
- 1已解决EROR 1064 (42000): You have an error in. your SOL syntax. check the manual that corresponds to yo_you have an error in your sol syntax; check the ma
- 2Hadoop学习日记-HDFS分布式文件存储系统整体概述_namenode和datanode分布式存储
- 3阿里云Big Data - |分层| ODS& DWD& DWS& ADS| 行为数仓_dws表 data
- 4一文读懂非关系型数据库(NoSQL)
- 5百度安全多篇议题入选Blackhat Asia以硬技术发现“芯”问题
- 6Locust性能测试教程_locust 性能测试
- 7Linux 常用命令与教程_/sbin:/usr/sbin:/usr/local/sbin:/root/bin:/usr/loc
- 8论文阅读:(AAAI 2019)M2det: A single-shot object detector based on multi-level feature pyramid network_a detector based on dl
- 9LCD1602命令代码整合
- 10基于JAVA高考志愿辅助填报系统
Redis(一) redis配置 | 如何连接redis服务器 | 基本数据类型 | 基本全局命令 | 数据结构和内部编码方式_redis 连接服务器
赞
踩

前言
本篇文章将介绍我们在 Linux 环境下安装了 Redis 之后的一些 redis 配置、如何启动 redis、redis 有哪些基本数据类型以及一些基础的全局命令。
Redis 配置文件
当我们在 Linux 环境下安装完成 redis 之后,需要修改 redis 的配置文件对齐进行配置,redis 的配置文章一般位于 /etc/redis/redis.conf 路径下,进入 redis 的配置文件之后我们找到 bind 配置,然后将 127.0.0.1 更改为 0.0.0.0:
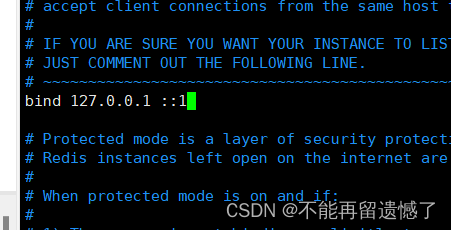
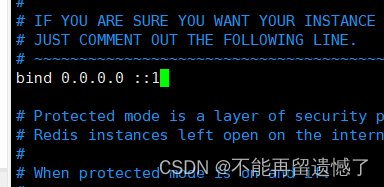
做这个更改是因为 127.0.0.1 表示只有我们本机才可以访问 redis,而修改为 0.0.0.0 我们其他的计算机则可以通过网络来访问该 redis。
第二个 protected-mode 大家可以根据情况更改,这个表示进入 redis 的时候是否需要密码,我们这里自己使用就将其更改为 no:
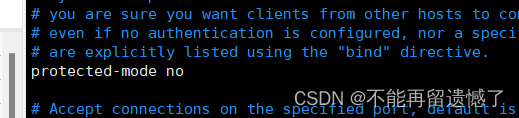
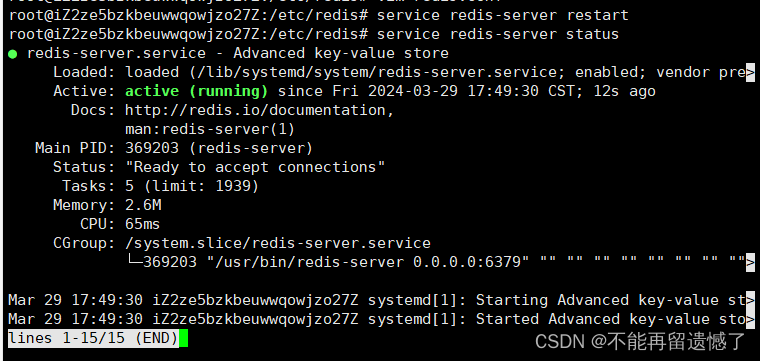
当修改完成之后,如果 redis 服务已经开启,我们需要使用 service redis-servcer restart 来重启 redis 服务。启动之后,我们可以使用 service redis-server status 来查看 redis 服务状态:
连接 redis 服务器
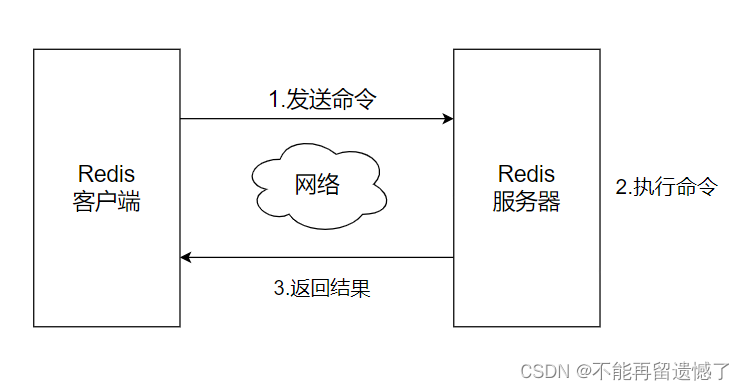
redis 是客户端-服务器 类型的系统
当配置完 redis 之后,我们就可以连接 redis 的服务器了,这里我们先通过 redis 自带的客户端来连接服务器 redis-cli -h {host} -p {port} -h 选项指定客 reids 服务器的 IP 地址,-p 选项则指定 redis 服务器的端口号,如果我们不想指定的话就可以直接使用 redis-cli 来使用默认的 IP 地址和端口号来连接 redis 服务器。

ping 命令用于检查 Redis 服务器是否正在运行并可以响应请求
Redis 客户端与服务器端交互的过程:
Redis 常见数据类型
redis 存储数据是以键值对的形式存储的,也就是数据的整体是 key-value 模型,key 都是 string 类型,但是 value 却存在多种数据类型。
