_a=16,w_b=4,w_c=8,w_d=6,w_e=20,w_f=3
wa=16,wb=4,wc=8,wd=6,we=20,wf=3,假设这6个词汇是6棵只要根节点的森林集合。于是构造步骤如下:
首先是权值最小的b和f合并,得到的新树,根节点权重是7。将b于f这两个树从列表中删除,并且添加刚刚得到的合并的树。此时森林里共有5棵树,根节点权重分别是16,8,6,20,7。此时根节点权重最小的6,7对应的树合并,得到新子树,依次类推,最终得到下面的霍夫曼树:
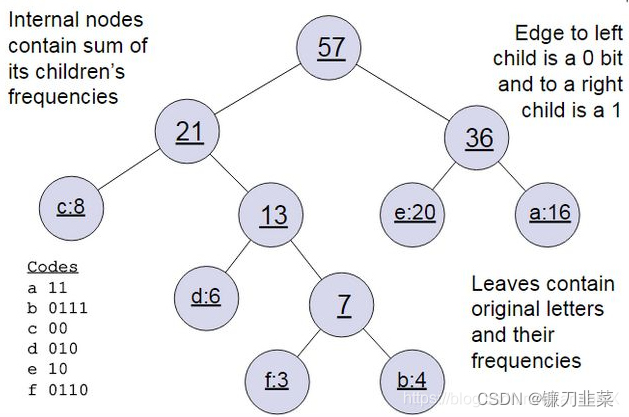
如何编码呢?一般对于一个霍夫曼树的节点(根节点除外),可以约定左子树编码为0,右子树编码为1。如上图,则可以得到c的编码是00。
注意,在word2vec中,约定编码方式和上面的例子相反,即约定左子树编码为1,右子树编码为0,同时约定左子树的权重不小于右子树的权重。
那么霍夫曼树有什么好处呢?一般得到霍夫曼树后我们会对叶子节点进行霍夫曼编码,由于权重高的叶子节点越靠近根节点,而权重低的叶子节点会远离根节点。这样我们的高权重节点编码值较短,而低权重值编码值较长。这保证的树的带权路径最短,即我们希望越常用的词拥有更短的编码。
有了上面的基础知识,就可以对word2vec进行讲解了。相比于用传统的神经网络的方法来训练词向量,于word2vec提出了有两种改进方法:一种是基于 Hierarchical Softmax 算法的,另一种是基于 Negative Sampling 算法的。
基于Hierarchical Softmax的 CBOW 模型和 Skip-gram 模型
CBOW 模型
基本结构
CBOW 模型是在已知当前词
w
t
w_t
wt的上下文
w
t
−
2
,
w
t
−
1
,
w
t
+
1
,
w
t
+
2
w_{t-2},w_{t-1},w_{t+1},w_{t+2}
wt−2,wt−1,wt+1,wt+2的前提下预测当前词
w
t
w_t
wt。后面我们用
c
o
n
t
e
x
t
(
w
)
context(w)
context(w)来表示词w的上下文中的词,通常,我们取词w前后2c个单词来组成
c
o
n
t
e
x
t
(
w
)
context(w)
context(w)。下图给出了CBOW模型的网络结构:
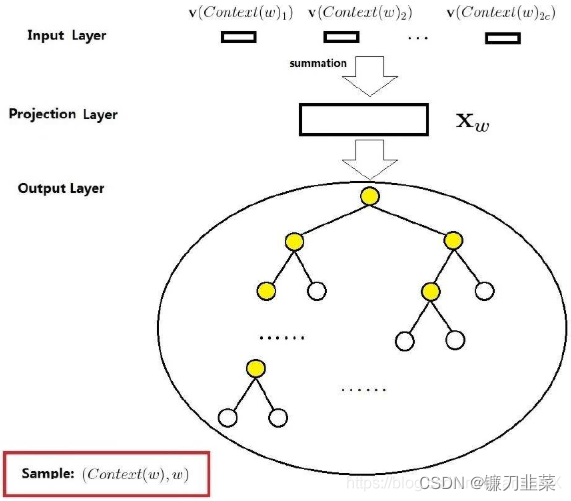
它包括三层:输入层、投影层、输出层。
- 输入层:包含 c o n t e x t ( w ) context(w) context(w)中的 2 c 2c 2c个词向量 v ( c o n t e x t ( w ) 1 ) , v ( c o n t e x t ( w ) 2 ) , … , v ( c o n t e x t ( w ) 2 c ) ∈ R m \mathbf v(context(w)_1),\mathbf v(context(w)_2),\ldots,\mathbf v(context(w)_{2c}) \in \mathbf R^m v(context(w)1),v(context(w)2),…,v(context(w)2c)∈Rm,每个词向量的长度是 m m m。
- 投影层:将输入层的2c个词向量累加求和,即 x w = ∑ i = 1 2 c v ( c o n t e x t ( w ) i ) \mathbf x_w = \sum_{i=1}^{2c}\mathbf v(context(w)_i) xw=∑i=12cv(context(w)i)。
- 输出层:输出层是用哈夫曼算法以各词在语料中出现的次数作为权值生成的一颗二叉树,其叶子结点是语料库中的所有词,叶子个数N=|D|,分别对应词典D中的词。
神经网络语言模型(NNLM)中大部分计算集中在隐藏层和输出层之间的矩阵向量运算,以及输出层上的softmax归一化运算,CBOW模型对此进行了改进。与传统的神经网络语言模型相比:
- NNLM是简单的讲输入的向量进行拼接,而CBOW模型将上下文的词累加求和作为输入;
