
- 1【Docker】通过Dockerfile构建Redis镜像,java堆和栈的区别面试题
- 2python 判断类属性(方法)是否存在_python 判断属性是否存在
- 3解决el-dialog弹出时,页面抖动,右侧会缩小的问题_vue3中当点击弹窗的时候,原来的页面宽度右侧会缩小一点是什么原因
- 4Redis搭建及使用
- 5javaEE002.03 js的三种嵌入方式_js 方法嵌入方法
- 6通过智能反射面进行安全的无线通信_secure wireless communication via intelligent refl
- 7阿里云云原生一体化数仓 — 湖仓一体新能力解读_阿里云湖仓一体
- 8MySQL运维实战(2.4) SSL认证在MySQL中的应用
- 9PMP项目管理项目中的文件_项目管理相关文件
- 10SimpleNet: A Simple Network for Image Anomaly Detection and Localization CVPR2023
TinySeg:模型优化框架
赞
踩
TinySeg: Model Optimizing Framework for
摘要
图像分割是计算机视觉任务中的主要组成部分,适用于各种领域,如无人机的自主导航。然而,由于图像分割模型的结构特点,其通常具有很高的峰值内存使用量,这使得图像分割难以在小型嵌入式系统上实现。
这项工作发现,在现有的小型机器学习框架下,图像分割模型不必要地占用大量内存空间。也就是说,现有框架不能有效地管理图像分割模型的内存空间。
本研究提出了一个新的模型优化框架TinySeg,它使小型嵌入式系统能够高效地进行图像分割。TinySeg分析目标模型中张量的生命周期,并识别长期存在的张量。
然后,TinySeg主要通过两种方法优化目标模型的内存使用:(i)将张量溢出到本地或远程存储,以及(ii)融合溢出张量的获取。本研究在现有小型机器学习框架之上实现了TinySeg,并证明TinySeg可以将图像分割模型在小型嵌入式系统上的峰值内存使用降低39.3%。 原型实现的开源代码可在https://github.com/coslab-kr/tinyseg获取。
本文的工作贡献如下:
一个新的模型优化框架,称为TinySeg,用于小型嵌入式系统上的图像分割。
TinySeg模型优化器的设计以及TinySeg运行时,采用了多种优化方法。
Background & Motivation
Image Segmentation Networks
近年来,计算机视觉界发展了各种神经网络架构,以实现精确的图像分割。图像分割是将输入图像的每个像素分类到某个类别,该类别对应于像素所属的目标。U-Net是最受欢迎的图像分割网络之一,最初是为医学图像分割设计的(Shan等人,2017年)。包括V-Net(Shan等人,2017年)和Swin-Unet(Shi等人,2018年)在内的许多最先进的图像分割网络,其结构都与U-Net相似。