redis 的 value 的常见数据类型有五种:
- 字符串(String)
- 字符串是 Redis 最基础的数据类型,可以存储任何形式的字符串,包括二进制数据。
- 字符串类型支持的操作包括 SET(设置值)、GET(获取值)、INCR(自增)、DECR(自减)、APPEND(追加)等。
- 字符串常常用于缓存经常访问的字符串数据,比如用户信息、配置信息等。
- 哈希(Hash)
- 哈希类型允许存储键值对集合,类似于字典或对象。
- 哈希的每个字段(field)都关联一个值(value),字段和值都是字符串类型。
- 哈希类型支持的操作包括 HSET(设置字段值)、HGET(获取字段值)、HGETALL(获取所有字段和值)等。
- 哈希类型常用于存储结构化数据,比如用户信息、商品详情等。
- 列表(List)
- 列表是简单的字符串列表,按照插入顺序排序。
- 列表类型支持的操作包括 LPUSH(在列表左侧插入元素)、RPUSH(在列表右侧插入元素)、LPOP(移除并获取列表左侧元素)、RPOP(移除并获取列表右侧元素)等。
- 列表类型常用于实现消息队列、任务队列等场景。
- 集合(Set)
- 集合是字符串的无序集合,集合中的元素是唯一的,不重复。
- 集合类型支持的操作包括 SADD(添加元素)、SMEMBERS(获取所有元素)、SISMEMBER(判断元素是否存在于集合中)等。
- 集合类型常用于实现交集、并集、差集等操作,比如共同好友、推荐系统等场景。
- 有序集合(Sorted Set)
- 有序集合与集合类似,但每个元素都会关联一个分数(score),Redis 根据分数对集合中的元素进行从小到大的排序。
- 有序集合类型支持的操作包括 ZADD(添加元素及其分数)、ZRANGE(根据分数范围获取元素)、ZRANK(获取元素的排名)等。
- 有序集合常用于实现排行榜、带权重的任务队列等场景。
Redis 基本全局命令
redis 的命令非常多,靠我们记是很难将全部的命令都给记住的,这里我们可以去 redis 的官网去查找需要的命令:redis官网
这里为大家介绍几个基本的全局命令。
Redis的全局命令是指那些对整个Redis服务器进行操作或获取服务器状态的命令,而不是针对某个特定数据类型的命令。简单来说就是可以搭配任意一个数据类型来使用的命令。
set 和 get 命令
首先是最基本的两个命令 set key value 来设置 value 为字符串类型的 key-value,然后就是 get key 来获取指定 key 的 value。
127.0.0.1:6379> set key1 123445
OK
- 1
- 2
当我们使用 set 设置 string 类型的 value 的时候,value 可以不同加单引号或者双引号,redis 可以自动将其识别为字符串,如果要加也是可以的:
127.0.0.1:6379> set key2 '0987'
OK
- 1
- 2
当存储了一些键值对之后,我们使用 get 命令来获取指定 key 的 value 值:
127.0.0.1:6379> get key1
"123445"
127.0.0.1:6379> get key2
"0987"
- 1
- 2
- 3
- 4
KEYS 命令
在 redis 中使用 keys (带有匹配规则的)字符串 来查看当前 redis 中存储的有哪些 key,这个匹配规则包括:
- h?llo 匹配 hallo,hbllo和hello,但是不匹配habllo
- h*llo 匹配 hllo,hello,haallo,hbbllo
- h[ae]llo 匹配 hallo 和 hello,但是不匹配hbllo
- h[^e]llo 匹配 hallo,hbllo…但是不匹配 hello
- h[a-c]llo 匹配 hallo,hbllo,hcllo,但是不匹配 hdllo、hello
?值匹配任意一个字符,*匹配0个或者多个任意字符,[ae]表示匹配a或者e,[^e]表示匹配除了 e 之外的所有字符,[a-c]表示匹配a-c之间的所有字符,该范围之外的其他字符不匹配。
