
- 1软考高项:项目沟通及干系人管理模拟试题_关于项目干系人的选择题怎么写
- 2淘宝线上扭蛋机小程序:推动扭蛋机销量
- 3AI-机器学习之模型评估_ai模型评估岗位的理解
- 4【win10专业版】防火墙筑起的边界防御需要关闭吗_win10防火墙有必要开吗
- 5队列与栈的异同点_线性表,栈和队列的异同点
- 6Python版本的查看_python version
- 7【愚公系列】软考高级-架构设计师 038-性能指标
- 8Ubuntu(x86、arm)22.04配置清华源_ubuntu 22.04清华源
- 9数据挖掘与数据化运营实战. 1.3 为什么要数据化运营
- 10【Unity入门】详解Unity中的射线与射线检测_unity 射线
自然语言处理实验之命名实体识别标注_命名实体识别序列标注
赞
踩
命名实体识别标注
常用的命名实体识别方法:
识别过程一般建模成一个系列标注过程,即给定标注系列C1,C2⋯,Cn(句子),选择一条(概率)最大化的标注路径L1,L2⋯,Ln,
满足函数:
argmaxP(L1, ⋯,Ln | C1, ⋯,Cn)
实验
- 采用BIO标注
例子:
自 然 语 言 处 理 是 人 工 智 能 的 一 个 分 支
B I I I I I O O O O O O O O O O - 运用长短期记忆神经递归网络LSTM和条件随机场CRF
实验主要步骤
数据集:分为训练集和测试集,且都为JSON文件格式。
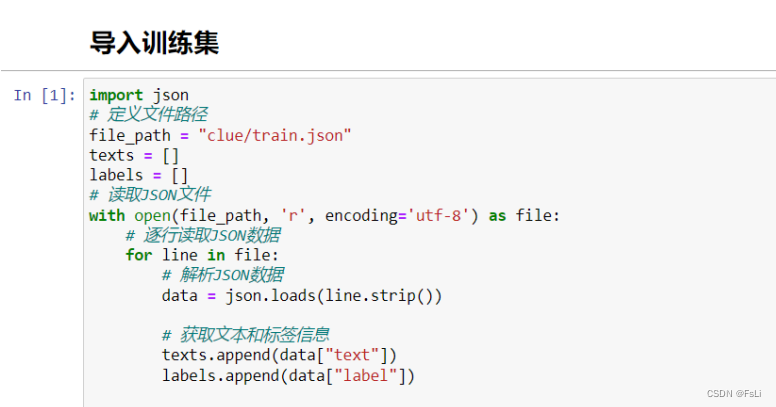
将clue/train.json文件中text和label部分分别提取出来。如下图:
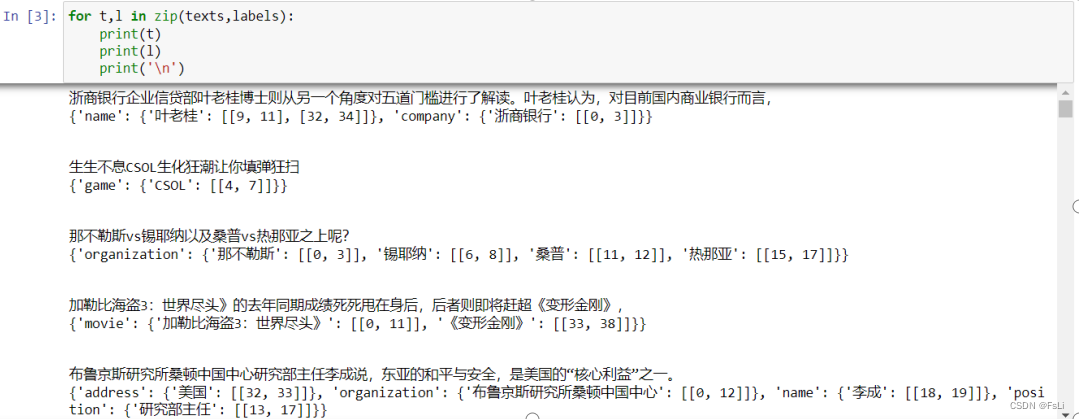
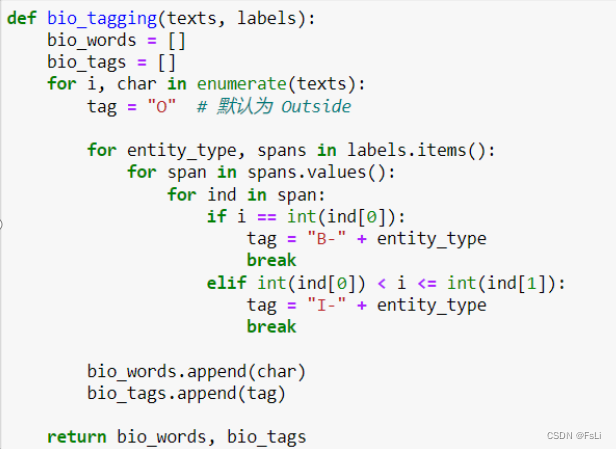
进行序列标注,此处采用BIO标注模式:
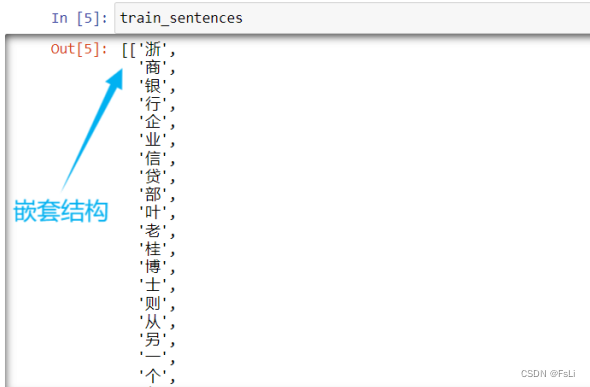
上述函数,返回值是二维句子列表(嵌套结构),最里层的一个列表代表一个句子,列表的一个元素对应句子中的一个字。以及根据相应句子按字为单位根据BIO标注模式标注好的标签(嵌套结构)。
特征:
标签:
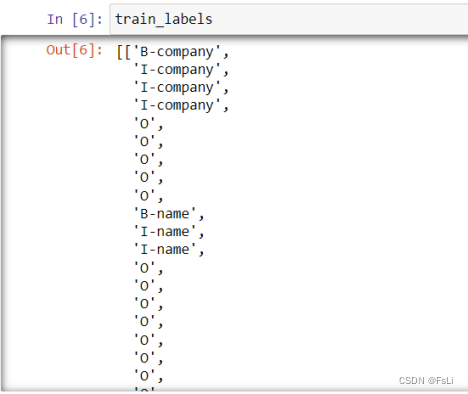
统计训练集中的出现的所有标签类别,用字典数据类型进行排序标号。
为接下来 字符—>数字 的步骤做准备,需要做相应的字典映射,方便传入训练模型(神经网络模型不能识别字符)。
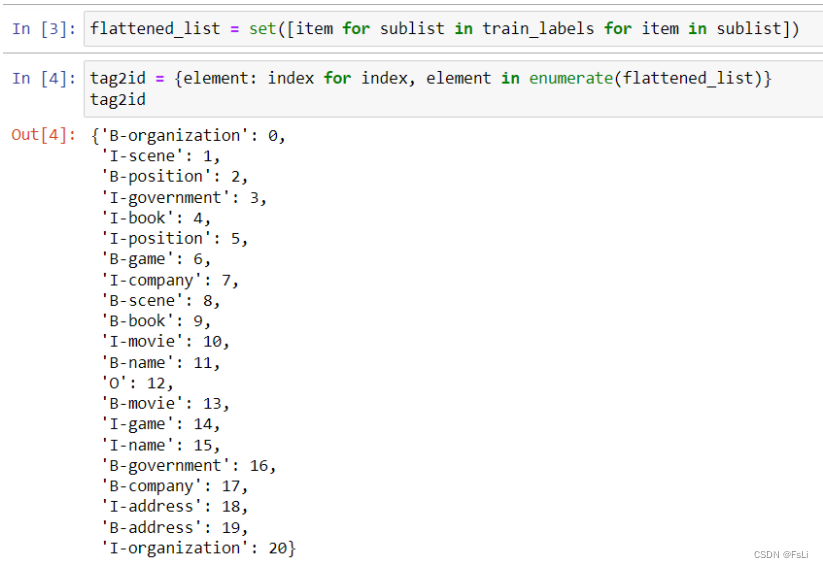
神经网络模型定义:
LSTM(长短时记忆网络):
LSTM是一种循环神经网络(RNN)的变体,专门设计用来解决长序列依赖问题。它通过引入门控机制,包括输入门、遗忘门和输出门,来控制信息的流动,从而有效地捕捉和保留长序列中的信息。LSTM在处理长期依赖关系时相比传统的RNN表现更好,适用于需要记忆长期上下文信息的任务。
CRF(条件随机场):
CRF是一种判别模型,通常用于序列标注问题。在NLP中,CRF通常用于将标签分配给输入序列的每个元素,如词性标注或命名实体识别。CRF考虑了序列中相邻标签之间的关系,通过建模条件概率来联合考虑整个序列的标签分配。这种条件建模使得CRF在序列标注任务中能够更好地处理标签之间的依赖关系,尤其是在考虑全局一致性时。
