
热门标签
热门文章
- 1第四轮学科评估计算机专业排名,第四轮学科评估
- 2Hive简介&环境搭建_cdp集群如何开通tez ui
- 3java.lang.IllegalStateException: failed to obtain node locks, tried [/usr/share/elasticsearch/data]
- 4web漏洞之XXE
- 5python实现刷问卷星份数(面向对象)_问卷星python刷问卷
- 6获取button中value值的方法_js中如何通过点击事件获得button的value
- 7微信小程序中的图像奥秘:图片与Base64的华丽变身记_微信小程序选择图片转base64
- 8高精度、高重复性国产三坐标测量机,精密制造的质量守护者
- 9自然语言处理(NLP)练习题_问答题 自然语言处理
- 10自动化测试框架的目录结构
当前位置: article > 正文
4、stable diffusion_512-inpainting-ema
作者:从前慢现在也慢 | 2024-05-25 13:35:46
赞
踩
512-inpainting-ema
安装anaconda环境
conda env create -f environment.yaml
conda activate ldm
- 1
- 2
安装依赖
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
- 1
- 2
- 3
安装xformers加速
xformers安装包
找到符合自己python,pytorch和cuda版本的xformers安装包

wget https://anaconda.org/xformers/xformers/0.0.16/download/linux-64/xformers-0.0.16-py39_cu11.3_pyt1.12.1.tar.bz2
conda install xformers-0.0.16-py310_cu11.3_pyt1.12.1.tar.bz2
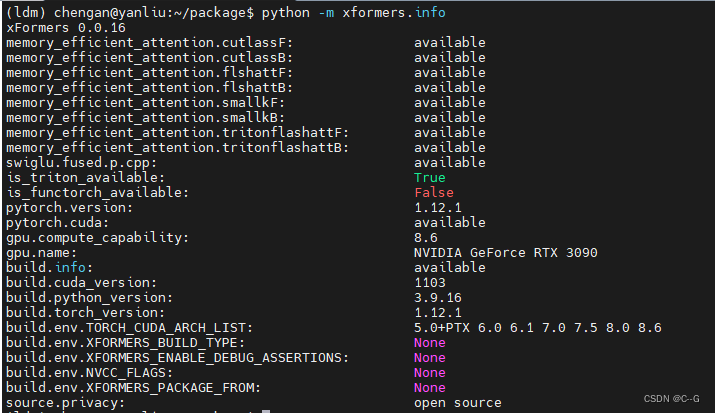
python -m xformers.info
- 1
- 2
- 3
安装成功为下述图片
源码
下载预训练模型权重
文生图
SD2.1-v
Image Inpainting with Stable Diffusion
512-inpainting-ema.ckpt
从Hugging Face下载encoding
当我们运行scripts/txt2img.py时,会发现还需要从hugging face下载encoding,但是国内无法下载,这时候我们会科学上网,同时安装下述依赖,这样就可以下载了
os.environ["http_proxy"] = "http://ip:7890"
os.environ["https_proxy"] = "http://ip:7890"
pip install urllib3==1.25.11
pip install requests==2.27.1
- 1
- 2
- 3
- 4
- 5
文生图
python scripts/txt2img.py
--prompt
"a professional photograph of an astronaut riding a horse"
--ckpt
/devdata/chengan/stablediffusion/v2-1_768-ema-pruned.ckpt
--config
configs/stable-diffusion/v2-inference-v.yaml
--H
768
--W
768
--device
cuda
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
注意: --device 默认为cpu,要换成 cuda,否则报错
RuntimeError: expected scalar type BFloat16 but found Float
- 1