- NNLM是线性结构,而CBOW是树形结构
- NNLM具有隐藏层,而CBOW没有隐藏层
目标函数
假设对于给定的文本,“我”、“喜欢”、“观看”、“巴西”、“足球”、“世界杯”这六个词出现的次数分别为15, 8, 6, 5, 3, 1。于是可以用这些语料构建霍夫曼树,并将其作为CBOW模型的输出层。如下图所示:

注意:与常规的霍夫曼树不同,左子树用1编码,右子树用0编码。
接下来,用 p w p^w pw表示从根结点出发到达 w w w对应叶子结点的路径, l w l^w lw表示这个路径中包含结点的个数, p l w p_{l}^w plw表示路径 p w p^w pw中的第 l l l个结点, d j w d_j^w djw表示路径 p w p^w pw中第 j j j个结点对应的编码(0或1), θ j w \theta^w_j θjw表示路径 p w p^w pw中第 j j j个非叶子结点对应向量。
我们的目标是利用输入向量 X w X_w Xw 和霍夫曼树来定义函数 p ( w ∣ c o n t e x t ( w ) ) p(w|context(w)) p(w∣context(w))。
以图中的词
w
=
"
足球
"
w="足球"
w="足球"为例,从霍夫曼树的根结点出发到“足球”,中间经历了4个分支,每一次分支,都可以看成进行了一次二分类。那么从二分类的角度来看,对于每个非叶子结点,就需要为其左右孩子指定类别。我们规定:编码为1的结点定义为负类,编码为0的结点定义为正类。也就是说,将一个结点进行二分类,分到左边是负类,分到右边是正类。所以有:
L
a
b
e
l
(
p
i
w
)
=
1
−
d
i
w
,
i
=
1
,
2
,
…
,
l
w
Label(p_i^w) = 1- d_i^w, \quad i=1,2,\ldots,l^w
Label(piw)=1−diw,i=1,2,…,lw
我们用逻辑斯蒂回归进行二分类,一个结点被分为正类的概率是:
σ
(
x
w
T
θ
)
=
1
1
+
e
−
x
w
T
θ
\sigma(\mathbf x_w^T\theta) = \frac{1}{1+e^{-\mathbf x_w^T\theta}}
σ(xwTθ)=1+e−xwTθ1
被分成负类的概率为:
1
−
σ
(
x
w
T
θ
)
1-\sigma(\mathbf x_w^T\theta)
1−σ(xwTθ)
这里的
θ
\theta
θ就是非叶子节点对应的向量,是个待定参数。
所以,从霍夫曼树的根结点出发到“足球”,中间经历了4个二分类,每个分类的结果如下:
第一次:
p
(
d
2
w
∣
x
w
,
θ
1
w
)
=
1
−
σ
(
x
w
T
θ
1
w
)
p(d_2^w|\mathbf x_w,\theta_1^w) = 1- \sigma(\mathbf x_w^T\theta_1^w)
p(d2w∣xw,θ1w)=1−σ(xwTθ1w)
第二次:
p
(
d
3
w
∣
x
w
,
θ
2
w
)
=
σ
(
x
w
T
θ
2
w
)
p(d_3^w|\mathbf x_w,\theta_2^w) = \sigma(\mathbf x_w^T\theta_2^w)
p(d3w∣xw,θ2w)=σ(xwTθ2w)
第三次:
p
(
d
4
w
∣
x
w
,
θ
3
w
)
=
σ
(
x
w
T
θ
3
w
)
p(d_4^w|\mathbf x_w,\theta_3^w) = \sigma(\mathbf x_w^T\theta_3^w)
p(d4w∣xw,θ3w)=σ(xwTθ3w)
第四次:
p
(
d
5
w
∣
x
w
,
θ
4
w
)
=
1
−
σ
(
x
w
T
θ
4
w
)
p(d_5^w|\mathbf x_w,\theta_4^w) = 1- \sigma(\mathbf x_w^T\theta_4^w)
p(d5w∣xw,θ4w)=1−σ(xwTθ4w)
这四个概率的乘积就是
p
(
足球
∣
c
o
n
t
e
x
t
(
足球
