
热门标签
热门文章
- 1XP使用技巧
- 2C++基础与技巧【顺序容器】 (三大顺序容器~vector, list, deque)_顺序寻址 vector list
- 3spyder下报错ModuleNotFoundError: No module named_它没有 spyder kernels 模块或没有安装正确的版本 (>= 2.4.0 并 < 2.5.
- 4Python基础知识总结(期末复习精简版)_华中农业大学python考试
- 5微信开发者工具使用git提交项目至gitee远程仓库(保姆级)_微信开发者工具 gitee
- 6精选力扣500题 第31题 LeetCode 69. x 的平方根【c++ / java 详细题解】_69. x 的平方根 c++
- 7数据结构-栈
- 8cfg是什么
- 9自定义幂等注解_自定义注解实现幂等
- 10猿创征文|2022年前端之路——我的前端开发好帮手_csdn前端征文
当前位置: article > 正文
PaddleSeg学习1——Windows c++部署pp_liteseg模型_paddleseg inference c++
作者:从前慢现在也慢 | 2024-04-29 23:36:03
赞
踩
paddleseg inference c++
1 准备环境
官网:Paddle Inference在Windows上部署(C++)
1.1 准备基础环境
Visual Studio 2017
CUDA 10.2
CUDNN 7.6.5
TensorRT 7.0
OpenCV 4.5.4
- 1
- 2
- 3
- 4
- 5
1.2 准备Paddle Inference C++预测库
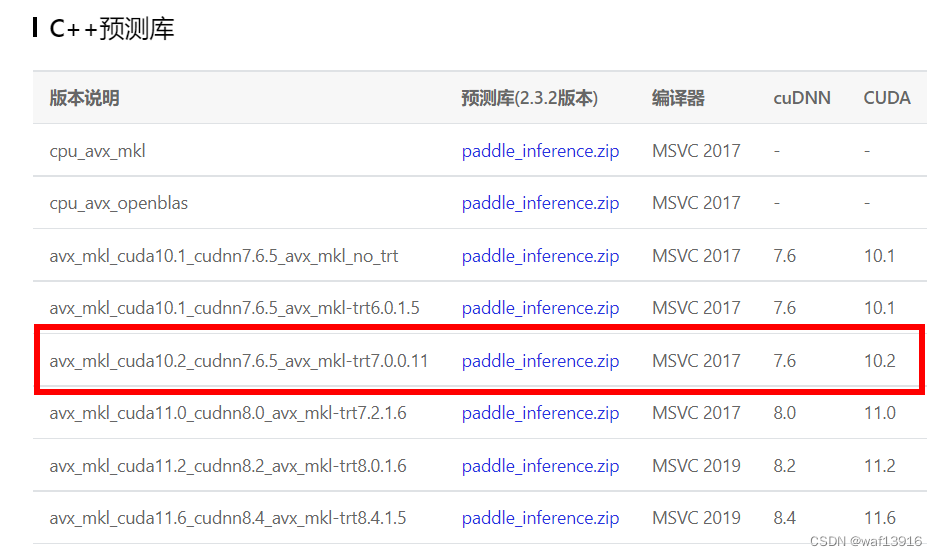
1.3. 准备模型和图片
下载准备好的预测模型到本地,用于后续测试。 如果需要测试其他模型,请参考文档导出预测模型。
预测模型文件格式如下:
pp_liteseg_infer_model
├── deploy.yaml # 部署相关的配置文件,主要说明数据预处理方式等信息
├── model.pdmodel # 预测模型的拓扑结构文件
├── model.pdiparams # 预测模型的权重文件
└── model.pdiparams.info # 参数额外信息,一般无需关注
- 1
- 2
- 3
- 4
- 5
model.pdmodel可以通过Netron 打开进行模型可视化,点击输入节点即可看到预测模型的输入输出的个数、数据类型(比如int32_t, int64_t, float等)。 如果模型的输出数据类型不是int32_t,执行默认的代码后会报错。此时需要大家手动修改deploy/cpp/src/test_seg.cc文件中的下面代码,改为输出对应的数据类别:
std::vector<int32_t> out_data(out_num);
- 1
下载cityscapes验证集中的一张图片到本地,用于后续测试。
2 编译
工程整体目录结构如下:
G:/paddle/c++
├── paddle_inference
└── PaddleSeg
- 1
- 2
- 3
2.1 使用CMake生成项目文件
编译参数的说明如下,其中带*表示仅在使用GPU版本预测库时指定,带#表示仅在使用TensorRT时指定。
参数名 含义
*WITH_GPU 是否使用GPU,默认为OFF;
*CUDA_LIB CUDA的库路径;
*USE_TENSORRT 是否使用TensorRT,默认为OFF;
#TENSORRT_DLL TensorRT的.dll文件存放路径;
WITH_MKL 是否使用MKL,默认为ON,表示使用MKL,若设为OFF,则表示使用Openblas;
CMAKE_BUILD_TYPE 指定编译时使用Release或Debug;
PADDLE_LIB_NAME Paddle预测库名称;
OPENCV_DIR OpenCV的安装路径;
PADDLE_LIB Paddle预测库的安装路径;
DEMO_NAME 可执行文件名;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
GPU使用TensorRT推理,命令如下:
cmake .. -G "Visual Studio 16 2019" -A x64 -T host=x64 -DUSE_TENSORRT=ON -DWITH_GPU=ON -DWITH_MKL=ON -DCMAKE_BUILD_TYPE=Release -DPADDLE_LIB_NAME=paddle_inference -DCUDA_LIB="C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\lib\x64" -DOPENCV_DIR=D:\projects\opencv -DPADDLE_LIB=D:\projects\paddle_inference -DTENSORRT_DLL="C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\bin" -DDEMO_NAME=test_seg
- 1
配置CMakeLists.txt