图生图
图生图使用到Gradio依赖,但是会缺少一个文件,使用下述命令补全
wget https://cdn-media.huggingface.co/frpc-gradio-0.2/frpc_linux_amd64
mv frpc_linux_amd64 frpc_linux_amd64_v0.2
mv frpc_linux_amd64_v0.2 /home/chengan/anaconda3/envs/llm/lib/python3.9/site-packages/gradio
chmod +x /home/chengan/anaconda3/envs/llm/lib/python3.9/site-packages/gradio/frpc_linux_amd64_v0.2
- 1
- 2
- 3
- 4
- 5
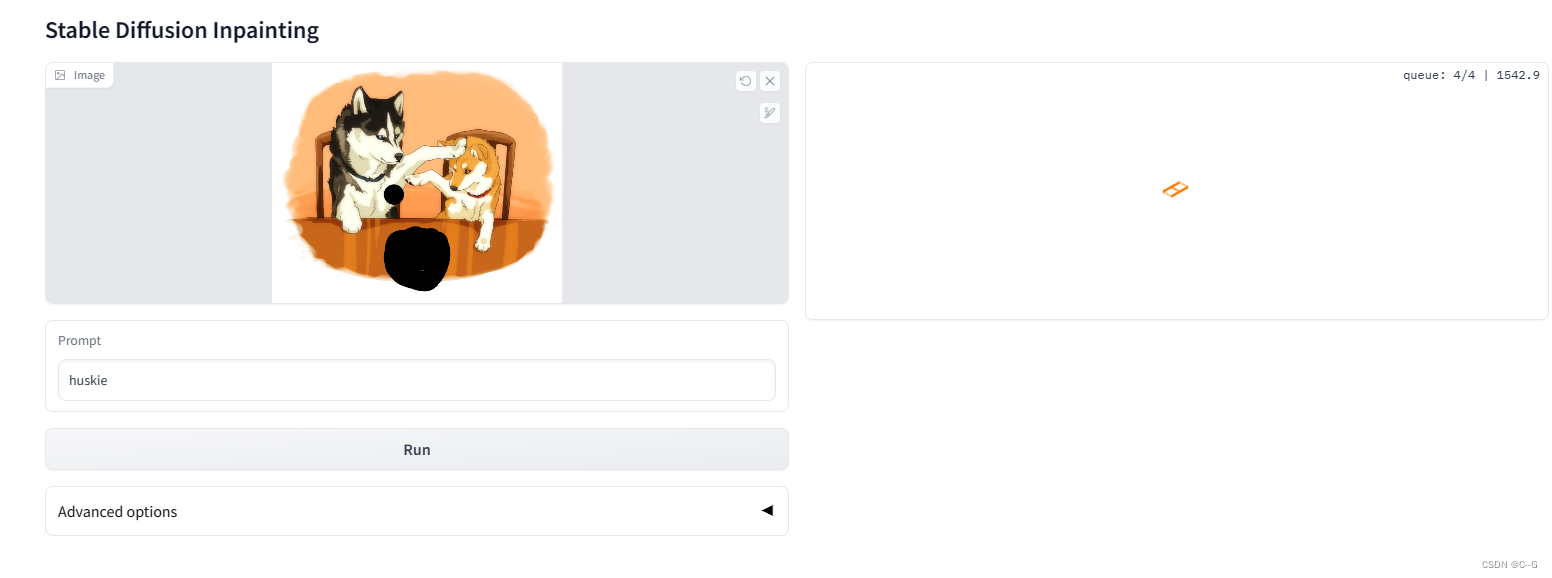
当部署项目到服务器,本地浏览器无法打开Gradio链接,修改inpainting.py文件最后一行
block.launch(server_name="0.0.0.0", server_port=7896, share=True)
- 1
python scripts/gradio/inpainting.py configs/stable-diffusion/v2-inpainting-inference.yaml /devdata/chengan/stablediffusion/512-inpainting-ema.ckpt
- 1

api
depth2image
pip install -U git+https://github.com/huggingface/transformers.git
pip install diffusers transformers accelerate scipy safetensors
- 1
- 2
import torch import requests from PIL import Image from diffusers import StableDiffusionDepth2ImgPipeline pipe = StableDiffusionDepth2ImgPipeline.from_pretrained( "stabilityai/stable-diffusion-2-depth", torch_dtype=torch.float16, ).to("cuda") url = "http://images.cocodataset.org/val2017/000000039769.jpg" init_image = Image.open(requests.get(url, stream=True).raw) prompt = "two tigers" n_propmt = "bad, deformed, ugly, bad anotomy" image = pipe(prompt=prompt, image=init_image, negative_prompt=n_propmt, strength=0.7).images[0]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
inpaint image
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-inpainting",
torch_dtype=torch.float16,
)
pipe.to("cuda")
prompt = "two tigers"
# image and mask_image should be PIL images.
# The mask structure is white for inpainting and black for keeping as is
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
mask_image = np.ones(image.size)
img = pipe(prompt=prompt, image=image, mask_image=mask_image).images[0]
plt.imshow(img)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/622258
推荐阅读
相关标签