)
)
p(足球|context(足球))
p(足球∣context(足球)),即:
p
(
足球
∣
c
o
n
t
e
x
t
(
足球
)
)
=
∏
j
=
2
5
p
(
d
j
w
∣
x
w
,
θ
j
−
1
w
)
p(足球|context(足球)) = \prod_{j=2}^5 p(d_j^w|\mathbf x_w,\theta_{j-1}^w)
p(足球∣context(足球))=j=2∏5p(djw∣xw,θj−1w)
总结:对于词典D中的任意词w, 霍夫曼树中必存在一条从根结点到词w对应结点的路径 p w p^w pw(且这条路径是唯一的)。路径 p w p^w pw上存在 l w − 1 l l^w -1l lw−1l个分支,将每个分支看做一次二分类,每一次分类就产生一个概率, 将这些概率乘起来,就是所需的 p ( w ∣ C o n t e x t ( w ) ) p(w|Context(w)) p(w∣Context(w))。
所以条件概率的定义如下:
p
(
w
∣
c
o
n
t
e
x
t
(
w
)
)
=
∏
j
=
2
l
w
p
(
d
j
w
∣
x
w
,
θ
j
−
1
w
)
p(w|context(w)) = \prod_{j=2}^{l^w} p(d_j^w|\mathbf x_w,\theta_{j-1}^w)
p(w∣context(w))=j=2∏lwp(djw∣xw,θj−1w)
其中:
p
(
d
j
w
∣
x
w
,
θ
j
−
1
w
)
=
{
σ
(
x
w
T
θ
j
−
1
w
)
d
j
w
=
0
1
−
σ
(
x
w
T
θ
j
−
1
w
)
d
j
w
=
1
p(\mathrm{d}_j^w|\mathrm{x}_w, \theta_{j-1}^w)=
于是整体表达式如下:
p
(
d
j
w
∣
x
w
,
θ
j
−
1
w
)
=
[
σ
(
x
w
T
θ
j
−
1
w
)
]
1
−
d
j
w
⋅
[
1
−
σ
(
x
w
T
θ
j
−
1
w
)
]
d
j
w
p(d_j^w|\mathbf x_w,\theta_{j-1}^w) = [\sigma(\mathbf x_w^T\theta_{j-1}^w)]^{1-d_j^w}\cdot[1-\sigma(\mathbf x_w^T\theta_{j-1}^w)]^{d_j^w}
p(djw∣xw,θj−1w)=[σ(xwTθj−1w)]1−djw⋅[1−σ(xwTθj−1w)]djw
所以我们的优化目标是:
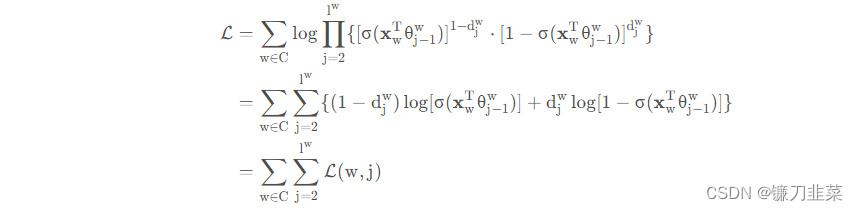
其中:
L
(
w
,
j
)
=
(
1
−
d
j
w
)
log
[
σ
(
x
w
T
θ
j
−
1
w
)
]
+
d
j
w
log
[
1
−
σ
(
x
w
T
θ
j
−
1
w
)
]
L(w,j) = ({1-d_j^w})\log[\sigma(\mathbf x_w^T\theta_{j-1}^w)]+d_j^w\log[1-\sigma(\mathbf x_w^T\theta_{j-1}^w)]
L(w,j)=(1−djw)log[σ(xwTθj−1w)]+djwlog[1−σ(xwTθj−1w)]
这就是CBOW的目标函数。
梯度计算
采用随机梯度上升法将这个函数最大化。
注意:随机梯度上升法:随机取一个样本
(
c
o
n
t
e
x
t
(
w
)
,
w
)
(context(w),w)
(context(w),w),对目标函数中的所有的参数行一次更新。
(1)更新
θ
j
−
1
w
\theta_{j-1}^w
θj−1w
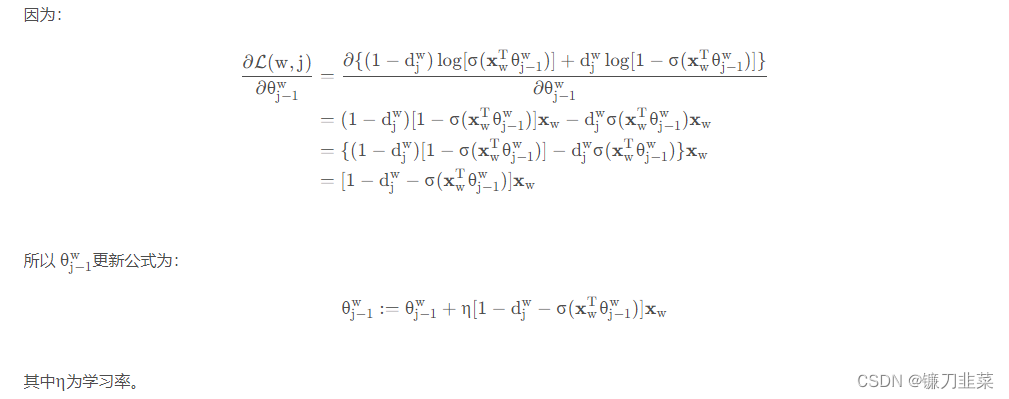
(2)更新
x
w
\mathrm{x}_w
xw
因为
L
(
w
,
j
)
\mathcal L(w,j)
L(w,j)关于变量
x
w
\mathbf x_w
xw和
θ
j
−
1
w
\theta_{j-1}^w
