
- 1文心一言指令详解及实例分析_文心一言 指令
- 2N元语言模型的训练方法_语言模型训练
- 3docker报错 driver failed programming external connectivity on e_docker: error response from daemon: driver failed
- 4【GitHub】修改默认分支_github如何切换默认分支
- 5【4】私有链发币_4、 私有链如何换币
- 6最新python实现问卷星刷问卷,Edge版本_python刷问卷星
- 7net start mysql 服务无法启动_net start mysql服务无法启动
- 8AI Mass人工智能大模型即服务时代:大模型即服务的算法选择_如何理解mass大模型
- 92024年我推荐给你这些高质量计算机书籍_计算机设计架构相关书籍推荐
- 10ImportError: cannot import name ‘OpenAI‘ from ‘openai‘ (D: \anaconda\lib\site-packages \openail_init_cannot import name 'openai' from 'openai
【复现】FreeU以及结合stable diffusion
赞
踩
code:GitHub - ChenyangSi/FreeU: FreeU: Free Lunch in Diffusion U-Net
目录
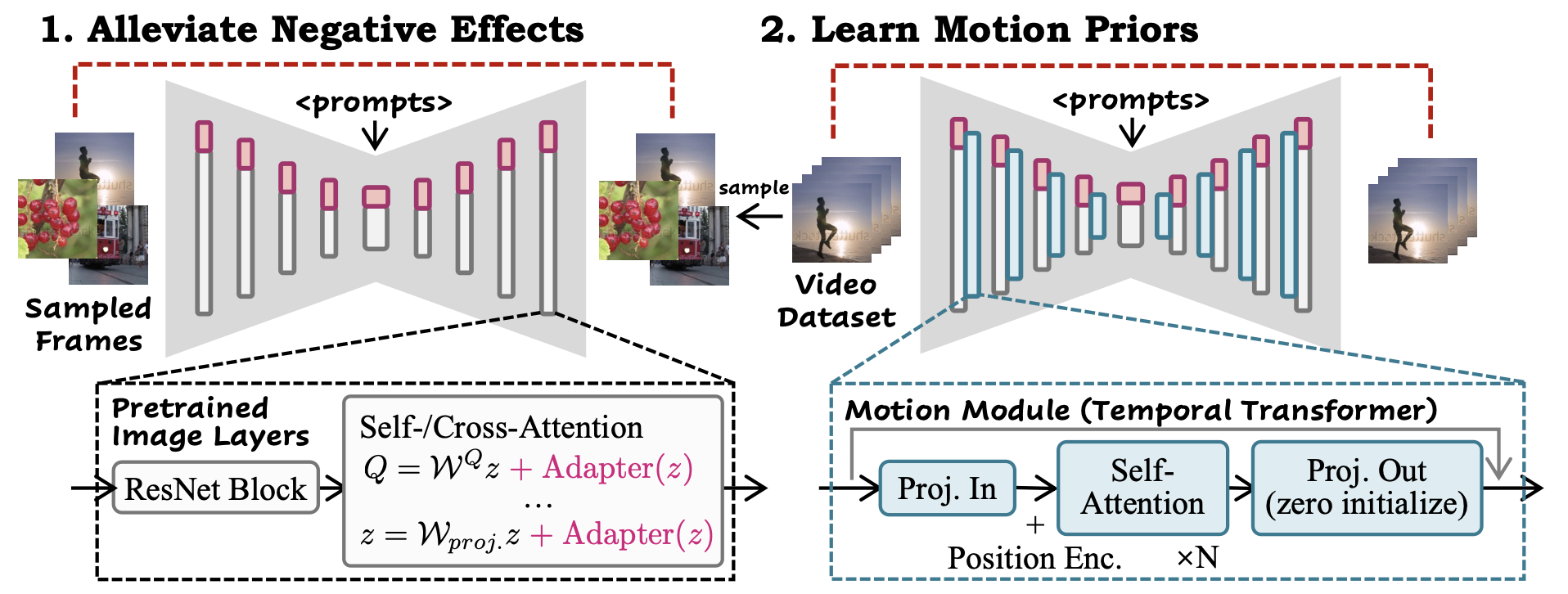
才发现AnimateDiff更新v3了,以及又发了篇CVPR的改进工作:
在这个版本中,我们通过域适配器LoRA对图像模型进行了微调,以便在推理时具有更大的灵活性。
实现了两个(RGB图像/scribble) SparseCtrl编码器,可以采用固定数量的条件映射来控制生成过程。
域适配器是一个在训练视频数据集的静态帧上进行训练的LoRA模块。这个过程是在训练运动模块之前完成的,并帮助运动模块专注于运动建模,如下图所示。在推理时,通过调整域适配器的LoRA尺度,可以去除训练视频的一些视觉属性,如水印。为了利用SparseCtrl编码器,有必要在管道中使用全域适配器。
明天读一下
整了半天发现目前的FreeU好像只支持SD2.1和SDXL啊。。而AnimateDiff v1, v2 and v3 都是用的 Stable Diffusion V1.5。而且AnimateDiff用的diffusers==0.11.1,而FreeU用的0.16.0,尝试了一下,各种不适配。那把他俩结合的尝试之后再说吧
代码分析
- import torch
- from torch.fft import fftn, ifftn, fftshift, ifftshift
-
- def Fourier_filter(x, threshold, scale):
- # FFT
- x_freq = fftn(x, dim=(-2, -1)) # 对输入进行二维快速傅里叶变换(FFT)
- x_freq = fftshift(x_freq, dim=(-2, -1)) # 平移频域结果,使低频部分位于中心
-
- B, C, H, W = x_freq.shape
- mask = torch.ones((B, C, H, W)).cuda() # 创建与输入形状相同的掩码,初始化为全1
-
- crow, ccol = H // 2, W // 2
- mask[..., crow - threshold:crow + threshold, ccol - threshold:ccol + threshold] = scale # 将掩码中心区域设为指定的缩放值
- x_freq = x_freq * mask # 将掩码应用于频域结果,得到滤波后的频域结果
-
- # IFFT
- x_freq = ifftshift(x_freq, dim=(-2, -1)) # 逆平移操作
- x_filtered = ifftn(x_freq, dim=(-2, -1)).real # 对滤波后的频域结果进行逆傅里叶变换(IFFT),并取实部
-
- return x_filtered
-
-
- class Free_UNetModel(UNetModel):
- """
- :param b1: decoder第一个阶段的骨干因子。
- :param b2: decoder第二个阶段的骨干因子。
- :param s1: decoder第一个阶段的跳跃因子。
- :param s2: decoder第二个阶段的跳跃因子。
- """
-
- def __init__(
- self,
- b1,
- b2,
- s1,
- s2,
- *args,
- **kwargs
- ):
- super().__init__(*args, **kwargs)
- self.b1 = b1