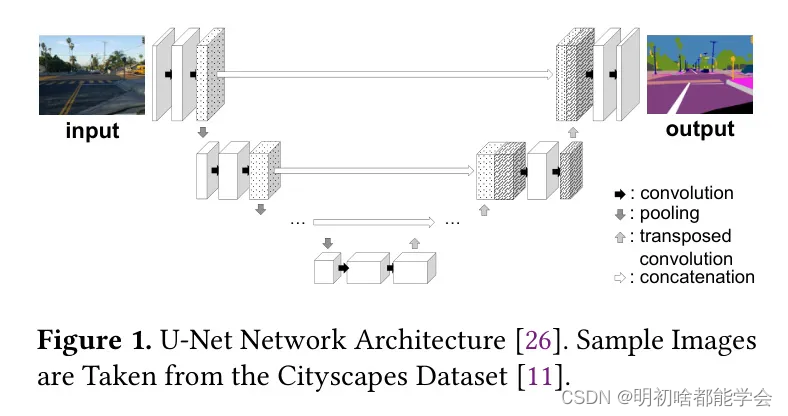
U-Net的结构被认为是类似于“沙漏”形状的,如图1所示。在向下过程中,它反复应用卷积和池化操作,激活的高度和宽度变小,但通道数增加,变得更深。然后,在向上过程中,它反复应用转置卷积和普通卷积,激活恢复到原始分辨率。同时,通过长跳跃连接将早期的激活与后期的激活连接起来,用于最终的预测。
TensorFlow Lite for Microcontrollers
TensorFlow Lite for Microcontrollers (TFLM) (Tensorflow, 2018) 是一个微小的机器学习框架,它使得在低功耗微控制器上部署神经网络模型变得容易,比如Arduino微控制器板。TFLM提供了一个C++编程接口,用于在裸机微控制器上加载和运行神经网络模型。TFLM将神经网络模型表示为操作符和张量的图,其中每个操作符接收输入张量,执行计算,并返回输出张量,如图2所示。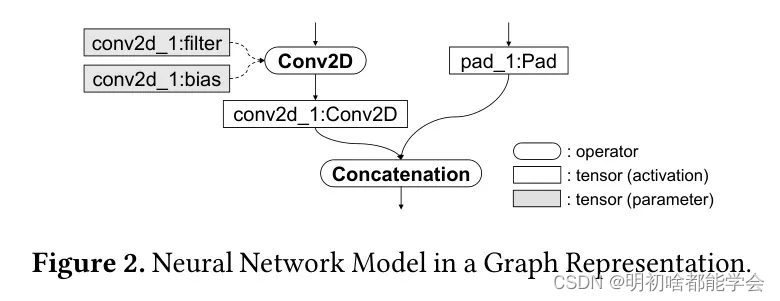
由于微控制器的内存有限,通常不足一兆字节,内存管理是框架的一个关键部分。通常,神经网络模型在内存中需要有两种类型的数据:
参数:一些神经网络操作符包括参数(权重),它们用于执行计算,如卷积滤波器。例如,在图2中,conv2d_1:filter和conv2d_1:bias是Conv2D的参数。参数的内存使用通常是_静态的_,因为参数值在训练后通常不会改变。
激活值:在执行过程中,神经网络操作符生成中间输出(特征图),这些输出成为其他操作符的输入。例如在图2中,conv2d_1:Conv2D是由Conv2D操作符定义的激活值,并由连接操作符使用。激活值的内存使用通常是_动态的_,因为它取决于如何在张量之间共享内存空间。
TFLM使用一个固定大小的全局内存缓冲区,称为_竞技场_,并在创建时到最后一次使用时(即在其生命周期内)将激活值存储在全局缓冲区中。TFLM分析每个张量的生命周期,并考虑张量的生命周期和大小生成内存计划。TFLM允许具有非重叠生命周期的张量共享同一内存空间,从而可以最小化运行网络模型的峰值内存使用。
当加载模型时,TFLM会检查模型的峰值内存使用是否会大于用户指定的竞技场大小。如果是这样,TFLM将返回一个内存不足错误,并且模型_无法_在目标系统上运行。也就是说,根据动态内存使用情况,模型可能无法在目标系统上运行。
Memory Usage of Image Segmentation Models
本研究分析了基于TFLM框架的图像分割模型的内存使用情况,并与框架提供的典型卷积神经网络图像分类模型(Chen等人,2018年)进行了比较。
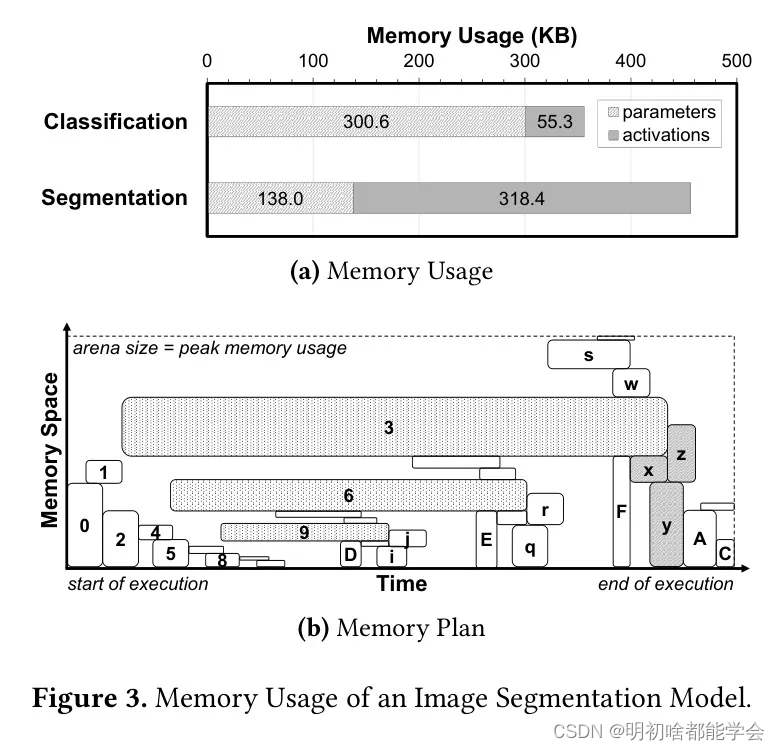