θj−1w是对称的。所以:
∂
L
(
w
,
j
)
∂
x
w
=
[
1
−
d
j
w
−
σ
(
x
w
T
θ
j
−
1
w
)
]
θ
j
−
1
w
\frac{\partial \mathcal{L}(w,j)}{\partial \mathrm{x}_w}=[1-d_j^w-\sigma (\mathrm{x}_w^T\theta_{j-1}^w)]\theta_{j-1}^w
∂xw∂L(w,j)=[1−djw−σ(xwTθj−1w)]θj−1w
这里存在一个问题:我们的最终目的是要求词典D中每个词的词向量,而这里的
x
w
\mathbf x_w
xw表示的是
c
o
n
t
e
x
t
(
w
)
context(w)
context(w)各词词向量的累加。那么,如何利用
∂
L
(
w
,
j
)
∂
x
w
\frac{\partial \mathcal L(w,j)}{\partial \mathbf x_w}
∂xw∂L(w,j)来对
v
(
w
)
,
w
∈
D
\mathbf v(w),w \in D
v(w),w∈D进行更新呢? word2vec中的做法很简单,直接取
v
(
w
)
:
=
v
(
w
)
+
η
∑
j
=
2
l
w
∂
L
(
w
,
j
)
∂
x
w
,
w
∈
c
o
n
t
e
x
t
(
w
)
\mathbf v(w) := \mathbf v(w) + \eta \sum_{j=2}^{l^w} \frac{\partial \mathcal L(w,j)}{\partial \mathbf x_w},\quad w \in context(w)
v(w):=v(w)+ηj=2∑lw∂xw∂L(w,j),w∈context(w)
注:既然 x w \mathbf x_w xw本身就是 c o n t e x t ( w ) context(w) context(w)中各个词向量的累加,求完梯度后也应该将其贡献到每个分量上。
下面是CBOW模型中采用的随机梯度上升法伪代码:
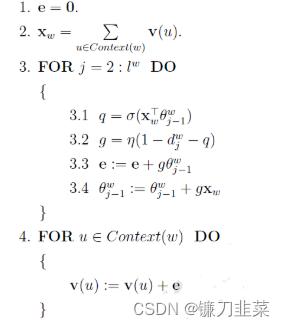
Skip-gram 模型
基本结构
Skip-gram 模型的结构也是三层,下面以样本
(
w
,
c
o
n
t
e
x
t
(
w
)
)
(w,context(w))
(w,context(w))为例说明。如下图所示
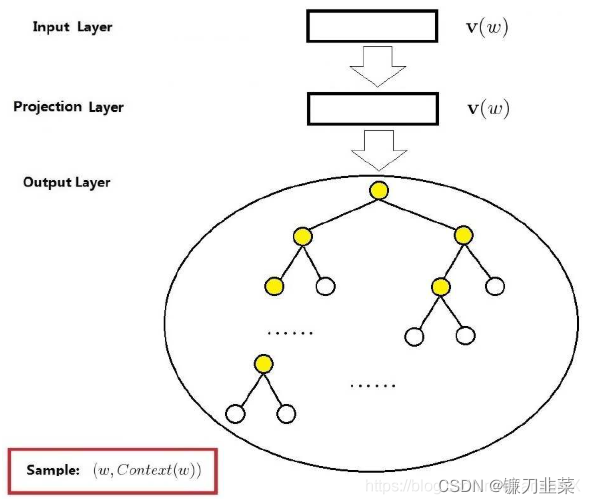
它也包括三层:输入层、投影层、输出层。
- 输入层:只包含当前样本中心词 w w w词向量 v ( w ) ∈ R m \mathbf v(w) \in \mathbf R^m v(w)∈Rm,每个词向量的长度是 m m m。
- 投影层:恒等投影,即和输入层一样,保留是为了与CBOW对比。
- 输出层:与CBOW类似
对于Skip-gram模型,已知的是当前词
w
w
w,需要对其上下文
c
o
n
t
e
x
t
(
w
)
context(w)
context(w)中的词进行预测,所以:
p
(
c
o
n
t
e
x
t
(
w
)
∣
w
)
=
∏
u
∈
c
o
n
t
e
x
t
(
w
)
p
(
u
∣
w
)
p(context(w)|w) = \prod_{u \in context(w)} p(u|w)
p(context(w)∣w)=u∈context(w)∏p(u∣w)
类似于CBOW,所以:
p
(
u
∣
w
)
=
∏
j
=
2
l
u
p
(
d
j
u
∣
v
(
w
)
,
θ
j
−
1
u
)
p(u|w) = \prod_{j=2}^{l^u}p(d_j^u|\mathbf v(w),\theta_{j-1}^u)
p(u∣w)=j=2∏lup(dju∣v(w),θj−1u)
其中:
p
(
d
j
u
∣
v
(
w
)
,
θ
j
−
1
u
)
=
[
σ
(
v
(
w
)
T
θ
j
−
1
u
)
]
1
−
d
j
u
⋅
[
1
−
σ
(
v
(