结合 LSTM 和 CRF:
在某些任务中,人们常常将LSTM和CRF结合在一起,形成一个端到端的序列标注模型。LSTM用于学习输入序列中的特征表示,然后CRF用于建模标签之间的依赖关系,确保全局一致性。这种结合通常能够提高序列标注任务的性能,尤其是在需要考虑上下文依赖关系的情况下。
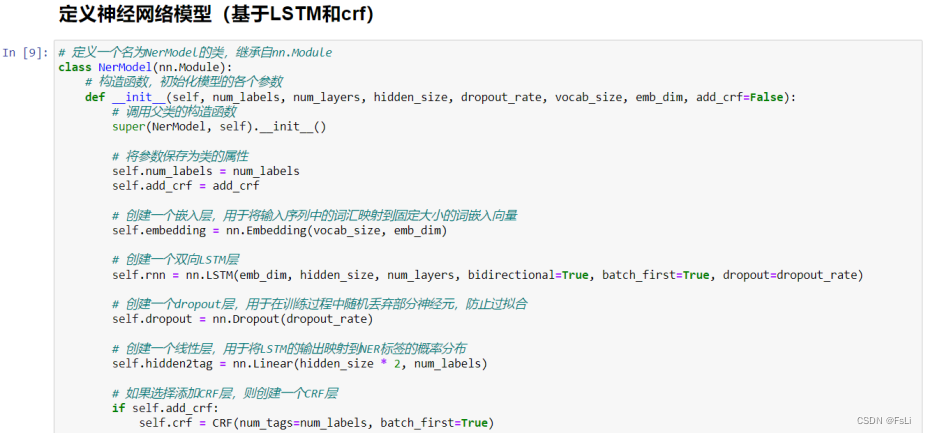
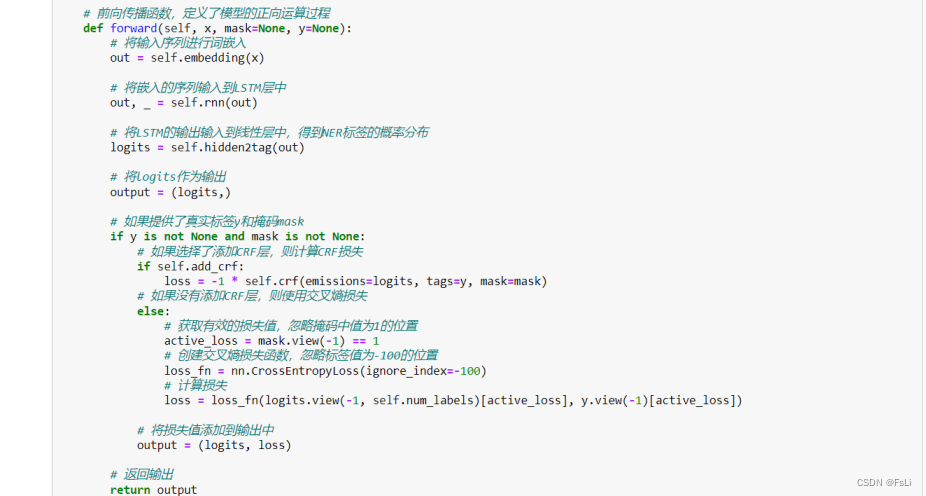
接下来就是将 句子train_sentences(一个一个的字)------> 数字:
先利用train_sentences做一个字典,可以先将train_sentences平铺成一维列表,再利用set型数据的构造函数将字去重,然后利用dic型数据将其一一编号,从而得到一个字典。(eg:{‘自’ : 1, ‘然’ : 2, ‘语’ : 3, ‘言’ : 4})
根据该字典将train_sentences中的字一一映射成数字得到数字编码的二维列表。