图3(a)展示了分类和分割模型在参数和激活上的内存使用情况。该图显示,分割模型对激活的内存需求远大于参数,而分类模型对激活的内存需求则小得多。然后,在二进制形式下,分割模型比分类模型小2.18倍,但在执行时需要多5.76倍的内存。
本研究发现,图像分割模型的高峰值内存使用主要源于两个问题:
(i)长时间闲置的“长生命期张量”在内存中占用空间,以及(ii)仅被短期使用的用于连接的“大型中间张量”。
首先,本研究发现在图像分割模型中,长生命期张量不必要地占用了大量内存空间。如图1所示,图像分割网络具有长的跳跃连接,以融合早期的(具体)信息用于最终预测。因此,早期的激活必须在内存中存储很长时间,直到它们与后期的激活进行连接。也就是说,尽管早期激活长时间未被访问,但必须为这些激活保留大量的内存空间,从而增加了模型的峰值内存使用。
图3(b)说明了由TFLM的默认内存计划器生成的图像分割模型的内存计划。该图显示了随时间每个张量占用的内存空间(即,区域)的哪部分。例如,张量0从时间0到时间1在区域的底部占用115.2千字节。该图展示了存在如张量3和张量6这样长时间占用内存空间的大型长生命期张量。
本研究还发现,尤其是用于连接的大型中间张量也导致了高峰值内存使用。在图3(b)中,一个连接操作读取张量3和张量x,并将结果写入张量y。然后,一个卷积操作读取张量y并将其写入张量z。这里,中间张量y仅用于短时间来连接张量3和张量x,但其内存使用不可忽视。
TinySeg: Model Optimizing Framework
这项工作提出了TinySeg,这是一个用于内存高效图像分割的优化框架,该框架的模型可能具有很高的峰值内存使用率。TinySeg框架由TinySeg模型优化器和TinySeg运行时组成,如图4所示。TinySeg模型优化器分析和转换输入模型以减少其峰值内存使用。TinySeg运行时提供高效的定制算子以执行优化后的模型。
TinySeg模型优化器包括两个主要用于内存优化的组件:冷范围分析器和图 Transformer 。冷范围分析器识别输入模型中每个张量的最长冷范围,即张量存储在内存中而未被访问的时间段。接下来,图 Transformer 根据分析结果修改模型图,以处理导致峰值内存使用的主要长期存在的张量和大尺寸中间张量。
整个优化过程在算法1中总结。在每次迭代中,模型优化器分析模型中张量的冷范围,根据分析结果转换模型,并生成新的内存计划以检查转换后模型的峰值内存使用。这是因为每次图 Transformer 修改模型并更新张量的生命周期时,模型的内存计划都可能发生变化。如果没有进一步的优化可能,模型优化器将停止优化模型并返回优化后的模型。

需要注意的是,TinySeg模型优化框架对输入模型的类型_没有限制_。因此,TinySeg框架可以处理任何机器学习模型,尽管它在具有长跳跃连接的图像分割模型上最有效。
