
- 1Cocos2d-X官方Demo---1.ActionManager
- 2hivesql行转列和列转行_hive sql 列转行
- 3Flutter web 最新进展: 发掘更多可能!
- 43.yolov5目标检测-常用评估指标_yolov5检测框上的显示的数字代表什么
- 5mysql和mysqldump出现command not found 问题解决_mysqldump: command not found
- 6网易 NLP 大模型实习面试题8道|含解析_1.文本生成的几大预训练任务?
- 7台积电砸1000亿元建12英寸晶圆厂:2018年量产--OFweek_台积电 晶圆产量 2018
- 8微信小程序—仿写京东购物商城带源码_微信小程序仿京东
- 9Linux(超级详细)
- 10我们该如何看待AIGC(人工智能)_大佬们怎么看aigc
大数据技术原理与应用(三):分布式文件系统HDFS
赞
踩
HDFS——Hadoop Distributed File System,Hadoop分布式文件系统
为了解决海量数据的分布式存储问题
主节点承担起数据目录(元数据)服务
从节点具体完成数据的存储任务HDFS设计目标
①兼容廉价的硬件设备
②能实现流数据读写
这是HDFS和其他分布式文件系统和传统的文件系统有很大区别的一个地方。传统的文件系统在进行数据读写的时候,是以块数据为单位,每一次可以读取指定的某一部分数据。而HDFS设计的目标就是对大量数据的读写,它不会去访问文件的某个子集,或去访问一块一块的数据,而是为了满足大规模数据的批量处理需求,HDFS是以这个出发点来设计的
③支持大数据集
小则几百MB,大则几个TB
④支持简单的文件模型
⑤强大的跨平台兼容性
HDFS自身的局限性
①不适合低延迟数据访问
HDFS实时性不高,不能满足实时的数据管理需求
②无法高效存储大量小文件
③不支持多用户写入及任意修改文件
HDFS只允许追加数据,不允许修改数据
HDFS相关概念
块是整个HDFS最核心的概念(之一)
HDFS的块和普通文件系统的块既有相同点又有区别
HDFS存储原理
优先就近读取
名称节点出错
如果总管家名称界点出了问题,因为名称节点只有这一个,而且保存了最核心的两大数据结构,FsImage和Editlog(基本上是访问整个文件系统所需要最基本的数据结构)
名称节点平时会做一个冷备份SecondNameNode,当名称节点NameNode出现问题以后,它会暂停服务一段时间,把相关的元数据信息吗,从SecondNameNode上恢复过来,恢复结束以后再提供对外服务,但到了2.0之后就不存在这个问题了,不需要暂停服务一段时间了
数据节点出错
首先我们是怎样知道数据节点出现问题了呢?数据节点在整个运行期间,都会定期给名称节点发送心跳信息,告诉名称界点自己还活着。一旦隔了一个周期,名称节点收不到心跳信息,它就知道这个数据节点发生了故障,名称节点就会在状态列表(它维护者一个整个集群中所有数据节点的一个列表)里面把它标记为宕机,并把存储在故障机上的数据重新复制分发到其他正常可用的机器上(所有数据都是有备份的)。
HDFS和其他分布式文件系统最大的区别就是可以调整冗余数据的位置,不仅是当它发生故障时可以调整,当负载发生严重不均衡的时候,也会实现均衡把这些数据块从这个机器迁移到另一个机器
数据本身出错
HDFS用什么机制来探测数据出问题呢——校验码
客户端读取数据之后会对数据进行校验码校验,如果发现校验码不对,就说明数据出了问题。校验码是文件被创建的时候生成的。







HDFS数据读写过程
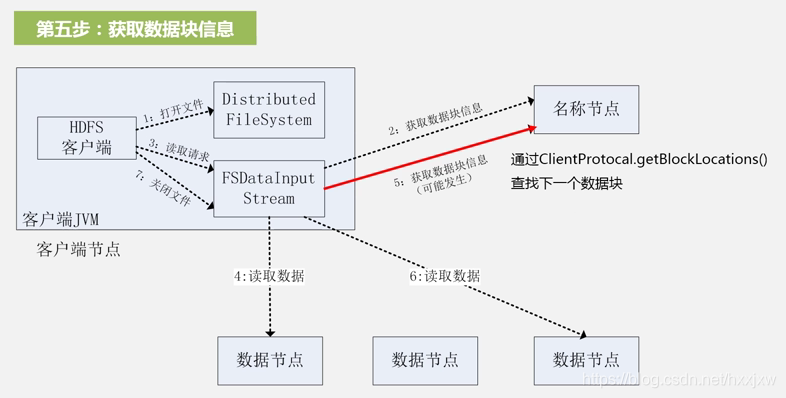
HDFS读数据过程
文件数据可能比较大,名称节点会把文件的开始一部分位置信息返回给刚才的调用
选择距离客户端最近的数据节点去建立连接,读数据
数据读完了以后要关闭和数据节点的连接
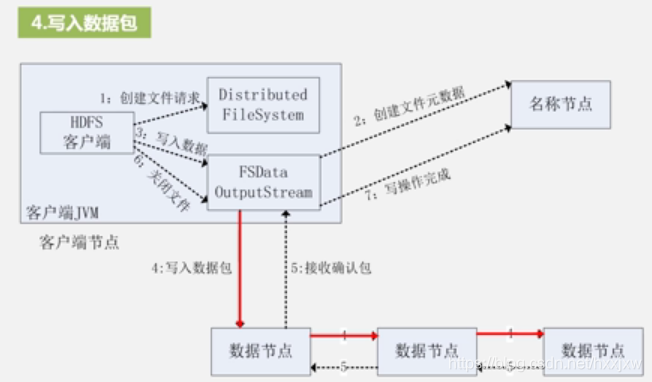
HDFS写数据过程

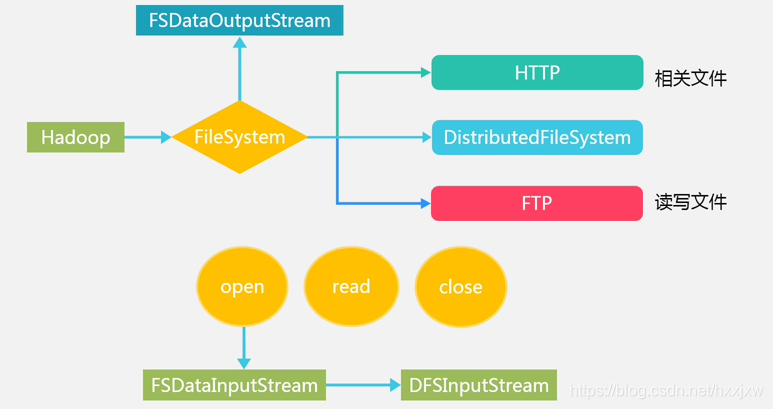











HDFS编程实践