- self.b2 = b2
- self.s1 = s1
- self.s2 = s2
-
- def forward(self, x, timesteps=None, context=None, y=None, **kwargs):
- """
- Apply the model to an input batch.
- :param x: 输入的[N x C x ...]张量。
- :param timesteps: 一个包含时间步长的一维批次。
- :param context: 通过交叉注意力插入的条件。
- :param y: 一个[N]张量的标签,如果是类别条件。
- :return: 输出的[N x C x ...]张量。
- """
- assert (y is not None) == (
- self.num_classes is not None
- ), "must specify y if and only if the model is class-conditional"
- hs = []
- t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
- emb = self.time_embed(t_emb)
-
- if self.num_classes is not None:
- assert y.shape[0] == x.shape[0]
- emb = emb + self.label_emb(y)
-
- h = x.type(self.dtype)
- for module in self.input_blocks:
- h = module(h, emb, context)
- hs.append(h)
- h = self.middle_block(h, emb, context)
- for module in self.output_blocks:
- hs_ = hs.pop()
-
- # --------------- FreeU code -----------------------
- # 只对前两个阶段进行操作
- if h.shape[1] == 1280:
- hidden_mean = h.mean(1).unsqueeze(1)
- B = hidden_mean.shape[0]
- hidden_max, _ = torch.max(hidden_mean.view(B, -1), dim=-1, keepdim=True)
- hidden_min, _ = torch.min(hidden_mean.view(B, -1), dim=-1, keepdim=True)
- hidden_mean = (hidden_mean - hidden_min.unsqueeze(2).unsqueeze(3)) / (hidden_max - hidden_min).unsqueeze(2).unsqueeze(3)
-
- h[:,:640] = h[:,:640] * ((self.b1 - 1 ) * hidden_mean + 1)
- hs_ = Fourier_filter(hs_, threshold=1, scale=self.s1)
- if h.shape[1] == 640:
- hidden_mean = h.mean(1).unsqueeze(1)
- B = hidden_mean.shape[0]
- hidden_max, _ = torch.max(hidden_mean.view(B, -1), dim=-1, keepdim=True)
- hidden_min, _ = torch.min(hidden_mean.view(B, -1), dim=-1, keepdim=True)
- hidden_mean = (hidden_mean - hidden_min.unsqueeze(2).unsqueeze(3)) / (hidden_max - hidden_min).unsqueeze(2).unsqueeze(3)
-
- h[:,:320] = h[:,:320] * ((self.b2 - 1 ) * hidden_mean + 1)
- hs_ = Fourier_filter(hs_, threshold=1, scale=self.s2)
- # ---------------------------------------------------------
-
- h = th.cat([h, hs_], dim=1)
- h = module(h, emb, context)
- h = h.type(x.dtype)
- if self.predict_codebook_ids:
- return self.id_predictor(h)
- else:
- return self.out(h)