The TinySeg Model Optimizer
作者为TinySeg提出了一种新颖的模型优化技术,这对于在移动设备上保持实时性能至关重要。主要思想是将分割网络分解为两个子网络:特征提取器和轻量级解码器。特征提取器负责从输入图像中提取高质量特征,而解码器则基于这些特征预测分割 Mask 。为了针对移动设备优化模型,作者采用了以下技术。
Cold Range Analyzer
冷范围分析器从根节点遍历模型图,并跟踪每个张量被定义和使用的位置以生成冷范围信息。一个张量的冷范围信息包括以下三个整数:
start:最长冷范围起始的操作符标识符
end:最长冷范围结束的操作符标识符
last:最后一个使用该张量的操作符标识符
请注意,起始操作符的标识符总是小于或等于结束操作符的标识符。
算法2描述了冷范围分析器如何构建用于图转换的冷范围信息。基本上,它遍历输入图中的所有操作符列表,并更新张量的(最长)冷范围。对于每个操作符,它首先检查操作符的输出张量,并初始化每个输出张量的冷范围(从第2行到第4行)。在模型图中,每个张量只被定义一次,因此在操作符定义时初始化冷范围信息是安全的。
接下来,它检查操作符的输入张量,并更新每个输入张量的冷范围(从第5行到第11行)。如果一个张量是操作符的输入,这意味着该张量被操作符使用。它还表示当前冷范围的结束和新的冷范围的开始。由于代码范围分析器旨在找到_最长_的冷范围,它首先检查当前冷范围(op.id - CR[t].last)是否比暂定的最长冷范围(CR[t].end -CR[t].start)更长。如果是这样,它更新最长冷范围,然后是最后一个操作符。
图5展示了一个单一张量的示例冷范围分析。当张量1被操作符1定义时,分析器初始化该张量的冷范围信息。接下来,当张量第一次被使用时,分析器更新冷范围信息,以确认第一个冷范围,从操作符1到操作符2。然后,当张量再次被操作符9使用时,分析器将当前冷范围(从操作符2到操作符9)与最长冷范围进行比较。由于当前冷范围比最长冷范围更长,分析器更新了冷范围信息。通过这种方式,冷范围分析器构建了输入模型图中所有张量的冷范围信息。
Graph Transformer
图Transformer通过两种方法根据冷范围分析修改目标模型的图:一是将张量溢出到本地或远程存储中,以将冷张量移开;二是通过融合获取来移除大的中间张量。算法3简要描述了整个转换过程。

4.2.1. Tensor Spilling
为了减少长期存在的张量不必要的内存使用,如果预期有益,模型优化器会将这些张量溢写到本地或远程存储中。对于给定的模型图,图 Transformer 找到一个要溢写的张量,并通过溢写该张量来修改图。为了选择受害者张量,它会找到与峰值内存使用相关的张量。在所有张量中,图 Transformer 选择具有最长冷区间(Cold Range)的张量作为受害者张量(算法3第3行)。