类似的操作,将train_labels(BIO序列标注的标签)------> 数字。
然后将训练数据转化为张量。以下是转化为张量的一些好处:
- 张量是数学运算的基本单位,能够方便地进行线性代数运算,如矩阵乘法、向量运算等,这对于深度学习等领域至关重要。
- 张量运算可以通过GPU等硬件进行高效并行处理,加速深度学习模型的训练和推断过程。多数深度学习框架(如TensorFlow、PyTorch)基于张量进行模型的构建和训练,因此将数据表示为张量更容易与这些框架集成。
- 在深度学习中用于计算梯度,这对于反向传播算法和模型优化至关重要。
- 可以在不同平台上进行传递和存储,支持模型在多种硬件设备上运行,提高了模型的可移植性。
同时我们要保证训练时的每批数据长度相同,若数据长度不够则用0填充。
接下来就是训练过程的展示:
此处设置模型迭代训练15次,学习率0.0005,hidden_dim = 200,emb_dim = 100。

并保存模型。
导入测试集,并将测试集的数据预处理同上述训练集的数据预处理。
用处理好的测试集数据放入模型进行预测并保存预测结果。

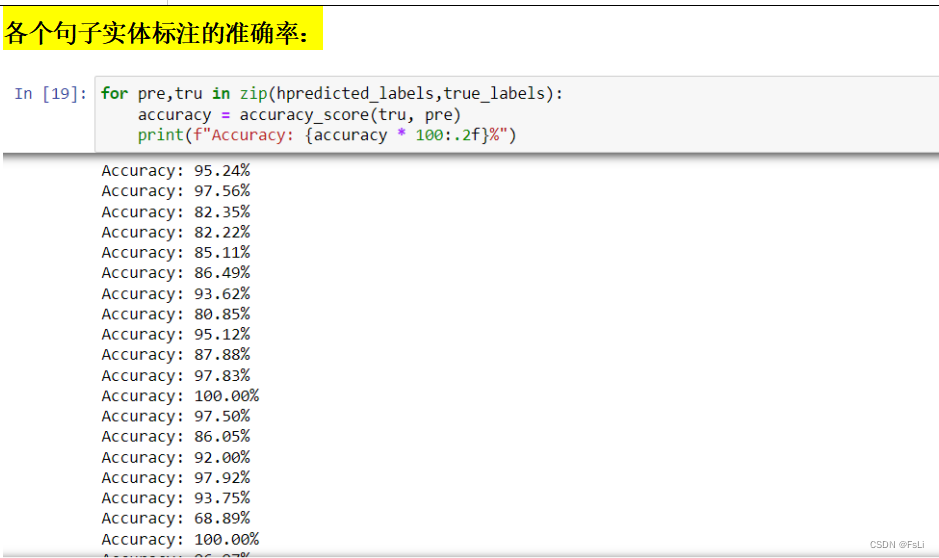
注意:这里仅仅只是BIO标注的预测结果的准确率计算,由于O占大多数,所以实体的标注(B、I 的标注)的准确率无法直观的知晓。
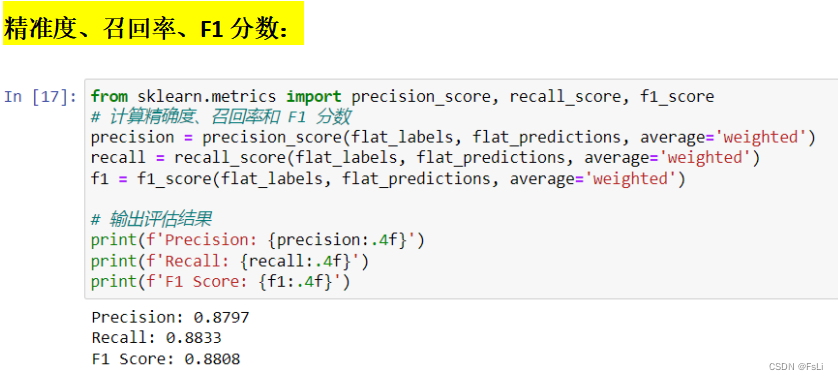
计算并绘制混淆矩阵:
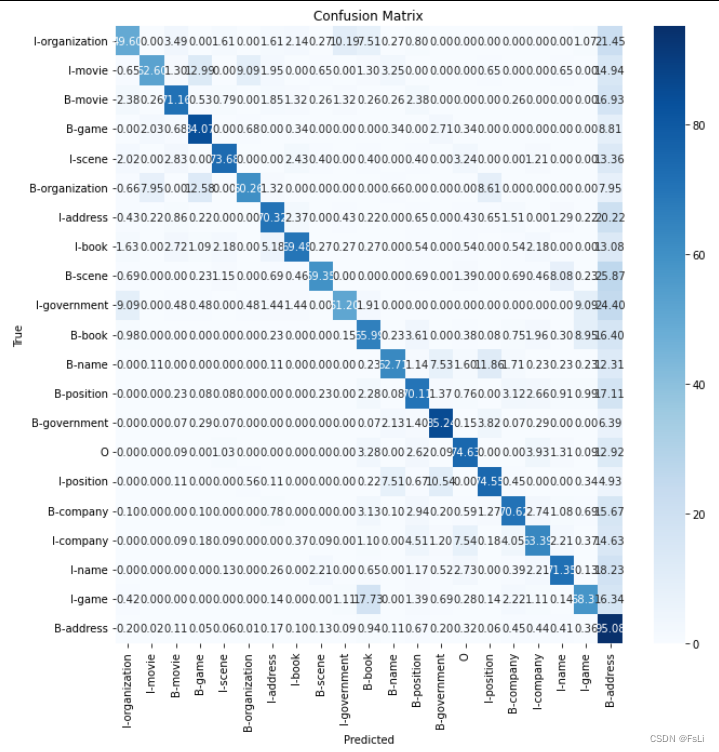
根据混淆矩阵来看,模型整体预测效果不错,但由于B-address的出现次数过多,导致模型预测时,出现了其他标签向B-address频繁地预测,而忽视样本数量较少的类别的情况。对预测准确性稍有影响,解决方案是可以针对该标签欠采样、在损失函数中引入类别权重、不平衡学习算法等等。
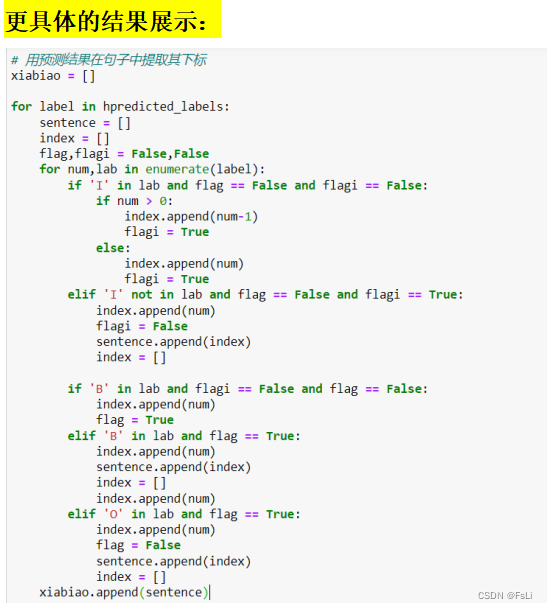
这里的提取思想是:
模型在序列标注预测时,部分序列的标注没有遵从BIO标注,部分实体的第一个字没有被标注(即没有B-),这里将从‘I-’标注开始的字串中,向前移动一位字符作为‘B-’, 即拓展‘I-’字串前一位字符作为该实体。