127.0.0.1:6379> keys *
1) "sex1"
2) "name2"
3) "name1"
4) "key2"
5) "key1"
6) "sex2"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
keys * 表示查看当前 redis 中存储的所有 key,我们处于学习阶段可以使用这些,而如果以后我们在公司或者其他地方的时候,尽量避免使用 keys * ,因为 Redis 在 4.x 版本引入了类多线程,6.x 版本才正式支持多线程,也就是说在 redis 6.x 版本之前都是单线程工作的,使用 keys * 会对所有的 key 进行扫描,如果当前 redis 中存在很多 key 的话,那么使用 keys * 就会花费很多的时间,当后续 redis 服务器接收到了其他请求命令的时候,就无法及时处理这些命令,我们应避免这样的情况发生。
127.0.0.1:6379> keys key*
1) "key2"
2) "key1"
127.0.0.1:6379> keys name?
1) "name2"
2) "name1"
- 1
- 2
- 3
- 4
- 5
- 6
127.0.0.1:6379> keys key[^2]
1) "key1"
- 1
- 2
127.0.0.1:6379> keys name[13]
1) "name1"
- 1
- 2
127.0.0.1:6379> keys name[1-3]
1) "name2"
2) "name1"
- 1
- 2
- 3
EXISTS 命令
exists 命令用来判断某个 key 是否存在,EXISTS key [key...]。
127.0.0.1:6379> exists key1
(integer) 1
127.0.0.1:6379> exists key2
(integer) 1
127.0.0.1:6379> exists key3
(integer) 0
- 1
- 2
- 3
- 4
- 5
- 6
EXISTS 命令也可同时判断多个 key 是否存在:
127.0.0.1:6379> exists key1 key2
(integer) 2
- 1
- 2
exists 的返回值是要查找的 key 中有多少个 key 存在:
127.0.0.1:6379> exists key1 key2 key3
(integer) 2
- 1
- 2
这种分多次查询 key 和一次查询多个 key 的做法有区别吗?很多人可能会想,不管你一次还是多次查询 key 是否存在最终的结果不都是相同的,都能达到目的吗?虽然最终的结果相同,但是分一次查询多个 key 和多次查询多个 key 的区别还是很大的。为什么呢?因为前面我们说过 redis 是客户端服务器类型的系统,而客户端和服务器之间进行交互通常依赖的是网络,而网络传输的速度和可靠性都是一言难尽的,你分多次进行查询,那么每多一次查询就需要多两次分装、分用和网络传输(请求和响应),那么这时交互的速度和安全性就大大降低了,所以可以一次查询的情况建议一次查询。
DEL 命令
del 命令用于删除指定的 key。既然是删除那么很多有就会有顾虑了,之前的 MySQL 等数据库都是不建议进行删除操作的,搞不好自己的年终奖都没有了,情节严重的可能还会喜提一副银手镯,那么我们这里的 redis 的删除是否也需要我们额外小心呢?小心行得万年船嘛,小心一点还是好一些,虽这样说,但是 redis 通常是被用来当作缓存的,而缓存往往是从数据库中得来的,删除少部分的 redis 缓存并没有什么大碍的,但是也不代表着我们可以肆无忌惮的删除,如果我们删除了大量 redis 数据,那么每次访问数据的话,这个请求最终还是会到达我们的 MySQL 等数据库,没有了 redis 的负重前行,查询速度就会大大降低,甚至很大可能会将我们的 MySQL 服务器搞挂掉,所以我们使用 DEL 命令的时候还是需要小心一点的。
DEL 的用法是 del key [key...]