w
)
T
θ
j
−
1
u
)
]
d
j
u
p(d_j^u|\mathbf v(w),\theta_{j-1}^u) = [\sigma(\mathbf v(w)^T\theta_{j-1}^u)]^{1-d_j^u}\cdot[1-\sigma(\mathbf v(w)^T\theta_{j-1}^u)]^{d_j^u}
p(dju∣v(w),θj−1u)=[σ(v(w)Tθj−1u)]1−dju⋅[1−σ(v(w)Tθj−1u)]dju
所以我们的优化目标是:
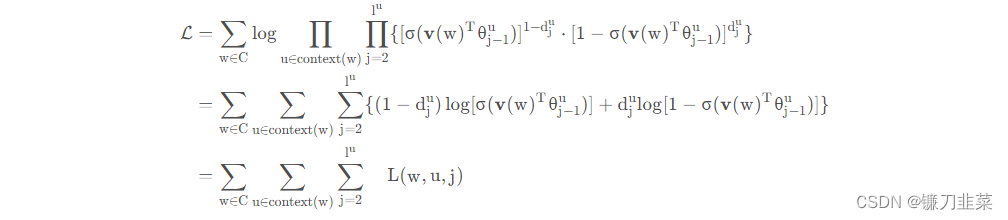
采用随机梯度上升法将这个函数最大化。
梯度计算
(1)更新
θ
j
−
1
w
\theta_{j-1}^w
θj−1w
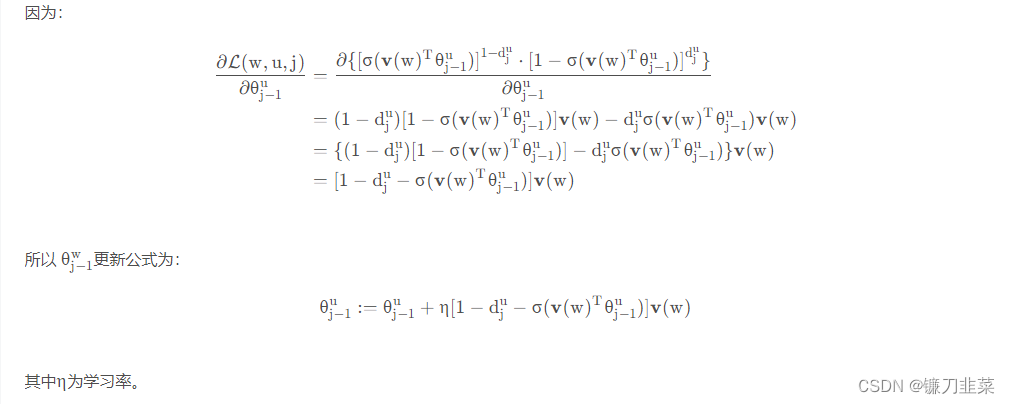
(2)更新
v
(
w
)
\mathrm{v}(w)
v(w)
因为
L
(
w
,
u
,
j
)
\mathcal L(w,u,j)
L(w,u,j)关于变量
v
(
w
)
\mathbf v(w)
v(w)和
θ
j
−
1
w
\theta_{j-1}^w
θj−1w是对称的。所以:
∂
L
(
w
,
u
,
j
)
∂
v
(
w
)
=
[
1
−
d
j
u
−
σ
(
v
(
w
)
T
θ
j
−
1
u
)
]
θ
j
−
1
u
\frac{\partial \mathcal{L}(w,u,j)}{\partial \mathrm{v}(w)}=[1-d_j^u-\sigma (\mathrm{v}(w)^T\theta_{j-1}^u)]\theta_{j-1}^u
∂v(w)∂L(w,u,j)=[1−dju−σ(v(w)Tθj−1u)]θj−1u
所以,
v
(
w
)
\mathbf v(w)
v(w)更新公式为:
v
(
w
)
:
=
v
(
w
)
+
η
∑
u
∈
c
o
n
t
e
x
t
(
w
)
∑
j
=
2
l
w
∂
L
(
w
,
u
,
j
)
∂
v
(
w
)
,
w
∈
c
o
n
t
e
x
t
(
w
)
\mathbf v(w) := \mathbf v(w) + \eta \sum_{u \in context(w)} \sum_{j=2}^{l^w} \frac{\partial \mathcal L(w,u,j)}{\partial \mathbf v(w)},\quad w \in context(w)
v(w):=v(w)+ηu∈context(w)∑j=2∑lw∂v(w)∂L(w,u,j),w∈context(w)
具体伪代码如下:
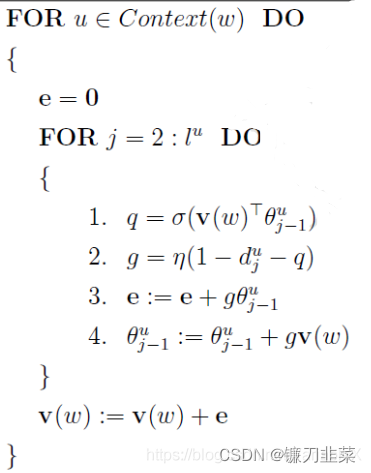
与 CBOW 相比,最大的区别是多个了外层循环。
小结
使用霍夫曼树来代替传统的神经网络,避免了从隐藏层到输出的softmax层这里的计算,也避免计算所有词的softmax概率。但是如果我们的训练样本里的中心词w是一个很生僻的词,那么就得在霍夫曼树中辛苦的向下走很久了。解决这个问题则是采用基于Negative Sampling的模型。
基于Negative Sampling 的 CBOW 模型和 Skip-gram 模型
Negative Sampling是这么一种求解word2vec模型的方法,它摒弃了霍夫曼树,采用了Negative Sampling(负采样)的方法来求解。
负采样算法
在CBOW模型中,已知词w的上下文 c o n t e x t ( w ) context(w) context(w)需要预测w。因此,对于给定的 c o n t e x t ( w ) context(w) context(w),词w就是一个正样本,其它词就是负样本了。在Skip-gram中同样也存在正负样本问题。负样本那么多,该如何选取呢?这就是Negative Sampling(负采样,简称NEG)问题。也就是对于给定的词,如何生成其负样本子集 N E G ( w ) NEG(w) NEG(w)?