举个例子:
真实序列标注是 自 B-xxx 然 I-xxx 语 I-xxx 言 I-xxx 。 O
模型预测的标注是 自 O 然 I-xxx 语 I-xxx 言 I-xxx 。 O
可以看到向前拓展一位字符即为正确的序列标注。
对于模型预测正常的序列标注按照‘B-’开始序列标注,‘I-’为中间序列标注 的方式提取。
提取出来的结果为:
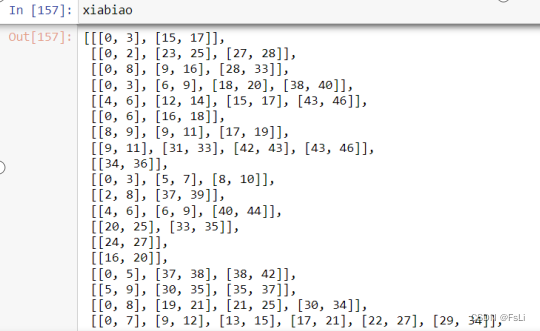
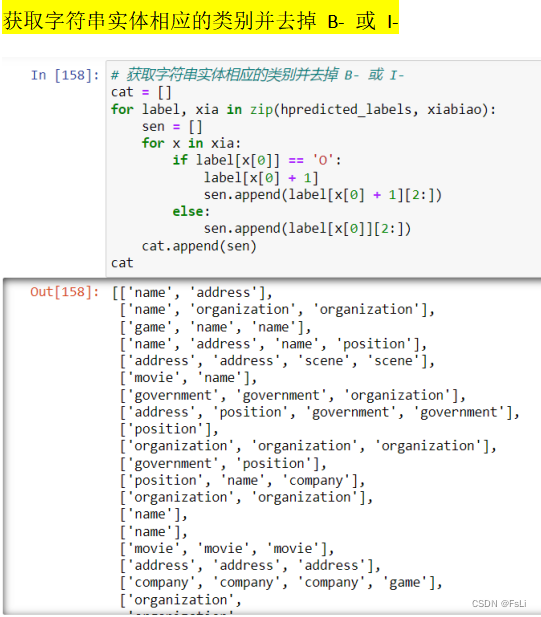
在经过一系列的有点点复杂的格式转换,得到以下结果:
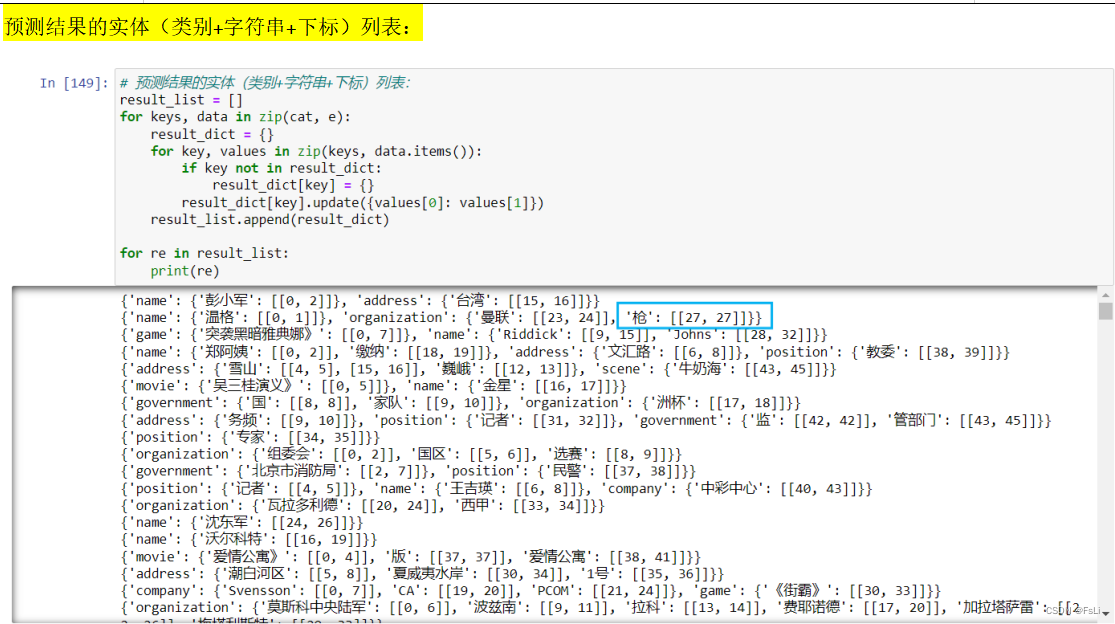
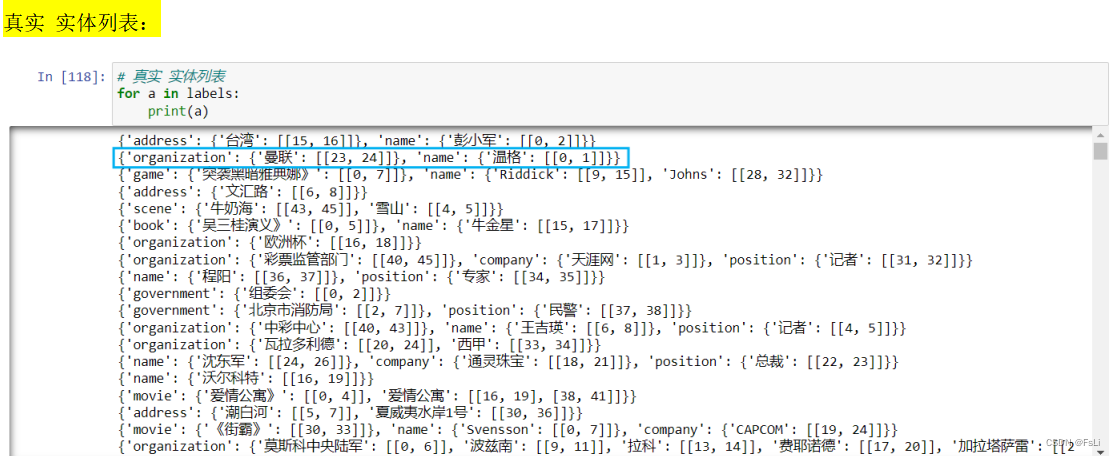
这样就得到了更直观的实体标注的结果对比,发现有些句子会出现标注错误的情况,如上两图中蓝框框住的部分。多标注了一个‘枪’作为了实体。
到这里就可以直观的看到模型预测出的实体、下标范围及其类别预测准确率还是不错滴。

