
- 1Git 使用技巧,让你的工作效率翻倍!_git提交本地仓库让他更快速
- 2移动新魔百盒M411A_S905L3_UWE5621DS_2+8_免拆卡刷固件包_m411a刷机包
- 3电网机巡智能管控平台渗透测试经历_电力渗透平台
- 4uniApp下载图片到手机相册,适配Android、Ios、微信小程序、H5_uniapp 下载图片
- 5nginx无法启动,任务管理器中找不到进程_错误: 没有找到进程 "nginx.exe"。
- 6卷王登场:yoloV5视频流处理LoadImages与box_label_yolov5 class loadwebam读rtsp
- 7时间序列预测----(基于多变量深度模型)_多变量时间序列模型
- 8rabbmitmq延时队列的多种实现_put("x-delayed-type", "direct")
- 9RCNN和CRNN
- 10c++ -O1,-O2,-O3资料整理_c++ -o2
免费开源语音克隆-GPT-SoVITS-WebUI只需 5 秒的声音样本_gpt-sovits.zip文件
赞
踩
语音克隆-GPT-SoVITS-WebUI

强大的少样本语音转换与语音合成Web用户界面。
功能:
-
零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
-
少样本 TTS: 仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
-
跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
-
WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
训练用整合包下载:
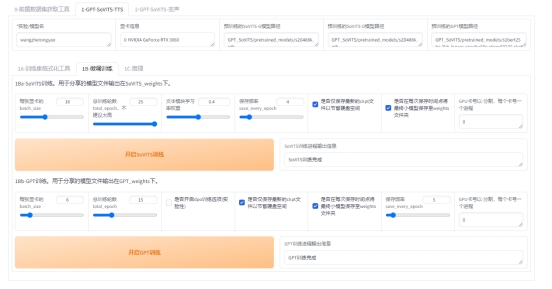
GSVI推理包 2.4.3
链接:夸克网盘分享
极佳模型分享(使用30小时派蒙数据集,100%正确率标注):
派蒙:夸克网盘分享
将GPT模型(ckpt后缀)放入GPT_weights文件夹,SoVITS模型(pth后缀)放入SoVITS_weights文件夹,刷新下模型就能选择模型推理了
解压:
请使用7-Zip解压!其他解压工具可能会吞文件,比如360解压、Windows自带的解压、2345好压等很多解压工具都会吞文件!
7-Zip中文版下载:夸克网盘分享
解压后,双击go-webui.bat打开,不要以管理员身份运行!
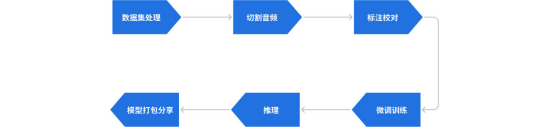
大致流程:
注意事项:
标注:
每一页修改完都要点一下保存修改(Submit Text),如果没保存就翻页那么会重置文本,在完成退出前要点保存文件(Save File),做任何其他操作前最好先点一下保存修改(Submit Text)。合并音频和分割音频不建议使用,精度非常差,一堆bug。删除音频先要点击要删除的音频右边的yes,再点删除音频(Delete Audio)。删除完后文件夹中的音频不会删除但标注已经删除了,不会加入训练集的。这个SubFix一堆bug,任何操作前都多点两下保存
复制的路径都不能有引号!!!千万不能有引号!
模型名,不要有中文
sovits训练建议batch_size设置为显存的一半以下,高了会爆显存。bs并不是越高越快!
关闭共享显存:
去nvidia官网下载了个Studio版本的驱动
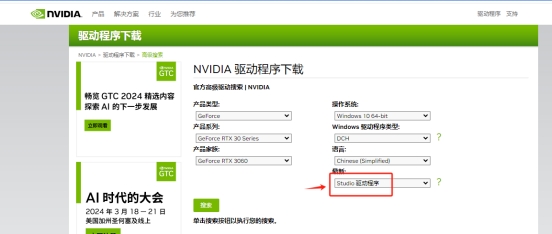
点击管理3D设置—程序设置—添加—浏览,选择GPT-SoVITS\runtime\python.exe这个文件
将CUDA-系统内存回退政策改为偏好无内存回退。如果你是英文界面,那么就是CUDA-Sysmem Fallback Policy改为Prefer No Sysmem Fallback。改完之后只会在运行这个程序的时候会关闭共享显存,不会影响其他时候使用共享显存。
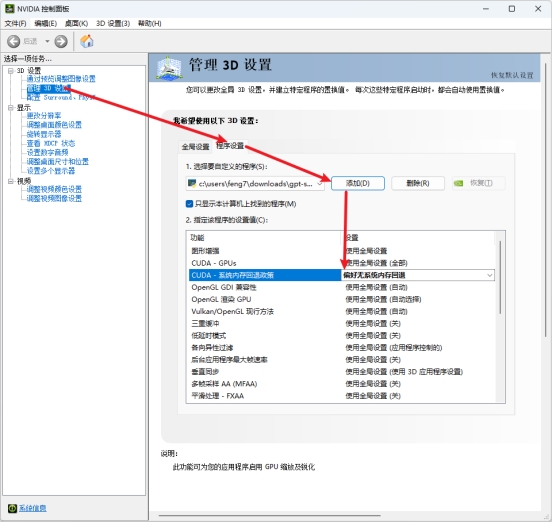
GPT-SoVITS-WebUI参考文档:https://github.com/RVC-Boss/GPT-SoVITS/blob/main/docs/cn/README.md
GSVI推理包文档:如何安装