127.0.0.1:6379> del key1
(integer) 1
127.0.0.1:6379> get key1
(nil)
127.0.0.1:6379> exists key1
(integer) 0
- 1
- 2
- 3
- 4
- 5
- 6
这里的 nil 是什么呢?其实他和我们前面的编程语言中表示空的 NULL 意思基本上是一样的,只是 NULL 和 nil 的使用场景不同。
同样 del 命令也支持一次删除多个key:
127.0.0.1:6379> del name1 name2
(integer) 2
127.0.0.1:6379> exists name1 name2
(integer) 0
- 1
- 2
- 3
- 4
EXPIRE 和 TTL 命令
expire 用来为指定的存在的 key 设置过期时间,当 key 存在的时间超过这个指定的值之后就会被删除了。这种有过期时间的现象在我们的生活中经常用到,例如我们每次收到的验证码只有五分钟有效期等等。
expire 命令的用法:expire key seconds
127.0.0.1:6379> expire key1 8
(integer) 1
127.0.0.1:6379> get key1 //在八秒之内获取
"nihao"
127.0.0.1:6379> get key1 //过了八秒之后再获取,为nil
(nil)
- 1
- 2
- 3
- 4
- 5
- 6
当为某个 key 设置了过期时间之后,我们可以使用 TTL(Time To Life) 命令来查看 key 还剩多少时间过期 ttl key
127.0.0.1:6379> expire key1 8 (integer) 1 127.0.0.1:6379> get key1 "nihao" 127.0.0.1:6379> get key1 (nil) 127.0.0.1:6379> set key1 nihao OK 127.0.0.1:6379> expire key1 8 (integer) 1 127.0.0.1:6379> ttl key1 (integer) 5 127.0.0.1:6379> ttl key1 (integer) 3 127.0.0.1:6379> ttl key1 (integer) 2 127.0.0.1:6379> ttl key1 (integer) 1 127.0.0.1:6379> ttl key1 (integer) -2 127.0.0.1:6379>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
当指定查询的 key 不存在时,使用 TTL 就会返回 -2.
使用 EXPIRE 设置过期时间的单位是秒(s),对于我们人来说 1s 可能也做不了什么,但是对于计算机来说可以做很多事,那么这里就会有人问了:以秒(s)为单位是不是太久了,要是觉得久,我们可以使用 redis 为我们提供的另一种设置过期时间的方法 pexpire key x(ms) pexpire 设置的过期时间的单位是毫秒(ms)。与 pexpire 对应的查看过期时间的命令是 pttl key
127.0.0.1:6379> pexpire key1 20
(integer) 1
127.0.0.1:6379> pttl key1
(integer) -2
- 1
- 2
- 3
- 4
到这里可能有人会想了:redis 是如何实现 key 的过期的呢?那么这也就是 redis 的一个经典面试题:redis 中 key 的过期策略是如何实现的?
在 redis 服务器中存在很多的 key,其中很大一部分的 key 都存在过期时间,那么 redis 是如何知道哪些 key 过期了,哪些 key 还没有过期呢?
通过遍历一遍全部的 key 来判断哪些 key 过期了是行不通的,因为这样操作的时间复杂度是 O(N),如果 key 非常多的话,就需要花费大量的时间,这个跟 keys * 需要的时间是差不多的。
Redis 过期策略
redis 整体的过期策略是:
- 定期删除
- 惰性删除
定期删除是指 redis 每隔一段时间都会对过期的 key 进行删除,那么 redis 是如何知道哪些 key 过期了呢?其实还是遍历 key,只不过 redis 每次遍历 key 不是遍历所有的 key,而是每次定期删除都会抽取部分的 key 对齐进行遍历,如果遍历到的 key 过期了,那么就直接删除。
惰性删除是指假设一个 key 达到了过期时间,但是我不是立即删除他,而是在后面的查询和使用过程中,如果使用到了这个过期的 key,那么 redis 首先会通过计算出来的哈希值,对应数组下标找到该 key,然后 redis 会查看该 key 是否过期,如果过期那就就会将这个 key 进行删除,并且返回值告诉用户该 key 不存在。
定时器和时间轮的方式实现过期key的及时删除
redis 就是通过上面这两种策略相结合实现对过期 key 的删除的,但是仅凭这两个策略是无法及时删除所有的过期的 key 的,仍会有部分的 key 无法得到及时的删除,那么是否有更好的方法来对过期的 key 进行及时的删除呢?