在选择了受害者张量之后,优化器检查受害者张量的大小是否大于目标内存减少量。如果是这样,这意味着为了达到目标内存减少,溢写整个张量是不必要的。为了部分溢写受害者张量,优化器插入了额外的操作符,将受害者张量分割成两个子张量,并将这些子张量连接起来(算法3的第7行到第9行)。然后,其中一个子张量变成了新的受害者张量,并相应地更新起始和结束操作符。通过这种方式,优化器可以减少要溢写的张量的大小,减少张量溢写和取回的不必要开销。
图5. 冷区间分析示例。
接下来,图 Transformer 在冷区间的开始和结束处插入实现张量溢写的操作符(算法3的第12行到第14行)。TinySeg提供了两个用于张量溢写的自定义操作符:溢写和取回操作符。溢写操作符将张量数据传输到本地或远程存储。取回操作符从本地或远程存储获取张量,如果有的话,将其与输入张量连接。
图6简要说明了张量溢写后模型图如何变化。首先,图 Transformer 在冷区间的开始处插入溢写操作符。溢写操作符将受害者张量(例如图中的张量1)作为其输入,并且没有输出张量。接下来,图 Transformer 在冷区间的结束处插入取回操作符。最后,由于张量在其冷区间内不再需要占用内存,如图所示,受害者张量的生命周期缩短了。然后,张量占用的内存空间可以与其他张量共享。
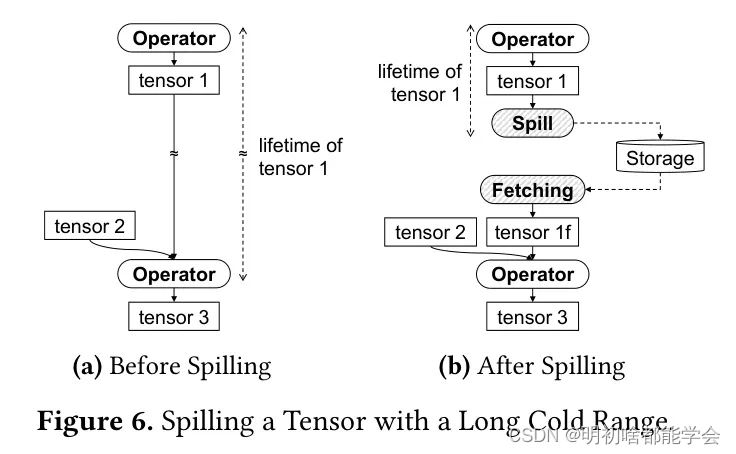
图7描述了在部分溢写情况下模型图如何变化。当允许部分溢写时,优化器插入一个分割操作符以将受害者张量分割成两个子张量。然后,优化器插入一个连接操作符,用这两个子张量恢复原始张量。然后,当一个子张量(即图中的张量1b)成为新的受害者张量时,优化器像图6中那样插入溢写和取回操作符。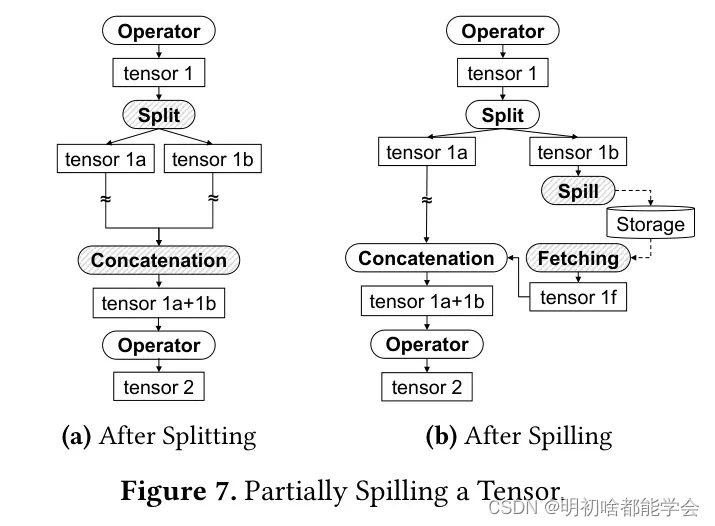
请注意,优化器在考虑目标内存减少量的同时确定分割大小。例如,假设受害者张量的尺寸为N,优化器将受害者张量分割成一个大小为N - align(MR)的子张量,以及一个大小为align(MR)的子张量,后者成为新的受害者张量。优化器根据受害者张量的形状和数据类型应用对齐。
4.2.2.Fused Fetching
在发生张量溢出后,模型优化器会尝试将取回(Fetching)操作与后续的操作融合,如果这样做是可能且有益的。首先,如果框架不支持高效的融合操作,操作融合可能无法实现。其次,如果中间张量小于输入和输出张量,操作融合可能不会带来好处。如果中间张量小于输入和输出张量,融合后的峰值内存使用可能会增加。融合后,融合操作将执行原始计算,同时从本地或远程存储中取回溢出的张量。
特别是当后续操作是连接(Concatenation)时,优化器将连接操作合并到取回操作中。由于取回操作可以在内部执行连接,因此无需另一个连接操作。然后,取回和后续的连接操作在融合后变成一个新的取回操作。对于其他类型的操作,优化器会创建一个新的融合操作,同时执行两个操作。