采用的基本要求是:词典D中的词在语料C中出现的次数有高有低,对于那些高频词,被选为负样本的概率就应该比较大,反之,对于那些低频词,其被选中的概率就应该比较小。本质上就是一个带权采样问题。
先用一段通俗的描述来帮助理解带权采样的机理:

word2vec中的具体做法。记
l
0
=
0
,
l
k
=
∑
j
=
1
k
l
e
n
(
w
j
)
,
k
=
1
,
2
,
.
.
.
,
N
l_0=0,l_k=\sum_{j=1}^k len(w_j), k=1,2,...,N
l0=0,lk=∑j=1klen(wj),k=1,2,...,N,这里
w
j
w_j
wj表示词典
D
D
D中的第
j
j
j个词,则以
{
l
j
}
j
=
0
N
\{l_j\}_{j=0}^N
{lj}j=0N为剖分节点可以得到区间[0,1]上的一个非等距剖分,
I
i
=
(
l
i
−
1
,
l
i
]
,
i
=
1
,
2
,
.
.
.
,
N
I_i=(l_{i-1},l_i], i=1,2,...,N
Ii=(li−1,li],i=1,2,...,N为其N个剖分区间。进一步引入区间[0,1]上的等距剖分,剖分节点为
{
m
j
}
j
=
0
M
\{m_j\}_{j=0}^M
{mj}j=0M,其中
M
>
>
N
M>>N
M>>N,具体如下图所示:
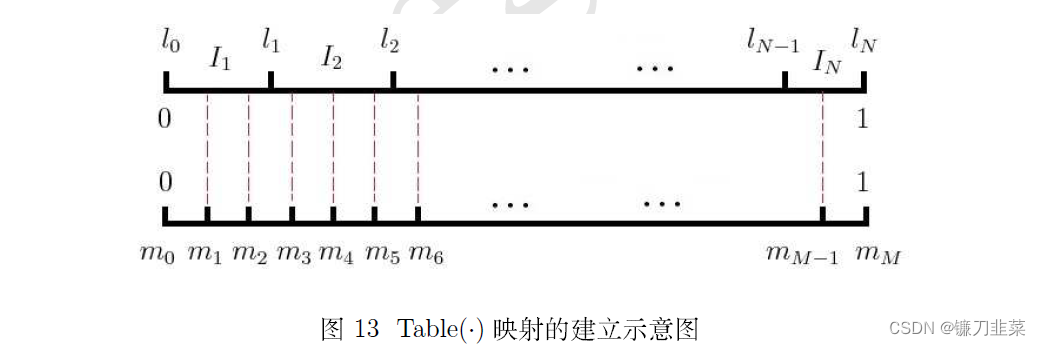
将内部剖分节点
{
m
j
}
j
=
1
M
−
1
\{m_j\}_{j=1}^{M-1}
{mj}j=1M−1投影到非等距剖分上,如上图中红色虚线所示,则可建立
{
m
i
}
j
=
1
M
−
1
\{m_i\}_{j=1}^{M-1}
{mi}j=1M−1与区间
{
I
j
}
j
=
1
N
\{I_j\}_{j=1}^N
{Ij}j=1N(或者说
{
w
j
}
j
=
1
N
\{w_j\}_{j=1}^N
{wj}j=1N)的映射关系
T
a
b
l
e
(
i
)
=
w
k
,
where
m
i
∈
I
k
,
i
=
1
,
2
,
.
.
.