答案是有的,现在有的好的办法有两个:定时器和时间轮的做法。
定时器,就是通过一个优先级队列来实现的,每个含有过期时间的 key 作为优先级队列的节点,与此同时,在为某个 key 设置过期时间的时候,这个过期时间还会被作为权重,这个优先级队列可以是小根堆,过期时间最短的 key 会被放在根节点上。定时器的线程会先扫描根节点的 key 的过期时间,如果到了过期时间就将头结点和末节点进行交换,然后进行向下调整,实现根节点的删除;如果还没有到达过期时间,那么该线程可以通过 while 循环来及时对头结点的过期时间进行判断,但是这样的话,会一直占用 CPU 资源,为了减少对 CPU 资源的浪费,可以让该线程等待指定的时间,等头结点的 key 的过期时间快到了之后,该线程才被唤醒,从而判断根节点的 key 是否过期。但是又有人会问了,如果在线程等待的期间又添加了一个过期时间短于根节点的 key 的过期时间该怎么办呢?也很简单,每次添加含有过期时间的 key 的时间就会调用类似 thread.notify() 这样的方法来唤醒该线程,那么当这个线程被唤醒之后,他就会去扫描根节点的 key 的过期时间,这样就算新添加进来的过期时间更短的 key,因为唤醒线程的操作,也可以及时的删除过期了的 key。
时间轮,就是将所有的具有过期时间的 key 放在一个轮上,该轮又被划分为了多个区间,轮上存在着一个指针,这个指针每隔一段时间就会从一个区间移动到下一个区间,这些具有过期时间的 key 会根据过期时间的长度划分在不同的区间中,当指针移动到某个区间,那么就会对该区间的 key 进行删除操作。
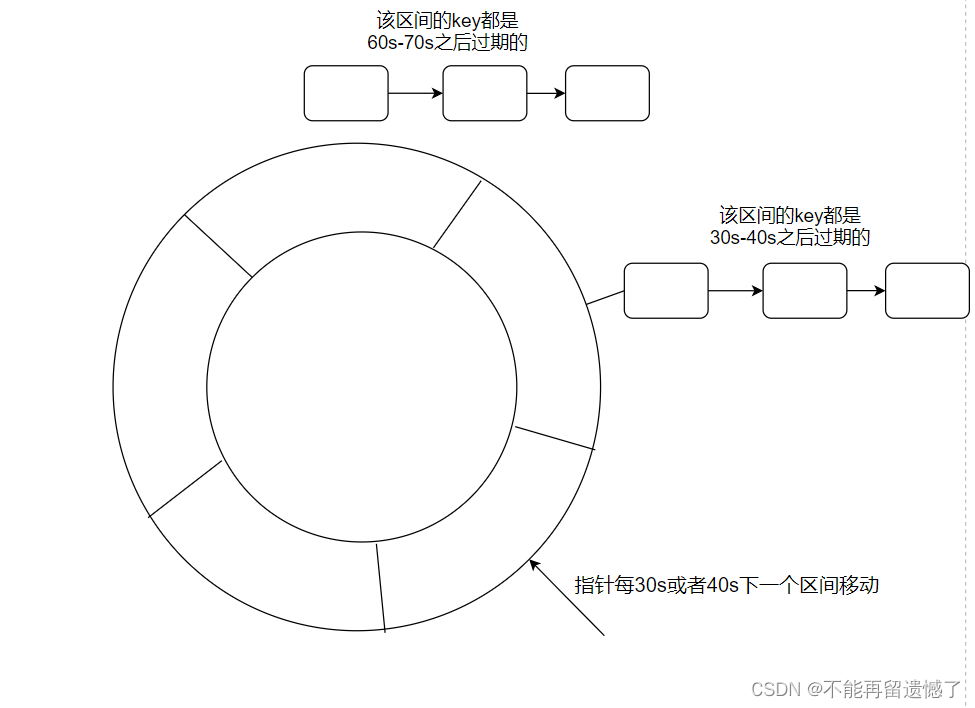
那么如果一个 key 的过期时间比较长,一个轮无法表示呢?我的想法是可能每个 key 节点中还会有类似计数器的变量,0表示指针第一次达到这个区间的时候,该 key 就被删除,1就表示第二次经过这个区间的时候,该 key 才被删除。
这两种方法都是比较好的及时删除过期 key 的方法,但是遗憾的是,redis 官方并没有采用这两种方法中的一个,而是用的定期删除和惰性删除相结合的策略来实现对过期 key 的删除,具体原因我们也不知道(可能是不想在 redis 中引入多线程,因为通过定时器和时间轮的做法都需要多添加一个或者多个线程来实现)。
TYPE 命令
type 命令返回 key 对应的 value 的数据类型。type key
type 命令的返回值有:none、string、hash、list、set、zset和stream。
返回 stream 类型是用在 redis 被用作消息队列的情况。
要想查看 type 命令的效果,我们可能需要用到其他的命令,这里我们主要关注 type 命令的效果,例子中出现的其他命令后面会为大家介绍到。
127.0.0.1:6379> set key1 "value" OK 127.0.0.1:6379> lpush key2 "value" (integer) 1 127.0.0.1:6379> sadd key3 "value" (integer) 1 127.0.0.1:6379> hset key4 filed1 "value" (integer) 1 127.0.0.1:6379> zadd key5 1 "value" (integer) 1 127.0.0.1:6379> type key1 string 127.0.0.1:6379> type key2 list 127.0.0.1:6379> type key3 set 127.0.0.1:6379> type key4 hash 127.0.0.1:6379> type key5 zset