Fourier_filter函数用于对输入进行傅里叶变换滤波。具体步骤如下:
- 对输入进行二维快速傅里叶变换(FFT)。
- 对频域结果进行平移操作,使低频部分位于中心。
- 创建一个与输入形状相同的掩码,初始化为全1。
- 根据给定的阈值和缩放因子,将掩码中心区域设为指定的缩放值。
- 将掩码应用于频域结果,得到滤波后的频域结果。
- 对滤波后的频域结果进行逆平移操作。
- 对逆平移后的结果进行二维逆傅里叶变换(IFFT)。
- 返回滤波后的实部结果。
Free_UNetModel类是基于UNet模型的扩展,具有自定义的前向传播方法。具体功能如下:
- 接收输入x、时间步长timesteps、上下文context和标签y。
- 根据是否有标签,计算时间嵌入向量并与标签嵌入向量相加。
- 通过输入块和中间块的循环,逐层处理输入数据,并将每一层的输出保存在列表hs中。
- 对输出块进行处理,其中包括对特定阶段的FreeU代码的应用。
- 将处理后的输出与上一层的输出拼接起来,并通过输出块进行最终处理。
- 根据模型设置,返回预测结果或编码器输出。
总体而言,这段代码实现了一个具有傅里叶滤波和自定义前向传播的UNet模型扩展。
free_lunch_utils.py
主要有三个函数:Fourier_filter,register_free_upblock2d,register_free_crossattn_upblock2d。后两者定义了FreeU的Unet框架
register_upblock2d 函数:
- 该函数注册的是普通的上采样块(UpBlock2D)的自定义前向传播方法。
- 在
up_forward函数中,通过循环遍历模型中的每个上采样块(UpBlock2D对象),将其前向传播方法重写为自定义的forward函数。 - 无需设置其他属性或参数。
register_free_upblock2d 函数:
- 该函数注册的是自由上采样块(FreeU UpBlock2D)的自定义前向传播方法。
- 在
up_forward函数中,与register_upblock2d函数类似,通过循环遍历模型中的每个上采样块,并将其前向传播方法重写为自定义的forward函数。 - 此外,还设置了一些额外的属性
b1、b2、s1和s2,分别表示两个阶段的放大因子和两个阶段的 Fourier 滤波器阈值。
模型复现
SDV2-1下载:stabilityai/stable-diffusion-2-1 at main (huggingface.co)
FreeU Code:https://github.com/ChenyangSi/FreeU/tree/main?ref=blog.hinablue.me#freeu-code
问题
问题1:torch.cuda.OutOfMemoryError
FreeU中没设置生成图片的大小,用的默认值多少也看不出来,手动设一下
- print("Generating SD:")
- # sd_image = pip(prompt, num_inference_steps=25).images[0]
- sd_image = pip(prompt, num_inference_steps=25, width=256, height=256).images[0]
-
- print("Generating FreeU:")
- # freeu_image = pip(prompt, num_inference_steps=25).images[0]
- freeu_image = pip(prompt, num_inference_steps=25, width=256, height=256).images[0]
结果报错:TypeError: Transformer2DModel.forward() got an unexpected keyword argument 'cross_attention_kwargs'
尝试注释掉所有cross_attention_kwargs,结果:
生成的东西意义不明,不能省略cross_attention_kwargs(包含与交叉注意力相关的配置信息)
终极方法:换GPU,上3090
解决!
问题2. TypeError: register_free_upblock2d.<locals>.up_forward.<locals>.forward() got an unexpected keyword argument 'scale'
尝试:可能是库之间的不兼容性引起的,重新安装了torch和cuda和requiremen,然后发现打印的torch版本和刚安装的版本不一样,检查发现是用了其他程序的虚拟环境。好像是在vscode里,用的哪个程序的python编辑器,就会自动用哪个程序的虚拟环境。重新创建了符合版本的虚拟环境和python==3.10.6,解决
效果
(左:SD,右:FreeU)
1. Busy freeway at night.
(b1=1.2 b2=1.3 s1=0.2 s2=0.2)