,
M
−
1
Table(i)=w_k, \text{ where } m_i\in I_k, i=1,2,...,M-1
Table(i)=wk, where mi∈Ik,i=1,2,...,M−1
有了这个映射,采样就简单了:每次生成一个
[
1
,
M
−
1
]
[1,M-1]
[1,M−1]间的随机整数
r
r
r,Table®就是一个样本。当然,还有一个细节,当对
w
i
w_i
wi进行负采样时,如果碰巧选到了
w
i
w_i
wi自己怎么办?那就跳过。
注意,word2vec源码中为词典
D
D
D中的词设置权值时,不是直接用counter(w),而是对其作了
α
\alpha
α次幂,其中
α
=
3
4
\alpha = \frac{3}{4}
α=43,即上述公式变为
l
e
n
(
w
)
=
[
c
o
u
n
t
e
r
(
w
)
]
3
4
∑
u
∈
D
[
c
o
u
n
t
e
r
(
u
)
]
3
4
len(w)=\frac{[counter(w)]^{\frac{3}{4}}}{\sum_{u\in D}[counter(u)]^{\frac{3}{4}}}
len(w)=∑u∈D[counter(u)]43[counter(w)]43
此外,代码中取
M
=
1
0
8
M=10^8
M=108,而映射则是通过一个名为InitUnigramTable函数完成的。
CBOW模型
假定现在已经选好了一个关于w的负采样子集
N
E
G
(
w
)
≠
⊘
NEG(w)\ne \oslash
NEG(w)=⊘。且对
∀
w
~
∈
D
\forall \tilde{w}\in D
∀w~∈D,定义
L
w
(
w
~
)
{
1
w
~
=
w
0
w
~
≠
w
L^w(\tilde w)
表示词
w
~
\tilde{w}
w~的标签,即正样本的标签为1,负样本的标签为0.
对于一个给定的正样本
(
c
o
n
t
e
x
t
(
w
)
,
w
)
(context(w),w)
(context(w),w),希望最大化:
g
(
w
)
=
∏
u
∈
w
∪
N
E
G
(
w
)
P
(
u
∣
c
o
n
t
e
x
t
(
w
)
)
g(w) = \prod_{u \in {w} \cup NEG(w) }P(u|context(w))
g(w)=u∈w∪NEG(w)∏P(u∣context(w))
其中:
p
(
u
∣
c
o
n
t
e
x
t
(
w
)
)
=
{
σ
(
x
w
T
θ
u
)
L
w
(
x
)
=
1
1
−
σ
(
x
w
T
θ
u
)
L
w
(
x
)
=
0
p(u|context(w))=
写成整体表达式:
P
(
u
∣
c
o
n
t
e
x
t
(
w
)
)
=
[
σ
(
x
w
T
θ
u
)
]
L
w
(
u
)
⋅
[
1
−
σ
(
x
w
T
θ
u
)
]
1
−
L
w
(
u
)
P(u|context(w)) = [\sigma(\mathbf x_w^T\theta^u)]^{L^w( u )} \cdot [1-\sigma(\mathbf x_w^T\theta^u)]^{1- L^w( u )}
P(u∣context(w))=[σ(xwTθu)]Lw(u)⋅[1−σ(xwTθu)]1−Lw(u)
这里的
x
w
\mathbf x_w
xw是各词向量之和。
θ
u
\theta^u
θu表示词对应的一个(辅助)向量,是个待训练参数。
所以,最终
g
(
w
)
g(w)
g(w)的表达式如下:
g
(
w
)
=
σ
(
x
w
T
θ
w