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
数据结构和编码方式
redis 的几种常见的基本数据结构有 string、list、hash、set和zset(有序集合)。但是实际上 redis 针对每种数据结构都有自己的底层内部编码实现,而且是多种实现,这样 Redis 会在合适的场景选择合适的内部编码。
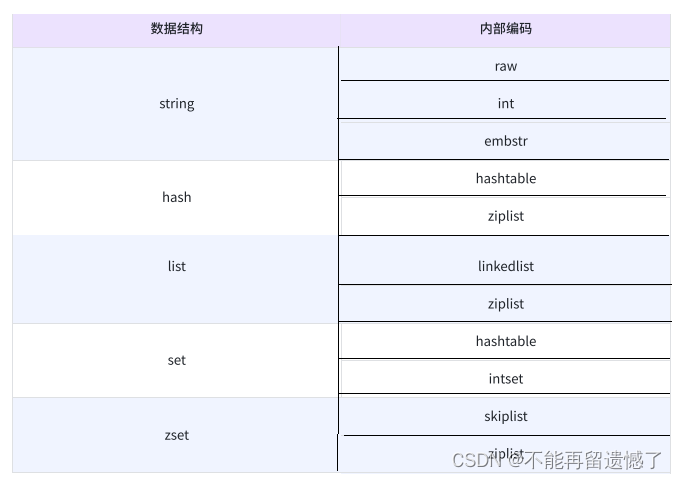
每种数据结构都存在至少两个的内部编码实现,redis 底层会根据情况决定使用哪种内部编码,并且这些不同的内部编码往往是对齐进行的优化,我们可以使用 object encoding key来查看指定 key 的 value 的内部编码:
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> lpush mylist a b c
(integer) 3
127.0.0.1:6379> object encoding hello
"embstr"
127.0.0.1:6379> object encoding mylist
"quicklist"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
当字符串较短的时候,string 的内部编码是 embstr;而如果字符串中的字符都是数字字符的时候,内部编码则是 int,字符串较长且存在非数字字符的时候,内部编码则是 raw,raw 的底层类似一个 char 类型的数组。当数据类型为 hash 的时候,如果哈希的长度较短,内部编码则是 ziplist,用来节省空间;哈希长度较长内部编码则是 hashtable。数据类型为 list 的时候也是,当列表较短时,内部编码是 ziplist;列表长度较长时,内部编码是 linkedlist,但是也会出现是 quicklist 的情况,quicklist 是 ziplist 和 linkedlist 的结合,它结合了这两种编码方式的优点。对于集合,如果集合中的元素都为整数的话,那么内部编码就是 intset,否则就是 hashtable。对于有序集合,如果集合的长度较短的话,内部编码就是 ziplist,较长就是 skiplist。
Redis 这样设计有两个好处:
- 可以改进内部编码,而对外的数据结构和命令没有任向影响,这样一具开发出更优秀的内部编码,无需改动外部数据结构和命令,例如RedisB.2 提供了quicklist,结合了ziplist和 linkedlist 两者的优势,为列表类型提供了一种更为优秀的内部组码实现,而对用户来说基本无感知。
- 多种内部编码实现可以在不同场景下发挥各自的优势,例如ziplist 比较节省内存,但是在列表元素
比较多的情况下,性能会下降,这时候 Redis 会根据配置选项将列表类型的内部实现转换为linkedlist,整个过程用户同样无感知。