图8简要说明了操作融合后模型图如何变化。图 Transformer 融合了两个操作并移除了中间张量,因为融合后不再需要该张量。在这里,假设张量2大于张量1或张量3。融合前的峰值内存使用为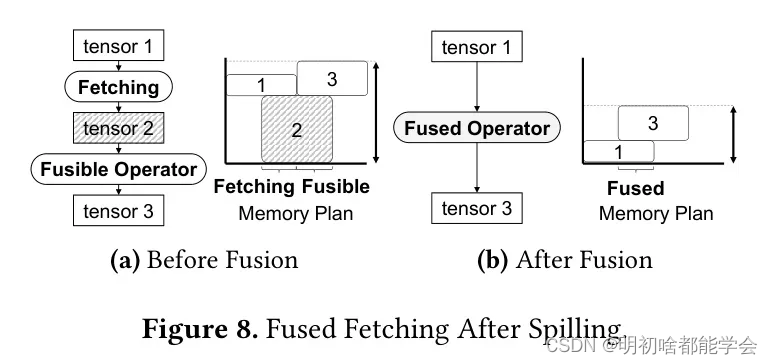
max{tensor 1/ +/tensor 2], |tensor 2| +|tensor 3}
而在操作融合后,峰值内存使用变为
|tensor 1/ +/tensor 3]
由于张量2大于张量1或张量3,修改后的图将具有比原始图更低的峰值内存使用。通过这种方式,内存优化器可以进一步优化目标模型的内存使用。
The TinySeg Runtime
TinySeg运行时负责在运行时实现张量的溢出和获取。TinySeg运行时采用各种优化方法来降低性能开销,本节将描述这些方法。
Dynamic Tensor Compression
TinySeg运行时在运行时传输张量数据以进行张量溢出和获取。为了减少数据传输的开销,这项工作设计了一种简单而有效的(压缩的)张量表示方法,它移除了最频繁值重复出现的情况。如图9(a)所示,它由一个代表性值、一个其他值的数组以及一个位图组成,位图用来指示其他值的位置。例如在图中,张量中最频繁的值是9,位图指示了每个不等于最频繁值的值的位置。
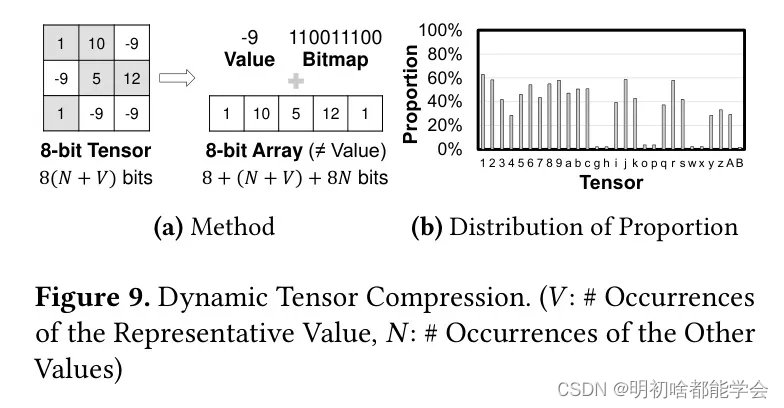
尽管压缩稀疏行(CSR)(Brockman et al., 2016)是一种广泛用于稀疏张量的表示方法,但它更复杂,更适合于张量稀疏性很高的情况(即张量数据中有许多零)。然而,这项工作发现,在示例图像分割模型中的张量通常含有一个非常频繁的非零值,该值占据了大约50%的张量。图9(b)显示了示例图像分割模型中每个张量中最频繁值的比例。图表显示,除了少数几个张量外,代表性值在相应的张量中占主导地位。
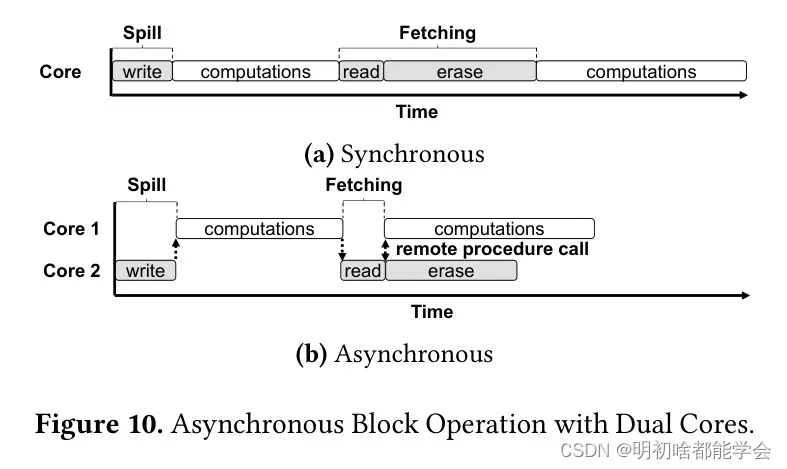
Asynchronous Block Operation
依赖于目标存储的规格,张量溢出和提取可能会产生不可忽视的开销,大大增加了总网络延迟。特别是在使用设备上的闪存时,开销可能更大,因为需要在覆盖张量数据之前进行块擦除。此外,众所周知,在典型闪存中,块擦除所需的时间比块写入或读取要长得多。
为了隐藏块擦除的开销,TinySeg运行时使用双核处理来启用异步块操作。最近,许多微控制器都配备了多个处理核心。由于块擦除在单个模型执行内的后续计算中没有依赖关系,运行时可以使用另一个核心来异步擦除闪存块。因此,如图10所示,运行时调用一个异步远程过程调用到另一个核心,以便块擦除可以并行运行。
Temporary Tensor Quantization