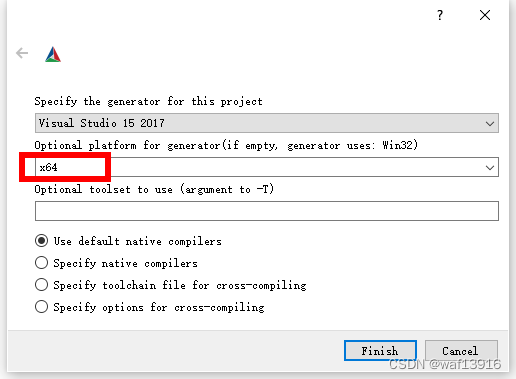
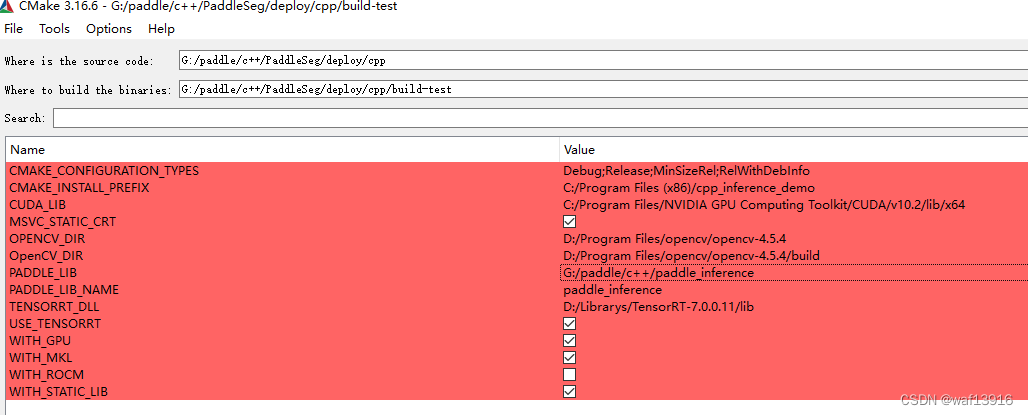
点击“Generate”->"Open Project"即可。
2.2 编译
用Visual Studio 2017打开cpp\build\cpp_inference_demo.sln,将编译模式设置为Release,点击生成->生成解决方案,在cpp\build\Release文件夹内生成test_seg.exe。
3 执行
进入到build/Release目录下,将准备的模型和图片放到test_seg.exe同级目录,build/Release目录结构如下:
Release
├──test_seg.exe # 可执行文件
├──cityscapes_demo.png # 测试图片
├──pp_liteseg_infer_model # 推理用到的模型
├── deploy.yaml # 部署相关的配置文件,主要说明数据预处理方式等信息
├── model.pdmodel # 预测模型的拓扑结构文件
├── model.pdiparams # 预测模型的权重文件
└── model.pdiparams.info # 参数额外信息,一般无需关注
├──*.dll # dll文件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
运行以下命令进行推理,GPU推理:
test_seg.exe --model_dir=./pp_liteseg_infer_model --img_path=./cityscapes_demo.png --devices=GPU
- 1
预测结果保存为out_img.jpg,该图片使用了直方图均衡化,便于可视化。

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/510377
推荐阅读
相关标签


{kind=link}