(b1=1.1 b2=1.2 s1=0.2 s2=0.2)(默认值)

A drone view of celebration with Christma tree and fireworks, starry sky - background.
(b1=1.4 b2=1.6 s1=0.9 s2=0.2)(论文推荐值)

(b1=1.4 b2=1.6 s1=0.2 s2=0.2)

(b1=1.4 b2=1.5 s1=0.9 s2=0.2)

(呃,说实话我感觉效果没有更好。。)
Campfire at night in a snowy forest with starry sky in the background.
(b1=1.4 b2=1.6 s1=0.9 s2=0.2)(论文推荐值)
区别大概是图片主体的柴火更逼真、细节了一点,而大面积的背景(树和星空)随机噪点更多了,较之于左边SD更模糊、粗糙,上面两个示例的地平线都给抹平了
A storm trooper vacuuming the beach.
(b1=1.4 b2=1.6 s1=0.9 s2=0.2)(论文推荐值)
哦,这个示例是效果最明显的,也是论文里的示例图
(b1=1 b2=1.6 s1=0.9 s2=0.2)
(b1=1 b2=1 s1=0.9 s2=0.2)

(b1=1.4 b2=1.6 s1=0 s2=0)

总结
总结一下效果:主体更逼真(b的影响),背景更平滑(s的影响),但是似乎只调整b就可以了,s对视觉效果没有明显改善,反而抹平了很多细节
FreeU + Diffusers
GitHub - lyn-rgb/FreeU_Diffusers: "FreeU: Free Lunch in Diffusion U-Net" for Huggingface Diffusers
来源:FreeU | 增强图像生成质量的插件 - 掘金 (juejin.cn)
webui插件:GitHub - ljleb/sd-webui-freeu: a1111 implementation of https://github.com/ChenyangSi/FreeU