在动态张量压缩和异步块操作之上,这项工作在现有框架(Chen等人,2019年)中发现了另一种内存优化机会。对于某些算子,框架分配并使用临时张量作为cratch缓冲区。然而,在像TransposeConv这样的某些算子的情况下,临时张量可能甚至比其输入和输出张量还要大,从而增加了峰值内存使用量。因此,这项工作进一步对大临时张量进行量化(如果可能的话,从32位到16位)。
Evaluation
Experimental Setup
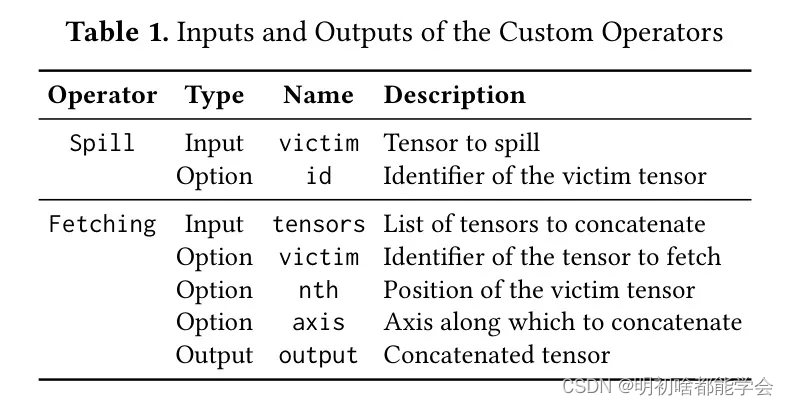
这项工作在开源的TensorFlow Lite框架(Chen等人,2019年)之上实现了TinySeg的原型。本研究开发了符合TensorFlow Lite模型格式的冷范围分析器和图 Transformer ,以实现适用性。此外,这项工作通过三种新的TensorFlow Lite算子扩展了框架,以支持张量溢出和融合提取:Spill、Fetching和FetchingConv2D,考虑了典型图像分割模型中使用的算子。
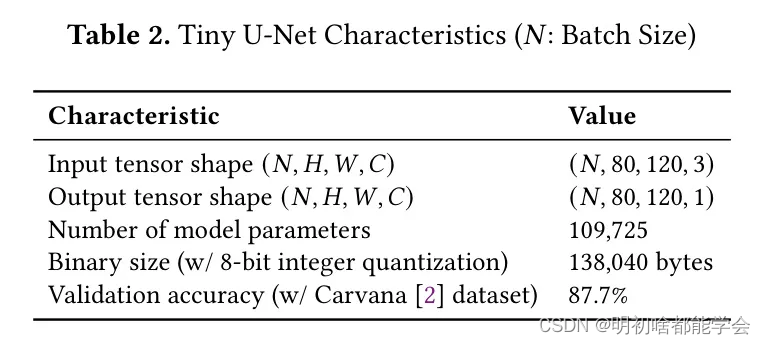
这项工作还设计了一种新的小型图像分割网络,称为Tiny U-Net,以实现在小型嵌入式设备上的图像分割。这个新网络是U-Net(Zhu等人,2019年)的缩小版,具有较小的卷积层和较少的跳跃连接。为了展示其有用性,这项工作从头开始训练网络,并为现有的图像分割数据集(Chen等人,2019年)获得了可比较的验证准确度。具体来说,Tiny U-Net模型在验证集上获得了87.7%的准确度,而大约200倍参数的原始U-Net获得了92.9%。表2总结了网络的特性。
为了展示TinySeg框架的有效性,这项工作逐步将优化方法应用于原始的Tiny U-Net模型(使用8位整数量化),并从内存使用、网络延迟和功耗方面评估优化后的模型。为了比较原始模型和优化模型的功耗,这项工作使用Keysight U1232A数字多用表测量流入目标设备的电流,该多用表的电流测量分辨率为0.01 A。
对于张量溢出,这项工作研究了以下三个选项:
将张量溢出到设备上的内部闪存,即微控制器芯片上的内部闪存
将张量溢出到设备上的外部闪存,连接到微控制器
通过串行通信将张量传输到远程存储,实现张量溢出
请注意,使用不同的溢出选项不会影响模型的峰值内存使用,但会影响模型的延迟。
这项工作使用现有框架的默认内存规划器GreedyMemoryPlanner(Chen等人,2019年)测量了原始模型和优化模型的峰值内存使用。此外,这项工作在商业低功耗微控制器板Arduino Nicla Vision(Chen等人,2019年)上测量了每个模型的网络延迟,该板使用配备双ARM Cortex-M7/M4核心、2 MB内部闪存、1 MB主内存以及连接16 MB外部QSPI闪存的STM32H757All6微控制器。