)
∏
u
∈
N
E
G
(
w
)
[
1
−
σ
(
x
w
T
θ
u
)
]
g(w) = \sigma(\mathbf x_w^T\theta^w) \prod_{u \in NEG(w) } [1-\sigma(\mathbf x_w^T\theta^u) ]
g(w)=σ(xwTθw)u∈NEG(w)∏[1−σ(xwTθu)]
其中
σ
(
x
w
T
θ
w
)
\sigma(\mathbf x_w^T\theta^w)
σ(xwTθw)表示当上下文为
c
o
n
t
e
c
x
t
(
w
)
contecxt(w)
contecxt(w)时,预测中心词为w的概率;而
σ
(
x
w
T
θ
u
)
\sigma(\mathbf x_w^T\theta^u)
σ(xwTθu),预测中心词为
u
u
u的概率。
从形式上看,最大化
g
(
w
)
g(w)
g(w), 相当于:增大正样本的概率同时降低负样本的概率。所以,给定预料库C,函数:
G
=
∏
w
∈
C
g
(
w
)
G= \prod_{w \in C} g(w)
G=w∈C∏g(w)
可以作为整体的优化目标。为了计算方便可以对G取对数。
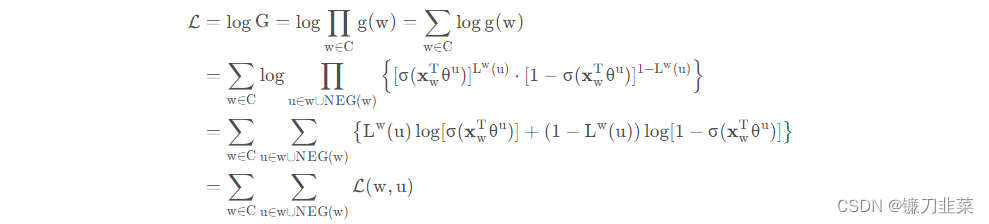
接下来利用随机梯度上升对参数进行优化。关键是要给出
L
\mathcal{L}
L的两类梯度。
(1)更新
θ
u
\theta^u
θu:
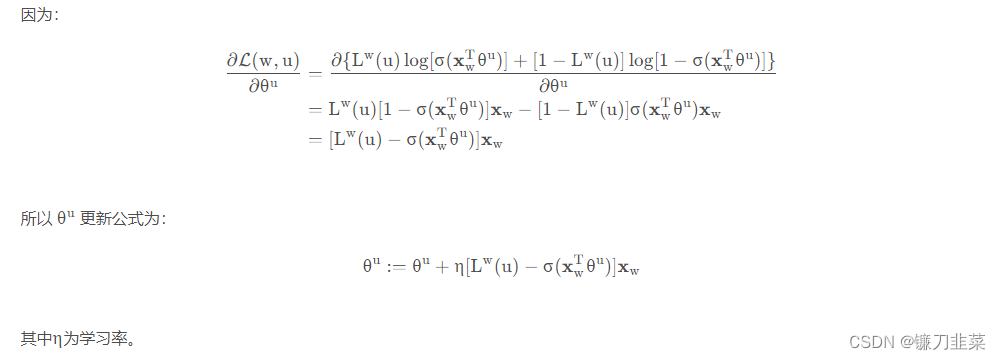
(2)更新
x
w
\mathrm{x}_w
xw
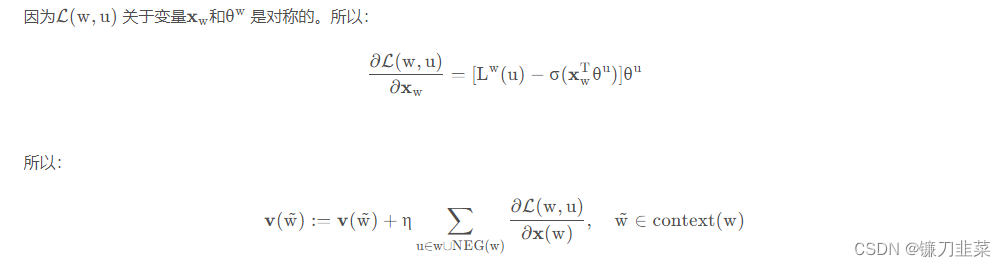
下面以样本
(
c
o
n
t
e
x
t
(
w
)
,
w
)
(context(w),w)
(context(w),w)为例,给出基于Negative Sampling的CBOW模型中采用随机梯度上升法更新各参数的伪代码:

Skip-gram模型
Skip-gram模型与CBOW模型的负采样模型推到过程相似。
对Skip-gram模型而言,正常来说,应该是要使用词
w
w
w来预测上下文中的词汇
c
o
n
t
e
x
t
(
w
)
context(w)
context(w),但是在word2vec 的源码中,本质上还是用了CBOW的思想,将上下文
c
o
n
t
e
x
t
(
w
)
context(w)
context(w)拆成一个个词来考虑,也就是说期望最大化的式子为:
g
(
w
)
=
∏
w
~
∈
C
o
n
t
e
x
(
w
)
∏
u
∈
{
w
}
∪
N
E
G
w
~
(
w
)
P
(
u
∣
w
~
)
g(w) = \prod_{\tilde w \in Contex(w)}\;\prod_{u \in \{w\} \cup NEG^{\;\tilde w}(w) }P(u| \tilde w)
g(w)=w~∈Contex(w)∏u∈{w}∪NEGw~(w)∏P(u∣w~)
其中,
N
E
G
w
~
(
w
)
NEG^{\;\tilde w}(w)
NEGw~(w)表示对上下文中词
w
~
\tilde w
w~的采样。基于上面的目标,用上文类似的推导过程,可以得到下面的算法。
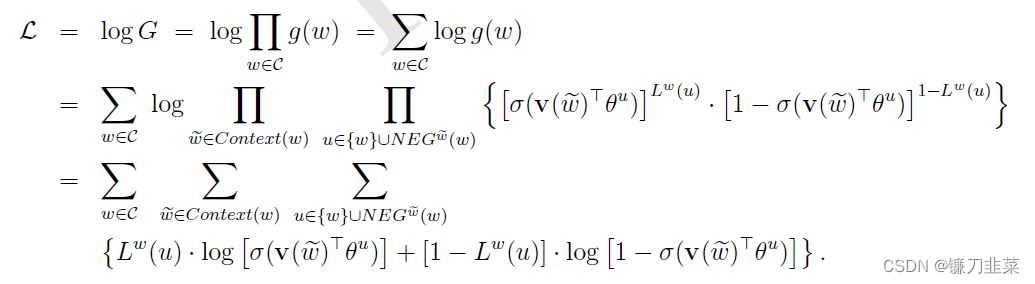
下面简单的给出随机梯度上升更新参数的伪代码:

参考资料
[1] word2vec 中的数学原理详解
[2] word2vec模型
[3] 基于Hierarchical Softmax的 CBOW 模型和 Skip-gram 模型

